阿里云上万个 Kubernetes 集群大规模管理实践
点击下载《不一样的 双11 技术:阿里巴巴经济体云原生实践》

本文节选自《不一样的 双11 技术:阿里巴巴经济体云原生实践》一书,点击上方图片即可下载!
作者 | 汤志敏,阿里云容器服务高级技术专家
在 2019 年 双11 中,容器服务 ACK 支撑了阿里巴巴内部核心系统容器化和阿里云的云产品本身,也将阿里巴巴多年的大规模容器技术以产品化的能力输出给众多围绕 双11 的生态公司。通过支撑来自全球各行各业的容器云,容器服务沉淀了支持单元化全球化架构和柔性架构的云原生应用托管中台能力,管理了超过 1W 个以上的容器集群。本文将会介绍容器服务在海量 Kubernetes 集群管理上的实践经验。
什么是海量 Kubernetes 集群管理?
大家可能之前看过一些分享,介绍了阿里巴巴如何管理单集群 1W 节点的最佳实践,管理大规模节点是一个很有意思的挑战。不过这里讲的海量 Kubernetes 集群管理,会侧重讲如何管理超过 1W 个以上不同规格的 Kubernetes 集群。根据我们和一些同行的沟通,往往一个企业内部只要管理几个到几十个 Kubernetes 集群,那么我们为什么需要考虑管理如此庞大数量的 Kubernetes 集群?
首先,容器服务 ACK 是阿里云上的云产品,提供了 Kubernetes as a Service 的能力,面向全球客户,目前已经在全球 20 个地域支持;
