Ambari 大数据集群管理
最近做了一个大数据项目,研究了下集群的搭建,现在将集群搭建整理的资料与大家分享一下!如有疑问可在评论区回复。
1前置配置
Centos7系统,每台系统都有java运行环境
全程使用root用户,避免安装过程中出现权限不足等情况
1.1 关闭防火墙
所有节点都要设置
Centos 7 命令
查看防火墙状态
firewall-cmd --state
systemctl disable firewalld
systemctl stop firewalld
Centos 6 命令
chkconfig iptables off
/etc/init.d/iptables stop
1.2 修改主机名
(首先所有节点如果没有vim工具,先进行安装:yum install vim -y)
#Master
vim
/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
#Slave1
vim
/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
#Slave2
vim
/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
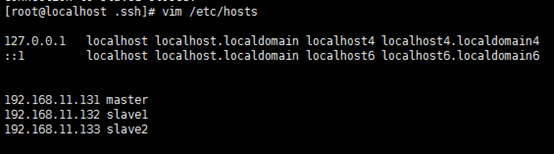
1.3 修改HOST
#Master、Slave1、Slave2
vim /etc/hosts
192.168.11.35
master
192.168.11.32
slave1
192.168.11.33 slave2
192.168.11.34
slave3
1.4 关闭Selinux所有机器
master、slave1、slave2
vim
/etc/sysconfig/selinux
selinux=disabled
修改配置文件后需要重启机器
reboot
1.5 开启NTP服务
所有集群上节点都需要操作
Centos 7 命令
yum -y install ntp
systemctl
is-enabled ntpd
systemctl enable
ntpd
systemctl start
ntpd
Centos 6 命令
yum install ntpd
chkconfig --list
ntpd
chkconfig ntpd
service ntpd start
1.6 检查最大打开文件描述符
推荐的最大打开文件描述符数为10000或更多。要检查为打开的文件描述符的最大数量设置的当前值,请在每个主机上执行以下shell命令:
ulimit -Sn
ulimit -Hn
如果输出不大于10000,请运行以下命令将其设置为合适的默认值:
ulimit -n 10000
1.7 设置服务器允许其他服务ssh免密链接
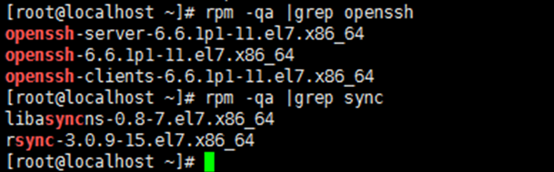
1.7.1 确认系统已经安装了SSH。
rpm -qa | grep
openssh
rpm -qa | grep
rsync
-->出现如下图的信息表示已安装
假设没有安装ssh和rsync,可以通过下面命令进行安装。
安装SSH协议
yum install ssh
rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件
yum install rsync
-->启动服务
service sshd
restart
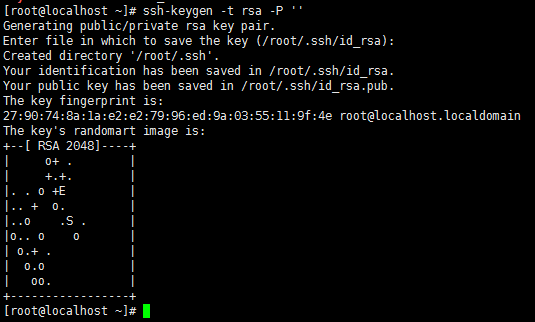
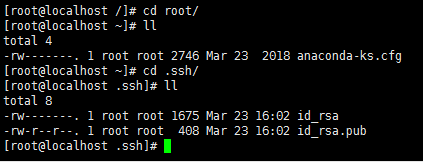
1.7.2 生成密钥对
每台服务器分别执行
ssh-keygen -t rsa
-P ''
直接回车生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/root/.ssh"目录下。
把id_rsa.pub追加到授权的key里面去。
cat
~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

