[C1W3] Neural Networks and Deep Learning - Shallow neural networks
第三周:浅层神经网络(Shallow neural networks)
神经网络概述(Neural Network Overview)
本周你将学习如何实现一个神经网络。在我们深入学习具体技术之前,我希望快速的带你预览一下本周你将会学到的东西。如果在本节课中的某些细节你没有看懂你也不用担心,我们将在后面的几节课中深入讨论技术细节。
现在我们开始快速浏览一下如何实现神经网络。首先你需要输入特征 \(x\),参数 \(w\) 和 \(b\),通过这些你就可以计算出 \(z\),接下来使用 \(z\) 就可以计算出 \(a\)。我们暂时将表示最终网络输出的符号 \(\hat{y}\) 换成表示激活(activation)单元的输出 \(a\),\(a = \sigma(z)\),然后可以计算出 loss function \(\mathcal{L}(a,y)\)
\(\left[\begin{array}{l} x,\ w,\ b \end{array} \right] \implies{z={w}^Tx+b} \implies{a = \sigma(z)}\ \implies{\mathcal{L}(a,y)}\)
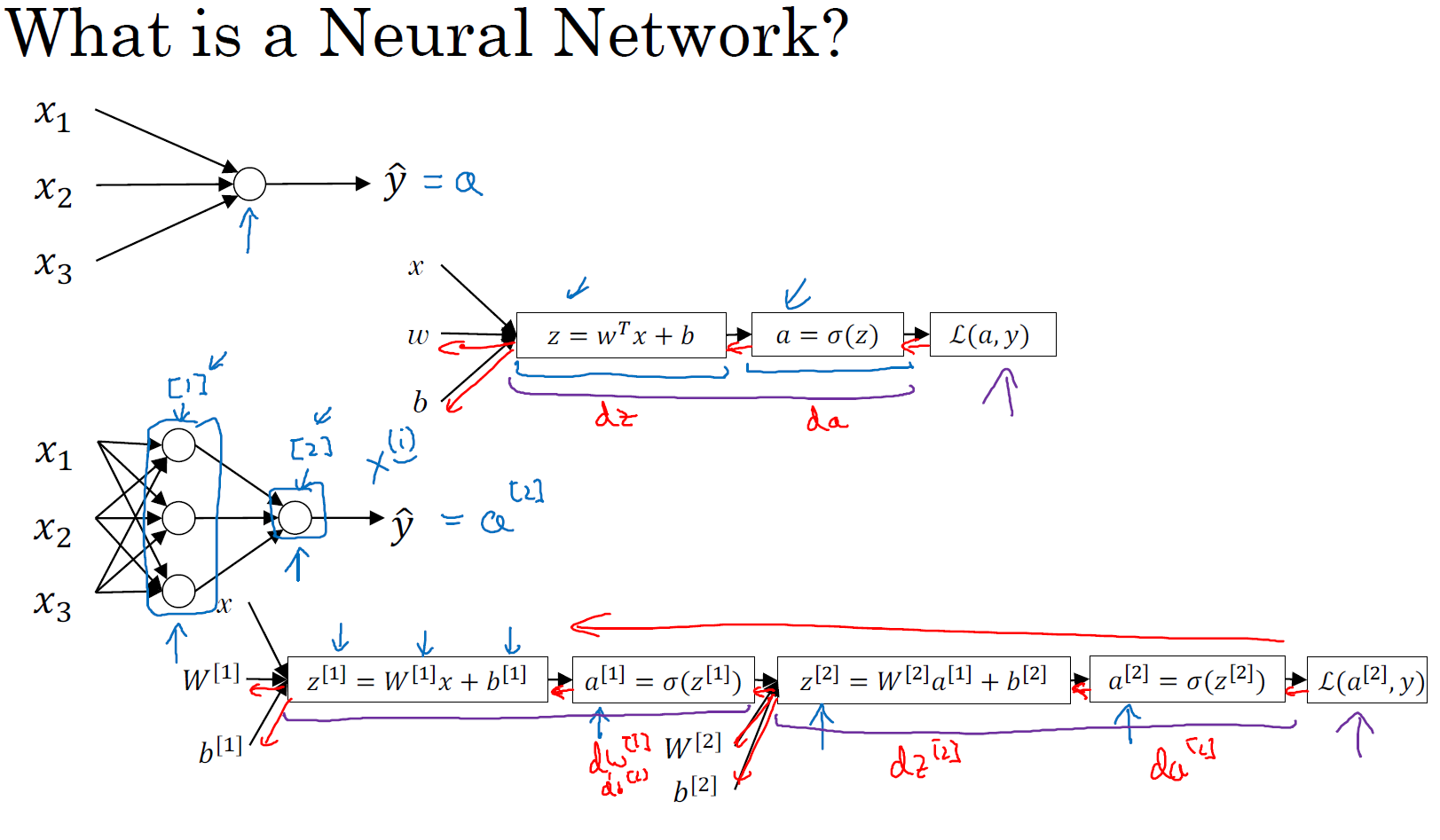
对于神经网络来说,正如我之前已经提到过,你可以把许多 sigmoid 单元堆叠起来形成一个神经网络。每个 sigmoid 单元包含了之前讲的计算的两个步骤:首先计算出 \(z\),然后通过 \(\sigma(z)\) 计算 \(a\)。
图中所示的这个神经网络对应的 3 个节点,首先计算第一层网络中的各个节点相关的数 \(z^{[1]}\),接着计算 \(a^{[1]}\),再计算下一层网络同理; 我们会使用符号 \(^{[m]}\) 表示第 \(m\) 层网络中节点相关的数,这些节点的集合被称为第 \(m\) 层网络。这样可以保证 \(^{[m]}\) 不会和我们之前用来表示单个的训练样本的 \(^{(i)}\) (即我们用来表示第 \(i\) 个训练样本)混淆,整个计算过程,如下(注:我们可以使用 \(a^{[0]}\) 表示 \(x\)):
\(\left[\begin{array}{r} a^{[0]},\ W^{[1]},\ b^{[1]} \end{array} \right] \implies{z^{[1]}=W^{[1]}x+b^{[1]}} \implies{a^{[1]} = \sigma(z^{[1]})}\)
\(\left[\begin{array}{r} a^{[1]},\ W^{[2]},\ b^{[2]} \end{array} \right] \implies{z^{[2]}=W^{[2]}a^{[1]}+b^{[2]}} \implies{a^{[2]} = \sigma(z^{[2]})}\ \implies{\mathcal{L}\left(a^{[2]},y \right)}\)
此时 \(a^{[2]}\) 就是整个神经网络最终的输出,用 \(\hat{y}\) 表示的网络输出。我知道这其中有很多细节,其中有一点非常难以理解,即在逻辑回归中,通过直接计算 \(z\) 得到结果 \(a\)。而这个神经网络中,我们反复的计算 \(z\) 和 \(a\),直到最后得到了最终的输出 loss function。
你应该记得逻辑回归中,有一些从后向前的计算用来计算导数 \(da\)、\(dz\)。同样,在神经网络中我们也有从后向前的计算,比如 \(da^{[2]}\)、\(dz^{[2]}\) 计算出来后,继续计算 \(dW^{[2]}\)、\(db^{[2]}\) 等等,从右到左反向的计算。
\(\left[\begin{array}{r} da^{[1]} = d\sigma(z^{[1]}),\ dW^{[2]},\ db^{[2]}\ \end{array} \right] \impliedby{dz}^{[2]}={d}(W^{[2]}a^{[1]}+b^{[2]}) \impliedby {da}^{[2]} = {d}\sigma(z^{[2]})\ \impliedby d\mathcal{L}\left(a^{[2]},y \right)\)
\(\left[\begin{array}{r} \qquad\qquad\qquad\;\;,\ dW^{[1]},\ db^{[1]}\ \end{array} \right] \impliedby {dz}^{[1]}={d}(W^{[1]}a^{[0]}+b^{[1]}) \impliedby da^{[1]} = d\sigma(z^{[1]})\)
现在你大概了解了什么是神经网络,基于逻辑回归重复使用了两次该模型得到上述例子的神经网络。我清楚这里面多了很多新符号和细节,如果没有理解也不用担心,在接下来的课程中我们会仔细讨论具体细节。
神经网络的表示(Neural Network Representation)
先回顾一下我在上节课画几张神经网络的图片,在本课中我们将讨论这些图片的具体含义,也就是我们画的这些神经网络到底代表什么。
我们首先关注一个例子,如图所示,本例中的神经网络只包含一个隐藏层,让我们给此图的不同部分取一些名字。
我们有输入特征 \(x_1\)、\(x_2\)、\(x_3\),它们被竖直地堆叠起来,这叫做神经网络的 输入层,它包含了神经网络的输入;然后接着是另外一层我们称之为 隐藏层,被竖直堆叠起来的 \(a_1^{[1]}\),\(a_2^{[1]}\),\(a_3^{[1]}\),\(a_4^{[1]}\),待会儿我会回过头来讲解术语 "隐藏" 的意义;在本例中最后一层只由一个结点构成 \(a^{[2]}\),而这个只有一个结点的层被称为 输出层,它负责产生预测值。
隐藏层的含义:在一个神经网络中,当你使用监督学习训练它的时候,训练集包含了输入 \(x\) 也包含了目标输出 \(y\),所以术语 隐藏层 的含义是在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。你能看见输入的值,你也能看见输出的值,但是隐藏层中的东西,在训练集中你是无法看到的。所以这也解释了词语 隐藏层,只是表示你无法在训练集中看到他们。
现在我们再引入几个符号,就像我们之前用向量 \(x\) 表示输入特征。这里有个可代替的记号 \(a^{[0]}\) 可以用来表示输入特征。\(a\) 表示激活(activation)的意思,它意味着网络中不同层的值会传递到它们后面的层中,输入层将 \(x\) 传递给隐藏层,所以我们将输入层的激活值称为 \(a^{[0]}\);下一层即隐藏层也同样会产生一些激活值,那么我将其记作 \(a^{[1]}\),所以具体地,这里的第一个单元或结点我们将其表示为 \(a_1^{[1]}\),第二个结点的值我们记为 \(a_2^{[1]}\) 以此类推。所以这里的 \(a^{[1]}\) 是一个四维(因为在本例中,我们有四个结点或者叫单元)的向量,或者称为四个隐藏层单元。如果写成 Python 代码,那么它是一个规模为 \(4 \times 1\) 的矩阵或一个大小为 4 的列向量:
\(a^{[1]} = \begin{bmatrix}a^{[1]}_1 \\ a^{[1]}_2 \\ a^{[1]}_3 \\ a^{[1]}_4\end{bmatrix}\)
最后输出层将产生某个数值 \(a\),它只是一个单独的实数,所以本例中的 \(a^{[2]}\) 就是最后的输出 \(\hat{y}\)。这与逻辑回归很相似,在逻辑回归中,我们只有一个激活单元,同时它既是激活单元也是输出层,所以在逻辑回归中我们有 \(\hat{y}\) 直接等于 \(a\)。又因为只有一个输出层,所以我们没有用带方括号的上标。但是在神经网络中,我们将使用这种带方括号上标的形式来明确地指出这些值来自于哪一层,有趣的是在约定俗成的符号传统中,现在你所看到例子只能叫做一个两层的神经网络。原因是当我们计算网络的层数时,输入层是不算入总层数内,所以隐藏层是第 1 层,输出层是第 2 层。第二个惯例是我们将输入层称为第 0 层,所以在技术上,这仍然是一个 3 层的神经网络,因为这里有 输入层、隐藏层,还有 输出层。但是在传统的符号使用中,如果你阅读研究论文或者在这门课中,你会看到人们将这个神经网络称为一个两层的神经网络,因为我们不将输入层看作一个标准的层。