其次,得益于云原生时代的发展,越来越多的企业拥抱 Kubernetes,Kubernetes 已经逐渐成为云原生时代的基础设施,成为 platform of platform。
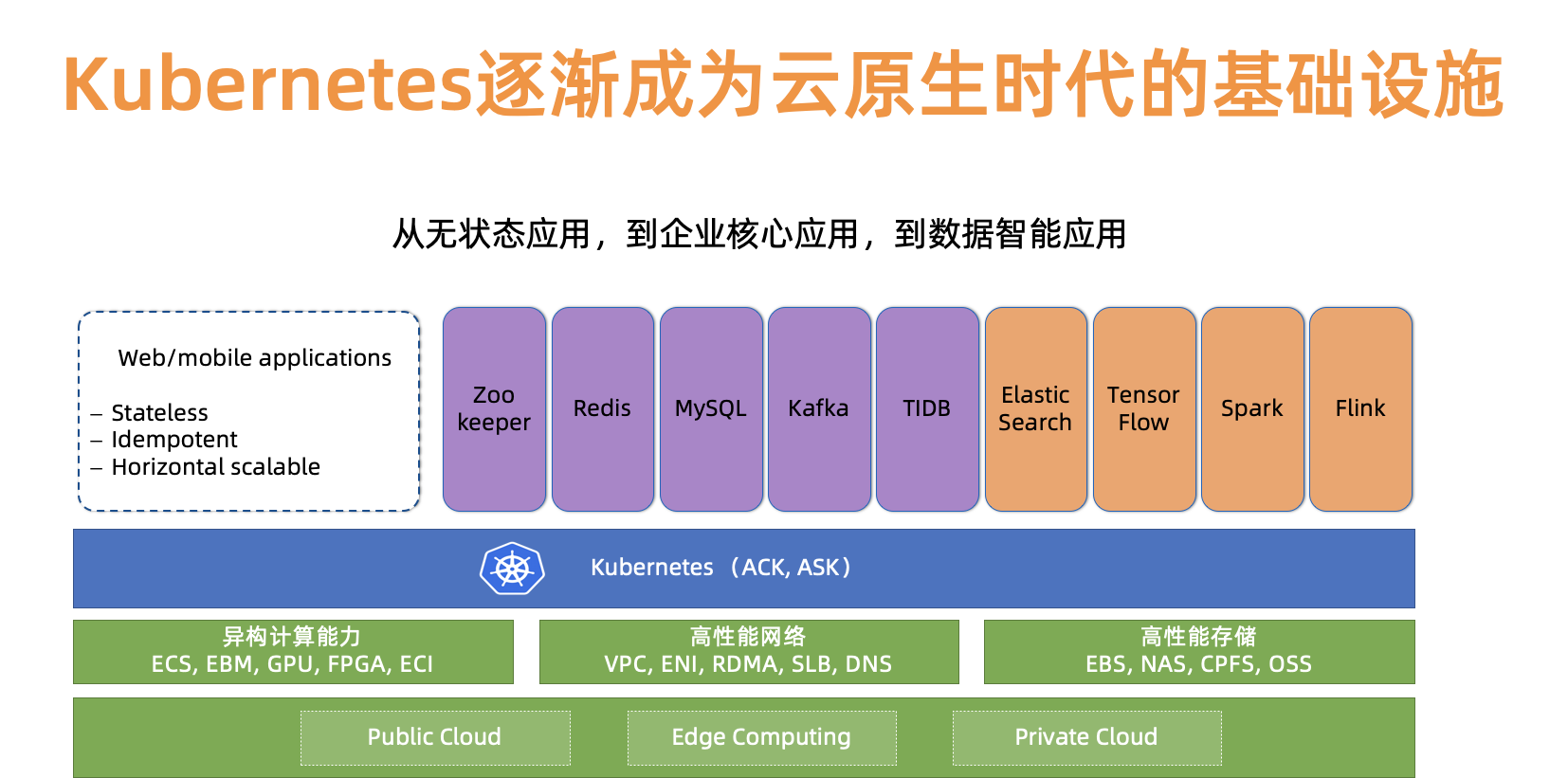
背景介绍
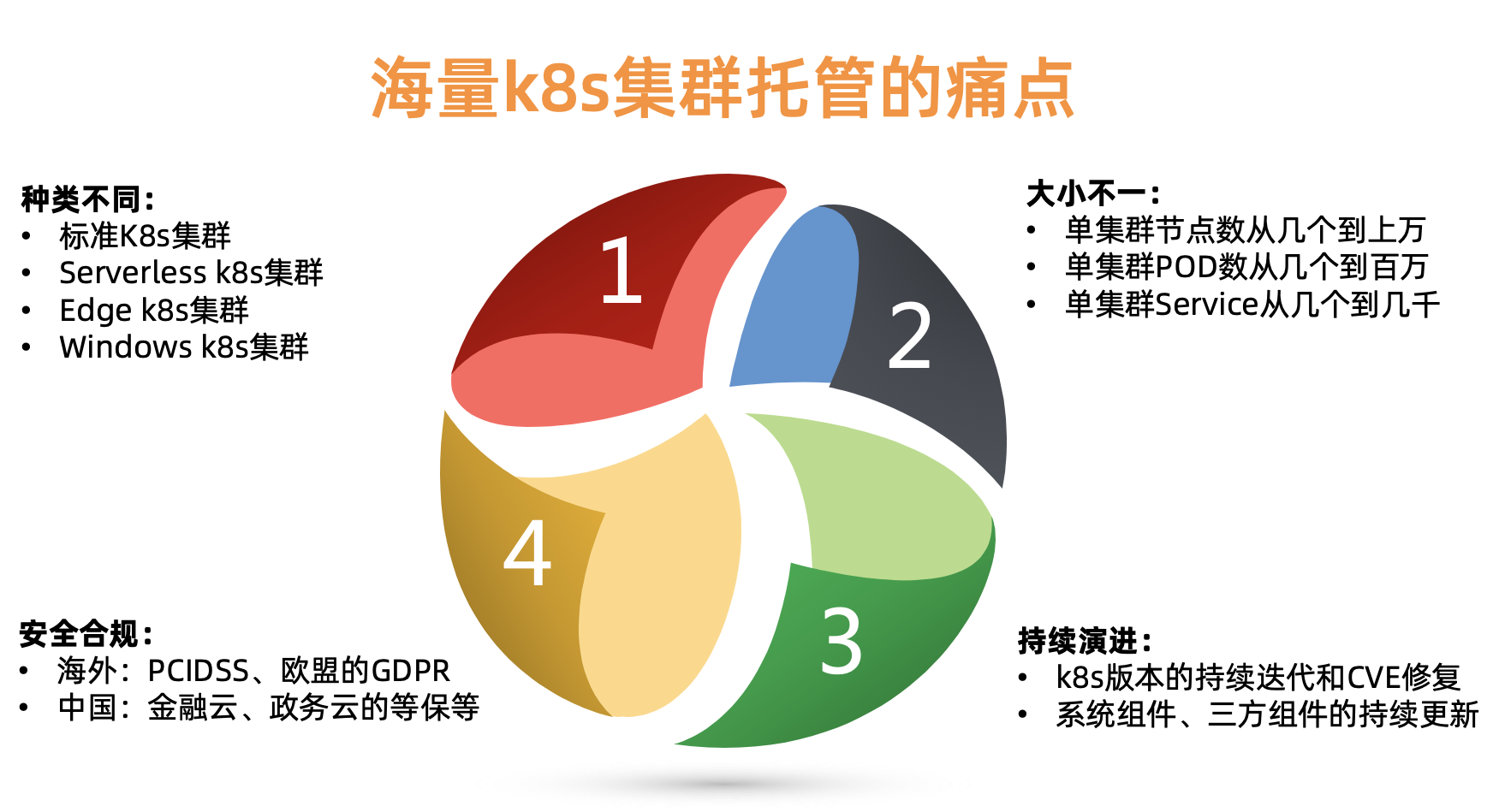
首先我们一起来看下托管这些 Kubernetes 集群的痛点:
1.集群种类不同:有标准的、无服务器的、AI 的、裸金属的、边缘、Windows 等 Kubernetes 集群。不同种类的集群参数、组件和托管要求不一样,并且需要支撑更多面向垂直场景的 Kubernetes;
2.集群大小不一:每个集群规模大小不一,从几个节点到上万个节点,从几个 service 到几千个 service 等,需要能够支撑每年持续几倍集群数量的增长;
3.集群安全合规:分布在不同的地域和环境的 Kubernetes 集群,需要遵循不同的合规性要求。比如欧洲的 Kubernetes 集群需要遵循欧盟的 GDPR 法案,在中国的金融业和政务云需要有额外的等级保护等要求;
4.集群持续演进:需要能够持续的支持 Kubernetes 的新版本新特性演进。
设计目标:
- 支持单元化的分档管理、容量规划和水位管理;
- 支持全球化的部署、发布、容灾和可观测性;
- 支持柔性架构的可插拔、可定制、积木式的持续演进能力。
1.支持单元化的分档管理、容量规划和水位管理
单元化
一般讲到单元化,大家都会联想到单机房容量不够或二地三中心灾备等场景。那单元化和 Kubernetes 管理有什么关系?
