Flask学习之旅--还是数据库(sqlacodegen + SQL Alchemy)
一、写在前面
其实之前已经写过一篇关于 Flask 中使用数据库的博客了,不过那一篇博客主要是记录我在使用 Flask + MySQL8.0 时所遇到的一些问题(如果用的不是 MySQL8.0估计就没有这么多问题了!)。然后这一篇可以算作一份学习笔记了,也是关于在 Flask 中进行数据库操作的,感觉写这种学习笔记还是比较有用的,可以再学习一遍也就能更好的掌握了。
在使用 Flask 的时候,一般都会创建一个 model.py,然后在里面继承和创建模型,再迁移到数据库中,最后进行一些增删改查等操作。但是如果数据库表已经建立好了呢?有没有办法将这些数据库表引入到 Flask 中呢?
二、sqlacodegen
1.sqlacodegen简介
sqlacodegen pypi:https://pypi.org/project/sqlacodegen/。
其中对 sqlacodegen 的介绍是:这是一个工具,它读取现有数据库的结构并生成相应的 SQLAlchemy 模型代码,如果可能,使用声明式样式。
sqlacodegen 的几个主要特性为:
1)支持 SQLAlchemy 0.8.x - 1.3.x。
2)生成几乎看起来像是手写的声明性代码。
3)生成符合 PEP 8 标准的代码。
4)准确地确定关系,包括多对多,一对一。
5)自动检测连接表继承。
2.sqlacodegen安装
使用 pip 安装即可:
pip install sqlacodegen
3.sqlacodegen用法
下面是一个 sqlacodegen 用法示例:
sqlacodegen mysql+pymysql://root:qwer1234@127.0.0.1/mydb --tables users,roles,phone >models.py
首先是一个 sqlacodegen 命令,后面接上连接数据库的语句,然后可以使用 --tables 指定要导入的数据表,最后用 >models.py 输出到 models.py 中,如果不指定输出文件,会将 python 代码直接打印出来。下面是生成的 models.py 中的代码:
# coding: utf-8
from sqlalchemy import Column, ForeignKey, String
from sqlalchemy.dialects.mysql import INTEGER
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
metadata = Base.metadata class Phone(Base):
__tablename__ = 'phone' phone = Column(String(11), primary_key=True)
phone_address = Column(String(40)) class Role(Base):
__tablename__ = 'roles' role_id = Column(INTEGER(11), primary_key=True)
role_name = Column(String(45)) class User(Base):
__tablename__ = 'users' user = Column(String(10), primary_key=True)
sex = Column(String(10))
email = Column(String(45))
phone = Column(String(11))
role_id = Column(ForeignKey('roles.role_id'), index=True) role = relationship('Role')
三、SQL Alchemy
1.SQL Alchemy简介
SQL Alchemy pypi:https://pypi.org/project/SQLAlchemy/。
SQL Alchemy 是 Python SQL 工具包和对象关系映射器,它为应用程序开发人员提供了SQL的全部功能和灵活性。
在写上篇博客的时候简单介绍过 Flask-SQLAlchemy,当时说到它将对 SQL Alchemy 的支持添加到 Flask 应用程序中,因此我们通过简单设置之后就能在 Flask 中队数据库进行操作了,可那是当我们在把定义好的模型映射到数据库中时所用的。如果数据库表已经建好了,还怎么用 Flask-SQLAlchemy 来操作呢?这时候就需要使用 SQL Alchemy 了!
2.SQL Alchemy安装
使用 pip 安装即可:
pip install SQLAlchemy
3.SQL Alchemy架构
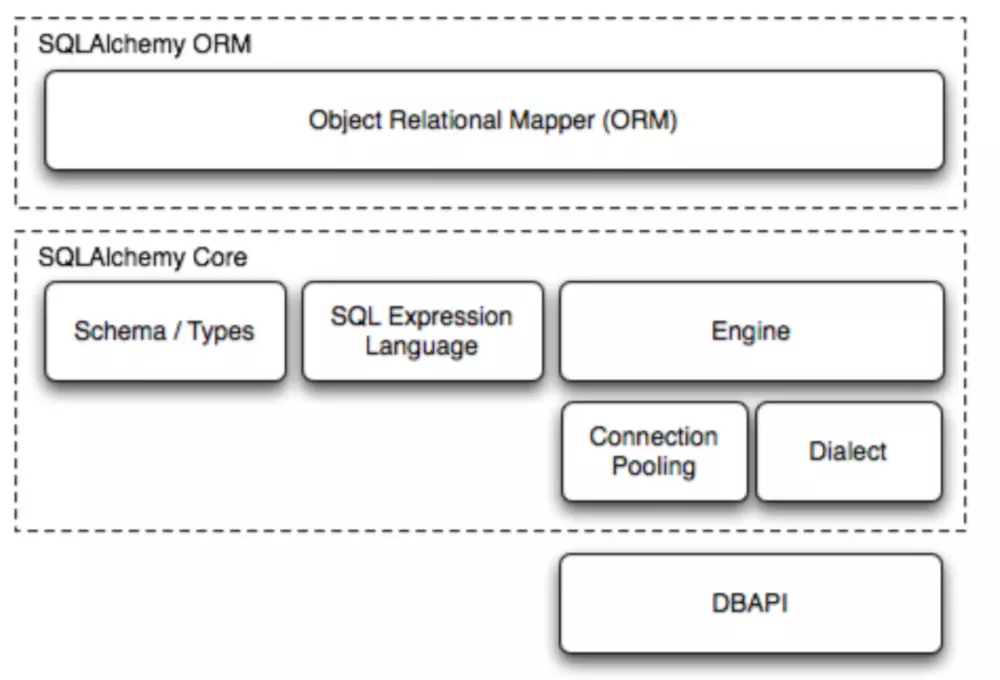
1)Schema / Types 定义了类到表之间的映射框架(规则)。
2)SQL Expression Language 封装好的 SQL 语句。
3)Engine 操作者。
4)Connection Pooling 连接池。
5)Dialect 根据用户的配置,调用不同的数据库 API(如:Mysql) 并执行对应的 SQL 语句。
4.SQL Alchemy用法
(1)连接数据库
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:qwer1234@127.0.0.1:3306/mydb")