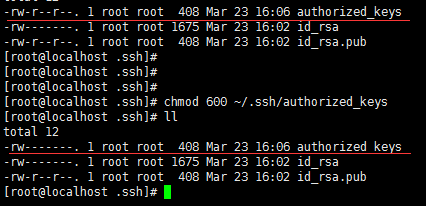
修改授权key的权限
chmod 600
~/.ssh/authorized_keys
使用root用户修改配置文件
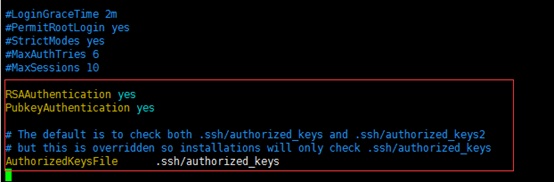
vim /etc/ssh/sshd_config
取消该三个属性的注释
测试连接
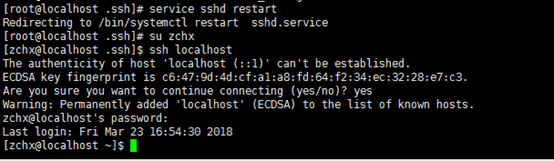
重启ssh服务
service sshd
restart
切换成普通用户
su zchx
连接普通用户测试
ssh localhost
1.7.3 相互追加Key
#Master
ssh slave1 cat
/root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
ssh slave2 cat
/root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
ssh slave3 cat
/root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
#Slave1
ssh master cat
/root/.ssh/authorized_keys > /root/.ssh/authorized_keys
#Slave2
ssh master cat
/root/.ssh/authorized_keys > /root/.ssh/authorized_keys
#Slave3
ssh master cat
/root/.ssh/authorized_keys > /root/.ssh/authorized_keys
1.8 JAVA开发环境JDK安装
1.8.1 安装JDK
安装环境:CentOS7
(后台)
1.检查系统中的jdk版本
显示:

2.检测jdk安装包
(如果显示有预装JDK需要进行卸载,如果没有显示就进行下一步)
rpm -qa|grep java

显示:
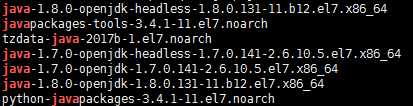
3.卸载openjdk
4.yum
remove *openjdk*

检查:
rpm -qa|grep java

显示:

5.所有节点在usr目录下创建一个java文件夹
cd usr
mkdir java
6.所有节点将下好的JDK安装包放进java文件夹下并解压
通过ftp工具连接虚拟机将安装包(tar -zxvf jdk-8u11-linux-x64.tar.gz)上传到各个节点的/urs/java路径下

7.切换目录:cd /usr/java
8.解压:tar -zxvf jdk-8u11-linux-x64.tar.gz
1.8.2 配置JDK环境变量
vi /etc/profile

·进入编辑模式:点击i
新增如下配置:
export
JAVA_HOME=/usr/java/jdk1.8.0_11
export
JRE_HOME=${JAVA_HOME}/jre
export
CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export
PATH=${JAVA_HOME}/bin:$PATH
退出编辑模式 esc
保存退出:wq
执行profile文件
source /etc/profile

9检查新安装的jdk

2 安装pdsh RPM
master节点
使用root用户安装pdsh RPM的EPEL存储库
在master服务器执行
rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
接下来执行安装程序命令
yum -y install
pdsh-rcmd-ssh
3 集群节点配置
3.1 安装Ambari库
master节点对slave1的配置
pdsh -w slave1
"wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.1.0/ambari.repo
-O /etc/yum.repos.d/ambari.repo"

