【大数据】SparkSql 连接查询中的谓词下推处理 (一)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/YPN85WBNcnhk8xKjTPTa2g
作者:李勇
目录:
1.SparkSql
2.连接查询和连接条件
3.谓词下推
4.内连接查询中的谓词下推规则
4.1.Join后条件通过AND连接
4.2.Join后条件通过OR连接
4.3.分区表使用OR连接过滤条件
1.SparkSql
SparkSql 是架构在 Spark 计算框架之上的分布式 Sql 引擎,使用 DataFrame 和 DataSet 承载结构化和半结构化数据来实现数据复杂查询处理,提供的 DSL可以直接使用 scala 语言完成 Sql 查询,同时也使用 thriftserver 提供服务化的 Sql 查询功能。
SparkSql 提供了 DataSource API ,用户通过这套 API 可以自己开发一套 Connector,直接查询各类数据源,数据源包括 NoSql、RDBMS、搜索引擎以及 HDFS 等分布式文件系统上的文件等。和 SparkSql 类似的系统有 Hive、PrestoDB 以及 Impala,这类系统都属于所谓的" Sql on Hadoop "系统,每个都相当火爆,毕竟在这个不搞 SQL 就是耍流氓的年代,没 SQL 确实很难找到用户使用。
2.连接查询和连接条件
Sql中的连接查询(join),主要分为内连接查询(inner join)、外连接查询(outter join)和半连接查询(semi join),具体的区别可以参考wiki的解释。
连接条件(join condition),则是指当这个条件满足时两表的两行数据才能"join"在一起被返回,例如有如下查询:

其中的"LT.id=RT.idAND LT.id>1"这部分条件被称为"join中条件",直接用来判断被join的两表的两行记录能否被join在一起,如果不满足这个条件,两表的这两行记录并非全部被踢出局,而是根据连接查询类型的不同有不同的处理,所以这并非一个单表的过滤过程或者两个表的的“联合过滤”过程;而where后的"RT.id>2"这部分被称为"join后条件",这里虽然成为"join后条件",但是并非一定要在join后才能去过滤数据,只是说明如果在join后进行过滤,肯定可以得到一个正确的结果,这也是我们后边分析问题时得到正确结果的基准方法。
3.谓词下推
所谓谓词(predicate),英文定义是这样的:A predicate is a function that returns bool (or something that can be implicitly converted to bool),也就是返回值是true或者false的函数,使用过scala或者spark的同学都知道有个filter方法,这个高阶函数传入的参数就是一个返回true或者false的函数。