对我们来说,一个地域(比如:杭州)可能会管理几千个 Kubernetes,需要统一维护这些 Kubernetes 的集群生命周期管理。作为一个 Kubernetes 专业团队,一个朴素的想法就是通过多个 Kubernetes 元集群来管理这些 guest K8s master。而一个 Kubernetes 元集群的边界就是一个单元。
曾经我们经常听说某某机房光纤被挖断,某某机房电力因故障而导致服务中断,容器服务 ACK 在设计之初就支持了同城多活的架构形态,任何一个用户 Kubernetes 集群的 master 组件都会自动地分散在多个机房,不会因单机房问题而影响集群稳定性;另外一个层面,同时要保证 master 组件间的通信稳定性,容器服务 ACK 在打散 master 时调度策略上也会尽量保证 master 组件间通信延迟在毫秒级。
分档化
大家都知道,Kubernetes 集群的 master 组件的负载主要与 Kubernetes 集群的节点规模、worker 侧的 controller 或 workload 等需要与 kube-apiserver 交互的组件数量和调用频率息息相关,对于上万个 Kubernetes 集群,每个用户 Kubernetes 集群的规模和业务形态都千差万别,我们无法用一套标准配置来去管理所有的用户 Kubernetes 集群。
同时,从成本经济角度考虑,我们提供了一种更加灵活、更加智能的托管能力。考虑到不同资源类型会对 master 产生不同的负载压力,因此我们需要为每类资源设置不同的因子,最终可归纳出一个计算范式,通过此范式可计算出每个用户 Kubernetes 集群 master 所适应的档位。另外,我们也会基于已构建的 Kubernetes 统一监控平台实时指标来不断地优化和调整这些因素值和范式,从而可实现智能平滑换挡的能力。
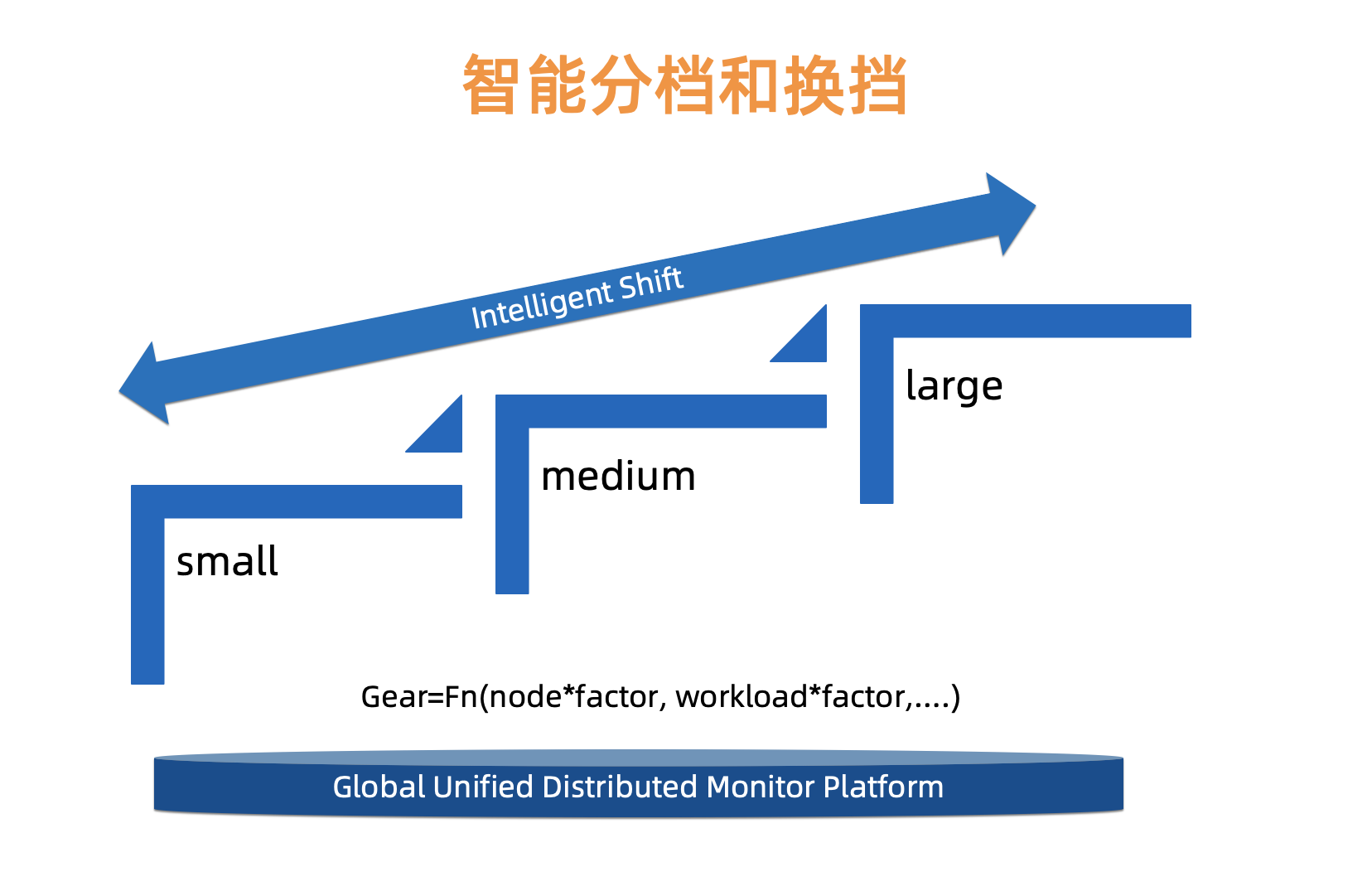
容量规划
接下来我们看下 Kubernetes 元集群的容量模型,单个元集群到底能托管多少个用户 Kubernetes 集群的 master?