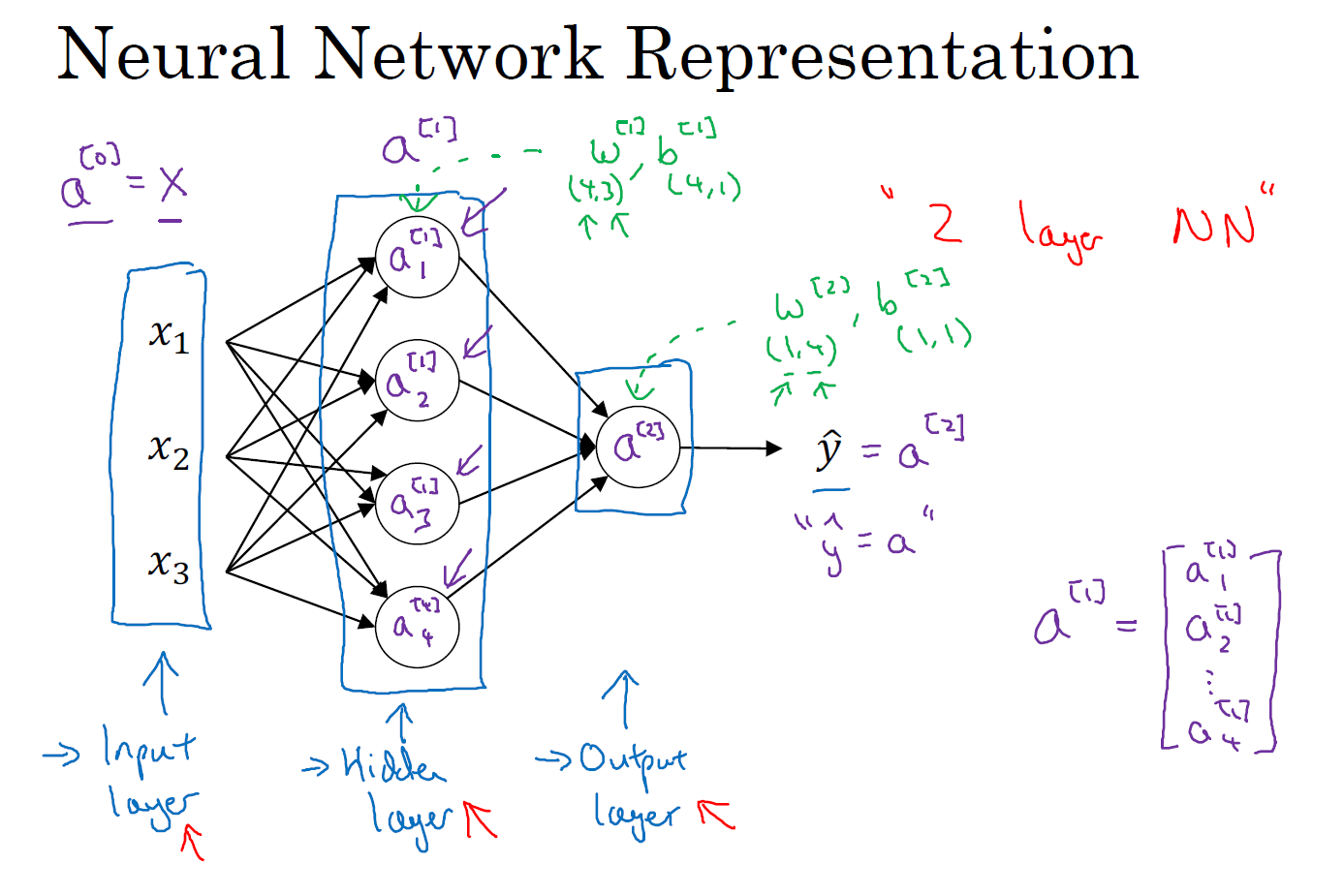
最后,我们要说的是 隐藏层 以及最后的 输出层 是带有参数的,这里的隐藏层将拥有两个参数 \(w\) 和 \(b\),我将给它们加上上标 \(^{[1]}\),即:\(w^{[1]}\) 和 \(b^{[1]}\),表示这些参数是和第一层的这个隐藏层有关系。之后在这个例子中我们会看到 \(w\) 是一个 \(4 \times 3\) 的矩阵,而 \(b\) 是一个 \(4 \times 1\) 的向量,第一个数字 4 源自于我们有四个结点或隐藏层单元,然后数字 3 源自于这里有三个输入特征,我们之后会更加详细地讨论这些矩阵的维数,到那时你可能就更加清楚了。相似的输出层也有一些与之关联的参数 \(w^{[2]}\) 以及 \(b^{[2]}\)。从维数上来看,它们的规模分别是 \(1 \times 4\) 以及 \(1 \times 1\)。\(1 \times 4\) 是因为隐藏层有四个隐藏层单元而输出层只有一个单元,之后我们会对这些矩阵和向量的维度做出更加深入的解释,所以现在你已经知道一个两层的神经网络什么样的了,即它是一个只有一个隐藏层的神经网络。
在下节课中。我们将更深入地了解这个神经网络是如何进行计算的,也就是这个神经网络是怎么输入 \(x\),然后又是怎么得到 \(\hat{y}\)。
计算一个神经网络的输出(Computing a Neural Network's output)
在上节课中,我们介绍只有一个隐藏层的神经网络的结构与符号表示。在这节课中让我们了解神经网络的输出究竟是如何计算出来的。
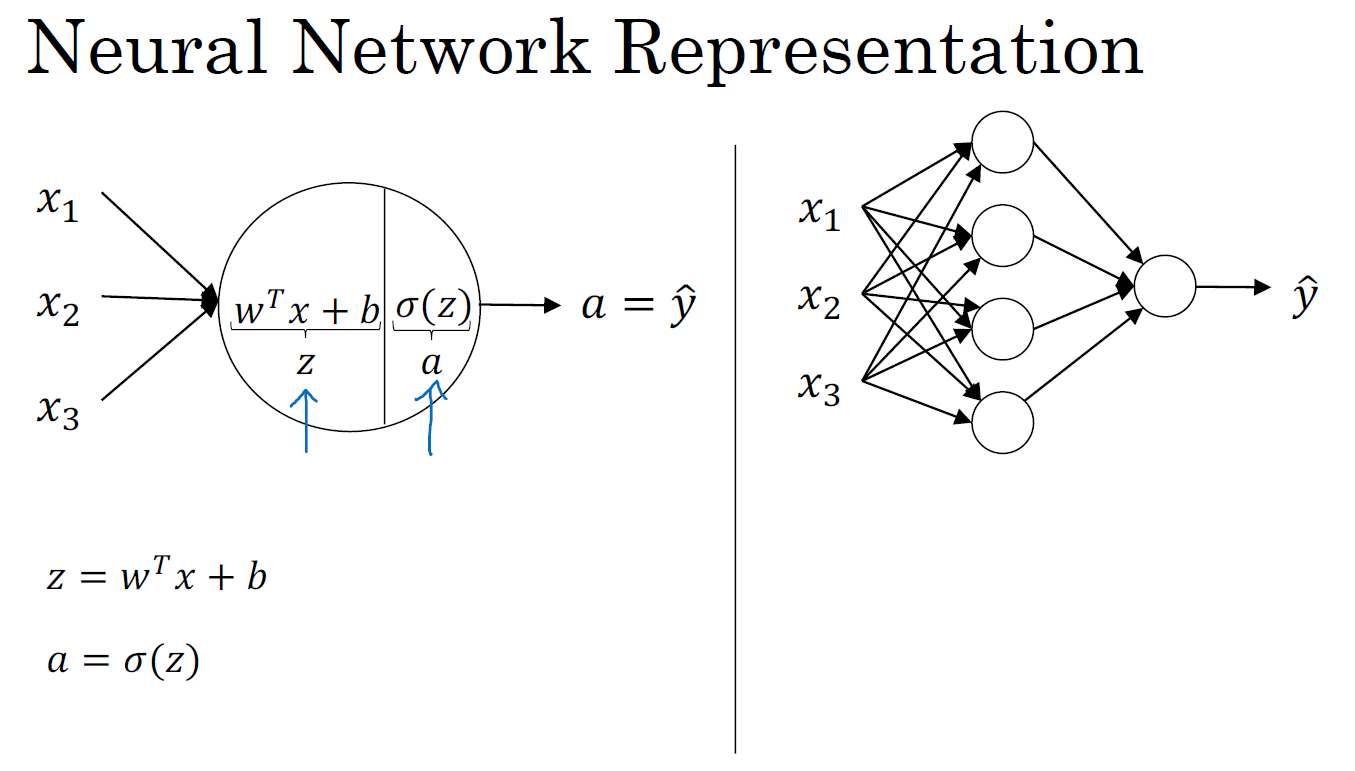
首先,回顾下只有一个隐藏层的简单两层神经网络结构。\(x\) 表示输入特征,\(a\) 表示每个神经元的输出,\(w\) 表示特征的权重,方括号上标表示神经网络的层数,下标表示该层的第几个神经元。这是神经网络的符号惯例。
关于神经网络是怎么计算的,从我们之前提及的逻辑回归开始。用圆圈表示神经网络的计算单元,逻辑回归的计算有两个步骤,首先你按步骤计算出 \(z\),然后在第二步中你以 sigmoid 函数为激活函数计算出 \(a\)。而对于一个神经网络只是这样子做了好多次重复计算。
回到两层的神经网络,我们从隐藏层的第一个神经元开始计算,输入与逻辑回归相似,这个神经元的计算与逻辑回归一样分为两步,小圆圈代表了计算的两个步骤。
Step 1:计算 \(z^{[1]}_1 = w^{[1]T}_1x + b^{[1]}_1\)
Step 2:通过激活函数计算 \(a^{[1]}_1 = \sigma(z^{[1]}_1)\)
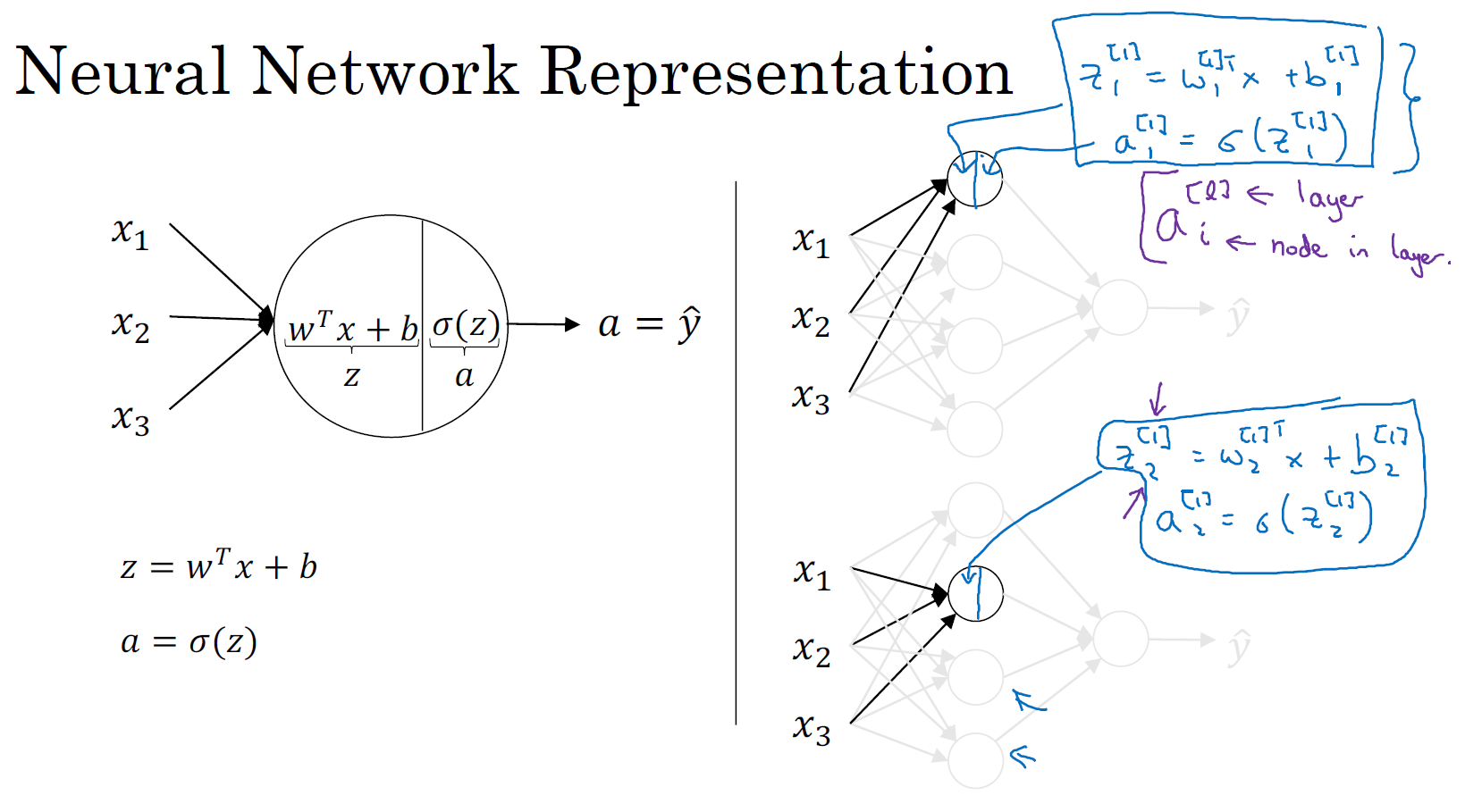
隐藏层的第二个以及后面两个神经元的计算过程一样,最终分别得到\(a^{[1]}_1、a^{[1]}_2、a^{[1]}_3、a^{[1]}_4\):
\(z^{[1]}_1 = w^{[1]T}_1x + b^{[1]}_1,\quad a^{[1]}_1 = \sigma(z^{[1]}_1)\)
\(z^{[1]}_2 = w^{[1]T}_2x + b^{[1]}_2,\quad a^{[1]}_2 = \sigma(z^{[1]}_2)\)
\(z^{[1]}_3 = w^{[1]T}_3x + b^{[1]}_3,\quad a^{[1]}_3 = \sigma(z^{[1]}_3)\)
\(z^{[1]}_4 = w^{[1]T}_4x + b^{[1]}_4,\quad a^{[1]}_4 = \sigma(z^{[1]}_4)\)
如果你执行神经网络的程序,用 for 循环来做这些看起来真的很低效。所以接下来我们要做的就是把这四个等式 向量化。向量化的过程是将神经网络中的一层的神经元参数纵向堆积起来,比如说本例中的隐藏层有四个逻辑回归单元,且每一个逻辑回归单元都有一个相对应的参数向量 \(w\),把这 4 个参数向量 \(w\) 纵向堆积起来,你会得到一个 \(4 \times 3\) 的矩阵,用大写的 \(W^{[1]}\) 表示。
\[
z^{[1]}=
\overbrace{
\begin{bmatrix}
\cdots w^{[1]T}_1 \cdots \\
\cdots w^{[1]T}_2 \cdots \\
\cdots w^{[1]T}_3 \cdots \\
\cdots w^{[1]T}_4 \cdots
\end{bmatrix}
}^{W^{[1]},\; (4 \times 3)}
\begin{bmatrix}
x_1 \\
x_2 \\
x_3
\end{bmatrix}
+
\overbrace{
\begin{bmatrix}
b^{[1]}_1 \\
b^{[1]}_2 \\
b^{[1]}_3 \\
b^{[1]}_4
\end{bmatrix}
}^{b^{[1]},\; (4 \times 1)}
=
\begin{bmatrix}
w^{[1]T}_1 x + b^{[1]}_1 \\
w^{[1]T}_2 x + b^{[1]}_2 \\
w^{[1]T}_3 x + b^{[1]}_3 \\
w^{[1]T}_4 x + b^{[1]}_4
\end{bmatrix}
=
\begin{bmatrix}
z^{[1]}_1 \\
z^{[1]}_2 \\
z^{[1]}_3 \\
z^{[1]}_4
\end{bmatrix}
\]
\[
a^{[1]}=
\begin{bmatrix}
a^{[1]}_1 \\
a^{[1]}_2 \\
a^{[1]}_3 \\
a^{[1]}_4
\end{bmatrix}
=\sigma(z^{[1]})
\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\;\;
\]
更通用的表示为:\(z^{[n]} = W^{[n]}a^{[n-1]} + b^{[n]},\quad a^{[n]} = \sigma(z^{[n]})\)
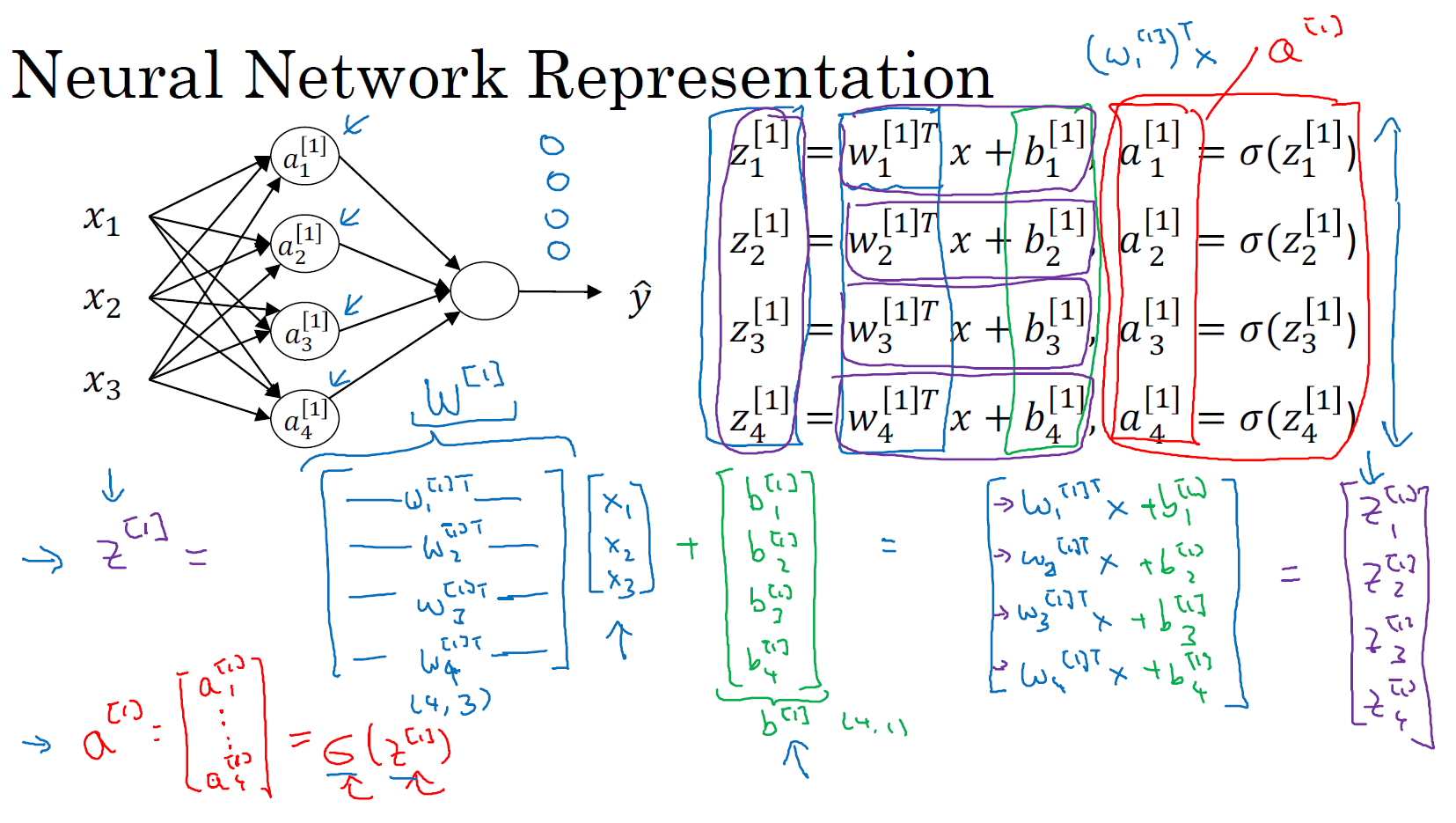
对于神经网络的第一层,给予一个输入 \(x\)(可以表示为 \(a^{[0]}\)),得到 \(a^{[1]}\)。通过相似的衍生你会发现,后一层的表示同样可以写成类似的形式,得到 \(a^{[2]}\),例子中 \(a^{[2]}\) 就是最后的输出,即:\(\hat{y} = a^{[2]}\)。
如下图左半部分所示的神经网络,把网络左边部分盖住先忽略,那么最后的输出单元就相当于一个逻辑回归的计算单元。当你有一个包含一层隐藏层的神经网络,你需要去实现用来计算得到输出的是右边的四个等式,并且可以看成是一个向量化的计算过程,计算出隐藏层的四个逻辑回归单元和整个隐藏层的输出结果,如果编程实现需要的也只是这四行代码。
总结:通过本节课,你能够根据给出的一个单独的输入特征向量,运用四行代码计算出一个简单神经网络的输出。接下来你将了解的是如何一次能够计算出不止一个样本的神经网络输出,而是能一次性计算整个训练集的输出。届时,本节课中所使用的符号 \(z^{[n]}\)、\(a^{[n]}\) 都将改成使用大写的版本 \(Z^{[n]}\)、\(A^{[n]}\) 用以区分和单样本向量计算的不同。
多样本向量化(Vectorizing across multiple examples)
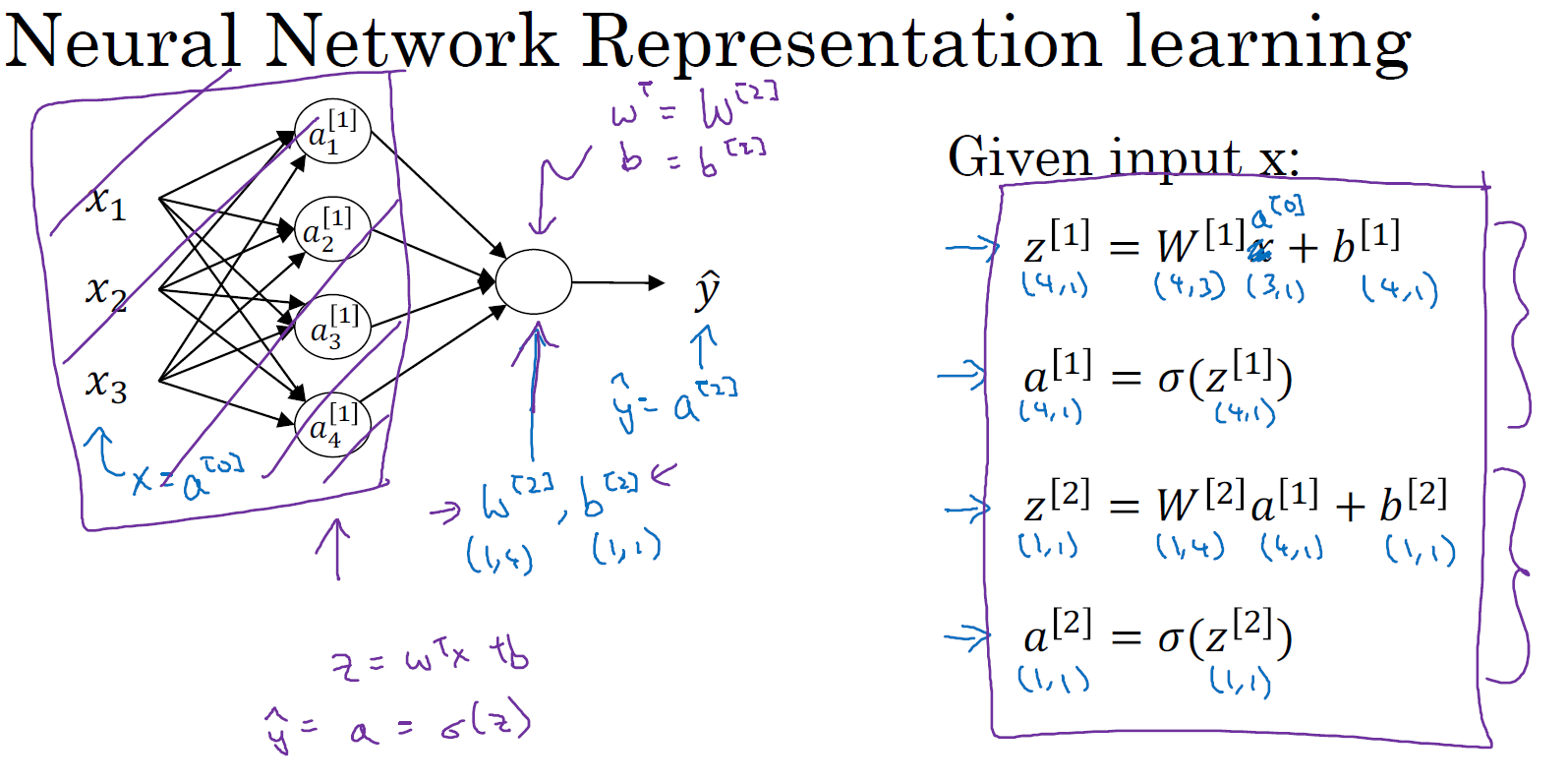
在上节课,了解到如何针对于单一的训练样本,在神经网络上计算出预测值。在本节课,将会了解到如何向量化多个训练样本,并计算出结果。该过程与你在逻辑回归中所做类似。
