百万年薪python之路 -- socket粘包问题解决
socket粘包问题解决
1. 高大上版解决粘包方式(自定制包头)
整体的流程解释
整个流程的大致解释:
我们可以把报头做成字典,字典里包含将要发送的真实数据的描述信息(大小啊之类的),然后json序列化,然后用struck将序列化后的数据长度打包成4个字节。
我们在网络上传输的所有数据 都叫做数据包,数据包里的所有数据都叫做报文,报文里面不止有你的数据,还有ip地址、mac地址、端口号等等,其实所有的报文都有报头,这个报头是协议规定的,看一下
发送时:
先发报头长度
再编码报头内容然后发送
最后发真实内容
接收时:
先手报头长度,用struct取出来
根据取出的长度收取报头内容,然后解码,反序列化
从反序列化的结果中取出待取数据的描述信息,然后去取真实的数据内容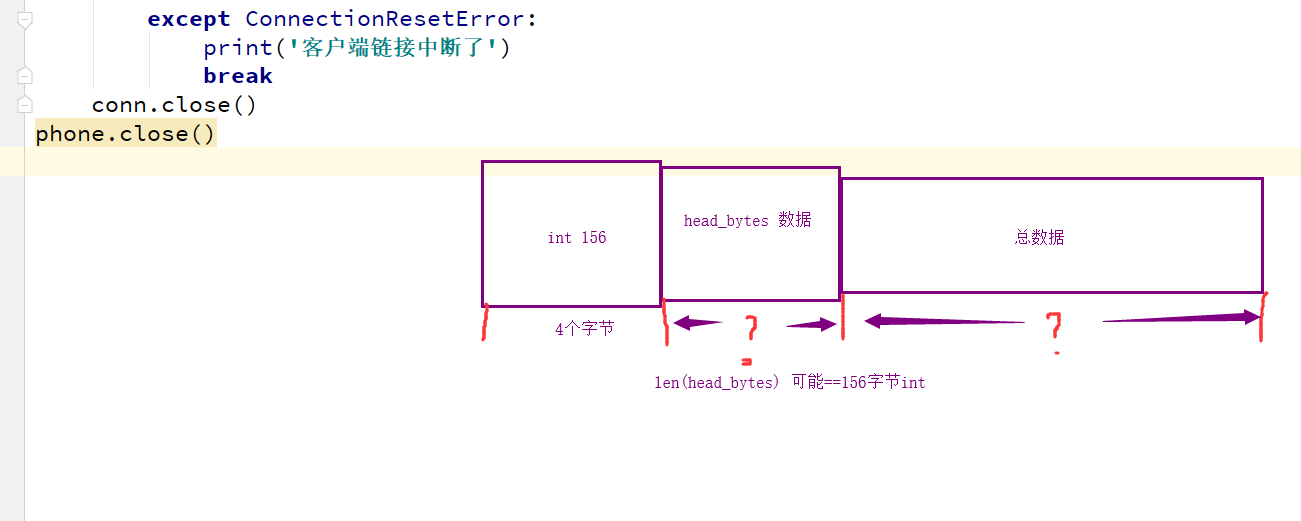

server端
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.bind(('127.0.0.1', 8080))
phone.listen(5)
while 1:
conn, client_addr = phone.accept()
print(client_addr)
while 1:
try:
cmd = conn.recv(1024)
ret = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
correct_msg = ret.stdout.read()
error_msg = ret.stderr.read()
# 1 制作固定报头
total_size = len(correct_msg) + len(error_msg)
header_dict = {
'md5': 'fdsaf2143254f',
'file_name': 'f1.txt',
'total_size':total_size,
}
header_dict_json = json.dumps(header_dict) # str
bytes_headers = header_dict_json.encode('utf-8')
header_size = len(bytes_headers)
header = struct.pack('i', header_size)
# 2 发送报头长度
conn.send(header)
# 3 发送报头
conn.send(bytes_headers)
# 4 发送真实数据:
conn.send(correct_msg)
conn.send(error_msg)
except ConnectionResetError:
break
conn.close()
phone.close()client端
import socket
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8080))
while 1:
cmd = input('>>>').strip()
if not cmd: continue
phone.send(cmd.encode('utf-8'))
# 1,接收固定报头
header_size = struct.unpack('i', phone.recv(4))[0]
# 2,解析报头长度
header_bytes = phone.recv(header_size)
header_dict = json.loads(header_bytes.decode('utf-8'))
# 3,收取报头
total_size = header_dict['total_size']
# 3,根据报头信息,接收真实数据
recv_size = 0
res = b''
while recv_size < total_size:
recv_data = phone.recv(1024)
res += recv_data
