构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大、综合成本低、支持非结构化数据、查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式。
因此数据湖相关服务成为了云计算的发展重点之一。Azure平台早年就曾发布第一代Data Lake Storage,随后微软将它与Azure Storage进行了大力整合,于今年初正式对外发布了其第二代产品:Azure Data Lake Storage Gen2 (下称ADLS Gen2)。ADLS Gen2的口号是“不妥协的数据湖平台,它结合了丰富的高级数据湖解决方案功能集以及 Azure Blob 存储的经济性、全球规模和企业级安全性”。
全新一代的ADLS Gen2实际体验如何?在架构及特性上是否堪任大型数据湖应用的主存储呢?在上篇文章中,我们已对ADLS Gen2的基本操作和权限体系有了初步的了解。接下来让我们继续深入探究,尤其是关注ADLS Gen2作为存储层挂载到大数据集群后的表现。
ADLS Gen2体验:集群挂载
数据湖存储主要适用于大数据处理的场景,所以我们选择建立一个HDInsight大数据集群来进行实验,使用Spark来访问和操作数据湖中的数据。可以看到HDInsight已经支持ADLS Gen2了:
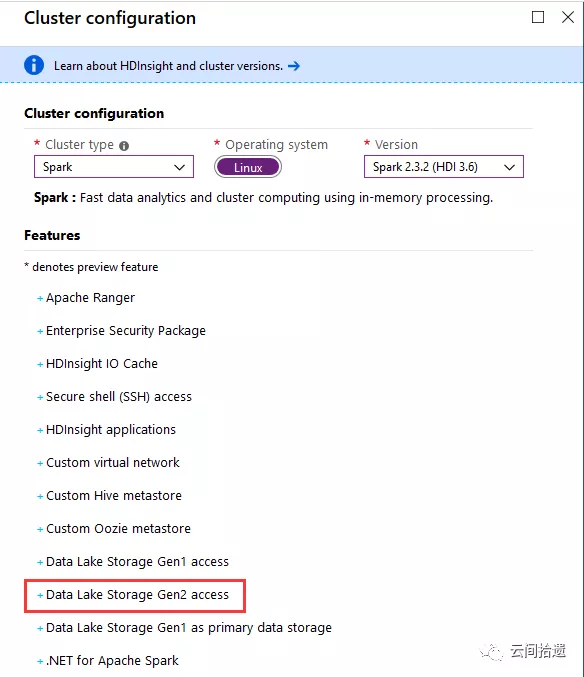
接下来是比较关键的存储配置环节,我们指定使用一个新建的ADLS Gen2实例hdiclusterroot来作为整个集群的存储,文件系统名为hdfs-root,如图所示:
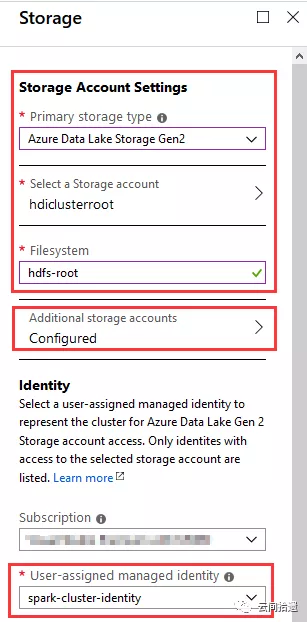
(图中我们还配置了Additional storage accounts,用于挂载传统Blob,之后作性能对比时会用到。此处暂不展开。)
很有意思的是上图的下半部分,它允许我们指定一个Identity,这个Identity可以代表Spark集群的身份和访问权限。这非常关键,意味着集群的身份能够完美地与ADLS Gen2的权限体系对应起来,在企业级的场景中能够很好地落地对于大数据资源访问的管控。
这里选择了专门建立的一个spark-cluster-identity作为集群的身份。我们事先为它赋予了hdiclusterroot这个存储账号的storage blob data owner权限,以便该identity能够对数据湖中的数据进行任意操作:
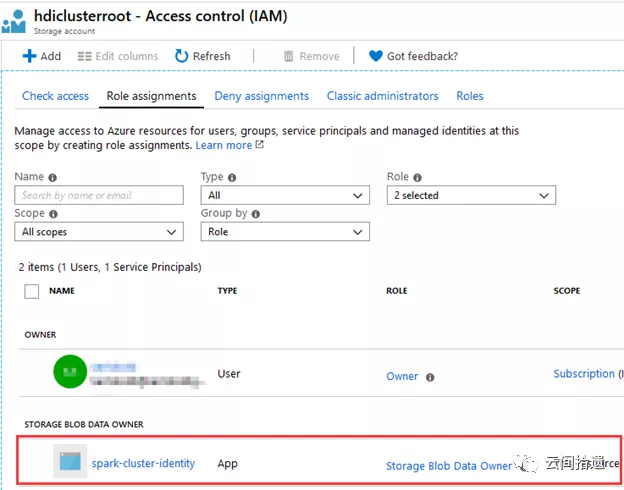
完成其他配置后按下创建按钮,Azure会一键生成Spark集群,大约十来分钟后整个集群就进入可用状态了:

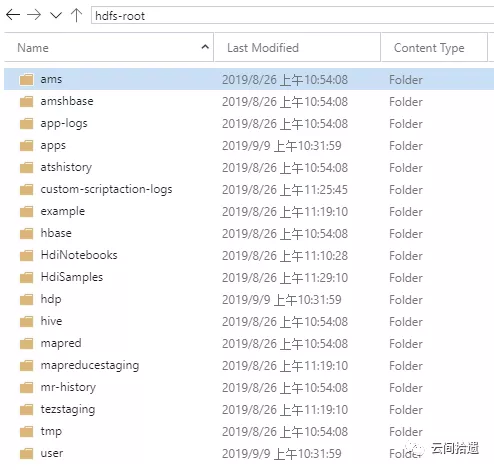
我们迫不及待地SSH登录进集群,查看其默认挂载的文件系统。尝试使用hadoop fs -ls列出根目录下的文件信息:
sshuser@hn0-cloudp:~$ hadoop fs -ls /
Found 18 items
drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:10 /HdiNotebooks
drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:29 /HdiSamples
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /ams
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /amshbase
drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /app-logs
drwxr-x--- - sshuser sshuser 0 2019-09-06 07:41 /apps
drwxr-x--x - sshuser sshuser 0 2019-08-26 02:54 /atshistory
drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:25 /custom-scriptaction-logs
drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:19 /example