但是如果是在sql语言中,没有方法,只有表达式。where后边的表达式起的作用正是过滤的作用,而这部分语句被sql层解析处理后,在数据库内部正是以谓词的形式呈现的。
那么问题来了,谓词为什么要下推呢? SparkSql中的谓词下推有两层含义,第一层含义是指由谁来完成数据过滤,第二层含义是指何时完成数据过滤。要解答这两个问题我们需要了解SparkSql的Sql语句处理逻辑,大致可以把SparkSql中的查询处理流程做如下的划分:
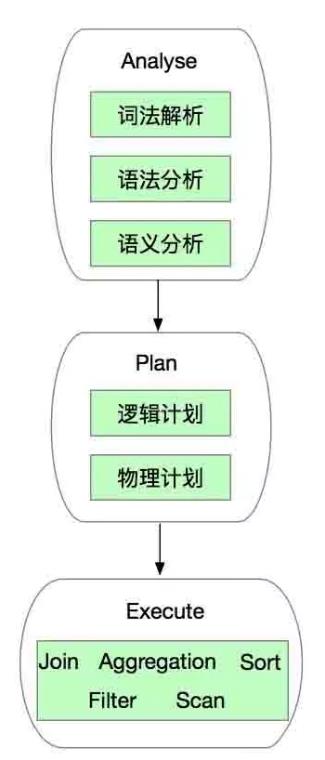
SparkSql首先会对输入的Sql语句进行一系列的分析(Analyse),包括词法解析(可以理解为搜索引擎中的分词这个过程)、语法分析以及语义分析(例如判断database或者table是否存在、group by必须和聚合函数结合等规则);之后是执行计划的生成,包括逻辑计划和物理计划。其中在逻辑计划阶段会有很多的优化,对谓词的处理就在这个阶段完成;而物理计划则是RDD的DAG图的生成过程;这两步完成之后则是具体的执行了(也就是各种重量级的计算逻辑,例如join、groupby、filter以及distinct等),这就会有各种物理操作符(RDD的Transformation)的乱入。
能够完成数据过滤的主体有两个,第一是分布式Sql层(在execute阶段),第二个是数据源。那么谓词下推的第一层含义就是指由Sql层的Filter操作符来完成过滤,还是由Scan操作符在扫描阶段完成过滤。
上边提到,我们可以通过封装SparkSql的Data Source API完成各类数据源的查询,那么如果底层数据源无法高效完成数据的过滤,就会执行全局扫描,把每条相关的数据都交给SparkSql的Filter操作符完成过滤,虽然SparkSql使用的Code Generation技术极大的提高了数据过滤的效率,但是这个过程无法避免大量数据的磁盘读取,甚至在某些情况下会涉及网络IO(例如数据非本地化存储时);如果底层数据源在进行扫描时能非常快速的完成数据的过滤,那么就会把过滤交给底层数据源来完成(至于哪些数据源能高效完成数据的过滤以及SparkSql又是如何完成高效数据过滤的则不是本文讨论的重点,会在其他系列的文章中介绍)。
那么谓词下推第二层含义,即何时完成数据过滤则一般是在指连接查询中,是先对单表数据进行过滤再和其他表连接还是在先把多表进行连接再对连接后的临时表进行过滤,则是本系列文章要分析和讨论的重点。
4.内连接查询中的谓词下推规则
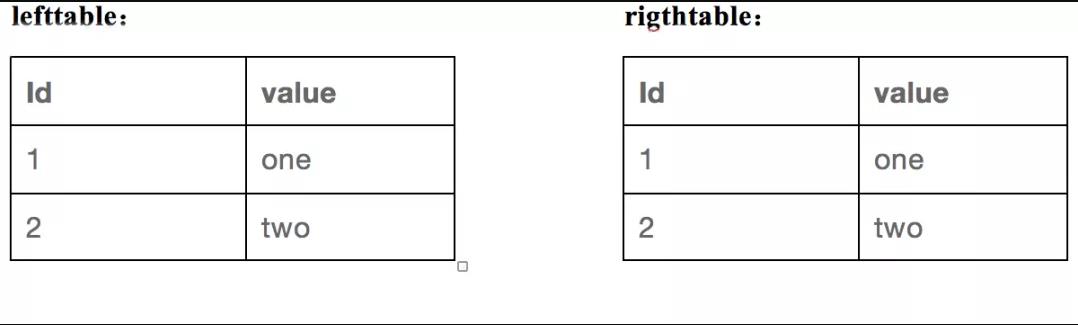
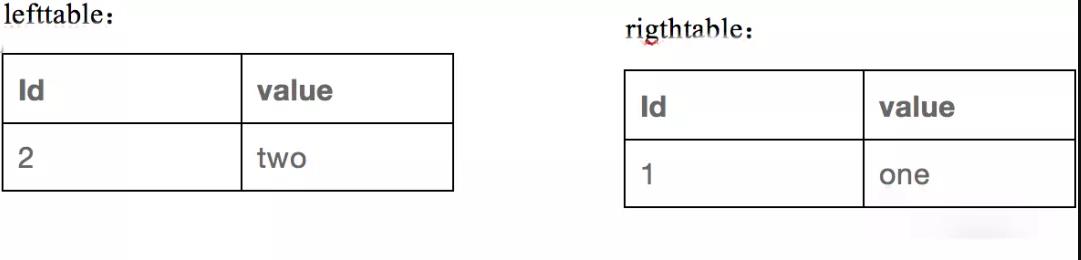
假设我们有两张表,表结构很简单,数据也都只有两条,但是足以讲清楚我们的下推规则,两表如下,一个lefttable,一个righttable:
4.1.Join后条件通过AND连接
先来看一条查询语句:

这个查询是一个内连接查询,join后条件是用and连接的两个表的过滤条件,假设我们不下推,而是先做内连接判断,这时是可以得到正确结果的,步骤如下:
左表id为1的行在右表中可以找到,即这两行数据可以"join"在一起
左表id为2的行在右表中可以找到,这两行也可以"join"在一起
至此,join的临时结果表(之所以是临时表,因为还没有进行过滤)如下:
然后使用where条件进行过滤,显然临时表中的第一行不满足条件,被过滤掉,最后结果如下:

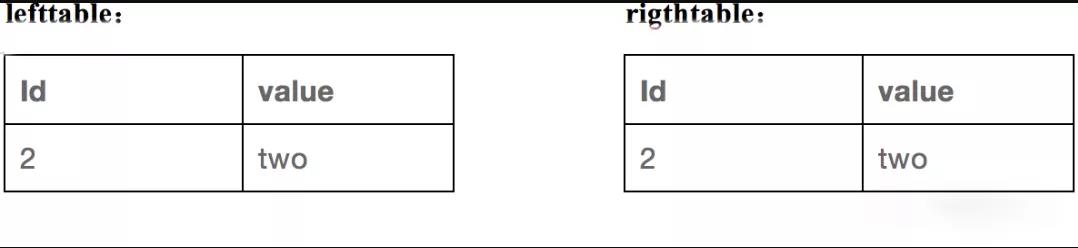
来看看先进行谓词下推的情况。先对两表进行过滤,过滤的结果分别如下:
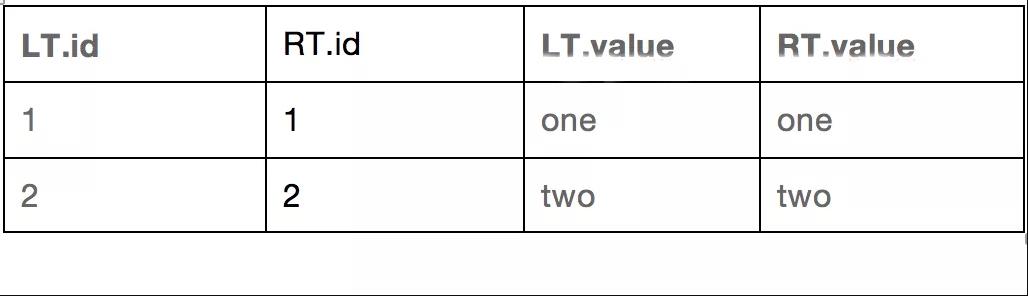
然后再对这两个过滤后的表进行内连接处理,结果如下:

可见,这和先进行join再过滤得到的结果一致。
4.2.Join后条件通过OR连接
再来看一条查询语句:

我们先进行join处理,临时表的结果如下:
然后使用where条件进行过滤,最终查询结果如下:
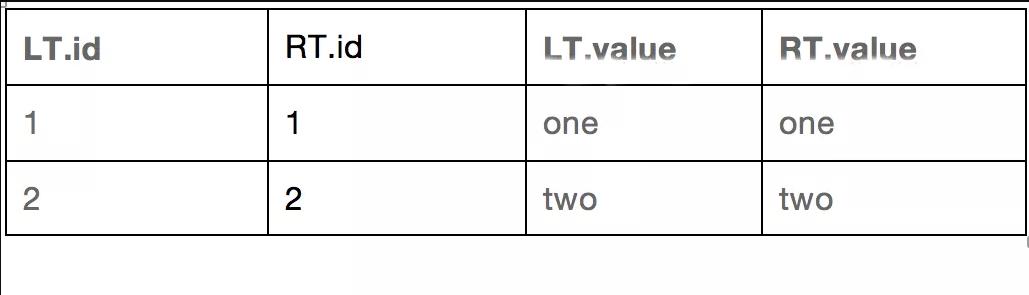
如果我们先使用where条件后每个表各自的过滤条件进行过滤,那么两表的过滤结果如下:
然后对这两个临时表进行内连接处理,结果如下:

表格有问题吧,只有字段名,没有字段值,怎么回事?是的,你没看错,确实没有值,因为左表过滤结果只有id为1的行,右表过滤结果只有id为2的行,这两行是不能内连接上的,所以没有结果。
那么为什么where条件中两表的条件被or连接就会出现错误的查询结果呢?分析原因主要是因为,对于or两侧的过滤条件,任何一个满足条件即可以返回TRUE,那么对于"LT.value = 'two' OR RT.value = 'two' "这个查询条件,如果使用LT.value='two'把只有LT.value为'two'的左表记录过滤出来,那么对于左表中LT.value不为two的行,他们可能在跟右表使用id字段连接上之后,右表的RT.value恰好为two,也满足"LT.value = 'two' OR RT.value = 'two' ",但是可惜呀可惜,这行记录因为之前的粗暴处理,已经被过滤掉,结果就是得到了错误的查询结果。所以这种情况下谓词是不能下推的。
但是OR连接两表join后条件也有两个例外,这里顺便分析第一个例外。第一个例外是过滤条件字段恰好为Join字段,比如如下的查询:

在这个查询中,join后条件依然是使用OR连接两表的过滤条件,不同的是,join中条件不再是id相等,而是value字段相等,也就是说过滤条件字段恰好就是join条件字段。大家可以自行采用上边的分步法分析谓词下推和不下推时的查询结果,得到的结果是相同的。
