『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发。刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程。
本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新ing)
- NLP机器翻译深度学习实战课程·零(基础概念)
- NLP机器翻译深度学习实战课程·壹(RNN base)
- NLP机器翻译深度学习实战课程·贰(RNN+Attention base)
- NLP机器翻译深度学习实战课程·叁(CNN base)
- NLP机器翻译深度学习实战课程·肆(Self-Attention base)
- NLP机器翻译深度学习实战课程·伍(应用部署)
本系列教程参考博客:https://me.csdn.net/chinatelecom08
0. 项目背景
在上个文章中,我们已经简单介绍了NLP机器翻译,这次我们将用实战的方式讲解基于RNN的翻译模型。
0.1 基于RNN的seq2seq架构翻译模型介绍
seq2seq结构
基于RNN的seq2seq架构包含encoder和decoder,decoder部分又分train和inference两个过程,具体结构如下面两图所示:

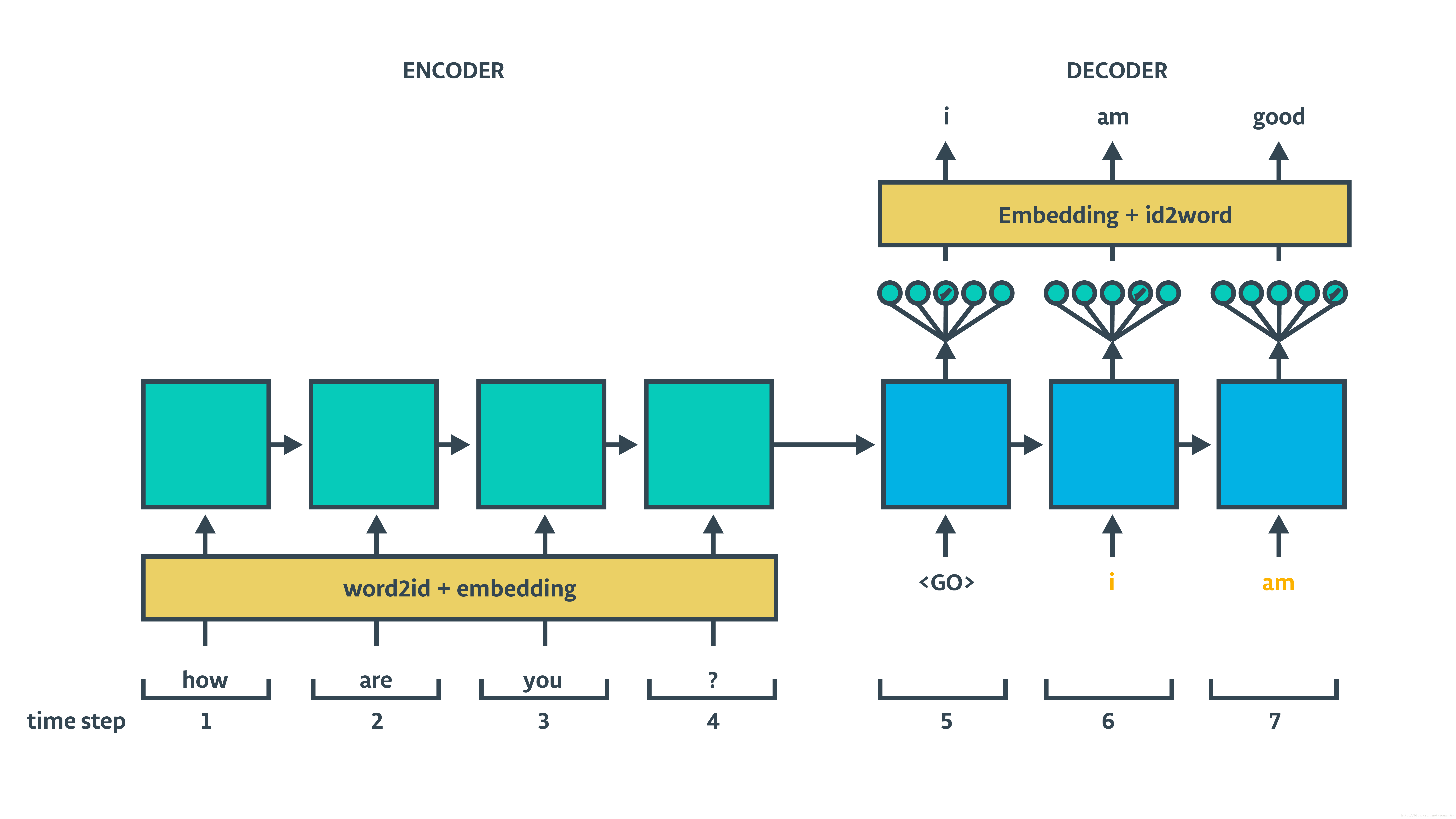
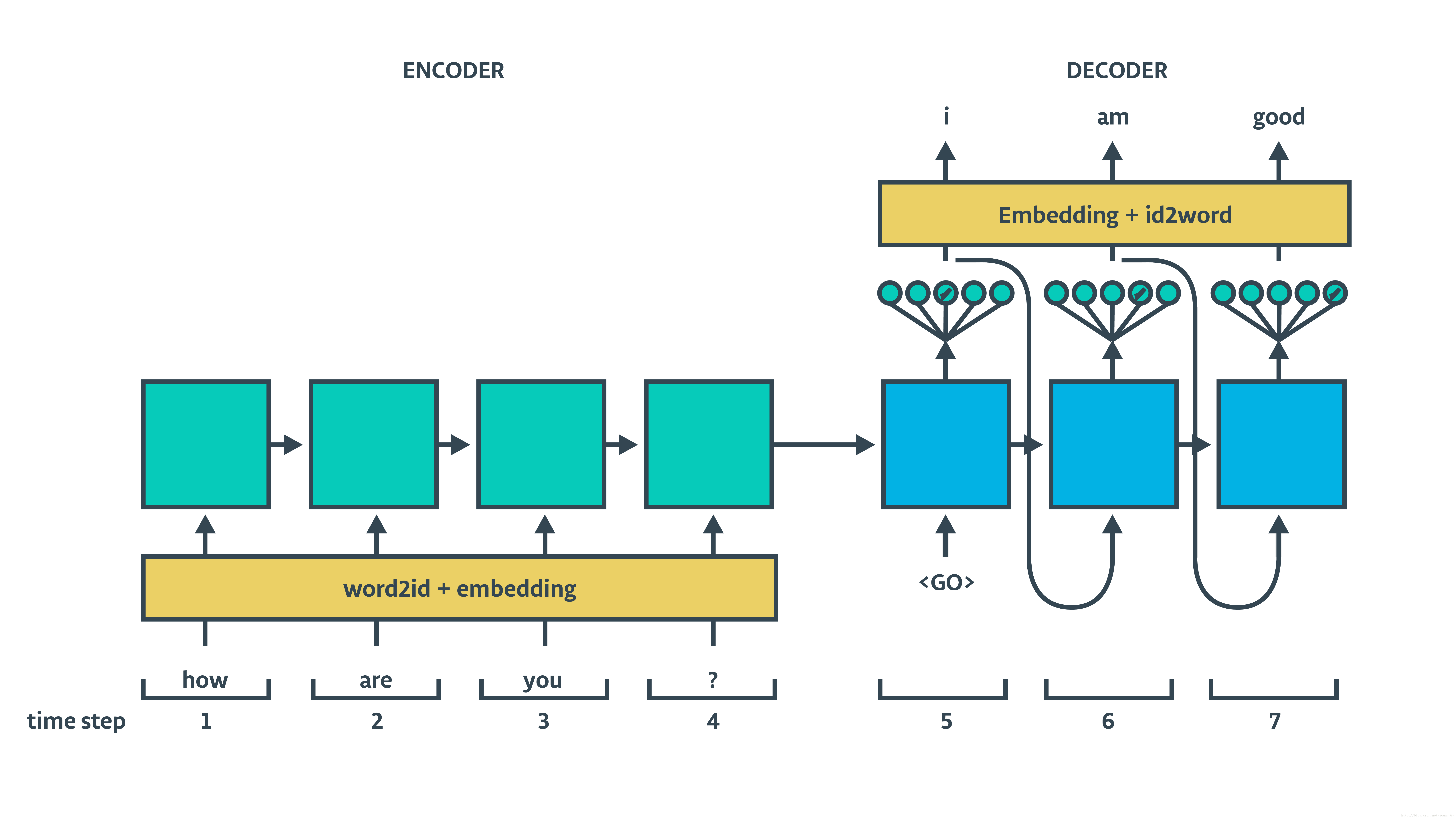
可以看出结构很简单(相较于CNN与Attention base),下面我们就通过代码的形式实现,来进一步探究理解模型内在原理。
1. 数据准备
1.1 下载数据
此网站http://www.manythings.org/anki/上有许多翻译数据,包含多种语言,这里此教程选择的是中文到英语的数据集。