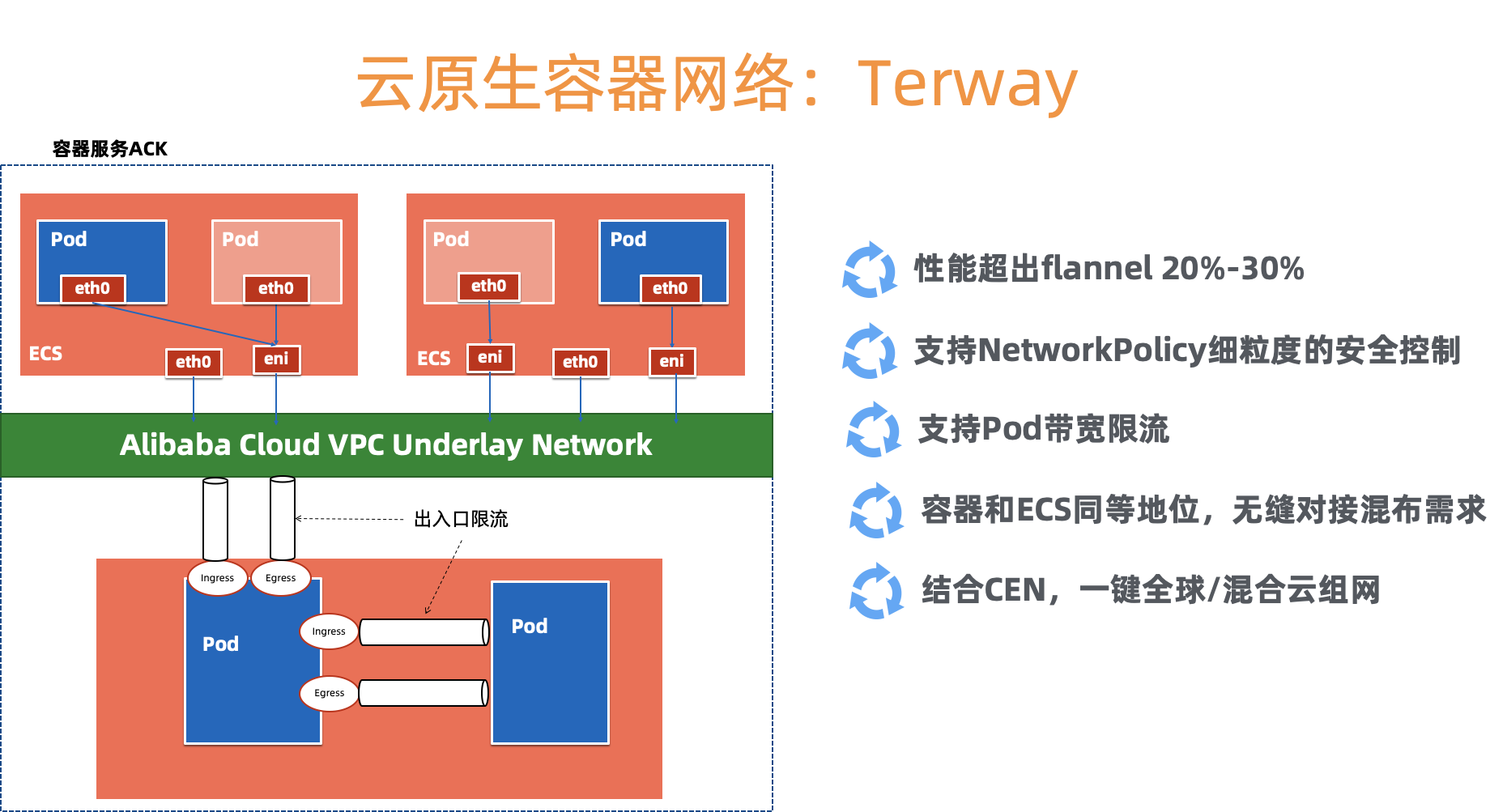
首先,要确认容器网络规划。这里我们选择了阿里云自研的高性能容器网络 Terway, 一方面需要通过弹性网卡 ENI 打通用户 VPC 和托管 master 的网络,另一方面提供了高性能和丰富的安全策略;
接下来,我们需要结合 VPC 内的 ip 资源,做网段的规划,分别提供给 node、pod 和 service。
最后,我们会结合统计规律,结合成本、密度、性能、资源配额、档位配比等多种因素的综合考量,设计每个元集群单元中部署的不同档位的 guest Kubernetes 的个数,并预留 40% 的水位。
2.支持全球化的部署、发布、容灾和可观测性
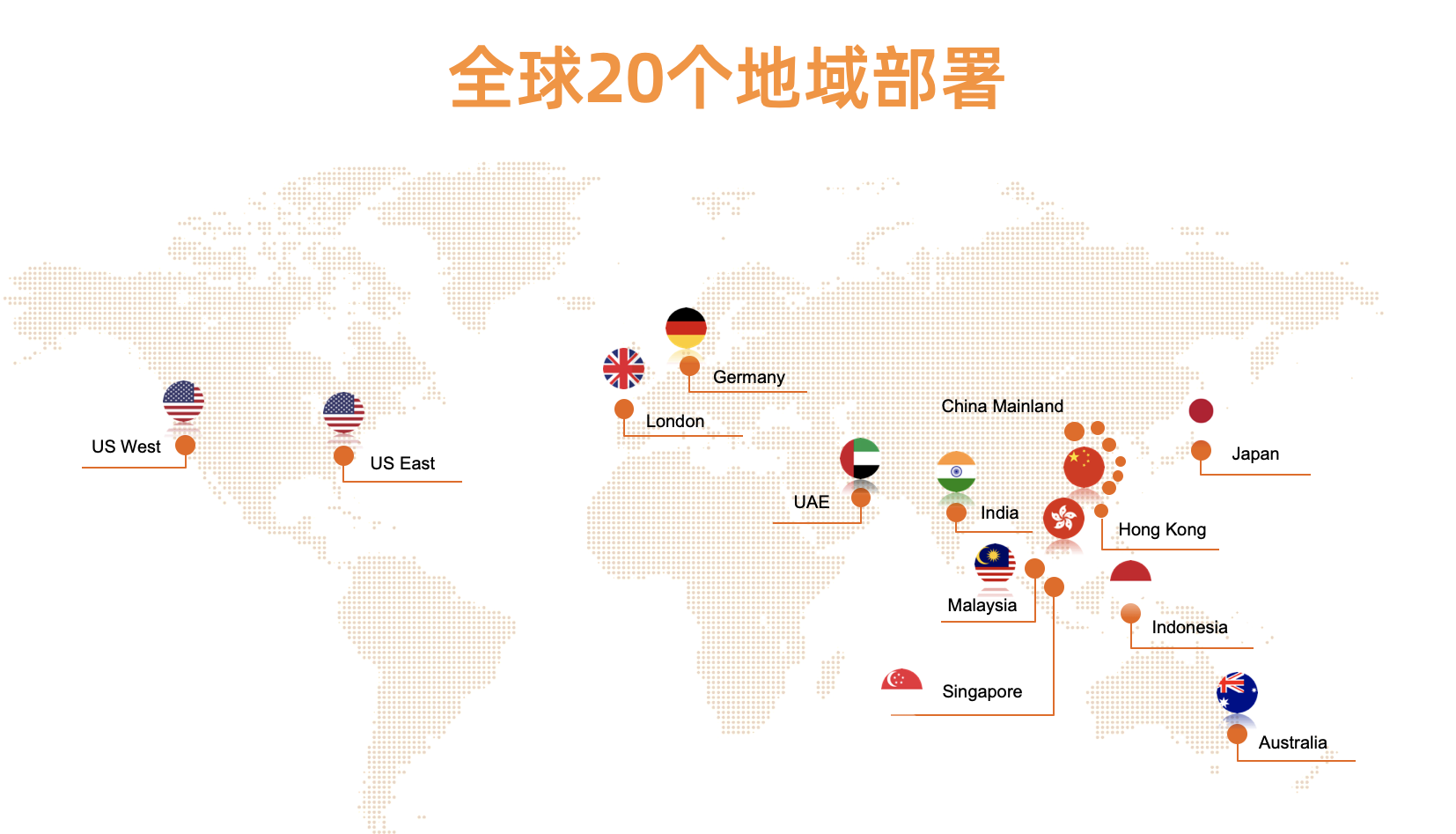
容器服务已经在全球 20 个地域支持,我们提供了完全自动化的部署、发布、容灾和可观测性能力,接下来将重点介绍全球化跨数据中心的可观测。
全球跨数据中心的可观测性
**全球化布局的大型集群的可观测性,对于 Kubernetes 集群的日常保障至关重要。如何在纷繁复杂的网络环境下高效、合理、安全、可扩展的采集各个数据中心中目标集群的实时状态指标,是可观测性设计的关键与核心。
我们需要兼顾区域化数据中心、单元化集群范围内可观测性数据的收集,以及全局视图的可观测性和可视化。基于这种设计理念和客观需求,全球化可观测性必须使用多级联合方式,也就是边缘层的可观测性实现下沉到需要观测的集群内部,中间层的可观测性用于在若干区域内实现监控数据的汇聚,中心层可观测性进行汇聚、形成全局化视图以及告警。
这样设计的好处在于可以灵活地在每一级别层内进行扩展以及调整,适合于不断增长的集群规模,相应的其他级别只需调整参数,层次结构清晰;网络结构简单,可以实现内网数据穿透到公网并汇聚。
针对该全球化布局的大型集群的监控系统设计,对于保障集群的高效运转至关重要,我们的设计理念是在全球范围内将各个数据中心的数据实时收集并聚合,实现全局视图查看和数据可视化,以及故障定位、告警通知。
进入云原生时代,Prometheus 作为 CNCF 第二个毕业的项目,天生适用于容器场景,Prometheus 与 Kubernetes 结合一起,实现服务发现和对动态调度服务的监控,在各种监控方案中具有很大的优势,实际上已经成为容器监控方案的标准,所以我们也选择了 Prometheus 作为方案的基础。
针对每个集群,需要采集的主要指标类别包括:
- OS 指标,例如节点资源(CPU, 内存,磁盘等)水位以及网络吞吐;
- 元集群以及用户集群 Kubernetes master 指标,例如 kube-apiserver, kube-controller-manager, kube-scheduler 等指标;
- Kubernetes 组件(kubernetes-state-metrics,cadvisor)采集的关于 Kubernetes 集群状态;
- etcd 指标,例如 etcd 写磁盘时间,DB size,Peer 之间吞吐量等等。
当全局数据聚合后,AlertManager 对接中心 Prometheus,驱动各种不同的告警通知行为,例如钉钉、邮件、短信等方式。
监控告警架构
为了合理地将监控压力负担分到多个层次的 Prometheus 并实现全局聚合,我们使用了联邦 Federation 的功能。在联邦集群中,每个数据中心部署单独的 Prometheus,用于采集当前数据中心监控数据,并由一个中心的 Prometheus 负责聚合多个数据中心的监控数据。
基于 Federation 的功能,我们设计的全球监控架构图如下,包括监控体系、告警体系和展示体系三部分。
监控体系按照从元集群监控向中心监控汇聚的角度,呈现为树形结构,可以分为三层:
- 边缘 Prometheus
为了有效监控元集群 Kubernetes 和用户集群 Kubernetes 的指标、避免网络配置的复杂性,将 Prometheus 下沉到每个元集群内。
- 级联 Prometheus
级联 Prometheus 的作用在于汇聚多个区域的监控数据。级联 Prometheus 存在于每个大区域,例如中国区、欧洲区、美洲区、亚洲区。每个大区域内包含若干个具体的区域,例如北京、上海、东京等。随着每个大区域内集群规模的增长,大区域可以拆分成多个新的大区域,并始终维持每个大区域内有一个级联 Prometheus,通过这种策略可以实现灵活的架构扩展和演进。
- 中心 Prometheus
中心 Prometheus 用于连接所有的级联 Prometheus,实现最终的数据聚合、全局视图和告警。为提高可靠性,中心 Prometheus 使用双活架构,也就是在不同可用区布置两个 Prometheus 中心节点,都连接相同的下一级 Prometheus。
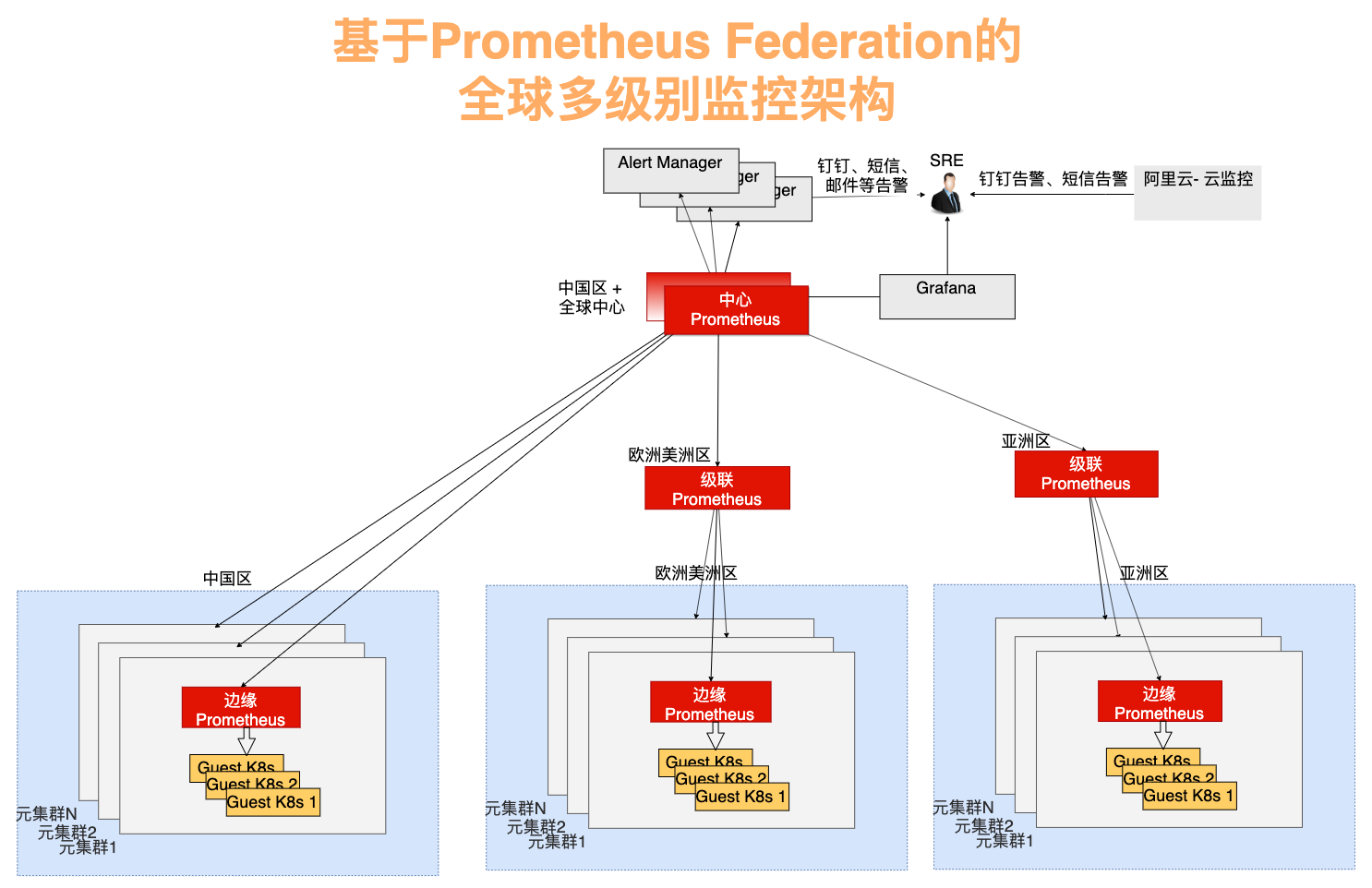
图2-1 基于 Prometheus Federation 的全球多级别监控架构
优化策略