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hbase
drwxr-x--x - sshuser sshuser 0 2019-09-06 07:41 /hdp
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hive
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /mapred
drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /mapreducestaging
drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /mr-history
drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /tezstaging
drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /tmp
drwxrwx-wt - sshuser sshuser 0 2019-09-09 02:31 /user
将文件列表和ADLS Gen2比对,可以看到这里的“根目录”事实上就完全对应着hdiclusterroot这个数据湖实例下hdfs-root文件系统中的数据,这说明集群实现了该数据湖文件系统的挂载:
那么,这样的远程挂载是如何实现的呢?打开集群的core-site.xml 配置文件,答案在fs.defaultFS配置节中:
<property>
<name>fs.defaultFS</name>
<value>abfs://hdfs-root@hdiclusterroot.dfs.core.windows.net</value>
<final>true</final>
</property>
原来,与通常使用hdfs不同,集群的fs.defaultFS在创建时就被设置为了以abfs为开头的特定url,该url正是指向我们的数据湖存储。这个ABFS驱动(Azure Blob File System)是微软专门为Data Lake Storage Gen2开发,全面实现了Hadoop的FileSystem接口,为Hadoop体系和ADLS Gen2架起了沟通桥梁。
为证明数据湖文件系统能够正常工作,我们来运行一个经典的WordCount程序。笔者使用AzCopy往数据湖中上传了一本小说《双城记》 (ATaleOfTwoCities.txt),然后到HDInsight集群自带的Jupyter Notebook里通过Scala脚本运用Spark来进行词频统计:

Great! 我们的Spark on ADLS Gen2实验完美运行,过程如丝般顺滑。
小结
Azure Data Lake Storage Gen2是微软Azure全新一代的大数据存储产品,专为企业级数据湖类应用所构建。它继承了Azure Blob Storage易于使用、成本低廉的特点,同时又加入了目录层次结构、细粒度权限控制等企业级特性。
作为ADLS Gen2系列的第二篇,本文主要实践了大数据集群挂载ADLS Gen2作为主存储的场景,在证明ADLS Gen2具备良好Hadoop生态兼容性的同时,也体验了与传统HDFS不同的存储计算分离架构。该种架构由于可独立扩展计算和存储部分,非常适合云端特点,正受到越来越多的欢迎。后续我们还将探索ADLS Gen2的更多特性,敬请关注。
关联阅读:
构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(上)
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑对应用场景进行深度解读。欢迎扫描下方二维码关注“云间拾遗”微信公众号,或订阅本博客。

构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)的更多相关文章
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- Azure Data Lake Storage Gen2实战体验
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount.挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中.mou ...