我们来看看上边不能下推时出现的情况在这种查询里会不会出现。对于左表,如果使用LT.value='two'过滤掉不符合条件的其他行,那么因为join条件字段也是value字段,说明在左表中LT.value不等于two的行,在右表中也不能等于two,否则就不满足"LT.value=RT.value"了。这里其实有一个条件传递的过程,通过join中条件,已经在逻辑上提前把两表整合成了一张表。
至于第二个例外,则涉及了SparkSql中的一个优化,所以需要单独介绍。
4.3.分区表使用OR连接过滤条件
如果两个表都是分区表,会出现什么情况呢?我们先来看如下的查询:

此时左表和右表都不再是普通的表,而是分区表,分区字段是pt,按照日期进行数据分区。同时两表查询条件依然使用OR进行连接。试想,如果不能提前对两表进行过滤,那么会有非常巨量的数据要首先进行连接处理,这个代价是非常大的。但是如果按照我们在2中的分析,使用OR连接两表的过滤条件,又不能随意的进行谓词下推,那要如何处理呢?SparkSql在这里使用了一种叫做“分区裁剪”的优化手段,即把分区并不看做普通的过滤条件,而是使用了“一刀切”的方法,把不符合查询分区条件的目录直接排除在待扫描的目录之外。
我们知道分区表在HDFS上是按照目录来存储一个分区的数据的,那么在进行分区裁剪时,直接把要扫描的HDFS目录通知Spark的Scan操作符,这样,Spark在进行扫描时,就可以直接咔嚓掉其他的分区数据了。但是,要完成这种优化,需要SparkSql的语义分析逻辑能够正确的分析出Sql语句所要表达的精确目的,所以分区字段在SparkSql的元数据中也是独立于其他普通字段,进行了单独的标示,就是为了方便语义分析逻辑能区别处理Sql语句中where条件里的这种特殊情况。
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:labs2020 联系。
【大数据】SparkSql 连接查询中的谓词下推处理 (一)的更多相关文章
- 【大数据】SparkSql 连接查询中的谓词下推处理 (二)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/II48YxGfoursKVvdAXYbVg作者:李勇 目录:1.左表 join 后条件下推2.左表j ...
- 【杂记】mysql 左右连接查询中的NULL的数据筛选问题,查询NULL设置默认值,DATE_FORMAT函数
MySQL左右连接查询中的NULL的数据筛选问题 xpression 为 Null,则 IsNull 将返回 True:否则 IsNull 将返回 False. 如果 expression 由多个变量 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- J2EE综合:如何处理大数据量的查询
在实际的任何一个系统中,查询都是必不可少的一个功能,而查询设计的好坏又影响到系统的响应时间和性能这两个要害指标,尤其是当数据量变得越来越大时,于是如何处理大数据量的查询成了每个系统架构设计时都必须面对 ...