训练下载地址:http://www.manythings.org/anki/cmn-eng.zip
解压cmn-eng.zip,可以找到cmn.txt文件,内容如下:
# ========读取原始数据========
with open('cmn.txt', 'r', encoding='utf-8') as f:
data = f.read()
data = data.split('\n')
data = data[:100]
print(data[-5:])
['Tom died.\t汤姆去世了。', 'Tom quit.\t汤姆不干了。', 'Tom swam.\t汤姆游泳了。', 'Trust me.\t相信我。', 'Try hard.\t努力。']
可以发现,每对翻译数据在同一行,左边是英文,右边是中文使用 \t 作为英语与中文的分界。
1.2 数据预处理
使用网络训练,需要我们把数据处理成网络可以接收的格式。
针对这个数据,具体来说就是需要把字符转换为数字(句子数字化),句子长度归一化处理。
句子数字化
可以参考我的这博客:『深度应用』NLP命名实体识别(NER)开源实战教程,数据预处理的实现。
分别对英语与汉字做处理。
英文处理
因为英语每个单词都是用空格分开的(除了缩写词,这里缩写词当做一个词处理),还有就是标点符号和单词没有分开,也需要特殊处理一下
这里我用的是一个简单方法处理下,实现在标点前加空格:
def split_dot(strs,dots=", . ! ?"):
for d in dots.split(" "):
#print(d)
strs = strs.replace(d," "+d)
#print(strs)
return(strs)
使用这个方法来把词个字典化:
def get_eng_dicts(datas):
w_all_dict = {}
for sample in datas:
for token in sample.split(" "):
if token not in w_all_dict.keys():
w_all_dict[token] = 1
else:
w_all_dict[token] += 1 sort_w_list = sorted(w_all_dict.items(), key=lambda d: d[1], reverse=True) w_keys = [x for x,_ in sort_w_list[:7000-2]]
w_keys.insert(0,"<PAD>")
w_keys.insert(0,"<UNK>") w_dict = { x:i for i,x in enumerate(w_keys) }
i_dict = { i:x for i,x in enumerate(w_keys) }
return w_dict,i_dict
中文处理
在处理中文时可以发现,有繁体也有简体,所以最好转换为统一形式:(参考地址)
# 安装
pip install opencc-python-reimplemented
# t2s - 繁体转简体(Traditional Chinese to Simplified Chinese)
# s2t - 简体转繁体(Simplified Chinese to Traditional Chinese)
# mix2t - 混合转繁体(Mixed to Traditional Chinese)
# mix2s - 混合转简体(Mixed to Simplified Chinese)
使用方法,把繁体转换为简体:
import opencc
cc = opencc.OpenCC('t2s')
s = cc.convert('這是什麼啊?')
print(s)
#这是什么啊?