1.监控数据流量与 API server 流量分离
API server 的代理功能可以使得 Kubernetes 集群外通过 API server 访问集群内的 Pod、Node 或者 Service。
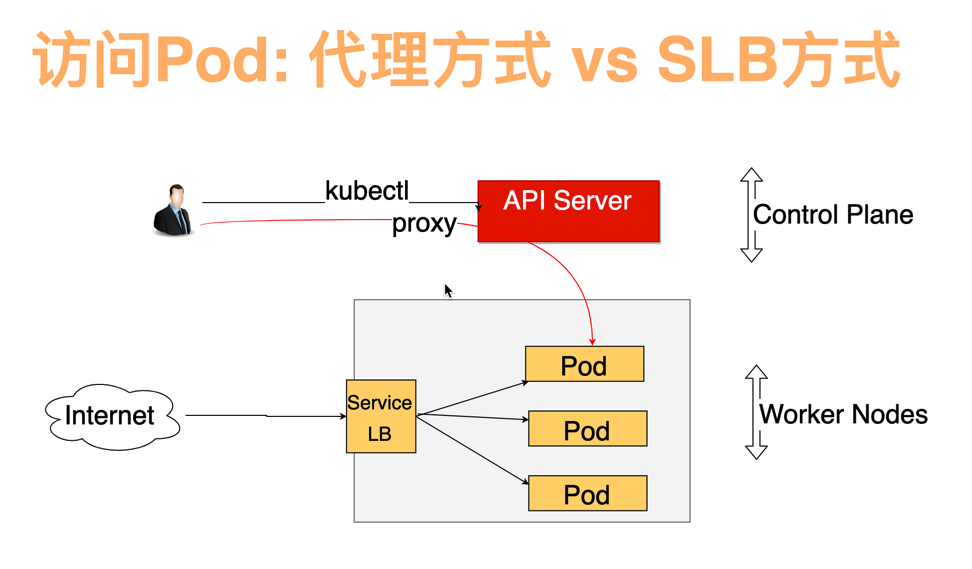
图3-1 通过 API Server 代理模式访问 Kubernetes 集群内的 Pod 资源
常用的透传 Kubernetes 集群内 Prometheus 指标到集群外的方式是通过 API server 代理功能,优点是可以重用 API server 的 6443 端口对外开放数据,管理简便;缺点也明显,增加了 API server 的负载压力。
如果使用 API Server 代理模式,考虑到客户集群以及节点都会随着售卖而不断扩大,对 API server 的压力也越来越大并增加了潜在的风险。对此,针对边缘 Prometheus 增加了 LoadBalancer 类型的 service,监控流量完全 LoadBalancer,实现流量分离。即便监控的对象持续增加,也保证了 API server 不会因此增加 Proxy 功能的开销。
2.收集指定 Metric
在中心 Prometheus 只收集需要使用的指标,一定不能全量抓取,否则会造成网络传输压力过大丢失数据。
3.Label 管理
Label 用于在级联 Prometheus 上标记 region 和元集群,所以在中心 Prometheus 汇聚是可以定位到元集群的颗粒度。同时,尽量减少不必要的 label,实现数据节省。
3.支持柔性架构的可插拔、可定制、积木式的持续演进能力
前面两部分简要描述了如何管理海量 Kubernetes 集群的一些思考,然而光做到全球化、单元化的管理还远远不够。Kubernetes 能够成功,包含了声明式的定义、高度活跃的社区、良好的架构抽象等因素,Kubernetes 已经成为云原生时代的 Linux。
我们必须要考虑 Kubernetes 版本的持续迭代和 CVE 漏洞的修复,必须要考虑 Kubernetes 相关组件的持续更新,无论是 CSI、CNI、Device Plugin 还是 Scheduler Plugin 等等。为此我们提供了完整的集群和组件的持续升级、灰度、暂停等功能。
组件可插拔
组件检查
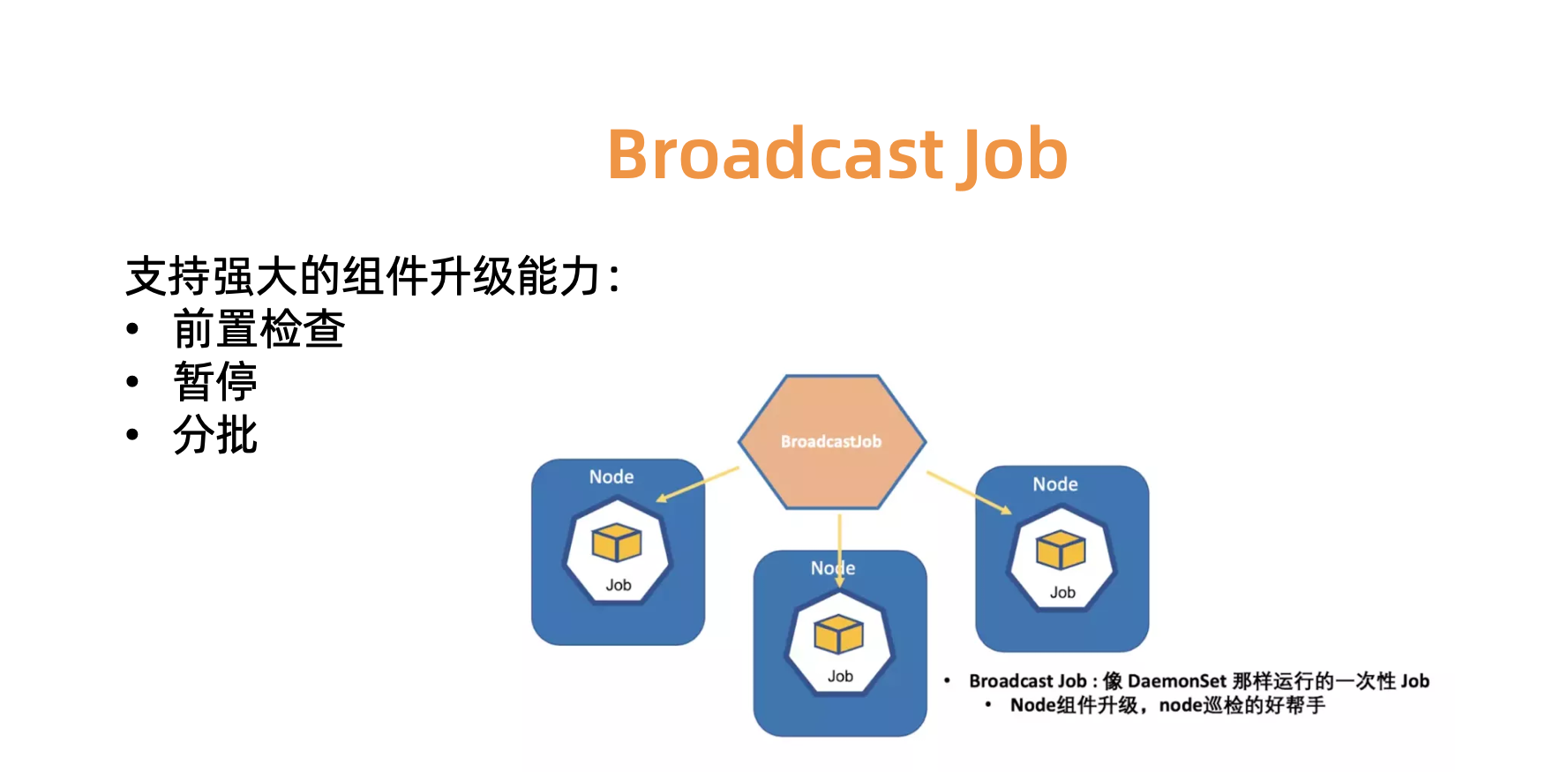
组件升级