逻辑回归的全样本向量化计算过程是将各个训练样本组合成矩阵,然后对矩阵的各列进行计算。神经网络是通过对逻辑回归中的等式简单的变形,让神经网络计算出输出值。这种计算是所有的训练样本同时进行的,以下是实现它具体的步骤:
上节课中得到的四个等式,它们给出如何计算出 \(z^{[1]}\),\(a^{[1]}\),\(z^{[2]}\),\(a^{[2]}\)。对于一个给定的输入特征向量 \(x\),这四个等式可以计算出 \(a^{[2]} = \hat{y}\)。这是针对于单一的训练样本。如果有 \(m\) 个训练样本,那么就需要重复这个过程。比如说用第一个训练样本 \(x^{(1)}\) 来计算出预测值 \(a^{[2](1)} = \hat{y}^{(1)}\),就是第一个训练样本上得出的结果。然后,用 \(x^{(2)}\) 来计算出预测值 \(a^{[2](2)} = \hat{y}^{(2)}\),循环往复,直至用 \(x^{(m)}\) 计算出 \(a^{[2](m)} = \hat{y}^{(m)}\)。
如果有一个非向量化形式的实现,而且要对于所有的训练样本计算出它的预测值,需要让 \(i\) 从 1 到 \(m\) 实现这四个等式:
for i = 1 to m:
\(\quad\quad z^{[1](i)} = w^{[1]}x^{(i)} + b^{[1]}\)
\(\quad\quad a^{[1](i)} = \sigma(z^{[1](i)})\)
\(\quad\quad z^{[2](i)} = w^{[2](i)}a^{[1](i)} + b^{[2]}\)
\(\quad\quad a^{[2](i)} = \sigma(z^{[2](i)})\)
对于上面的这个方程(代码)中的 \(^{(i)}\),是所有依赖于训练样本的变量,即:将 \((i)\) 添加到 \(x\),\(z\) 和 \(a\)。如果想计算 \(m\) 个训练样本上的所有输出,就应该向量化整个计算,以简化这个 \(^{(i)}\)。

接下来讲讲究竟如何正确的向量化它们,首先定义矩阵 \(X\) 等于训练样本,将每一个样本组合成矩阵的各列,形成一个 \(n_x \times m\) 维的矩阵(水平方向扫描索引到各个训练样本,垂直方向扫描索引到不同的输入特征):
\(x = \begin{bmatrix} \vdots & \vdots & & \vdots \\ x^{(1)} & x^{(2)} & \cdots & x^{(m)} \\ \vdots & \vdots & & \vdots \end{bmatrix}\)
同理,\(z^{[1](1)}\),\(z^{[1](2)}\),...,\(z^{[1](m)}\) 都是 \(z^{[1]}\) 的列向量,将所有 \(m\) 都组合在各列中,就的到矩阵 \(Z^{[1]}\)(水平方向扫描索引到各个训练样本,垂直方向扫描索引到神经网络中不同的节点或者叫隐藏单元):
\(Z^{[1]} = \begin{bmatrix} \vdots & \vdots & & \vdots \\ z^{[1](1)} & z^{[1](2)} & \cdots & z^{[1](m)} \\ \vdots & \vdots & & \vdots \end{bmatrix}\)
同理,\(a^{[1](1)}\),\(a^{[1](2)}\),...,\(a^{[1](m)}\) 将其组合在矩阵各列中,如同从向量 \(x\) 到矩阵 \(X\),以及从向量 \(z\) 到矩阵 \(Z\) 一样,就能得到矩阵 \(A^{[1]}\)(水平方向扫描索引到各个训练样本,垂直方向扫描索引到神经网络中不同的节点或者叫隐藏单元):
\(A^{[1]} = \begin{bmatrix} \vdots & \vdots & & \vdots \\ a^{[1](1)} & a^{[1](2)} & \cdots & a^{[1](m)} \\ \vdots & \vdots & & \vdots \end{bmatrix}\)
同样的,对于 \(Z^{[2]}\) 和$ A^{[2]}$,也是这样得到。
最后向量化计算的式子表示为:
\(Z^{[1]} = W^{[1]}X + b^{[1]}\)
\(A^{[1]} = \sigma(Z^{[1]})\)
\(Z^{[2]} = W^{[2]}A^{[1]} + b^{[2]}\)
\(A^{[2]} = \sigma(Z^{[2]})\)

这就是神经网络在所有样本情况下计算网络输出的向量化实现。在下节课中,将证明为什么这是一种正确向量化的实现,这种证明将会与逻辑回归中的证明类似。
向量化实现的解释(Justification for vectorized implementation)
在上节课中,我们学习到如何将多个训练样本横向堆叠成一个矩阵 \(X\),然后就可以推导出神经网络中前向传播(forward propagation)部分的向量化实现。在本节课中,我们将会继续了解到,为什么上一节中写下的公式就是将所有样本向量化的正确实现。
为了描述的简便,我们先忽略掉 \(b^{[1]}\)。现在 \(W^{[1]}\) 是一个矩阵,这个矩阵水平方向扫描索引到神经网络中各个节点上对应到各个特征的参数,垂直方向扫描索引到神经网络中不同的节点或者叫隐藏单元。\(x^{(1)}\),\(x^{(2)}\), \(x^{(3)}\) 都是列向量,且已经被堆叠到矩阵 \(X\),下面将它们用直观的方式表示出来:
\[
W^{[1]} X =
\begin{bmatrix}
\cdots & w^{[1]T}_1 & \cdots \\
\cdots & w^{[1]T}_2 & \cdots \\
& \vdots &
\end{bmatrix}
\begin{bmatrix}
\vdots & \vdots & \\
x^{(1)} & x^{(2)} & \cdots\\
\vdots & \vdots &
\end{bmatrix}
=
\begin{bmatrix}
\vdots &\vdots & \\
w^{[1]}x^{(1)} & w^{[1]}x^{(2)} & \cdots \\
\vdots &\vdots &
\end{bmatrix}
=
\begin{bmatrix}
\vdots &\vdots & \\
z^{[1](1)} & z^{[1](2)} & \cdots \\
\vdots &\vdots &
\end{bmatrix}
=
Z^{[1]}
\]
所以从这里我们也可以了解到,为什么之前我们对单个样本的计算要写成 \(z^{[1]} = W^{[1]}x^{(i)} + b^{[1]}\) 这种形式,因为当有不同的训练样本时,将它们堆到矩阵 \(X\) 的各列中,那么它们的输出也就会相应的堆叠到矩阵 \(Z^{[1]}\) 的各列中。现在我们就可以直接计算矩阵 \(Z^{[1]}\) 加上 \(b^{[1]}\),因为列向量 \(b^{[1]}\)(该列向量是由该层所有隐藏单元的偏置单元组成的,即:一个隐藏单元一个偏置项)和矩阵 \(Z^{[1]}\) 的列向量有着相同的尺寸,而 Python 的广播机制对于这种矩阵与向量直接相加的处理方式是,将向量与矩阵的每一列相加。所以这一节只是说明了为什么公式 \(Z^{[1]} =W^{[1]}X + \ b^{[1]}\) 是前向传播的第一步计算的正确向量化实现,但事实证明,类似的分析可以发现,前向传播的其它步也可以使用非常相似的逻辑。而且还有一点就是,如果将输入按列向量横向追加堆叠进矩阵,那么通过公式计算之后,也能得到成列追加堆叠的输出。
最后,对本节课的内容做一个总结:使用向量化的方法,可以不需要显示循环,而直接通过矩阵运算从 \(X\) 就可以计算出 \(A^{[1]}\),实际上 \(X\) 可以记为 \(A^{[0]}\),使用同样的方法就可以由神经网络中的每一层的输入 \(A^{[i-1]}\) 计算输出 \(A^{[i]}\)。
\(Z^{[1]} = W^{[1]}X + b^{[1]}\)
\(A^{[1]} = \sigma(Z^{[1]})\)