再使用jieba分词的方法来从句子中分出词来:
def get_chn_dicts(datas):
w_all_dict = {}
for sample in datas:
for token in jieba.cut(sample):
if token not in w_all_dict.keys():
w_all_dict[token] = 1
else:
w_all_dict[token] += 1 sort_w_list = sorted(w_all_dict.items(), key=lambda d: d[1], reverse=True) w_keys = [x for x,_ in sort_w_list[:10000-4]]
w_keys.insert(0,"<EOS>")
w_keys.insert(0,"<GO>")
w_keys.insert(0,"<PAD>")
w_keys.insert(0,"<UNK>")
w_dict = { x:i for i,x in enumerate(w_keys) }
i_dict = { i:x for i,x in enumerate(w_keys) }
return w_dict,i_dict
下面进行padding
def get_val(keys,dicts):
if keys in dicts.keys():
val = dicts[keys]
else:
keys = "<UNK>"
val = dicts[keys]
return(val) def padding(lists,lens=LENS):
list_ret = []
for l in lists: while(len(l)<lens):
l.append(1) if len(l)>lens:
l = l[:lens]
list_ret.append(l) return(list_ret)
最后统一运行处理一下:
if __name__ == "__main__":
df = read2df("cmn-eng/cmn.txt")
eng_dict,id2eng = get_eng_dicts(df["eng"])
chn_dict,id2chn = get_chn_dicts(df["chn"])
print(list(eng_dict.keys())[:20])
print(list(chn_dict.keys())[:20]) enc_in = [[get_val(e,eng_dict) for e in eng.split(" ")] for eng in df["eng"]]
dec_in = [[get_val("<GO>",chn_dict)]+[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]]
dec_out = [[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]] enc_in_ar = np.array(padding(enc_in,32))
dec_in_ar = np.array(padding(dec_in,30))
dec_out_ar = np.array(padding(dec_out,30))
输出结果如下:
(TF_GPU) D:\Files\Prjs\Pythons\Kerases\MNT_RNN>C:/Datas/Apps/RJ/Miniconda3/envs/TF_GPU/python.exe d:/Files/Prjs/Pythons/Kerases/MNT_RNN/mian.py
Using TensorFlow backend.
eng chn
0 Hi . 嗨。
1 Hi . 你好。
2 Run . 你用跑的。
3 Wait ! 等等!
4 Hello ! 你好。
save csv
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\xiaos\AppData\Local\Temp\jieba.cache
Loading model cost 0.788 seconds.
Prefix dict has been built succesfully.
['<UNK>', '<PAD>', '.', 'I', 'to', 'the', 'you', 'a', '?', 'is', 'Tom', 'He', 'in', 'of', 'me', ',', 'was', 'for', 'have', 'The']
['<UNK>', '<PAD>', '<GO>', '<EOS>', '。', '我', '的', '了', '你', '他', '?', '在', '汤姆', '是', '她', '吗', '我们', ',', '不', '很']
2. 构建模型与训练
2.1 构建模型与超参数
用的是双层LSTM网络
# =======预定义模型参数========
EN_VOCAB_SIZE = 7000
CH_VOCAB_SIZE = 10000
HIDDEN_SIZE = 256 LEARNING_RATE = 0.001
BATCH_SIZE = 50
EPOCHS = 100 # ======================================keras model==================================
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Embedding,CuDNNLSTM
from keras.optimizers import Adam
import numpy as np def get_model():
# ==============encoder=============
encoder_inputs = Input(shape=(None,))
emb_inp = Embedding(output_dim=128, input_dim=EN_VOCAB_SIZE)(encoder_inputs)
encoder_h1, encoder_state_h1, encoder_state_c1 = CuDNNLSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)(emb_inp)
encoder_h2, encoder_state_h2, encoder_state_c2 = CuDNNLSTM(HIDDEN_SIZE, return_state=True)(encoder_h1) # ==============decoder=============
decoder_inputs = Input(shape=(None,)) emb_target = Embedding(output_dim=128, input_dim=CH_VOCAB_SIZE)(decoder_inputs)
lstm1 = CuDNNLSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)
lstm2 = CuDNNLSTM(HIDDEN_SIZE, return_sequences=True, return_state=True)
decoder_dense = Dense(CH_VOCAB_SIZE, activation='softmax') decoder_h1, _, _ = lstm1(emb_target, initial_state=[encoder_state_h1, encoder_state_c1])
decoder_h2, _, _ = lstm2(decoder_h1, initial_state=[encoder_state_h2, encoder_state_c2])
decoder_outputs = decoder_dense(decoder_h2) model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # encoder模型和训练相同