- 【Azure 存储服务】Hadoop集群中使用ADLS(Azure Data Lake Storage)过程中遇见执行PUT操作报错
问题描述 在Hadoop集中中,使用ADLS 作为数据源,在执行PUT操作(上传文件到ADLS中),遇见 400错误[put: Operation failed: "An HTTP head ...
- Azure Data Lake(一) 在NET Core 控制台中操作 Data Lake Storage
一,引言 Azure Data Lake Storage Gen2 是一组专用于大数据分析的功能,基于 Azure Blob Storage 构建的.Data Lake Storage Gen2 包含 ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- Big Data Solution in Azure: Azure Data Lake
https://blogs.technet.microsoft.com/dataplatforminsider/2015/09/28/microsoft-expands-azure-data-lake ...
- data lake 新式数据仓库
Data lake - Wikipedia https://en.wikipedia.org/wiki/Data_lake 数据湖 Azure Data Lake Storage Gen2 预览版简介 ...
随机推荐
- django前后端分离部署
部署静态文件: 静态文件有两种方式1:通过django路由访问2:通过nginx直接访问 方式1: 需要在根目录的URL文件中增加,作为入口 url(r'^$', TemplateView.as_vi ...
- RN 性能优化
按需加载: 导出模块使用属性getter动态require 使用Import语句导入模块,会自动执行所加载的模块.如果你有一个公共组件供业务方使用,例如:common.js import A from ...
- Linux系统@根目录下各目录作用归纳图
- ThreadLocal可以解决并发问题吗?
前言 到底什么是线程的不安全?为什么会存在线程的不安全?线程的不安全其实就是多个线程并发的去操作同一共享变量没用做同步所产生意料之外的结果.那是如何体现出来的呢?我们看下面的一个非常经典的例子:两个操 ...
- 简明Python教程-函数联系笔记
1.实参与形参 在定义函数时给定的名称称作"形参",再调用函数时你所提供给函数的值称作“实参” 2.局部变量 所有变量的作用域是它们被定义的块,从定义它们的名字的定义点开始. 3. ...
- [企业微信通知系列]Jenkins发布后自动通知
一.前言 最近使用Jenkins进行自动化部署,但是部署后,并没有相应的通知,虽然有邮件发送通知,但是发现邮件会受限于接收方的接收设置,导致不能及时看到相关的发布内容.而由于公司使用的是企业微信,因此 ...
- 混合图欧拉回路POJ1637Sightseeing tour
http://www.cnblogs.com/looker_acm/archive/2010/08/15/1799919.html /* ** 混合图欧拉回路 ** 只记录各定点的出度与入度之差,有向 ...
- UOJ 34 多项式乘法 FFT 模板
这是一道模板题. 给你两个多项式,请输出乘起来后的多项式. 输入格式 第一行两个整数 nn 和 mm,分别表示两个多项式的次数. 第二行 n+1n+1 个整数,表示第一个多项式的 00 到 nn 次项 ...
- codeforces 822 C. Hacker, pack your bags!(思维+dp)
题目链接:http://codeforces.com/contest/822/submission/28248100 题解:多维的可以先降一下维度sort一下可以而且这种区间类型的可以拆一下区间只要加 ...
- codeforces 812 E. Sagheer and Apple Tree(树+尼姆博弈)
题目链接:http://codeforces.com/contest/812/problem/E 题意:有一颗苹果树,这个苹果树所有叶子节点的深度要不全是奇数,要不全是偶数,并且包括根在内的所有节点上 ...