\(Z^{[2]} = W^{[2]}A^{[1]} + b^{[2]}\)
\(A^{[2]} = \sigma(Z^{[2]})\)
其实这些方程有一定对称性,其中第一个方程也可以写成 \(Z^{[1]} = W^{[1]}A^{[0]} + b^{[1]}\),你看第一个和第三个方程,还有第二个和第四个方程形式其实很类似,只不过所有方括号内的指标都加了 1。所以这样就显示出神经网络的不同层次,你知道大概每一步做的都是一样的,或者只不过同样的计算不断重复而已。这里我们有一个双层神经网络,我们在下周的课程里会讲深得多的神经网络,你看到随着网络的深度变大,基本上也还是重复这两步运算,只不过是比这里你看到的重复次数更多。在下周的课程中将会讲解更深层次的神经网络,随着层数的加深,基本上也还是重复同样的运算。
以上就是对神经网络向量化实现的正确性的解释,到目前为止,我们仅使用 sigmoid 函数作为激活函数,事实上这并非最好的选择,在下节课中,将会继续深入的讲解如何使用更多不同种类的激活函数。
激活函数(Activation functions)
使用一个神经网络时,需要决定使用哪种激活函数用隐藏层上,哪种用在输出节点上。到目前为止,之前的课程只用过 sigmoid 激活函数,但是,有时其他的激活函数效果会更好。
在神经网路的前向传播中,\(a^{[1]} = \sigma(z^{[1]})\) 和 \(a^{[2]} =\sigma(z^{[2]})\) 这两步会使用到 sigmoid 函数。sigmoid 函数在这里被称为激活函数,\(a = \sigma(z) = \frac{1}{{1 + e}^{- z}}\)。
更通常的情况下,使用不同的函数 \(g( z^{[1]})\),\(g\) 可以是除了 sigmoid 函数以外的其它非线性函数。tanh(双曲正切)函数总体上都优于 sigmoid 函数的激活函数。
\(a = tan(z) = \frac{e^{z} - e^{- z}}{e^{z} + e^{- z}}\),事实上,tanh 函数是 sigmoid 的向下平移和伸缩后的结果。对它进行了变形后,穿过了 \((0,0)\) 点,并且值域介于 +1 和 -1 之间。
结果表明,如果在隐藏层上使用函数 \(g(z^{[1]}) = tanh(z^{[1]})\) 效果总是优于 sigmoid 函数。因为函数值域在 -1 和 +1 的激活函数,其均值是更接近零均值的。在训练一个算法模型时,如果使用 tanh 函数代替 sigmoid 函数中心化数据,使得数据的平均值更接近 0 而不是 0.5,这会使下一层学习简单一点,在第二门课中会详细讲解。
在讨论优化算法时,有一点要说明:我基本已经不用 sigmoid 激活函数了,tanh 函数在所有场合都优于 sigmoid 函数。但有一个例外:在二分类的问题中,对于输出层,因为 \(y\) 的值是 0 或 1,所以想让 \(\hat{y}\) 的数值介于 0 和 1 之间,而不是在 -1 和 +1 之间。所以需要使用 sigmoid 激活函数。从下图中这个例子可以看到,我们对隐藏层使用了 tanh 激活函数,而对输出层使用 sigmoid 函数,即:\(g(z^{[2]}) = \sigma(z^{[2]})\)。
所以,在不同的神经网络层中,激活函数可以不同。为了表示不同的激活函数,在不同的层中,使用方括号上标来指出 \(g\) 上标为 \([1]\) 的激活函数,可能会跟 \(g\) 上标为 \([2]\) 不同。方括号上标 \([1]\) 代表隐藏层,方括号上标 \([2]\) 表示输出层。

sigmoid 函数和 tanh 函数两者共同的缺点是,在 \(z\) 特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于 0,导致降低梯度下降的速度。
在机器学习另一个很流行的函数是:修正线性单元的函数 ReLU,\(a = max(0,z)\)。只要 \(z\) 是正值的情况下,导数恒等于 1,当 \(z\) 是负值的时候,导数恒等于 0。从实际上来说,当使用 \(z\) 的导数时,\(z=0\) 时的导数是没有定义的。但是当编程实现的时候,\(z\) 的取值刚好是 0.0000000000 的概率很低,所以不用担心这个。你也可以在 \(z=0\) 时,给它的导数赋值 0 或 1 都可以。
这有一些选择激活函数的经验法则:如果输出是 0、1值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 ReLU 函数。这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 ReLU 激活函数。有时,也会使用 tanh 激活函数,ReLU 的一个缺点是:当 \(z\) 是负值的时候,导数等于 0,在实践中这没什么问题。ReLU 还有另外一个版本叫 Leaky ReLU。当 \(z\) 是负值时,这个函数的导数不是为 0,而是有一个平缓的斜率。这个函数通常比 ReLU 激活函数效果要好,尽管在实际中 Leaky ReLU 使用的并不多。这些选一个就好了,我通常只用 ReLU。
ReLU 和 Leaky ReLU 的优点是:
第一,在 \(z\) 的区间变动很大的情况下(for a lot of the space of \(Z\)),激活函数的导数或者说斜率都会远大于 0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中,使用 ReLU 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
第二,sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成 梯度弥散,而 ReLU 和 Leaky ReLU 函数大于 0 部分都为常数,不会产生梯度弥散现象。同时应该注意到的是,ReLU 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的 稀疏性,而 Leaky ReLU 不会有这问题。另外,虽说 \(z\) 在 ReLU 的梯度一半都是 0,但是,有足够的隐藏层使得 \(z\) 的值大于 0,所以对大多数的训练数据来说学习过程仍然可以很快。
快速概括一下不同激活函数的优缺点(Pros and cons of activation functions):
sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
tanh 激活函数:tanh 是非常优秀的,几乎适合所有场合。
ReLU 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLU 或者 Leaky ReLU。对于 Leaky ReLU 激活函数 \(a = max(0.01z,z)\) 来说,为什么常数是 0.01 ?当然,你也可以尝试为学习算法选择不同的参数。

在选择自己神经网络的激活函数时,有一定的直观感受,在深度学习中的经常遇到一个问题:在编写神经网络的时候,会有很多选择:隐藏层单元的个数、激活函数的选择、初始化权值……这些选择想得到一个相对比较好的指导原则是挺困难的。
鉴于以上三个原因,以及在工业界的见闻,提供一种直观的感受,哪一种工业界用的多,哪一种用的少。但是,自己的神经网络的应用,以及其特殊性,是很难提前知道选择哪些效果更好。所以通常的建议是:如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在交叉验证集或者在我们稍后会讲到的开发集上跑跑,看看哪一个表现好,就用哪个。在你的应用中自己多尝试下不同的选择,很可能你会搭建出具有前瞻性的神经网络架构,可以对你的问题的特质更有针对性,让你的算法迭代更流畅。这里不会告诉你一定要使用 ReLU 激活函数,而不用其他的,因为 ReLU 激活函数对你现在或未来要处理的问题而言,可能管用,也可能不管用。
为什么需要非线性激活函数?(why need a nonlinear activation function?)