recv_size += len(recv_data)
print(res.decode('gbk'))
phone.close()网络编程作业
加粗的是必须要做的,倾斜的是比较有难度的,大家别放松呀。
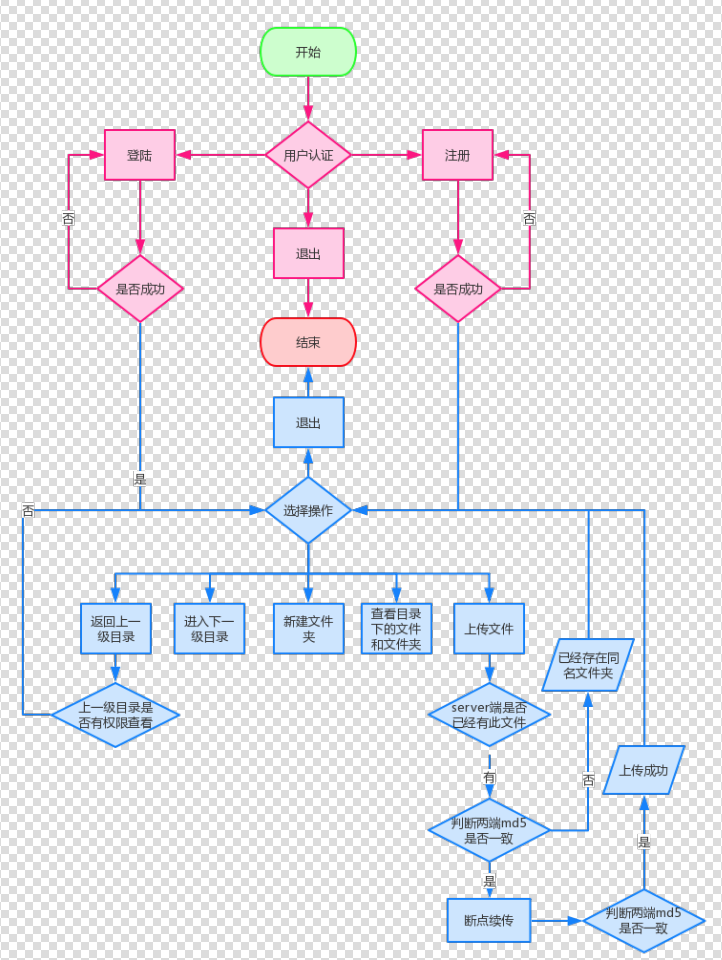
1. 多用户同时登陆
2. 用户登陆,加密认证
3. 上传/下载文件,保证文件一致性
4. 传输过程中现实进度条
5. 不同用户家目录不同,且只能访问自己的家目录
6. 对用户进行磁盘配额、不同用户配额可不同
7. 用户登陆server后,可在家目录权限下切换子目录
8. 查看当前目录下文件,新建文件夹
9. 删除文件和空文件夹
10. 充分使用面向对象知识
11. 支持断点续传
简单分析一下实现方式:
1.字符串操作以及打印 —— 实现上传下载的进度条功能
2.socketserver —— 实现ftp server端和client端的交互
3.struct模块 —— 自定制报头解决文件上传下载过程中的粘包问题
4.hashlib或者hmac模块 —— 实现文件的一致性校验和用户密文登录
5.os模块 —— 实现目录的切换及查看文件文件夹等功能
6.文件操作 —— 完成上传下载文件及断点续传等功能
看一下流程图:
2. 基于UDP协议的socket通信
UDP协议下的socket
udp是无链接的,先启动哪一端都不会报错
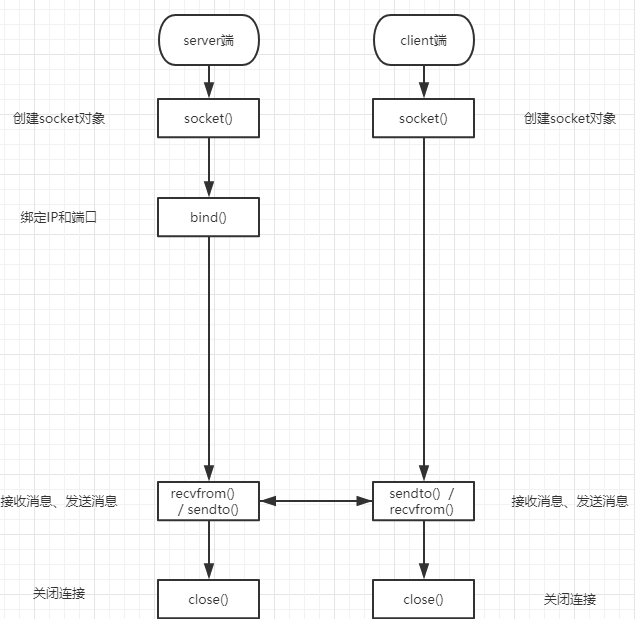
UDP下的socket通讯流程
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),recvform接收消息,这个消息有两项,消息内容和对方客户端的地址,然后回复消息时也要带着你收到的这个客户端的地址,发送回去,最后关闭连接,一次交互结束
服务端
import socket
udp_sk = socket.socket(type=socket.SOCK_DGRAM) #创建一个服务器的套接字
udp_sk.bind(('127.0.0.1',8080)) #绑定服务器套接字
msg,addr = udp_sk.recvfrom(1024)
print(msg)
udp_sk.sendto(b'hi',addr) # 对话(接收与发送)
udp_sk.close() # 关闭服务器套接字客户端
import socket
ip_port=('127.0.0.1',8080)
udp_sk=socket.socket(type=socket.SOCK_DGRAM)
udp_sk.sendto(b'hello',ip_port)
back_msg,addr=udp_sk.recvfrom(1024)
print(back_msg.decode('utf-8'),addr)初版qq聊天
服务端
#_*_coding:utf-8_*_
import socket
ip_port=('127.0.0.1',8081)
udp_server_sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) #DGRAM:datagram 数据报文的意思,象征着UDP协议的通信方式
udp_server_sock.bind(ip_port)#你对外提供服务的端口就是这一个,所有的客户端都是通过这个端口和你进行通信的
while True:
qq_msg,addr=udp_server_sock.recvfrom(1024)# 阻塞状态,等待接收消息
print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],qq_msg.decode('utf-8')))
back_msg=input('回复消息: ').strip()
udp_server_sock.sendto(back_msg.encode('utf-8'),addr)客户端
import socket
BUFSIZE=1024
