Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了《糗事百科》的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy。
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图
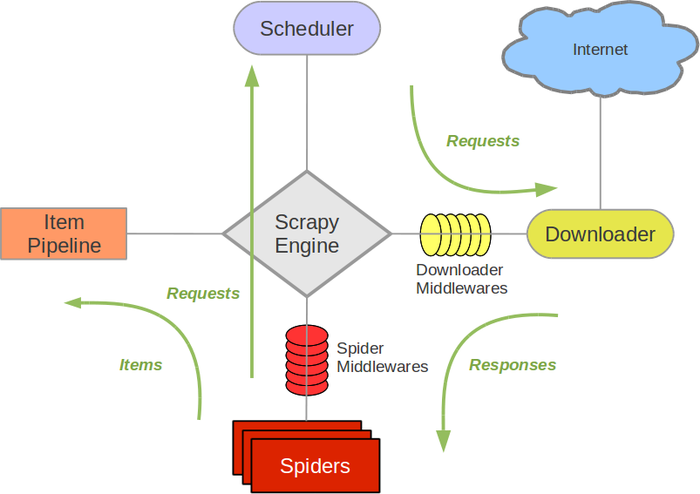
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
我们可以通过 pip install scrapy 进行 scrapy 框架的下载安装。
接下来我们就来创建一个简单的爬虫目录并对其中的目录结构进行说明。
首先我们进入我们的工作目录,然后在终端运行 scrapy startproject qiushi ,这样我们就创建了一个叫 qiushi 的基于 scrapy 框架构建的爬虫项目,目录结构如下:
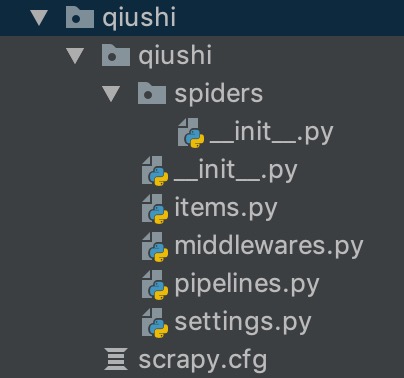
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
qiushi/ :项目的Python模块,将会从这里引用代码
qiushi/items.py :项目的目标文件
qiushi/middlewares/ :项目的中间件
qiushi/pipelines.py :项目的管道文件
qiushi/settings.py :项目的设置文件
对于目录中的 __init__.py 文件,是一个空文件,我们可以不去管理,但是也不能删除,否则项目将无法运行。
items.py 使我们要写代码逻辑的文件,相关的爬取代码在这里面写。
middlewares.py 是一个中间件文件,可以将一些自写的中间件在这里面写。
pipelines.py 是一个管道文件,我们爬取信息的处理可以在这里面写。
settings.py 是一个设置文件,里面是我们爬取信息的一些相关信息,我们可以根据需要对其进行球盖,当然也可以按照里面给定的默认设置。
接下来我们就来爬取一下之前我们爬取过的糗百的内容。
我们要爬取的网站是 https://www.qiushibaike.com/text/page/1/ 。
我们通过 Xpath Helper 的谷歌插件经过分析获取到我们想要的内容为: //div[contains(@id,"qiushi_tag")]
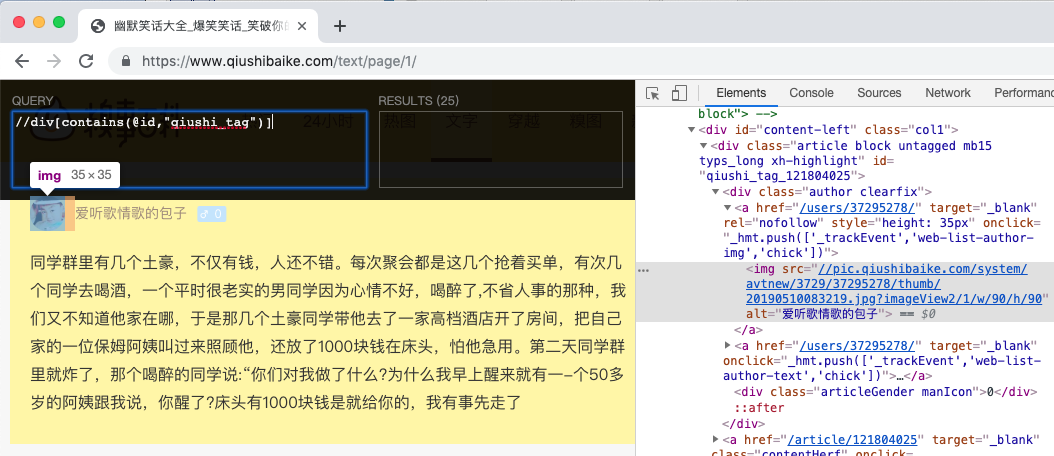
我们要爬取的是发布糗百的 作者,头像和糗事内容。
我们打开 items.py,然后将其改为如下代码:
import scrapy class QiushiItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 作者
imgUrl = scrapy.Field() # 头像
content = scrapy.Field() # 内容
然后我们在 qiushi/qiushi/spiders 文件夹下创建一个 qiushiSpider.py 的文件,代码如下:
import scrapy
from ..items import QiushiItem class QiushiSpider(scrapy.Spider):
# 爬虫名
name = "qiubai1"
# 允许爬虫作用的范围,不能越界
allowd_domains = ["https://www.qiushibaike.com/"]
# 爬虫起始url
start_urls = ["https://www.qiushibaike.com/text/page/1/"] # 我们无需再像之前利用 urllib 库那样去请求地址返回数据,在 scrapy 框架中直接利用下面的 parse 方法进行数据处理即可。
def parse(self, response):
# 通过 scrayy 自带的 xpath 匹配想要的信息
qiushi_list = response.xpath('//div[contains(@id,"qiushi_tag")]')
for site in qiushi_list:
# 实例化从 items.py 导入的 QiushiItem 类
item = QiushiItem()
# 根据查询发现匿名用户和非匿名用户的标签不一样
try:
# 非匿名用户
username = site.xpath('./div/a/img/@alt')[0].extract() # 作者
imgUrl = site.xpath('./div/a/img/@src')[0].extract() # 头像
except Exception:
# 匿名用户
username = site.xpath('./div/span/img/@alt')[0].extract() # 作者
imgUrl = site.xpath('./div/span/img/@src')[0].extract() # 头像
content = site.xpath('.//div[@class="content"]/span[1]/text()').extract()