为什么神经网络需要非线性激活函数?事实证明:要让你的神经网络能够计算出有趣的函数,你必须使用非线性激活函数。
见下图中的神经网络正向传播方程,现在我们去掉函数 \(g\),然后令 \(a^{[1]} = z^{[1]}\),或者我们也可以令 \(g(z)=z\),这个有时被叫做 线性激活函数(更学术点的名字是 恒等激励函数,因为它们就是把输入值输出)。为了说明问题,我们令 \(a^{[2]} = z^{[2]}\),那么这个模型的输出 \(y\) 或仅仅只是输入特征 \(x\) 的线性组合。
如果我们用上面所说的方式改变这些方程,令:
(1) \(a^{[1]} = z^{[1]} = W^{[1]}x + b^{[1]}\)
(2) \(a^{[2]} = z^{[2]} = W^{[2]}a^{[1]}+ b^{[2]}\) 将式子 (1) 代入式子 (2) 中,则:\(a^{[2]} = z^{[2]} = W^{[2]}(W^{[1]}x + b^{[1]}) + b^{[2]}\)
(3) $a^{[2]} = z^{[2]} = W^{[2]}W^{[1]}x + W^{[2]}b^{[1]} + b^{[2]} $,简化多项式得 $a^{[2]} = z^{[2]} = W^{'}x + b^{'} $,如果你是用线性激活函数或者叫恒等激励函数,那么神经网络做的只是把输入线性组合之后再输出。

我们稍后会谈到深度网络,有很多层的神经网络,很多隐藏层。事实证明,如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。在我们的简明案例中,事实证明如果你在隐藏层用线性激活函数,在输出层用 sigmoid 函数,那么这个模型的复杂度和没有任何隐藏层的标准 Logistic 回归是一样的,如果你愿意的话,可以证明一下。
在这里线性隐层一点用也没有,因为这两个线性函数的组合本身就是线性函数,所以除非你引入非线性,否则你无法计算更有趣的函数,即使你的网络层数再多也不行;只有一个地方可以使用线性激活函数 \(g(z)=z\),就是你在做机器学习中的回归问题。\(y\) 是一个实数,举个例子,比如你想预测房地产价格,\(y\) 就不是二分类任务 0 或 1,而是一个实数,从 0 到正无穷。如果 \(y\) 是个实数,那么在输出层用线性激活函数也许可行,你的输出也是一个实数,从负无穷到正无穷。
总而言之,不能在隐藏层用线性激活函数,可以用 ReLU 或者 tanh 或者 Leaky ReLU 或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层;除了这种情况,会在隐层用线性函数的,还有一些特殊情况,比如与压缩有关的,那方面在这里将不深入讨论。在这之外,在隐藏层使用线性激活函数非常少见。另外,因为房价都是非负数,所以我们也可以在输出层使用 ReLU 函数这样你的 \(\hat{y}\) 都大于等于 0。
理解为什么使用非线性激活函数对于神经网络十分关键,接下来我们将在下节课中开始讨论梯度下降的基础————激活函数的导数。
激活函数和损失函数的导数(Derivatives of activation functions and loss function)
在神经网络中使用反向传播的时候,你需要计算激活函数和损失函数的斜率或者导数。这节课我们将探究一下之前提到过的四种激活函数以及损失函数的导数。
sigmoid activation function
\(\widehat{y} = a = \sigma(z) = \frac{1}{1+e^{-z}}\)
\(\sigma(z)\) 在 \(z\) 点的导数 \(\sigma'(z)\)(slope of \(\sigma\)(z) at z) 推导如下:
\[
\begin{align}
\sigma'(z) = \frac{\mathrm{d}a}{\mathrm{d}z}= & (\frac{1}{1+e^{-z}})' \\
= & \Big((1+e^{-z})^{-1}\Big)' \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot (1 + e^{-z})' \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot (e^{-z})' \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot ((e^z)^{-1})' \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot (-1) \cdot (e^z)^{-2} \cdot (e^z)' \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot (-1) \cdot (e^z)^{-2} \cdot e^z \\
= & (-1) \cdot (1 + e^{-z})^{-2} \cdot (-1) \cdot (e^z)^{-1} \\
= & (1 + e^{-z})^{-2} \cdot (e^{-z}) \\
= & \frac{e^{-z}}{(1 + e^{-z})^{2}} \\
= & \frac{1}{1 + e^{-z}} \cdot \frac{e^{-z}}{1 + e^{-z}} \\
= & \frac{1}{1 + e^{-z}} \cdot (1 - \frac{1}{1 + e^{-z}}) \\
= & g(z) \cdot \Big(1 - g(z)\Big) \\
= & a \cdot (1-a)
\end{align}
\]

当 \(z\) = 10 时,g(z) \(\approx\) 1, g'(z) \(\approx 1 \cdot (1 - 1) \approx 0\)
当 \(z\) = -10 时,g(z) \(\approx\) 0, g'(z) \(\approx 0 \cdot (1 - 0) \approx 0\)
当 \(z\) = 0 时,g(z) = \(\frac{1}{2}\), g'(z) = \(\frac{1}{2}(1 - \frac{1}{2}) = \frac{1}{4}\)
Hyperbolic Tangent (Tanh)
\(g(z) = tanh(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}\)
\(g(z)\) 在 \(z\) 点的导数 \(g'(z)\)(slope of g(z) at z) 推导如下:
\[
\begin{align}
g'(z) = \frac{\mathrm{d}a}{\mathrm{d}z} = & \left( \frac{e^z - e^{-z}}{e^z + e^{-z}} \right)' \\
= & \frac{(e^z - e^{-z})'(e^z + e^{-z}) - (e^z - e^{-z})(e^z + e^{-z})'}{(e^z + e^{-z})^2} \\
= & \frac{\left[ (e^z)' - (e^{-z})' \right](e^z + e^{-z}) - (e^z - e^{-z}) \left[ (e^z)' + (e^{-z})' \right]}{(e^z + e^{-z})^2} \\
= & \frac{\left[ e^z - e^{-z} \cdot (-z)' \right](e^z + e^{-z}) - (e^z - e^{-z}) \left[ e^z + e^{-z} \cdot (-z)' \right]}{(e^z + e^{-z})^2} \\
= & \frac{\left[ e^z - e^{-z} \cdot (-1) \right](e^z + e^{-z}) - (e^z - e^{-z}) \left[ e^z + e^{-z} \cdot (-1) \right]}{(e^z + e^{-z})^2} \\
= & \frac{(e^z + e^{-z})(e^z + e^{-z}) - (e^z - e^{-z}) (e^z - e^{-z})}{(e^z + e^{-z})^2} \\
= & \frac{(e^z + e^{-z})^2 - (e^z - e^{-z})^2}{(e^z + e^{-z})^2} \\
= & 1 - \left( \frac{e^z - e^{-z}}{e^z + e^{-z}} \right)^2 \\
= & 1 - \left( \mathrm{tanh}(z) \right)^2 = 1 - \left( g(z) \right)^2 \\
= & 1 - a^2
\end{align}
\]

当 \(z\) = 10 时,tanh(z) \(\approx\) 1, g'(z) \(\approx\) 0
当 \(z\) = -10 时,tanh(z) \(\approx\) -1, g'(z) \(\approx\) 0
当 \(z\) = 0 时,tanh(z) = 0, g'(z) = 1
Rectified Linear Unit (ReLU)
\(g(z)=\max(0, z)\)
\(g'(z)= \begin{cases} 0 & \text{if z < 0} \\ 1 & \text{if z > 0} \\ \text{undefined} & \text{if z = 0} \end{cases}\)
ReLU 导数为 0 或 1,通常在 \(Z = 0\) 的时候导数 undefined,直接将导数赋值 0 或 1;当然 \(Z = 0.000000000\) 的概率很低。

Leaky Rectified Linear Unit (Leaky ReLU)
\(g(z)=\max(0.01z, z)\)
\(g'(z) = \begin{cases} 0.01 & \text{if z < 0} \\ 1 & \text{if z > 0} \\ \text{undefined} & \text{if z = 0} \end{cases}\)
Leaky ReLU 导数为 0.01 或 1,通常在 \(Z = 0\) 的时候导数 undefined,直接将导数赋值 0.01 或 1;当然 \(Z = 0.000000000\) 的概率很低。

loss function
\(\mathcal{L}(a, y) = -y \cdot log(a) - (1- y) \cdot log (1 - a)\)