create_engine() 会返回一个引擎实例,它代表着数据库的接口。这个引擎实例可以执行 SQL 语句,例如:
engine.execute("show tables")
(2)创建会话
光有这个数据库的引擎还不够,还需要建立会话才行,这里要使用引擎来创建一个 Session 类的实例,代码为:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker # 创建引擎
engine = create_engine("mysql+pymysql://root:qwer1234@127.0.0.1:3306/mydb")
# 使用引擎创建Session
DB_Session = sessionmaker(bind=engine)
# 实例化
db_session = DB_Session()
(3)单表 CRUD
插入数据:
# 插入
db_session.execute("insert into roles values(%d,%s)" % (1, "'admin'"))
db_session.execute("insert into users values(%s,%s,%s,%s,%d)" % ("'user1'", "'man'", "'user1@163.com'", "'12233445566'", 1))
db_session.commit()
插入数据可以使用 SQL 语句来完成,在插入数据之后要使用 commit(),这一点不能忘记。
查询数据:
# 查询
result = db_session.query(User).filter(User.user == "user1")
print(result.all())
usr = result.all()[0]
print(usr.email) # [<SQlAlchemy.models.User object at 0x0000028D33D7CDD8>]
# user1@163.com
在查询的时候需要使用 query() 和 filter(),返回的结果是一个列表,如果列表为空就表示数据库中没有该记录。对于返回的这个结果,使用 all() 返回所有记录,使用 one() 返回第一条记录。
更新数据:
# 更新
db_session.query(User).filter(User.user == "user1").update({User.email: 'user1user1@163.com'})
db_session.commit()
# 查询
result = db_session.query(User).filter(User.user == "user1")
usr = result.one()
print(usr.email) # user1user1@163.com
更新数据可以使用 update() 方法,不过要接在 filter() 之后,使用这种方法即使数据库中没有记录也不会报错。
删除数据:
# 删除
db_session.query(User).filter(User.user == "user1").delete()
# 查询
result = db_session.query(User).filter(User.user == "user1")
usr = result.one()
print(usr.email) # sqlalchemy.orm.exc.NoResultFound: No row was found for one()
删除数据的使用方法和更新数据类似,只不过是在 filter() 之后使用 delete() 方法。
(4)多表查询
假设要查询 phone 为"12233445566"的用户名称和电话所在地址,就需要将 users 表和 phone 表联合起来进行查询,方法是使用多个 filter():
res = db_session.query(User, Phone).filter(User.phone == "").filter(Phone.phone == "")
u, p = res.one()
print(u.user, p.phone_address) # user1 A
假设要查询 user 为"user1"的用户的角色信息,就需要将 users 表和 roles 表联合起来进行查询,因为有外键的关系,所以可以使用 join():
res = db_session.query(User).join(Role).filter(User.user == "user1")
u = res.one()
print(u.user, u.role.role_name) # user1 admin
Flask学习之旅--还是数据库(sqlacodegen + SQL Alchemy)的更多相关文章
- Flask学习之旅--数据库
一.写在前面 在Web开发中,数据库操作是很重要的一部分,因为网站的很多重要信息都保存在数据库之中.而Flask在默认情况下是没有数据库.表单验证等功能的,但是可以用Flask-extension为W ...
- Flask学习之旅--简易留言板
一.写在前面 正所谓“纸上得来终觉浅,方知此事要躬行”,在看文档和视频之余,我觉得还是要动手做点什么东西才能更好地学习吧,毕竟有些东西光看文档真的难以理解,于是就试着使用Flask框架做了一个简易留言 ...