encoder_model = Model(encoder_inputs, [encoder_state_h1, encoder_state_c1, encoder_state_h2, encoder_state_c2]) # 预测模型中的decoder的初始化状态需要传入新的状态
decoder_state_input_h1 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c1 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_h2 = Input(shape=(HIDDEN_SIZE,))
decoder_state_input_c2 = Input(shape=(HIDDEN_SIZE,)) # 使用传入的值来初始化当前模型的输入状态
decoder_h1, state_h1, state_c1 = lstm1(emb_target, initial_state=[decoder_state_input_h1, decoder_state_input_c1])
decoder_h2, state_h2, state_c2 = lstm2(decoder_h1, initial_state=[decoder_state_input_h2, decoder_state_input_c2])
decoder_outputs = decoder_dense(decoder_h2) decoder_model = Model([decoder_inputs, decoder_state_input_h1, decoder_state_input_c1, decoder_state_input_h2, decoder_state_input_c2],
[decoder_outputs, state_h1, state_c1, state_h2, state_c2]) return(model,encoder_model,decoder_model)
2.2 模型配置与训练
自定义了一个acc,便于显示效果,keras内置的acc无法使用
import keras.backend as K
from keras.models import load_model def my_acc(y_true, y_pred):
acc = K.cast(K.equal(K.max(y_true,axis=-1),K.cast(K.argmax(y_pred,axis=-1),K.floatx())),K.floatx())
return acc Train = True if __name__ == "__main__":
df = read2df("cmn-eng/cmn.txt")
eng_dict,id2eng = get_eng_dicts(df["eng"])
chn_dict,id2chn = get_chn_dicts(df["chn"])
print(list(eng_dict.keys())[:20])
print(list(chn_dict.keys())[:20]) enc_in = [[get_val(e,eng_dict) for e in eng.split(" ")] for eng in df["eng"]]
dec_in = [[get_val("<GO>",chn_dict)]+[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]]
dec_out = [[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]] enc_in_ar = np.array(padding(enc_in,32))
dec_in_ar = np.array(padding(dec_in,30))
dec_out_ar = np.array(padding(dec_out,30)) #dec_out_ar = covt2oh(dec_out_ar) if Train: model,encoder_model,decoder_model = get_model() model.load_weights('e2c1.h5') opt = Adam(lr=LEARNING_RATE, beta_1=0.9, beta_2=0.99, epsilon=1e-08)
model.compile(optimizer=opt, loss='sparse_categorical_crossentropy',metrics=[my_acc])
model.summary()
print(dec_out_ar.shape)
model.fit([enc_in_ar, dec_in_ar], np.expand_dims(dec_out_ar,-1),
batch_size=50,
epochs=64,
initial_epoch=0,
validation_split=0.1)
model.save('e2c1.h5')
encoder_model.save("enc1.h5")
decoder_model.save("dec1.h5")
64Epoch训练结果如下:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, None) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, None, 128) 896000 input_1[0][0]
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, None, 128) 1280000 input_2[0][0]
__________________________________________________________________________________________________
cu_dnnlstm_1 (CuDNNLSTM) [(None, None, 256), 395264 embedding_1[0][0]
__________________________________________________________________________________________________
cu_dnnlstm_3 (CuDNNLSTM) [(None, None, 256), 395264 embedding_2[0][0]
cu_dnnlstm_1[0][1]
cu_dnnlstm_1[0][2]
__________________________________________________________________________________________________
cu_dnnlstm_2 (CuDNNLSTM) [(None, 256), (None, 526336 cu_dnnlstm_1[0][0]
__________________________________________________________________________________________________
cu_dnnlstm_4 (CuDNNLSTM) [(None, None, 256), 526336 cu_dnnlstm_3[0][0]
cu_dnnlstm_2[0][1]
cu_dnnlstm_2[0][2]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 10000) 2570000 cu_dnnlstm_4[0][0]
==================================================================================================
Non-trainable params: 0
__________________________________________________________________________________________________
...