\(\mathcal{L}\) 在 \(a\) 点的导数,推导过程如下:
\[
\begin{align}
\frac{\mathrm{d}\mathcal{L}(a, y)}{\mathrm{d}a}
= & \left[ -y \cdot log(a) - (1- y) \cdot log (1 - a) \right]' \\
= & -y \cdot \left( log(a) \right)' - (1-y) \cdot \left( log (1 - a) \right)' \\
= & -y \cdot \frac{1}{a} - (1-y) \cdot \frac{1}{1-a} \cdot (1-a)' \\
= & - \frac{y}{a} - \frac{1-y}{1-a} \cdot (-1) \\
= & \frac{1-y}{1-a} - \frac{y}{a}
\end{align}
\]
二分类时,以 sigmoid 做输出层的网络比较常见,此处给出 dz 的导数推导:
\[
\begin{align}
\mathrm{d}z \text{(variable in python)} = & \frac{\mathrm{d}\mathcal{L}(a,y)}{\mathrm{d}z} = \frac{\mathrm{d}\mathcal{L}}{\mathrm{d}a} \cdot \frac{\mathrm{d}a}{\mathrm{d}z} \\
= & \left( \frac{1-y}{1-a} - \frac{y}{a} \right) \cdot a(1-a) \\
= & a - y
\end{align}
\]
还有 softmax 做输出层的场景,以后回过头再补充。
神经网络的梯度下降(Gradient descent for neural networks)
在这节课中,我会给你实现反向传播或者说梯度下降算法的方程组,在下节课我们会介绍为什么这几个特定的方程是针对你的神经网络实现梯度下降的正确方程。
你的单隐层神经网络会有 \(W^{[1]}\),\(b^{[1]}\),\(W^{[2]}\),\(b^{[2]}\) 这些参数,还有个 \(n_x\) 表示输入特征的个数,\(n^{[1]}\) 表示隐藏单元个数,\(n^{[2]}\) 表示输出单元个数。
那么参数矩阵 \(W^{[1]}\) 的维度就是 (\(n^{[1]}, n^{[0]}\)),\(b^{[1]}\) 就是 \(n^{[1]}\) 维向量,可以写成 \((n^{[1]}, 1)\),就是一个列向量。参数矩阵 \(W^{[2]}\) 的维度就是 (\(n^{[2]}, n^{[1]}\)),\(b^{[2]}\) 的维度就是 \((n^{[2]},1)\) 维度。
你还有一个神经网络的成本函数,假设你在做二分类任务,那么你的成本函数(Cost function)为:\(J(W^{[1]},b^{[1]},W^{[2]},b^{[2]}) = {\frac{1}{m}}\sum\limits_{i=1}^m \mathcal{L}(\hat{y}, y)\),其中 loss function 和之前的 logistic 回归完全一样。并且此处的 \(\hat y\) 就是 \(a^{[2]}\)。
训练参数需要做 梯度下降,在训练神经网络的时候,随机初始化参数很重要,而不是初始化成全零。当你参数初始化成某些值后,每次梯度下降都会循环计算以下预测值:
Repeat{
Compute predict \((\hat{y}^{(i)}, i=1,2,…,m)\)
\(dW^{[1]} = \frac{dJ}{dW^{[1]}}\), \(db^{[1]} = \frac{dJ}{db^{[1]}}\)
\(dW^{[2]} = \frac{dJ}{dW^{[2]}}\), \(db^{[2]} = \frac{dJ}{db^{[2]}}\)
\(W^{[1]} = {W^{[1]} - \alpha \ dW^{[1]}}\), \(b^{[1]} = {b^{[1]} - \alpha \ db^{[1]}}\)
\(W^{[2]} = {W^{[2]} - \alpha \ dW^{[2]}}\), \(b^{[2]} = {b^{[2]} - \alpha \ db^{[2]}}\)
}
Formulas for computing derivatives
正向传播(forward propagation)方程如下:
\(Z^{[1]} = W^{[1]}X + b^{[1]}\)
\(A^{[1]} = g^{[1]}(Z^{[1]})\)
\(Z^{[2]} = W^{[2]}A^{[1]} + b^{[2]}\)
\(A^{[2]} = g^{[2]}(Z^{[2]}) = \sigma(z^{[2]})\)
反向传播(back propagation)方程如下:
\(dZ^{[2]} = A^{[2]} - Y,\quad Y = \begin{bmatrix}y^{[1]} & y^{[2]} & \cdots & y^{[m]}\ \end{bmatrix}\)
\(dW^{[2]} = \frac{1}{m} dZ^{[2]} {A^{[1]}}^T\)
\(db^{[2]} = \frac{1}{m} np.sum(dZ^{[2]}, axis=1, keepdims = True)\)
\(dZ^{[1]} = \underbrace{{W^{[2]}}^T dZ^{[2]}}_{(n^{[1]},m)} \underbrace{\times}_{\text{element-wise product}} {g^{[1]}}^{'} \underbrace{(Z^{[1]})}_{(n^{[1]},m)}\)
\(dW^{[1]} = \frac{1}{m} dZ^{[1]}X^{T}\)
\({\underbrace{db^{[1]}}_{(n^{[1]},1)}} = \frac{1}{m} np.sum(\underbrace{dZ^{[1]}}_{(n^{[1]},)}, axis=1, \underbrace{keepdims=True}_{\text{reshape}})\)
上述是反向传播的步骤,这些都是针对所有样本进行过向量化的,\(Y\) 是 \(1 \times m\) 的矩阵;这里 np.sum 是 Python 的 numpy 命令,axis=1 表示水平相加求和,keepdims 是防止 Python 输出那些古怪的秩为 1 的数组 \((n,)\),加上这个确保阵矩阵 \(db^{[2]}\) 这个向量输出的维度为 \((n,1)\) 这样标准的形式。如果不使用 keepdims,可以可以使用 reshape 显性指明数组的维度。
目前为止,我们计算的都和 Logistic 回归十分相似,但当你开始计算反向传播时,你需要计算的是隐藏层函数的导数,输出层使用 sigmoid 函数进行二元分类。因为 \({W^{[2]}}^T dZ^{[2]}\) 和 \((Z^{[1]})\) 这两个都为 \((n^{[1]},m)\) 矩阵,所以们之间的乘积是逐个元素乘积(element-wise product)。
以上就是正向传播的 4 个方程和反向传播的 6 个方程,这里我是直接给出的,在下节课中,我会讲如何推导出反向传播的这 6 个式子的。如果你要实现这些算法,你必须正确执行正向和反向传播运算,你必须能计算所有需要的导数,用梯度下降来学习神经网络的参数;你也可以向许多成功的深度学习从业者一样直接实现这个算法,不去了解其中的知识。
(选修)直观理解反向传播(Backpropagation intuition)
这节课主要是推导反向传播。
回想当时我们讨论逻辑回归的时候,我们有这个正向传播步骤,先计算 \(z\),然后 \(a\),然后再到损失函数 \(L\):
\([\begin{array}{l} {x}\ {w}\ {b} \end{array}] \implies{z={w}^Tx+b} \implies{a = \sigma(z)} \implies{\mathcal{L}\left(a,y \right)}\)
以及反向传播的步骤,我们会计算 \(da\),然后 \(dz\),再到 \(dw\) 和 \(db\)。
\[
\underbrace{[x \ w \ b]}_{dw=dz \cdot x, \\ db=dz}
\impliedby
\underbrace{z=w^Tx+b}_{dz=da \cdot g'(z) \\ g(z)=\sigma(z) \\ \frac{dL}{dz}=\frac{dL}{da} \cdot \frac{da}{dz} \\ \frac{d}{dz} g(z)=g^{'}(z)}
\impliedby
\underbrace{{a=\sigma(z)} \impliedby{\mathcal{L}(a,y)}}_{da={\frac{d}{da}}{\mathcal{L}}\left(a,y\right) \\ =(-y\log{\alpha}-(1-y)\log(1-a))^{'} \\ =-\frac{y}{a} + \frac{1-y}{1-a}}
\]

神经网络的计算中,与逻辑回归十分类似,但中间会有多层的计算。下图是一个双层神经网络,有一个输入层,一个隐藏层和一个输出层。
前向传播:计算 \(z^{[1]}\),\(a^{[1]}\),再计算 \(z^{[2]}\),\(a^{[2]}\),最后得到 Loss Function。
反向传播:向后推算出 \(da^{[2]}\),然后推算出 \(dz^{[2]}\),接着推算出 \(da^{[1]}\),然后推算出 \(dz^{[1]}\)。
我们不需要对 \(x\) 求导,因为 \(x\) 是固定的,我们也不是想优化 \(x\)。向后推算出 \(da^{[2]}\),然后推算出 \(dz^{[2]}\) 的步骤可以合为一步:\(dz^{[2]}=a^{[2]}-y\)
\(dW^{[2]}=dz^{[2]}{a^{[1]}}^{T}\)
\(db^{[2]}=dz^{[2]}\)
\(dz^{[1]} = W^{[2]T}dz^{[2]}* g[1]^{'}(z^{[1]})\)
注意:为什么 \({a^{[1]}}^T\) 多了个转置?\(dW\) 中的 \(W\),本课程在逻辑回归中使用的 \(W^{[2]}_i\) 是一个列向量,而神经网络中使用的 \(W^{[2]}\) 是个行向量,由 \({W^{[2]}_i}^T\) 组成,故需要加个转置。