- Flask学习之旅--分页功能:分别使用 flask--pagination 和分页插件 layPage
一.前言 现在开发一个网站,分页是一个很常见的功能了,尤其是当数据达到一定量的时候,如果都显示在页面上,会造成页面过长而影响用户体验,除此之外,还可能出现加载过慢等问题.因此,分页就很有必要了. 分页 ...
- Flask学习之旅--用 Python + Flask 制作一个简单的验证码系统
一.写在前面 现在无论大大小小的网站,基本上都会使用验证码,登录的时候要验证,下载的时候要验证,而使用的验证码也从那些简简单单的字符图形验证码“进化”成了需要进行图文识别的验证码.需要拖动滑块的滑动验 ...
- Flask学习之旅--Flask项目部署
一.写在前面 Flask 作为一个轻量级的 Web 框架,具有诸多优点,灵活方便,扩展性强,开发文档也很丰富.在开发调试的过程中,我们往往会使用 Flask 自带的 Web 服务器,但如果要投入到生产 ...
- SQL server学习(一)数据库的基本知识、基本操作和基本语法
在软件测试中,数据库是必备知识,假期闲里偷忙,整理了一点学习笔记,共同探讨. 阅读目录 基本知识 数据库发展史 数据库名词 SQL组成 基本操作 登录数据库操作 数据库远程连接操作 数据库分离操作 数 ...
- SQL 数据库 学习 003 什么是数据库? 为什么需要数据库?是不是所有的软件都是用Sql Server?
什么是数据库? 为什么需要数据库? 是不是所有的软件都是用Sql Server? 我的电脑系统: Windows 10 64位 使用的SQL Server软件: SQL Server 2014 Exp ...
- SQL server学习(一)数据库的基本知识、基本操作(分离、脱机、收缩、备份、还原、附加)和基本语法
在软件测试中,数据库是必备知识,共同探讨. 阅读目录 基本知识 数据库发展史 数据库名词 SQL组成 基本操作 登录数据库操作 数据库远程连接操作 数据库分离操作 数据库脱机.联机操作 数据库收缩操作 ...
- Python 学习 第17篇:从SQL Server数据库读写数据
在Python语言中,从SQL Server数据库读写数据,通常情况下,都是使用sqlalchemy 包和 pymssql 包的组合,这是因为大多数数据处理程序都需要用到DataFrame对象,它内置 ...
随机推荐
- LCA最近公共祖先---倍增法笔记
先暂时把模板写出来,A几道题再来补充 此模板也是洛谷上的一道模板题 P3379 [模板]最近公共祖先(LCA) #pragma GCC optimize(2) //o2优化 #include < ...
- Go---go-cache包学习
github.com/patrickmn/go-cachego-cache是一款类似于memached 的key/value 缓存软件.它比较适用于单机执行的应用程序.go-cache实质上就是拥有过 ...
- Hyper-V修改Docker for Windows存储设置
自从Win10安装了Docker for Windows后,C盘容量爆炸,必须做一波迁移了.我的Docker使用的是Windows的Hyper-V虚拟机,于是google了一番找到以下一篇文章 doc ...
- ID转名称到手方案01
> 好久没有写技术文章了,那就重新捡起来,从今天开始,分享这段时间的收获吧 ------------ > ## 其实很多时候,我们只需要鱼,而不是渔,呐,给你鱼. ### 这次的分享主题是 ...
- 纯数据结构Java实现(6/11)(二叉堆&优先队列)
堆其实也是树结构(或者说基于树结构),一般可以用堆实现优先队列. 二叉堆 堆可以用于实现其他高层数据结构,比如优先队列 而要实现一个堆,可以借助二叉树,其实现称为: 二叉堆 (使用二叉树表示的堆). ...
- 数据读写API——IO流
理清一些概念 1.Java 中的IO是干啥的? IO指的是Input和Output,主要目的是实现数据在存储介质之间的传输.[流:数据流,类比与水流的流动] 2.IO分类 按照操作单元来划分,可以分为 ...
- 2015-11-17 linux基础笔记
21. 可执行权限不代表能够执行,这得看文件内容 22. 还是可以用适当的拓展名表示该文件是什么种类的*.sh 脚本或批处理文件 *Z.*.tar.*.tar.gz.*.zip.*.tgz 压缩文件 ...
- 设计模式(C#)——11代理模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 前言 在软件开发过程中,当无法直接访问某个对象或访问某个对象存在困难时,我们希望可以通过一个中介来间接访问,这就是 ...
- Javaweb Session机制(有待补充)
Javaweb Session机制 一.前言 session,中文经常翻译为会话,其本来的含义是指有始有终的一系列动作/消息,比如打电话是从拿起电话拨号到挂断电话这中间的一系列过程可以称之为一个ses ...
- redis数据结构、持久化、缓存淘汰策略
Redis 单线程高性能,它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题.redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放 ...