Spark学习之路(十一)—— Spark SQL 聚合函数 Aggregations
一、简单聚合
1.1 数据准备
// 需要导入spark sql内置的函数包
import org.apache.spark.sql.functions._
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
// 注册为临时视图,用于后面演示SQL查询
empDF.createOrReplaceTempView("emp")
empDF.show()
注:emp.json可以从本仓库的resources目录下载。
1.2 count
// 计算员工人数
empDF.select(count("ename")).show()
1.3 countDistinct
// 计算姓名不重复的员工人数
empDF.select(countDistinct("deptno")).show()
1.4 approx_count_distinct
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用approx_count_distinct函数,并可以使用第二个参数指定最大允许误差。
empDF.select(approx_count_distinct ("ename",0.1)).show()
1.5 first & last
获取DataFrame中指定列的第一个值或者最后一个值。
empDF.select(first("ename"),last("job")).show()
1.6 min & max
获取DataFrame中指定列的最小值或者最大值。
empDF.select(min("sal"),max("sal")).show()
1.7 sum & sumDistinct
求和以及求指定列所有不相同的值的和。
empDF.select(sum("sal")).show()
empDF.select(sumDistinct("sal")).show()
1.8 avg
内置的求平均数的函数。
empDF.select(avg("sal")).show()
1.9 数学函数
Spark SQL中还支持多种数学聚合函数,用于通常的数学计算,以下是一些常用的例子:
// 1.计算总体方差、均方差、总体标准差、样本标准差
empDF.select(var_pop("sal"), var_samp("sal"), stddev_pop("sal"), stddev_samp("sal")).show()
// 2.计算偏度和峰度
empDF.select(skewness("sal"), kurtosis("sal")).show()
// 3. 计算两列的皮尔逊相关系数、样本协方差、总体协方差。(这里只是演示,员工编号和薪资两列实际上并没有什么关联关系)
empDF.select(corr("empno", "sal"), covar_samp("empno", "sal"),covar_pop("empno", "sal")).show()
1.10 聚合数据到集合
scala> empDF.agg(collect_set("job"), collect_list("ename")).show()
输出:
+--------------------+--------------------+
| collect_set(job)| collect_list(ename)|
+--------------------+--------------------+
|[MANAGER, SALESMA...|[SMITH, ALLEN, WA...|
+--------------------+--------------------+
二、分组聚合
2.1 简单分组
empDF.groupBy("deptno", "job").count().show()
//等价SQL
spark.sql("SELECT deptno, job, count(*) FROM emp GROUP BY deptno, job").show()
输出:
+------+---------+-----+
|deptno| job|count|
+------+---------+-----+
| 10|PRESIDENT| 1|
| 30| CLERK| 1|
| 10| MANAGER| 1|
| 30| MANAGER| 1|
| 20| CLERK| 2|
| 30| SALESMAN| 4|
| 20| ANALYST| 2|
| 10| CLERK| 1|
| 20| MANAGER| 1|
+------+---------+-----+
2.2 分组聚合
empDF.groupBy("deptno").agg(count("ename").alias("人数"), sum("sal").alias("总工资")).show()
// 等价语法
empDF.groupBy("deptno").agg("ename"->"count","sal"->"sum").show()
// 等价SQL
spark.sql("SELECT deptno, count(ename) ,sum(sal) FROM emp GROUP BY deptno").show()
输出:
+------+----+------+
|deptno|人数|总工资|
+------+----+------+
| 10| 3|8750.0|
| 30| 6|9400.0|
| 20| 5|9375.0|
+------+----+------+
三、自定义聚合函数
Scala提供了两种自定义聚合函数的方法,分别如下:
- 有类型的自定义聚合函数,主要适用于DataSet;
- 无类型的自定义聚合函数,主要适用于DataFrame。
以下分别使用两种方式来自定义一个求平均值的聚合函数,这里以计算员工平均工资为例。两种自定义方式分别如下:
3.1 有类型的自定义函数
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
// 1.定义员工类,对于可能存在null值的字段需要使用Option进行包装
case class Emp(ename: String, comm: scala.Option[Double], deptno: Long, empno: Long,
hiredate: String, job: String, mgr: scala.Option[Long], sal: Double)
// 2.定义聚合操作的中间输出类型
case class SumAndCount(var sum: Double, var count: Long)
/* 3.自定义聚合函数
* @IN 聚合操作的输入类型
* @BUF reduction操作输出值的类型
* @OUT 聚合操作的输出类型
*/