\(W^{[2]}\) 的维度是:\((n^{[2]},n^{[1]})\)
\(z^{[2]}\),\(dz^{[2]}\) 的维度都是:\((n^{[2]},1)\),如果是二分类,那维度就是 \((1,1)\)
\(z^{[1]}\),\(dz^{[1]}\) 的维度都是:\((n^{[1]},1)\)
\(W^{[2]T}dz^{[2]}\) 维度为:\((n^{[1]},n^{[2]})\) 和 \((n^{[2]},1)\) 矩阵乘得到 \((n^{[1]},1)\),其维度与 \(z^{[1]}\) 维度相同,
\(g[1]^{'}(z^{[1]})\) 的维度为 \((n^{[1]},1)\),这就变成了两个都是 \((n^{[1]},1)\) 向量逐元素乘积(element-wise product)。
实现后向传播有个技巧,就是要保证矩阵的维度相互匹配。最后得到 \(dW^{[1]}\) 和 \(db^{[1]}\):
\(dW^{[1]}=dz^{[1]}x^{T}\)
\(db^{[1]}=dz^{[1]}\)
可以看出 \(dW^{[1]}\) 和 \(dW^{[2]}\) 非常相似,其中 \(x\) 扮演了 \(a^{[0]}\) 的角色,\(x^{T}\) 等同于 \({a^{[0]}}^T\)。
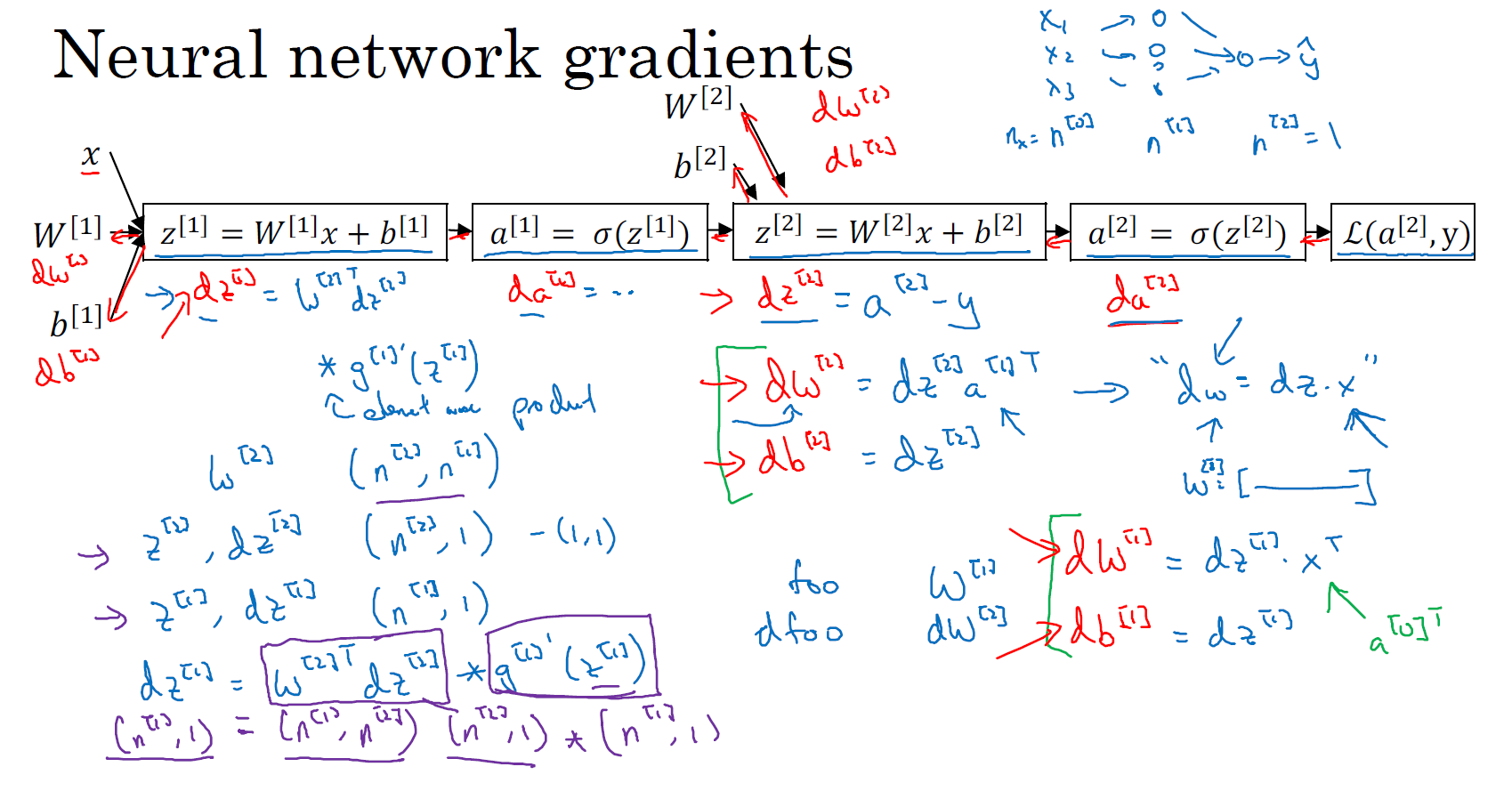
一个样本:\(z^{[1]}=W^{[1]}x+b^{[1]}, \ \ a^{[1]}=g^{[1]}(Z^{[1]})\)
\(m\) 个样本:\(Z^{[1]}=W^{[1]}x+b^{[1]}, \ \ A^{[1]}=g^{[1]}(Z^{[1]})\)
\(Z^{[1]} = \left[ \begin{array}{c} \vdots &\vdots & \vdots & \vdots \\ z^{[1](1)} & z^{[1](2)} & \vdots & z^{[1](m)} \\ \vdots &\vdots & \vdots & \vdots \end{array} \right]\)
注意:大写的 \(Z^{[1]}\) 表示 \(z^{[1](1)}, z^{[1](2)},...,z^{[1](m)}\) 的列向量堆叠成的矩阵,以下类同。

下图写了主要的推导过程:
\(dZ^{[2]}=A^{[2]}-Y ;dW^{[2]}={\frac{1}{m}}dZ^{[2]}{A^{[1]}}^{T}\)
\(\mathcal{L}={\frac{1}{m}}\sum_i^n{L(\hat{y},y)}\)
\(db^{[2]}={\frac{1}{m}}np.sum(dZ^{[2]},axis=1,keepdims=True)\)
\(\underbrace{dZ^{[1]}}{(n^{[1]},m)}=\underbrace{W^{[2]T}dZ^{[2]}}{(n^{[1]},m)}*\underbrace{g[1]^{'}(Z^{[1]})}_{(n^{[1]},m)}\)
\(dW^{[1]}={\frac{1}{m}}dZ^{[1]}x^{T}\)
\(db^{[1]}={\frac{1}{m}}np.sum(dZ^{[1]},axis=1,keepdims=True)\)

吴恩达老师认为反向传播的推导是机器学习领域最难的数学推导之一,矩阵的导数要用链式法则来求,如果这章内容掌握不了也没大的关系,只要有这种直觉就可以了。还有一点,就是初始化你的神经网络的权重,不要都是 0,而是随机初始化,下一章将详细介绍原因。
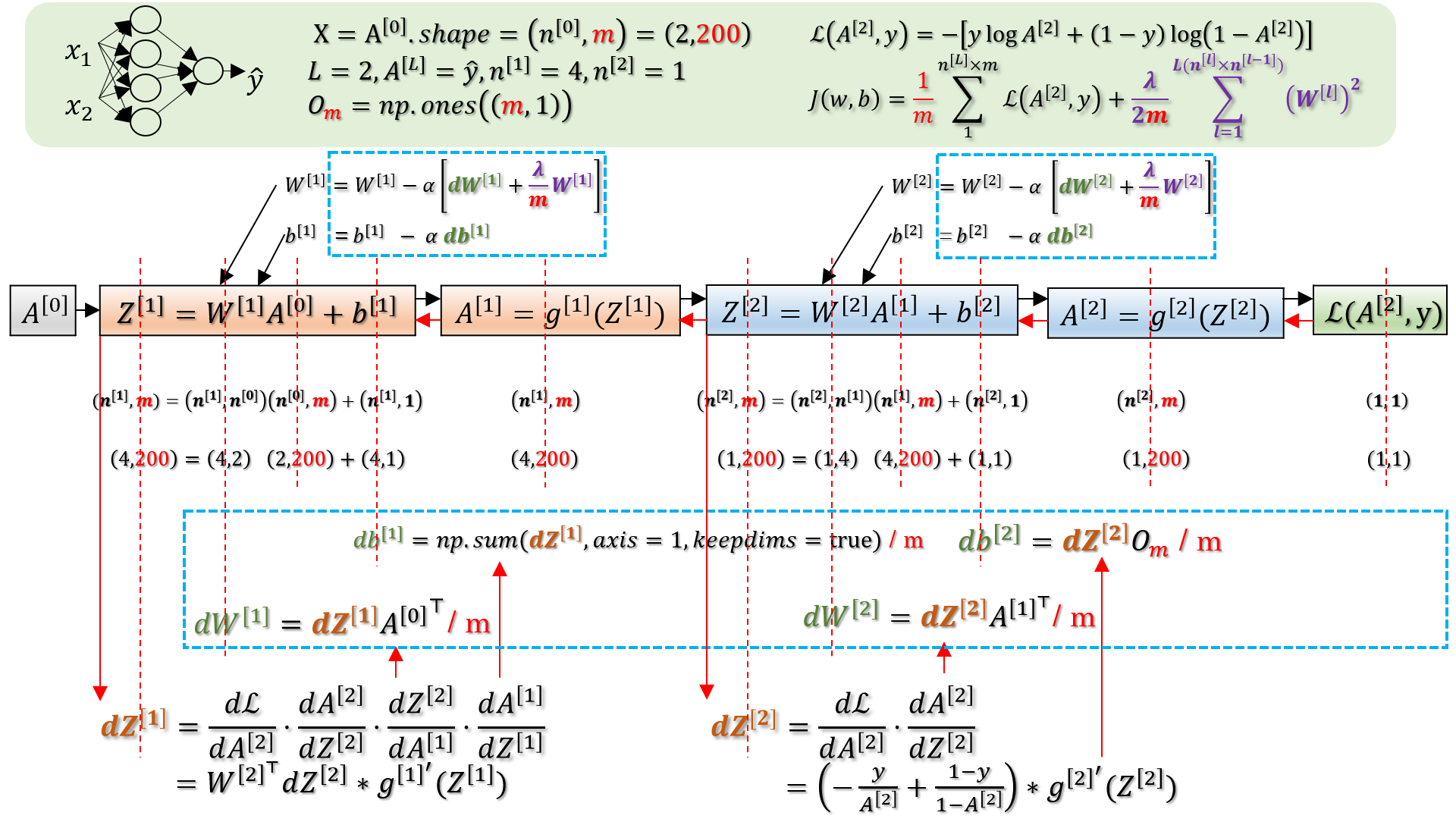
\(J\) 中第一个求和,是最后一层所有激活项所有元素整体求和,最后是一个常数。第二个求和是所有层中,所有 \(W\) 中的所有元素求和,最后也是一个常数,所以 \(J\) 最后也是一个常数,shape 为 (1, 1)。
紫色为正则化项,因为 \(J\) 中正则化项包含 \(W\),所以使用链式求导法则求到 \(W\) 时,即需要对 \(W\) 求全导数时,还需要把 \(J\) 中的正则化项(因为包含 \(W\))带过来。求导参考连接,其他时候该项导数为 0,可以忽略。
\(L\) 表示为神经网络的层数,在计算神经网络层数时,\(X\)(即:\(A^{[0]}\)),即:输入层,不被算入在内,或者也可以把它称作神经网络的第 0 层。所以图中演示的神经网络有 2 层,所以 \(L = 2\).
\(n^{[l]}\) 表示第 \(l\) 层的激活单元数,本例中 \(n^{[0]} = 2\)(输入层样本有两个特征), \(n^{[1]} = 4\)(隐藏层有 4 个激活单元), \(n^{[2]} = 1\)(最后一层,即输出层有 1 个激活单元)。因为 \(n^{[2]}\) 是最后一层,所以 \(n^{[L]}=n^{[2]}\)。
\(m\) 表示样本数量,图中示例有 200 个样本,所以 \(m = 200\),图中涉及 \(m\) 的地方均用红色字体高亮显示,方便比对查看。另外,在计算 \(dW\) 和 \(db\) 时,最后需要除以一个 \(m\),这是因为 \(J\) 中也带有一个 \(\frac{1}{m}\) 项,所以当链式求导求导终点的时候,需要把它带过来。此处求导终点的意思是 \(dW\) 和 \(db\) 里面没有复合函数存在了,所以是求导的重点。对比理解当求导求到 \(dA\) 时,它仍是一个复合函数,里面还包含其他函数,所以不是求导终点。它继续求导,可以求出下一层的 \(dZ\),再继续可以求出下一层的 \(dW\) 和 \(db\),到此又是一个求导的终点。
关于绿色的 \(dW\) 和 \(db\),也即梯度。\(dW\) 中存在矩阵乘法,内含求和操作,向量化的方式计算高效,代码简洁。但是 \(db\) 在计算时没有矩阵乘法,也就是没有求和操作,所以需要用其他方法来完成,图中在计算 \(db^{[1]}\) 和 \(db^{[2]}\) 时分别记录了两种方式来对 \(db\) 按行求和。np.sum(\(dZ^{[1]}\), axis=1, keepdims=True) 是调用 numpy 中的 sum 方法来求和,axis = 1 表示对每行进行求和,keepdims 表示求和后保留其维度特性。另外一种求和方式是初始化一个全部为 1 的矩阵,然后让 \(dZ\) 与其进行矩阵相乘,言外之意就是做求和的操作,异曲同工。
关于褐红色 \(dZ\),可参考多元复合函数的链式求导法则,其间均为点号相连,表示相乘。式中的第二个等号是其向量化的表示,可以看到其中既有矩阵乘,也有元素乘(*),因为是向量化表示,所以需要合理的组织和选择向量的前后位置,是否需要转置,使用矩阵乘还是元素乘等等,使之达到正确计算第一个等号列出的链式求导公式的目的。可以看到图中反向传播求导时都是直接求到 \(dZ\),跨过了 \(dA\),因为每一层的激活单元可能不同,所以 \(dA\) 的导数都是使用 \({g^{[l]}}^{'}(Z^{[l]})\) 来代替,以不变应万变。另外,\(dZ^{[l]}\) 可以推导出它上一层的 \(dZ^{[l-1]}\),而每一层的 \(dZ\) 又可以直接推到出该层的 \(dW\) 和 \(db\)。所以在编写程序时,直接计算出并缓存各个层的 \(dZ^{[l]}\) 是一个非常好的设计,既可以计算本层的 \(dW\) 和 \(db\),也可以计算上一层的 \(dZ\)。它就相当于一个计算梯度的中介和桥梁。
关于图中垂直的红色虚线,被它贯穿的向量维度均一致。如此方便比对神经网络在计算时各个步骤间向量呈现出的维度特性和变化规律。比如:
\(A^{[l]}.shape=(n^{[l]}, m)\)
\(Z^{[l]}.shape=dZ^{[l]}.shape=(n^{[l]}, m)\)
\(W^{[l]}.shape=dW^{[l]}.shape=(n^{[l]}, n^{[l-1]})\)
\(b^{[l]}.shape=db^{[l]}.shape=(n^{[l]}, 1)\)
\(J.shape=(1, 1)\)
如此可以更合理和高效的使用 Python 的 assert :
assert (\(A^{[l]}\).shape == (\(n^{[l]}\), m));
assert (\(Z^{[l]}\).shape == \(dZ^{[l]}\).shape == (\(n^{[l]}\), m));
assert (\(W^{[l]}\).shape == \(dW^{[l]}\).shape == (\(n^{[l]}\), \(n^{[l-1]}\)));
assert (\(b^{[l]}\).shape == \(db^{[l]}\).shape == (\(n^{[l]}\), 1));
assert (J.shape == (1, 1));
随机初始化(Random+Initialization)
当你训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为 0 当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为 0,那么梯度下降将不会起作用,让我们看看这是为什么。
有两个输入特征 \(n^{[0]}=2\),2 个隐藏层单元 \(n^{[1]}\) 就等于 2。 因此与一个隐藏层相关的矩阵,或者说 \(W^{[1]}\) 是 \(2\times2\) 的矩阵,假设把它初始化为 0 的 \(2\times2\) 矩阵,\(b^{[1]}\) 也等于 \({[0, 0]}^T\),把偏置项 \(b\) 初始化为 0 是合理的,但是把 \(w\) 初始化为 0 就有问题了。那这个问题如果按照这样初始化的话,你总是会发现 \(a_{1}^{[1]}\) 和 \(a_{2}^{[1]}\) 相等。因为两个隐含单元计算同样的函数,这样输出的权值也会一模一样,由此 \(W^{[2]}\) 等于 \([0 \ 0]\)。当你做反向传播计算时,这会导致 \({dz}_1^{[1]}\) 和 \({dz}_2^{[1]}\) 也会一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数,令人困惑。对于 \(dW\) 来说,它会是一个每一行有同样的值的矩阵,因此我们做权重更新把权重 \(W^{[1]}\implies{W^{[1]}-adW}\),那么每次迭代后的 \(W^{[1]}\) 将会是第一行等于第二行。