udp_client_socket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
qq_name_dic={
'taibai':('127.0.0.1',8081),
'Jedan':('127.0.0.1',8081),
'Jack':('127.0.0.1',8081),
'John':('127.0.0.1',8081),
}
while True:
qq_name=input('请选择聊天对象: ').strip()
while True:
msg=input('请输入消息,回车发送,输入q结束和他的聊天: ').strip()
if msg == 'q':break
if not msg or not qq_name or qq_name not in qq_name_dic:continue
udp_client_socket.sendto(msg.encode('utf-8'),qq_name_dic[qq_name])# 必须带着自己的地址,这就是UDP不一样的地方,不需要建立连接,但是要带着自己的地址给服务端,否则服务端无法判断是谁给我发的消息,并且不知道该把消息回复到什么地方,因为我们之间没有建立连接通道
back_msg,addr=udp_client_socket.recvfrom(BUFSIZE)# 同样也是阻塞状态,等待接收消息
print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],back_msg.decode('utf-8')))
udp_client_socket.close()自制时间服务器的代码示例:
服务端
from socket import *
from time import strftime
import time
ip_port = ('127.0.0.1', 9000)
bufsize = 1024
udp_server = socket(AF_INET, SOCK_DGRAM)
udp_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
udp_server.bind(ip_port)
while True:
msg, addr = udp_server.recvfrom(bufsize)
print('===>', msg)
stru_time = time.localtime() #当前的结构化时间
if not msg:
time_fmt = '%Y-%m-%d %X'
else:
time_fmt = msg.decode('utf-8')
back_msg = strftime(time_fmt,stru_time)
print(back_msg,type(back_msg))
udp_server.sendto(back_msg.encode('utf-8'), addr)
tcp_server.close()客户端
from socket import *
ip_port=('127.0.0.1',9000)
bufsize=1024
udp_client=socket(AF_INET,SOCK_DGRAM)
while True:
msg=input('请输入时间格式(例%Y %m %d)>>: ').strip()
udp_client.sendto(msg.encode('utf-8'),ip_port)
data=udp_client.recv(bufsize)
print('当前日期:',str(data,encoding='utf-8'))百万年薪python之路 -- socket粘包问题解决的更多相关文章
- 百万年薪python之路 -- socket()模块的用法
socket()模块的用法: import socket socket.socket(socket_family,socket_type,protocal=0) socket_family 可以是 A ...