...
19004/19004 [==============================] - 98s 5ms/step - loss: 0.1371 - my_acc: 0.9832 - val_loss: 2.7299 - val_my_acc: 0.7412
Epoch 58/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.1234 - my_acc: 0.9851 - val_loss: 2.7378 - val_my_acc: 0.7410
Epoch 59/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.1132 - my_acc: 0.9867 - val_loss: 2.7477 - val_my_acc: 0.7419
Epoch 60/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.1050 - my_acc: 0.9879 - val_loss: 2.7660 - val_my_acc: 0.7426
Epoch 61/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.0983 - my_acc: 0.9893 - val_loss: 2.7569 - val_my_acc: 0.7408
Epoch 62/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.0933 - my_acc: 0.9903 - val_loss: 2.7775 - val_my_acc: 0.7414
Epoch 63/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.0885 - my_acc: 0.9911 - val_loss: 2.7885 - val_my_acc: 0.7420
Epoch 64/64
19004/19004 [==============================] - 96s 5ms/step - loss: 0.0845 - my_acc: 0.9920 - val_loss: 2.7914 - val_my_acc: 0.7423
3. 模型应用与预测
从训练集选取部分数据进行测试
Train = False if __name__ == "__main__":
df = read2df("cmn-eng/cmn.txt")
eng_dict,id2eng = get_eng_dicts(df["eng"])
chn_dict,id2chn = get_chn_dicts(df["chn"])
print(list(eng_dict.keys())[:20])
print(list(chn_dict.keys())[:20]) enc_in = [[get_val(e,eng_dict) for e in eng.split(" ")] for eng in df["eng"]]
dec_in = [[get_val("<GO>",chn_dict)]+[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]]
dec_out = [[get_val(e,chn_dict) for e in jieba.cut(eng)]+[get_val("<EOS>",chn_dict)] for eng in df["chn"]] enc_in_ar = np.array(padding(enc_in,32))
dec_in_ar = np.array(padding(dec_in,30))
dec_out_ar = np.array(padding(dec_out,30)) #dec_out_ar = covt2oh(dec_out_ar) if Train: pass else: encoder_model,decoder_model = load_model("enc1.h5",custom_objects={"my_acc":my_acc}),load_model("dec1.h5",custom_objects={"my_acc":my_acc}) for k in range(16000-20,16000):
test_data = enc_in_ar[k:k+1]
h1, c1, h2, c2 = encoder_model.predict(test_data)
target_seq = np.zeros((1,1)) outputs = []
target_seq[0, len(outputs)] = chn_dict["<GO>"]
while True:
output_tokens, h1, c1, h2, c2 = decoder_model.predict([target_seq, h1, c1, h2, c2])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
#print(sampled_token_index)
outputs.append(sampled_token_index)
#target_seq = np.zeros((1, 30))
target_seq[0, 0] = sampled_token_index
#print(target_seq)
if sampled_token_index == chn_dict["<EOS>"] or len(outputs) > 28: break print("> "+df["eng"][k])
print("< "+' '.join([id2chn[i] for i in outputs[:-1]]))
print()
测试结果如下:基本上都翻译正确了。
> I can understand you to some extent .
< 在 某种程度 上 我 能 了解 你 。
> I can't recall the last time we met .
< 我 想不起来 我们 上次 见面 的 情况 了 。
> I can't remember which is my racket .
< 我 不 记得 哪个 是 我 的 球拍 。
> I can't stand that noise any longer .
< 我 不能 再 忍受 那 噪音 了 。
> I can't stand this noise any longer .
< 我 无法 再 忍受 这个 噪音 了 。
> I caught the man stealing the money .
< 我 抓 到 了 这个 男人 正在 偷钱 。
> I could not afford to buy a bicycle .
< 我 买不起 自行车 。
> I couldn't answer all the questions .
< 我 不能 回答 所有 的 问题 。
> I couldn't think of anything to say .
< 我 想不到 要说 什么 话 。
> I cry every time I watch this movie .