object MyAverage extends Aggregator[Emp, SumAndCount, Double] {
// 4.用于聚合操作的的初始零值
override def zero: SumAndCount = SumAndCount(0, 0)
// 5.同一分区中的reduce操作
override def reduce(avg: SumAndCount, emp: Emp): SumAndCount = {
avg.sum += emp.sal
avg.count += 1
avg
}
// 6.不同分区中的merge操作
override def merge(avg1: SumAndCount, avg2: SumAndCount): SumAndCount = {
avg1.sum += avg2.sum
avg1.count += avg2.count
avg1
}
// 7.定义最终的输出类型
override def finish(reduction: SumAndCount): Double = reduction.sum / reduction.count
// 8.中间类型的编码转换
override def bufferEncoder: Encoder[SumAndCount] = Encoders.product
// 9.输出类型的编码转换
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
object SparkSqlApp {
// 测试方法
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Spark-SQL").master("local[2]").getOrCreate()
import spark.implicits._
val ds = spark.read.json("file/emp.json").as[Emp]
// 10.使用内置avg()函数和自定义函数分别进行计算,验证自定义函数是否正确
val myAvg = ds.select(MyAverage.toColumn.name("average_sal")).first()
val avg = ds.select(functions.avg(ds.col("sal"))).first().get(0)
println("自定义average函数 : " + myAvg)
println("内置的average函数 : " + avg)
}
}
自定义聚合函数需要实现的方法比较多,这里以绘图的方式来演示其执行流程,以及每个方法的作用:
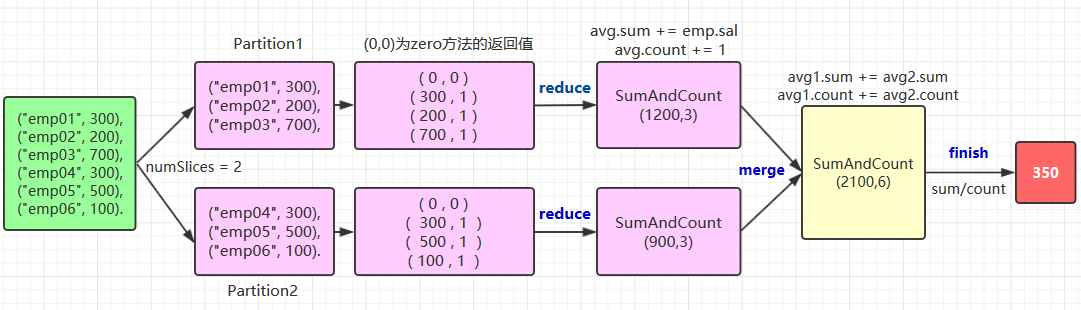
关于zero,reduce,merge,finish方法的作用在上图都有说明,这里解释一下中间类型和输出类型的编码转换,这个写法比较固定,基本上就是两种情况:
- 自定义类型Case Class或者元组就使用
Encoders.product方法; - 基本类型就使用其对应名称的方法,如
scalaByte,scalaFloat,scalaShort等,示例如下:
override def bufferEncoder: Encoder[SumAndCount] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
3.2 无类型的自定义聚合函数
理解了有类型的自定义聚合函数后,无类型的定义方式也基本相同,代码如下:
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
object MyAverage extends UserDefinedAggregateFunction {
// 1.聚合操作输入参数的类型,字段名称可以自定义
def inputSchema: StructType = StructType(StructField("MyInputColumn", LongType) :: Nil)
// 2.聚合操作中间值的类型,字段名称可以自定义
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("MyCount", LongType) :: Nil)
}
// 3.聚合操作输出参数的类型
def dataType: DataType = DoubleType
// 4.此函数是否始终在相同输入上返回相同的输出,通常为true
def deterministic: Boolean = true
// 5.定义零值
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// 6.同一分区中的reduce操作
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 7.不同分区中的merge操作
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 8.计算最终的输出值
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
object SparkSqlApp {
// 测试方法
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Spark-SQL").master("local[2]").getOrCreate()
// 9.注册自定义的聚合函数
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("file/emp.json")
df.createOrReplaceTempView("emp")
// 10.使用自定义函数和内置函数分别进行计算
val myAvg = spark.sql("SELECT myAverage(sal) as avg_sal FROM emp").first()
val avg = spark.sql("SELECT avg(sal) as avg_sal FROM emp").first()
println("自定义average函数 : " + myAvg)
println("内置的average函数 : " + avg)
}
}
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(十一)—— Spark SQL 聚合函数 Aggregations的更多相关文章
- Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- SQL 聚合函数
SQL聚合函数 MAX---最大值 MIN--最小值 AVG--平均值 SUM--求和 COUNT--记录的条数 EXample: --从MyStudent表中查询最大年龄,最小年龄,平均年龄,年龄的 ...