- 百万年薪python之路 -- Socket
Socket 1. 为什么学习socket 你自己现在完全可以写一些小程序了,但是前面的学习和练习,我们写的代码都是在自己的电脑上运行的,虽然我们学过了模块引入,文件引入import等等,我可以在程序 ...
- socket粘包问题解决
粘包client.send(data1)client.send(data2)这两次send紧挨在一起,处理的时候会放在一起发过去在Linux里每次都粘包,Windows里面某次会出现粘包在两次send ...
- python之路--subprocess,粘包现象与解决办法,缓冲区
一. subprocess 的简单用法 import subprocess sub_obj = subprocess.Popen( 'dir', #系统指令 shell=True, #固定方法 std ...
- python网络编程-socket“粘包”(小数据发送问题)
一:什么是粘包 “粘包”, 即服务器端你调用时send 2次,但你send调用时,数据其实并没有立刻被发送给客户端,而是放到了系统的socket发送缓冲区里,等缓冲区满了.或者数据等待超时了,数据才会 ...
- 百万年薪python之路 -- 包
包 使用import 和from xx import xx 现有如下结构 bake ├── __init__.py ├── api ├── __init__.py ├── policy.py └── ...
- 百万年薪python之路 -- 数据库初始
一. 数据库初始 1. 为什么要有数据库? 先来一个场景: 假设现在你已经是某大型互联网公司的高级程序员,让你写一个火车票购票系统,来hold住十一期间全国的购票需求,你怎么写? 由于在同一时 ...
- 百万年薪python之路 -- 并发编程之 协程
协程 一. 协程的引入 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两 ...
- 百万年薪python之路 -- MySQL数据库之 Navicat工具和pymysql模块
一. IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navicat工具,这个工具本质上就是一个socket客户端,可视化的连接 ...
随机推荐
- Kubernetes学习之应用部署变迁
从物理单机.虚拟化(容器化)到云原生 历史 云原生 ---初期 总结
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
- jenkins构建maven项目:找不到本地依赖包的解决办法
前言: 我们在构建maven项目时,常常会用到一些特殊的jar包(不能在中央仓库中直接下载到本地仓库如微软不允许以maven的方式直接下载com.microsoft.sqlserver:sqljdbc ...
- JAVA Atm测试实验心得
通过一个假期的自学,完成了老师布置的样卷任务.使用Escipse编写一个学生成绩的管理系统. 一开始两眼摸黑,通过观看Java课程的视频,地址:https://www.bilibili.com/vid ...
- 使用servlet+jdbc+MD5实现用户加密登录
/** * 分析流程: * 1.前端页面提交登录请求 * 2.被web.xml拦截,进入到LoginServlet(有两种方式:方式一,在web.xml文件中配置servlet拦截器;方式二,不用在w ...
- MariaDB简单操作
RHEL7之后操作系统带的数据库都是mariadb,跟mysql一样用 1.安装客户端和服务端 [root@localhost ~]# yum install mariadb mariadb-serv ...
- 无法导入要素类到SDE中
我遇到的原因的表空间不足(并且表空间没有设置为自动增长) 首先通过SELECT FILE_NAME, TABLESPACE_NAME, AUTOEXTENSIBLE FROM DBA_DATA_FIL ...
- vue中"‘webpack-dev-server’不是内部或外部命令,也不是可运行的程序"的报错
在vue项目中发现了这个报错 解决办法将项目里的“node_modules”文件夹删除,然后重新运行cnpm install
- docker 更新后出现 error during connect
docker更新后出现 error during connect: Get http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.39/containers/json: o ...
- Docker学习1-CentOS 7安装Docker
前言 docker 是一个开源的应用容器引擎,基于 Go语言 并遵从Apache2.0协议开源. docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何流行的 ...