2019 年 6 月,阿里巴巴将内部的云原生应用自动化引擎 OpenKruise 开源,这里我们重点介绍下其中的 BroadcastJob 功能,它非常适用于每台 worker 机器上的组件进行升级,或者对每台机器上的节点进行检测。(Broadcast Job 会在集群中每个 node 上面跑一个 pod 直至结束。类似于社区的 DaemonSet, 区别在于 DaemonSet 始终保持一个 pod 长服务在每个 node 上跑,而 BroadcastJob 中最终这个 pod 会结束。)
集群模板
此外,考虑不同 Kubernetes 使用场景,我们提供了多种 Kubernetes 的 cluster profile,可以方便用户进行更方便的集群选择。我们会结合大量集群的实践,持续提供更多更好的集群模板。

总结
随着云计算的发展,以 Kubernetes 为基础的云原生技术持续推动行业进行数字化转型。
容器服务 ACK 提供了安全稳定、高性能的 Kubernetes 托管服务,已经成为云上运行 Kubernetes 的最佳载体。在本次 双11,容器服务 ACK 在各个场景为 双11 做出贡献,支撑了阿里巴巴内部核心系统容器化上云,支撑了阿里云微服务引擎 MSE、视频云、CDN 等云产品,也支撑了 双11 的生态公司和 ISV 公司,包括聚石塔电商云、菜鸟物流云、东南亚的支付系统等等。
容器服务 ACK 会持续前行,持续提供更高更好的云原生容器网络、存储、调度和弹性能力、端到端的全链路安全能力、serverless 和 servicemesh 等能力。
有兴趣的开发者,可以前往阿里云控制台,创建一个 Kubernetes 集群来体验。同时也欢迎容器生态的合作伙伴加入阿里云的容器应用市场,和我们一起共创云原生时代。
本书亮点
- 双11 超大规模 K8s 集群实践中,遇到的问题及解决方法详述
- 云原生化最佳组合:Kubernetes+容器+神龙,实现核心系统 100% 上云的技术细节
- 双 11 Service Mesh 超大规模落地解决方案
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
更多相关信息,请关注“阿里巴巴云原生”。
阿里云上万个 Kubernetes 集群大规模管理实践的更多相关文章
- 配置阿里云SLB全站HTTPS集群
配置阿里云SLB全站HTTPS集群(以下内容仅为流程,信息可能有些对应不上) 1 登录阿里云购买两台实例 1.1 按量付费购买两台实例 1.2 配置网络可以不选择分配外网 1.3 自定义密码 1.4 ...