item['username'] = username
item['imgUrl'] = "https:" + imgUrl
item['content'] = content # 将获取的数据交给 pipeline 管道文件
yield item
接下来我们打开 settings.py,settings.py 内可以根据我们的需求自己去修改,由于内容过多,在后续的章节如果有需要用到的我们单独再说。
参考文档:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#topics-settings-ref
在该案例中我们需要做的修改如下:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 300,
}
在上面的代码中,我们加入了请求报头,然后注入一个管道文件,接下来我们打开 oippelines.py 来完成这个管道文件,代码如下:
import json class QiushiPipeline(object):
def __init__(self):
self.file = open('qiushi.json', 'a') def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.file.write(content)
return item def close_spider(self, spider):
self.file.close()
这个管道文件其实就是我们将爬取到的数据存储到本地一个叫 qiushi.json 的文件中,其中 def process_item 会接受我们的数据 item,我们就可以对其进行相关操作了。
至此我们就完成了一个简单的爬取糗百的爬虫,可以看出我们不需要再像之前那样考虑太多操作时的细节,scrapy 框架会自动为我们处理,我们只需要按照相应的流程对我们的数据做处理就行了。
在控制台输入 scrapy crawl qiubai 即可运行改程序,其中“qiubai” qiushiSpider.py 中为我们定义的 name 名,最终结果如下:

Python 爬虫从入门到进阶之路(十六)的更多相关文章
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- boost库交叉编译(Linux生成ARM的库)
1. 环境: Linux系统:Ubuntu 14.04 编译工具:arm-fsl-linux-gnueabi-gcc 2.下载boost源码: 地址:https://sourceforge.net/p ...
- jquery表单过滤器
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- iOS开发之应用首次启动显示用户引导
这个功能的重点就是在如何判断应用是第一次启动的. 其实很简单 我们只需要在一个类里面写好用户引导页面 基本上都是使用UIScrollView 来实现, 新建一个继承于UIViewController ...
- WPF4.0用tablet实现手写输入(更新XP SP3下也能手写输入方法)
原文:WPF4.0用tablet实现手写输入(更新XP SP3下也能手写输入方法) 由于项目需求一个手写输入的控件,纠结了2天,终于搞定了. 主要是由于本人的英语不过关,一直和ocr混淆在一起,研究了 ...
- Win8 Metro(C#)数字图像处理--2.46图像RGB分量增强效果
原文:Win8 Metro(C#)数字图像处理--2.46图像RGB分量增强效果 [函数名称] RGB分量调整 RGBAdjustProcess(WriteableBitmap ...
- Android零基础入门第49节:AdapterViewFlipper图片轮播
原文:Android零基础入门第49节:AdapterViewFlipper图片轮播 上一期学习了ExpandableListView的使用,你已经掌握了吗?本期开始学习AdapterViewFilp ...
- 一顶博士帽能带来什么——访GOOGLE公司中国区总裁李开复
在读了博士生远潇给本报的来信后,GOOGLE公司中国区总裁李开复说,有这些困惑和担心,实际上是很多博士生们在读博士之前并没有认真地想过,自己是不是能耐得住寂寞做学问,是不是能抵御来自物质世界的诱惑 ...
- c# RedisHelper
使用redis组件如下,至于为什么使用3.9版本,是因为4.0开始商业了,限制了次数 ServiceStack.Common" version="3.9.70"Servi ...
- 深入浅出RPC——深入篇(转载)
本文转载自这里是原文 <深入篇>我们主要围绕 RPC 的功能目标和实现考量去展开,一个基本的 RPC 框架应该提供什么功能,满足什么要求以及如何去实现它? RPC 功能目标 RPC的主要功 ...
- 数据备份服务商Rubrik获4000万美元B轮融资
搜狐科技 文/丽丽卡 5月27日,数据备份服务商Rubrik获Greylock Partners领投的4000万美元B轮融资,Lightspeed Venture Partners及其现有投资者跟投, ...