由此可以推导,如果你把权重都初始化为 0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过 1 个隐含单元也没什么意义,因为他们计算同样的东西。
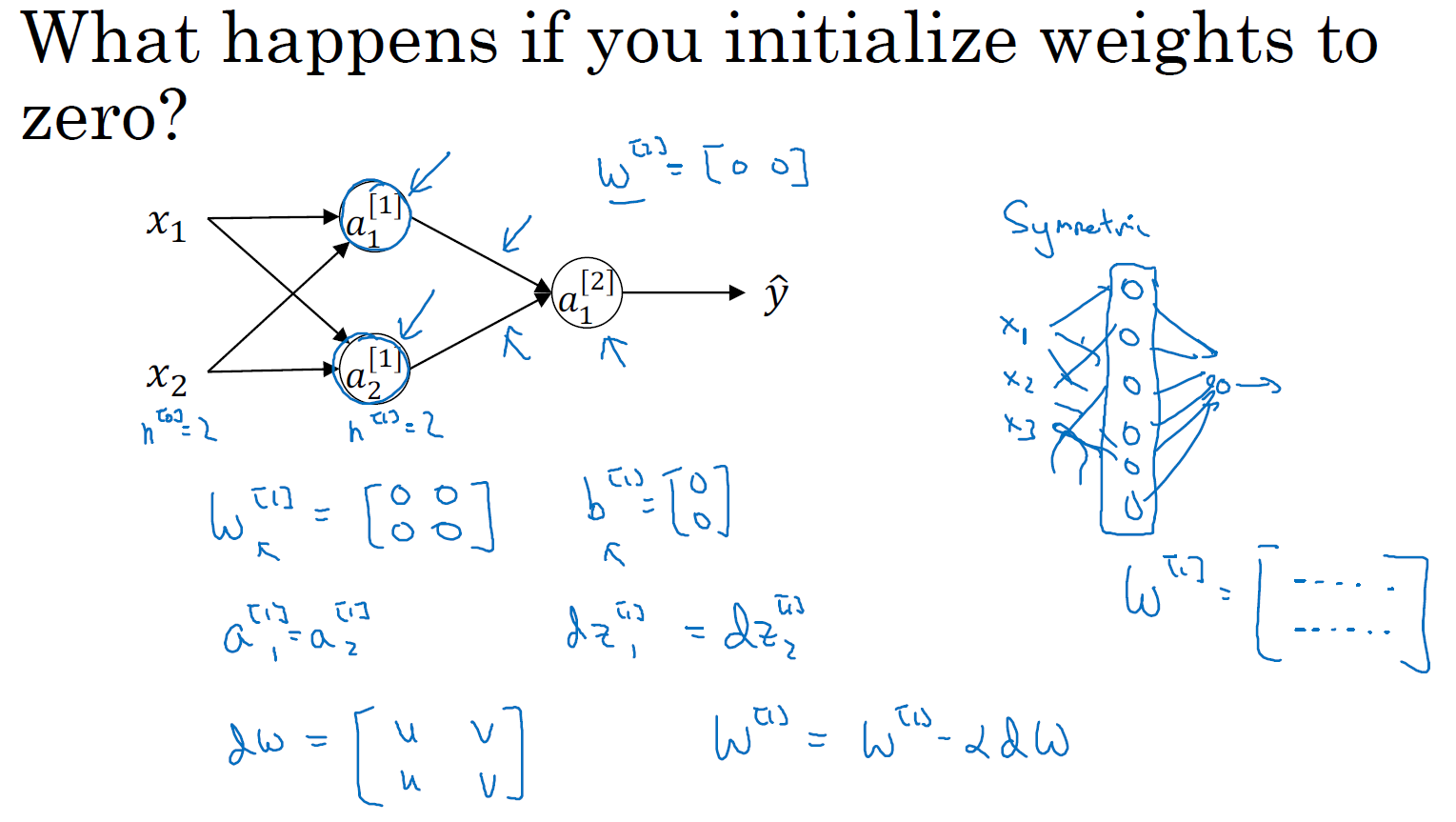
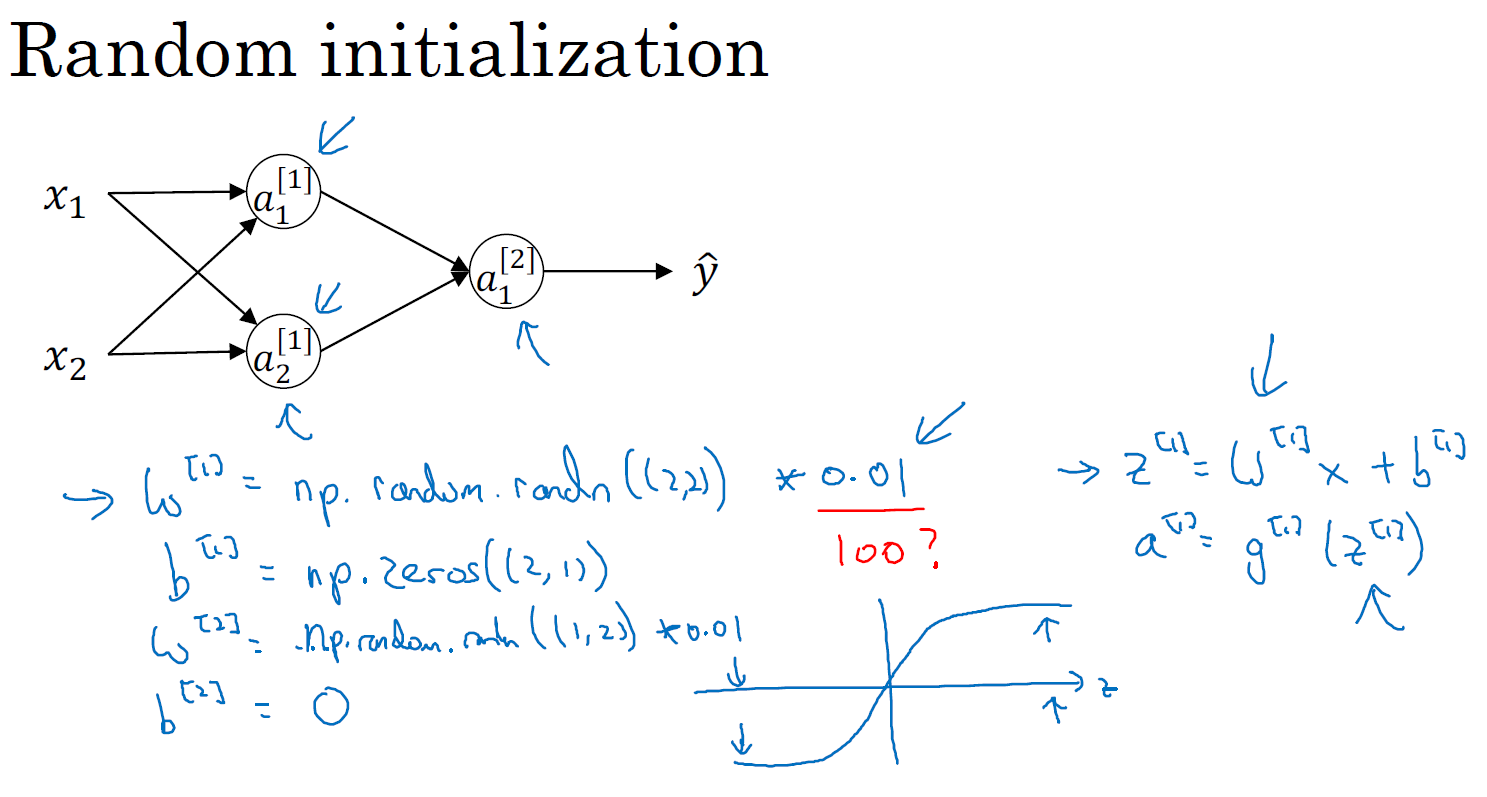
如果你要初始化成 0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为你想要两个不同的隐含单元计算不同的函数,这个问题的解决方法就是随机初始化参数。你应该这么做:把 \(W^{[1]}\) 设为 np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如 0.01,这样把它初始化为很小的随机数。然后 \(b\) 没有这个对称的问题(叫做 symmetry breaking problem),所以可以把 \(b\) 初始化为 0,因为只要随机初始化 \(W\) 你就有不同的隐含单元计算不同的东西,因此不会有 symmetry breaking 问题了。相似的,对于 \(W^{[2]}\) 你可以随机初始化,\(b^{[2]}\) 可以初始化为 0。
\(W^{[1]}\) = np.random.randn(2,2) \(*\) 0.01,\(b^{[1]}\) = np.zeros((2,1))
\(W^{[2]}\) = np.random.randn(2,2) \(*\) 0.01,\(b^{[2]}\) = 0
你也许会疑惑,这个常数从哪里来,为什么是 0.01,而不是 100 或者 1000。我们通常倾向于初始化为很小的随机数。因为如果你用 tanh 或者 sigmoid 激活函数,或者说只在输出层有一个 Sigmoid,如果数值波动太大,当你计算激活值时 \(z^{[1]}=W^{[1]}x + b^{[1]}\),\(a^{[1]}=\sigma(z^{[1]})=g^{[1]}(z^{[1]})\), 如果 \(W\) 很大,\(z\) 就会很大或者很小,因此这种情况下你很可能停在 tanh / sigmoid 函数的平坦的地方,这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
总结一下:如果 \(w\) 很大,那么你很可能最终停在(甚至在训练刚刚开始的时候)\(z\) 很大的值,这会造成 tanh / Sigmoid 激活函数饱和在龟速的学习上,如果你没有 sigmoid / tanh 激活函数在你整个的神经网络里,就不成问题。但如果你做二分类并且你的输出单元是 Sigmoid 函数,那么你不会想让初始参数太大,因此这就是为什么乘上 0.01 或者其他一些小数是合理的尝试。对于 \(w^{[2]}\) 也是一样,就是 np.random.randn((1,2)),也会乘以 0.01。
事实上有时有比 0.01 更好的常数,当你训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为 0.01 可能也可以。但当你训练一个非常非常深的神经网络,你可能要试试 0.01 以外的常数。下一周的课程我们会讨论怎么并且何时去选择一个不同于 0.01 的常数,但是无论如何它通常都会是个相对小的数。
好了,这就是这周的课程。你现在已经知道如何建立一个 1 层的神经网络了,初始化参数,用前向传播预测,还有计算导数,结合反向传播用在梯度下降中。
1. 在吴恩达老师机器学习课程中,初始化神经网络参数的方法是让 \(W\) 为一个在 \([-\epsilon, \epsilon]\) 之间的随机数。
epsilon_init = 0.12
np.random.rand(\(n^{[l]}\), \(n^{[l-1]}\)) \(*\) 2 \(*\) epsilon_init - epsilon_init
2. 在吴恩达老师本门课程(深度学习)中,使用如下方法:
\(W^{[1]}\) = np.random.randn(\(n^{[l]}\), \(n^{[l-1]}\)) \(*\) 0.01(生成高斯分布)
\(b^{[1]}\) = np.zeros((\(n^{[l]}\), 1))
[C1W3] Neural Networks and Deep Learning - Shallow neural networks的更多相关文章
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week3, Neural Networks Basics
NN representation 这一课主要是讲3层神经网络 下面是常见的 activation 函数.sigmoid, tanh, ReLU, leaky ReLU. Sigmoid 只用在输出0 ...
- Coursera, Deep Learning 1, Neural Networks and Deep Learning - week2, Neural Networks Basics
Logistic regression Cost function for logistic regression Gradient Descent 接下来主要讲 Vectorization Logi ...
- Neural Networks and Deep Learning
Neural Networks and Deep Learning This is the first course of the deep learning specialization at Co ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- 《Neural Networks and Deep Learning》课程笔记
Lesson 1 Neural Network and Deep Learning 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第一门课程的课程笔记. 参考了其他人的笔记继续归纳 ...
- 第四节,Neural Networks and Deep Learning 一书小节(上)
最近花了半个多月把Mchiael Nielsen所写的Neural Networks and Deep Learning这本书看了一遍,受益匪浅. 该书英文原版地址地址:http://neuralne ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week2 Neural Networks Basics课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week2 Neural Networks Basics 2.1 ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week1 Introduction to deep learning课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week1 Introduction to deep learn ...
- Neural Networks and Deep Learning学习笔记ch1 - 神经网络
近期開始看一些深度学习的资料.想学习一下深度学习的基础知识.找到了一个比較好的tutorial,Neural Networks and Deep Learning,认真看完了之后觉得收获还是非常多的. ...
随机推荐
- June 09th, 2019. Week 24th, Sunday
The beauty you see in me is a reflection of you. 你在我身上看到的美,正是你的倒影. From Jalaluddin Rumi. What we see ...
- AtCoder Beginner Contest 140
传送门 A - Password 输出\(n*n*n\)即可. Code #include <bits/stdc++.h> using namespace std; typedef lon ...
- 【AtCoder】AtCoder Grand Contest 040 解题报告
点此进入比赛 \(A\):><(点此看题面) 大致题意: 给你一个长度为\(n-1\).由\(<\)和\(>\)组成的的字符串,第\(i\)位的字符表示第\(i\)个数和第\( ...
- HTML5新属性在Google浏览器中不能显示的问题
这两天在学习HTML5新属性时遇到了如下问题,很是不解: 例如在学习使用canvas时,需要绘制一个红色的原点,代码如下: <!DOCTYPE HTML> <html> < ...
- php date获取前一天的时间
结果: 结论: 第二种方式只使用了一个函数,所以更快一些,速度大约是第一种的两倍
- python做中学(六)os.getcwd() 的用法
概述 os.getcwd() 方法用于返回当前工作目录. 语法 getcwd()方法语法格式如下: os.getcwd() 参数 无 返回值 返回当前进程的工作目录. 实例 以下实例演示了 getcw ...
- Wireshark 抓取USB的数据包
需要使用root权限来运行Wireshark,并利用Wireshark来嗅探USB通信数据.当然了,我们并不建议大家利用root权限来进行操作.我们可以使用Linux提供的usbmon来为我们获取和导 ...
- C++入门到理解阶段二基础篇(1)——简介与环境安装
1.C++ 简介 C++ 是一种静态类型的.编译式的.通用的.大小写敏感的.不规则的编程语言,支持过程化编程.面向对象编程和泛型编程. C++ 被认为是一种中级语言,它综合了高级语言和低级语言的特点. ...
- linux检测远程端口是否打开
常用telnet ip port 方式(如telnet 172.17.193.18 5902)测试远程主机端口是否打开,或者用于测试当前环境与远程主机的端口之间的防火墙开通与否. telnet [ro ...
- 记一次收集APP native崩溃信息
最近在学习 极客时间Android开发高手课 老师推荐了Breakpad开源库来采集native 的crash1.为什么要使用Google Breakpad? 我们在开发过程中,Android JNI ...