< 我 每次 看 这部 电影 都 会 哭 。
> I did not participate in the dialog .
< 我 没有 参与 对话 。
> I didn't really feel like going out .
< 我 不是 很想 出去 。
> I don't care a bit about the future .
< 我 不在乎 将来 。
『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)的更多相关文章
- 『深度应用』NLP机器翻译深度学习实战课程·零(基础概念)
0.前言 深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内 ...
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 『深度应用』NLP命名实体识别(NER)开源实战教程
近几年来,基于神经网络的深度学习方法在计算机视觉.语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展.在NLP的关键性基础任务—命名实体识别(Named Entity Recogni ...
- NLP与深度学习(一)NLP任务流程
1. 自然语言处理简介 根据工业界的估计,仅有21% 的数据是以结构化的形式展现的[1].在日常生活中,大量的数据是以文本.语音的方式产生(例如短信.微博.录音.聊天记录等等),这种方式是高度无结构化 ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- 在NLP中深度学习模型何时需要树形结构?
在NLP中深度学习模型何时需要树形结构? 前段时间阅读了Jiwei Li等人[1]在EMNLP2015上发表的论文<When Are Tree Structures Necessary for ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
随机推荐
- 网页缓存相关的HTTP头部信息详解
前言 之前看完了李智慧老师著的<大型网站技术架构-核心原理与案例分析>这本书,书中多次提起浏览器缓存的话题,恰是这几天生产又遇到了一个与缓存的问题,发现自己书是没少看,正经走心的内容却不多 ...
- 基于surging 的stage组件设计,谈谈我眼中的微服务。
一.前言 随着业务的发展,并发量的增多,业务的复杂度越来越大,对于系统架构能力要求越来越高,这时候微服务的设计思想应运而生,但是对于微服务需要引擎进行驱动,这时候基于.NET CORE 的微服务引擎s ...
- sqlserver2014创建数据库时,错误提示如下:尝试打开或创建物理‘c:\数据库\db.mdf’时,Create File遇到操作系统错误5(拒绝访问)
CREATE DATABASE test1 ON PRIMARY ( NAME =test1, FILENAME='C:\Program Files\test1.mdf',SIZE=10240K ...
- liunx基本操作操作与文件和目录的管理
一.基本操作 Tab键: 自动补全ctrl + u: 清空至行首ctrl + k: 清空至行尾 ctrl + l: 清屏 ctrl + c: 取消本次命令编辑重启:rebootsystemctl re ...
- linux初学者-网络管理篇
linux初学者-网络管理篇 linux学习中,网络管理是非常重要的一个内容,本篇将会介绍一些ip.网关.DNS配置的一些基本内容. 1.ip配置 1.1.ip查询 在linux系统中一般可以使用& ...
- 关于Hack术语方面
1.肉鸡 所谓“肉鸡”是一种很形象的比喻,比喻那些可以随意被我们控制的电脑,对方可以是WINDOWS系统,也可以是UNIX/LINUX系统,可以是普通的个人电脑,也可以是大型的服务器,我们 ...
- 仿LookUpEdit多列模糊搜索,功能比GridLookUpEdit强大,比SearhLookUpEdit方便
先上效果图: 控件调用示例:(devexpress使用了16.2.6.0版本,可以根据实际需要进行版本转换) using System; using System.Collections.Generi ...
- 一文掌握 Spring Boot Profiles
Spring Boot Profiles 简介 Profile 的概念其实很早在 Spring Framework 就有了,在 Spring Framework 3.1 版本引入了注解 @Profil ...
- react项目建立导入包问题总结
1.react和react-dom包 使用react开发网页的话,我们难免会下载两个包,一个是react,一个是react-dom,其中react是react的核心代码.react的核心思想是虚拟Do ...
- 用大白话告诉你 :Java 后端到底是在做什么?
阅读本文大概需要 6 分钟. 作者:黄小斜 新手程序员通常会走入一个误区,就是认为学习了一门语言,就可以称为是某某语言工程师了.但事实上真的是这样吗?其实并非如此. 今天我们就来聊一聊,Java 开发 ...