- sql连接查询中的分类
sql连接查询中的分类 1.内连接(结果不保留表中未对应的数据) 1.1等值连接:关联条件的运算符是用等号来连接的. 1.2不等值连接:连接条件是出等号之外的操作符 1.3自然连接:特殊的等值连接,在 ...
- MongoDB 大数据技术之mongodb中在嵌套子文档的文档上面建立索引
一.给collection objectid赋自定义的值 MongoDB Enterprise > db.testid.insert({_id:{imsi:"4567890123&qu ...
- 关于连接查询主要是左右连接查询中,where和on的区别
工作中,今天用到左连接查询,我自己造的数据,需要根据条件进行筛选,但是筛选不符合我的要求,最终发现是左右连接中where和on的区别,在作怪,工作中用的表关联太多,我下面简化要点,仅仅把注意点写个简单 ...
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- 大数据系列-CDH环境中SOLR入数据
1 创建集合 SSH远程连接到安装了SOLR的CDH节点. 运行solrctl instancedir --generate /solr/test/GX_SH_TL_TGRYXX_2 ...
随机推荐
- PriorityBlockingQueue
public class PriorityBlockingQueueTest { /** * 有优先级顺序的阻塞队列,底层实现是数组,无边界.默认是11. * 构造方法可以传入一个比较器,不传的话,默 ...
- 利用zabbix监控ogg进程(Linux平台下)
前段时间生产的一个数据库的ogg进程挂了快半个月才被发现,已经起不来了,只有重新初始化再同步.因此很有必要监控下ogg的进程,这里给大家介绍如何使用zabbix监控oracle的ogg的进程.思路就是 ...
- WPF 程序员休息数字时钟
由于,程序员工作压力较大,上周996.ICU项目也非常火,为了让程序员开发者注重休息,特意写了一个休眠时钟,启动程序默认会倒计时3分钟. 效果图: 程序支持自定义休息时间,通过命令行参数执行,例如: ...
- numpy 和 tensorflow 中的各种乘法(点乘和矩阵乘)
点乘和矩阵乘的区别: 1)点乘(即" * ") ---- 各个矩阵对应元素做乘法 若 w 为 m*1 的矩阵,x 为 m*n 的矩阵,那么通过点乘结果就会得到一个 m*n 的矩阵. ...
- JAVA笔记 -- this关键字
this关键字 一. 基本作用 在当前方法内部,获得当前对象的引用.在引用中,调用方法不必使用this.method()这样的形式来说明,因为编译器会自动的添加. 必要情况: 为了将对象本身返回 ja ...
- 微信小程序和支付宝小程序富文本使用
微信小程序使用的是 1. wxml 页面元素的最简单使用 <rich-text nodes="{{这是你的数据}}"></rich-text> 2. j ...
- 自定义滚动条样式纯(css)
啥都不说先看图: 注: 只适合chrom,不适用IE和fireFox 下面展示代码: <html lang="en"> <head> <meta ch ...
- RSA 非对称加密算法的Java实现
关于RSA的介绍Google一下很多,这里不做说明.项目开发中一般会把公钥放在本地进行加密,服务端通过私钥进行解密.Android项目开发中要用到这个加密算法,总结后实现如下: import andr ...
- 微信跳转外部浏览器下载app原理
在我们使用微信营销的时候,很容易碰到推广连接在微信内无法打开或无法下载app的情况.通常这种情况微信会给个提示 “已停止访问该网址” ,那么导致这个情况的因素有哪些呢,主要有以下三点 1.网页链接被举 ...
- [转]国内阿里Maven仓库镜像Maven配置文件Maven仓库速度快
原文地址:http://www.cnblogs.com/ae6623/p/4416256.html 国内连接maven官方的仓库更新依赖库,网速一般很慢,收集一些国内快速的maven仓库镜像以备用. ...