pdsh -w slave1
"yum -y install ambari-agent"
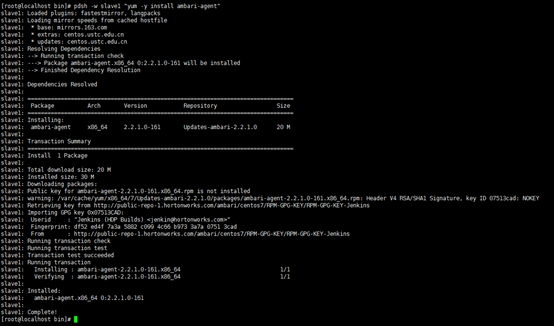
在节点上设置ambari服务器主机名
pdsh -w slave1
"sed -i 's/hostname=localhost/hostname=master/g' /etc/ambari-agent/conf/ambari-agent.ini"
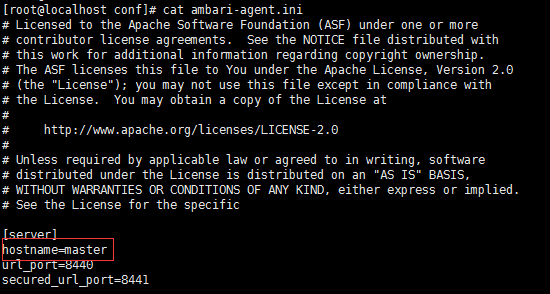
pdsh -w slave1
"service ambari-agent start" | sort
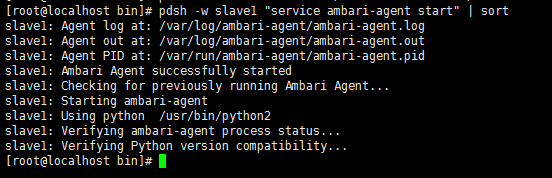
master节点对slave2的配置
pdsh -w slave2
"wget
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.1.0/ambari.repo
-O /etc/yum.repos.d/ambari.repo"
pdsh -w slave2
"yum -y install ambari-agent"
pdsh -w slave2
"sed -i 's/hostname=localhost/hostname=master/g'
/etc/ambari-agent/conf/ambari-agent.ini"
pdsh -w slave2
"service ambari-agent start" | sort
3.2 安装Ambari服务器
master节点上执行命令:
yum -y install
ambari-server
yum -y install
ambari-agent
service
ambari-agent start
3.3 配置Ambari
ambari-server
setup
下面为图文描述
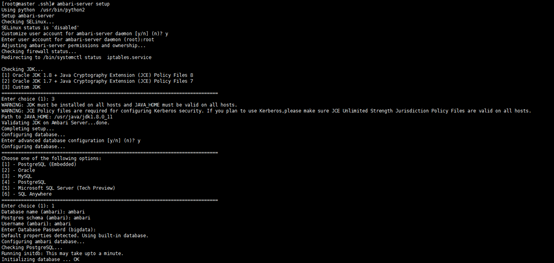
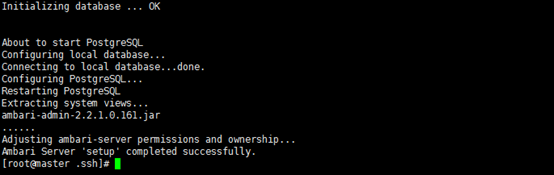
Using python /usr/bin/python2
Setup
ambari-server
Checking
SELinux...
SELinux status is
'disabled'
Customize user
account for ambari-server daemon [y/n] (n)? y
Enter user account
for ambari-server daemon (root):root
Adjusting
ambari-server permissions and ownership...
Checking firewall
status...
Redirecting to
/bin/systemctl status iptables.service
Checking JDK...
[1] Oracle JDK 1.8
+ Java Cryptography Extension (JCE) Policy Files 8
[2] Oracle JDK 1.7
+ Java Cryptography Extension (JCE) Policy Files 7
[3] Custom JDK