- SQL Server数据库--》top关键字,order by排序,distinct去除重复记录,sql聚合函数,模糊查询,通配符,空值处理。。。。
top关键字:写在select后面 字段的前面 比如你要显示查询的前5条记录,如下所示: select top 5 * from Student 一般情况下,top是和order by连用的 orde ...
- Spark学习之路 (十九)SparkSQL的自定义函数UDF
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (十九)SparkSQL的自定义函数UDF[转]
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
随机推荐
- Linux(Centos7)下自动启动程序
1.文件转移 先将要执行的文件转移或复制到路径较短的地方如:/usr/local 主要是为了方便,同时防止误删.2.编写Service文件 $ vim /usr/lib/systemd/system/ ...
- DDD实战9 经销商领域上下文
1.创建Dealer.Domain 类库项目 2.创建实体和值对象 3.安装ef的包 4.创建上下文接口(IDealerContext)之所以要创建上下文接口,是为了可替换,在其他项目总使用接口,当需 ...
- 追本溯源 —— 句型、表达、模式,pattern,著名的话
** 时候,做了 ** 事,是我 **,做得最对的一件事: "Winning that ticket was the best thing that ever happened to me& ...
- 在Expression Blend中制作侧面为梯形的类棱柱体
原文:在Expression Blend中制作侧面为梯形的类棱柱体 在上一篇"在WPF设计工具Blend2中制作立方体图片效果"( http://blog.csdn.net/joh ...
- objective-c启用ARC时的内存管理
PDF版下载:http://download.csdn.net/detail/cuibo1123/7443125 在objective-c中,内存的引用计数一直是一个让人比較头疼的问题.尤其 ...
- Emgu-WPF 激光雷达研究-移动物体跟踪2
原文:Emgu-WPF 激光雷达研究-移动物体跟踪2 初步实现了去燥跟踪,并用圆点标注障碍物 https://blog.csdn.net/u013224722/article/details/8078 ...
- InitializeComponent无法识别的问题
学习Xamarin官方文档的时候,Xamarin.Forms的开始篇一直在用ContentPage讲解自己一直是创建Page,然后手动修改成继承于ContentPage,然后InitializeCom ...
- XF 表视图添加和删除行
using System;using Xamarin.Forms;using Xamarin.Forms.Xaml; [assembly: XamlCompilation (XamlCompilati ...
- NUGET源不存在,安装Nuget包提示“本地源不存在”
困扰了两天的问题,终于找到原因了.因此来这里记录一下~ 前两天写项目时,要从NUGET上安装个第三方库,但不管是从可视化的管理器还是管理器控制台安装,都提示“本地源‘*******’不存在”.然后到网 ...
- Qt 事件处理 快捷键(重写eventFilter的函数,使用Qt::ControlModifier判断)
CTRL+Enter发送信息的实现 在现在的即时聊天程序中,一般都设置有快捷键来实现一些常用的功能,类似QQ可以用CTRL+Enter来实现信息的发送. 在QT4中,所有的事件都继承与QEvent这个 ...