- 阿里巴巴大规模神龙裸金属 Kubernetes 集群运维实践
作者 | 姚捷(喽哥)阿里云容器平台集群管理高级技术专家 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击即可完成下载. 导读:值得阿里巴巴技术人骄傲的是 2019 ...
- 阿里云-容器服务之集群服务 k8s(Jenkins+gitlab+k8s的devops)- 01
由于docker官方停止更新Swarm,另外swarm在使用期间出现了很多bug,所以阿里云也在2019年7月发布公告:于2019年12月31日起停止技术支持,请您尽快迁移至容器服务Kubernete ...
- Kubernetes 集群无损升级实践 转至元数据结尾
一.背景 活跃的社区和广大的用户群,使 Kubernetes 仍然保持3个月一个版本的高频发布节奏.高频的版本发布带来了更多的新功能落地和 bug 及时修复,但是线上环境业务长期运行,任何变更出错都可 ...
- vivo 公司 Kubernetes 集群 Ingress 网关实践
文章转载自:https://mp.weixin.qq.com/s/qPqrJ3un1peeWgG9xO2m-Q 背景 vivo 人工智能计算平台小组从 2018 年底开始建设 AI 计算平台至今,已经 ...
- 多台云服务器的 Kubernetes 集群搭建
环境 两台或多台腾讯云服务器(本人搭建用了两台),都是 CentOs 7.6, master 节点:服务器为 4C8G,公网 IP:124.222.61.xxx node1节点:服务器为 4C4G,公 ...
- 阿里云构建Kafka单机集群环境
简介 在一台ECS阿里云服务器上构建Kafa单个集群环境需要如下的几个步骤: 服务器环境 JDK的安装 ZooKeeper的安装 Kafka的安装 1. 服务器环境 CPU: 1核 内存: 2048 ...
- 在阿里云上进行Docker集群的自动弹性伸缩
摘要: 在刚刚结束的云栖大会上,阿里云容器服务演示了容器的自动弹性伸缩,能够从容应对互联网应用的峰值流量.阿里云容器服务不仅支持容器级别的自动弹性伸缩,也支持集群节点级别的自动弹性伸缩.从而真正做到从 ...
- 阿里云服务器 进行zookeeper集群时候的肯!
首先我本地虚拟机 部署过N次没什么问题! 擦,上了云就启动后不能正常节点之间连接和发现! 这上面有手误 擦,吧编号的2 打成22 了,这个看下日志就解决了 重点是zoo.conf 中的IP进行配置时候 ...
随机推荐
- 省市区三级联动(vue)
vue项目中使用到三级联动,现在自己实现一个三级联动,仅供大家参考一下,直接上代码. <template> <section class="container"& ...
- 面向云原生的混沌工程工具-ChaosBlade
作者 | 肖长军(穹谷)阿里云智能事业群技术专家 导读:随着云原生系统的演进,如何保障系统的稳定性受到很大的挑战,混沌工程通过反脆弱思想,对系统注入故障,提前发现系统问题,提升系统的容错能力.Ch ...
- Android自定义控件:图形报表的实现(折线图、曲线图、动态曲线图)(View与SurfaceView分别实现图表控件)
图形报表很常用,因为展示数据比较直观,常见的形式有很多,如:折线图.柱形图.饼图.雷达图.股票图.还有一些3D效果的图表等. Android中也有不少第三方图表库,但是很难兼容各种各样的需求. 如果第 ...
- 谷歌黑客语法(google hacking)让你的搜索更精准有效
Google Hacking的含义原指利用Google Google搜索引擎搜索信息来进行入侵的技术和行为: 现指利用各种搜索引擎搜索信息来进行入侵的技术和行为,但我们也可以利用这个在互联网上更加便捷 ...
- 【IT教程-Oracle】尚观Oracle白金级入门教程
链接: https://pan.baidu.com/s/1GMncQN6mpgaH3hZQjGelaA 提取码: qu6j
- 程序员接私活经验总结,来自csdn论坛语录
以下为网上摘录,以做笔记: 可是到网上看看,似乎接私活也有很多不容易,技术问题本身是个因素,还有很多有技术的人接私活时被骗,或者是合作到最后以失败告终,所以想请有经验的大侠们出来指点一下,接私活是怎么 ...
- [2018-06-28] django项目 实例
实例一.显示一个基本的字符串在网页中 首先先进入views.py def home(request): string = u'随便写' return render(request, 'home.htm ...
- Promise A+ 规范【中文版】
0. 前言 本文为Promise A+规范的中文译文,Promise A+规范英文版原文链接:Promise A+. 正文如下: 一个开放.健全且通用的 JavaScript Promise 标准.由 ...
- CSP-S 46 题解
改完题了,就稍写一下题解,顺便反思一下! 其实这次考试挺水的,然而我也挺水的,看了考试结束后的成绩,就吃-*了! T1 set 这个我考试的时候实在是没有想到如何去判断-1,然后我就觉得这神仙题没法解 ...
- 2. 彤哥说netty系列之IO的五种模型
你好,我是彤哥,本篇是netty系列的第二篇. 欢迎来我的公从号彤哥读源码系统地学习源码&架构的知识. 简介 本文将介绍linux中的五种IO模型,同时也会介绍阻塞/非阻塞与同步/异步的区别. ...