==============================================================================
Enter choice (1):
WARNING: JDK must
be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE
Policy files are required for configuring Kerberos security. If you plan to use
Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are
valid on all hosts.
Path to JAVA_HOME:
/usr/java/jdk1.8.0_11
Validating JDK on
Ambari Server...done.
Completing
setup...
Configuring
database...
Enter advanced
database configuration [y/n] (n)? y
Configuring
database...
==============================================================================
Choose one of the
following options:
[1] - PostgreSQL
(Embedded)
[2] - Oracle
[3] - MySQL
[4] - PostgreSQL
[5] - Microsoft
SQL Server (Tech Preview)
[6] - SQL Anywhere
==============================================================================
Enter choice (1):
Database name
(ambari): ambari
Postgres schema
(ambari): ambari
Username (ambari):
ambari
Enter Database
Password (bigdata): bigdata
Default properties
detected. Using built-in database.
Configuring ambari
database...
Checking
PostgreSQL...
Running initdb:
This may take upto a minute.
Initializing
database ... OK
About to start
PostgreSQL
Configuring local
database...
Connecting to
local database...done.
Configuring PostgreSQL...
Restarting
PostgreSQL
Extracting system
views...
ambari-admin-2.2.1.0.161.jar
......
Adjusting
ambari-server permissions and ownership...
Ambari Server
'setup' completed successfully.
3.4 启动Amabri
执行启动命令,启动Ambari服务
ambari-server
start
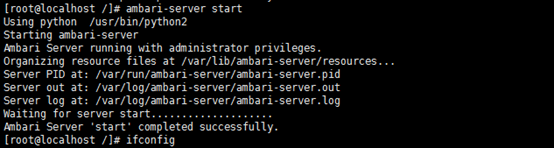
成功启动后在浏览器输入Ambari地址:
admin/admin
登录成功后出现下面的界面,至此Ambari的安装成功
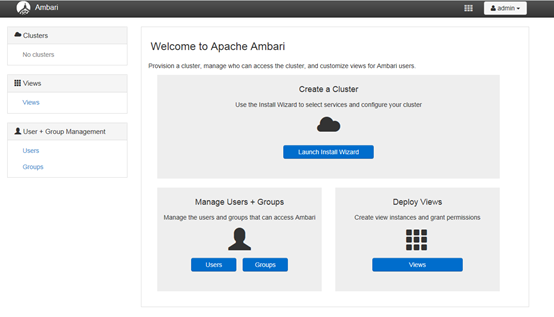
4 安装HDP 2.4.0配置集群
点击上面登录成功页面的Launch
Install Wizard 按钮进行集群配置
4.1 设置集群名称
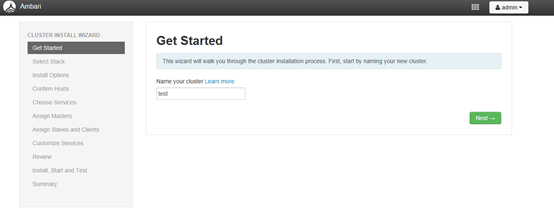
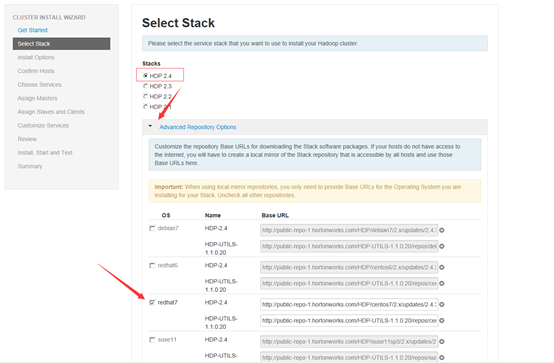
4.2 设置HDP安装源
选择HDP2.4 ,并且设置Advanced Repository Options 的信息,本次使用本地源,所以修改对用系统的安装源为本地源地址。
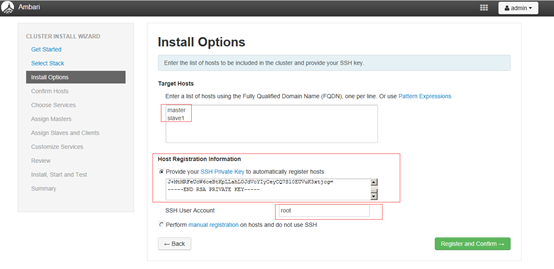
4.3 设置集群机器 (私钥文件地址/root/.ssh/id_rsa)
more
/root/.ssh/id_rsa
私钥文件从master节点中选取,复制文件内容粘贴到输入框中
提示主机名无效,直接点击确定
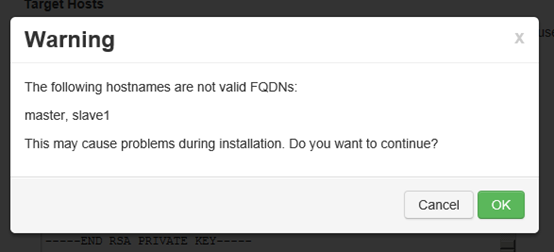
4.4 Host 确认
C:\Windows\System32\drivers\etc\hosts
修改本地host文件地址
添加如下配置
192.168.11.35
master
192.168.11.32
slave1
192.168.11.33
slave2
192.168.11.34
slave3
确认前面配置集群中hosts列表中的机器是否都可用,也可以移除相关机器,集群中机器Success后进行下一步操作。
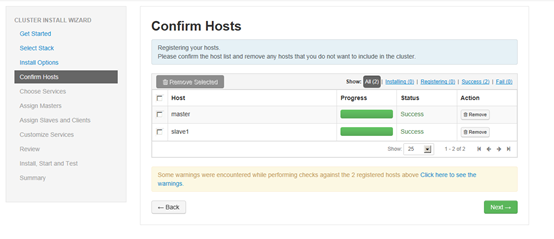
如果有异常提示的话,需要根据异常类型和相关提示解决方案处理,处理完成后再次进行验证,此处为告警,不影响后续服务所以直接下一步
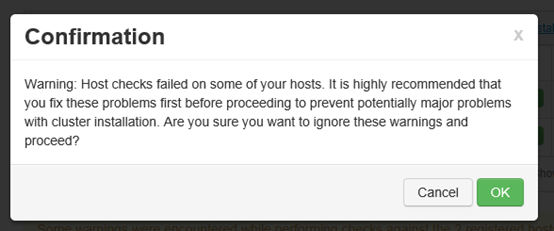
4.5 选择要安装的服务
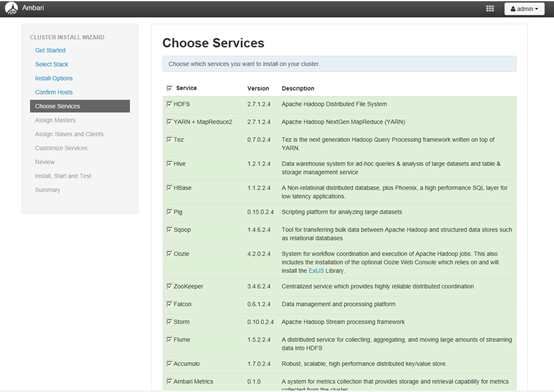
服务较多,目前先安装zoopekker和Ambari Metrics,后续在根据需要安装其他服务
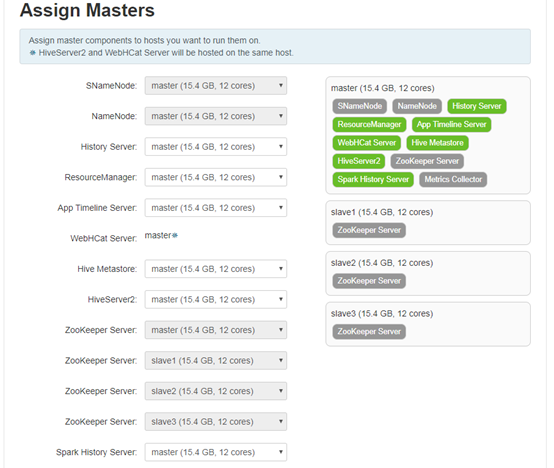
4.6 各个服务Master配置
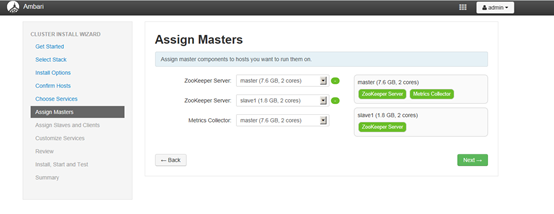
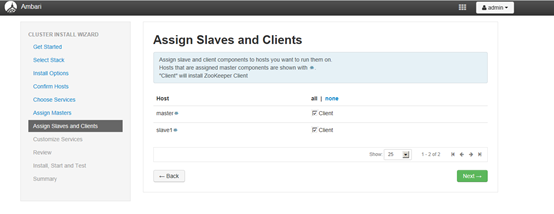
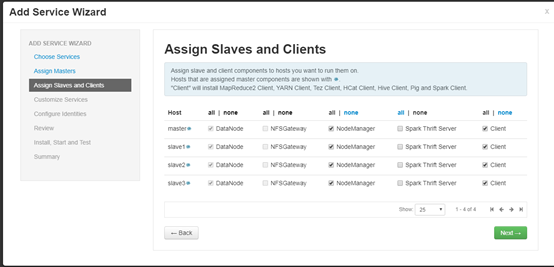
4.7 服务的Slaves和Clients节配置
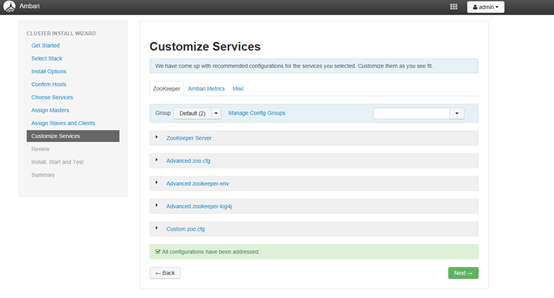
4.8 服务的客制化配置,这些参数待集群建好后都是可以再调整的。(有些组件需要让你设定密码,例如hive)
4.9 修改项
4.9.1 HDFS hdfs-site
修改hdfs-site.xml增加如下选项
4.9.1.1
无法写入
环境中有4个datanode,备份数量设置的是3。在写操作时,它会在pipeline中写3个机器。默认replace-datanode-on-failure.policy是DEFAULT,如果系统中的datanode大于等于3,它会找另外一个datanode来拷贝。目前机器只有3台,因此只要一台datanode出问题,就一直无法写入成功。
对于dfs.client.block.write.replace-datanode-on-failure.enable,客户端在写失败的时候,是否使用更换策略,默认是true没有问题。
对于,dfs.client.block.write.replace-datanode-on-failure.policy,default在3个或以上备份的时候,是会尝试更换结点尝试写入datanode。而在两个备份的时候,不更换datanode,直接开始写。对于3个datanode的集群,只要一个节点没响应写入就会出问题,所以可以关掉。
解决办法:修改hdfs-site.xml文件,添加或者修改如下两项:
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
4.9.1.2
root用户没有hdfs目录的操作权限
通过ambari后台HDFS-Configs-Advanced-Advanced hdfs-site 配置项
dfs.permissions.enabled属性设置为 false
问题原因为hdfs服务在不修改权限认证的情况下,只接受hdfs用户操作,改选项在系统安装完毕后需要关闭,或者在安装前自定义设置时直接关闭
4.9.1.3
数据备份修改
数据默认备份三份,放在不同节点,项目对数据的备份要求不高,所以需要修改数据备份份数为一份.
修改方式:在
ambari界面中的HDFS选项的Config界面中的Advanced配置中修改,General下的Block replication值为1(设置备份数据的份数为1)
并且修改Adcance
hdfs-site配置下的dfs.replication.max值为1(设置最大的本分数据的分数)
注:如果该数据块
的副本经常丢失,导致在环境中太多的节点处复制了超过dfs.replication.max的副本数,那么就不再复制了。
4.9.2 HDFS core-site
添加hadoop.proxyuser.root.groups属性设置为 *
添加hadoop.proxyuser.root.hosts属性设置为 *
“*”表示可通过超级代理“xxx”操作hadoop的用户、用户组和主机
主要原因是hadoop引入了一个安全伪装机制,使得hadoop 不允许上层系统直接将实际用户传递到hadoop层,而是将实际用户传递给一个超级代理,由此代理在hadoop上执行操作,避免任意客户端随意操作hadoop
该选项在系统安装完毕后扩展,或者在安装前自定义设置时直接添加

此处有提示,可以直接运行,也可以按照提示的参数修改为推荐值
4.9.3 spark运行内存
修改spark的配置项,
Advanced spark-thrift-sparkconf
将spark.executor.memory配置项的值由1g修改为4g
此处修改根据服务器内存大小动态配置,内存越大spark内存可缓存数据量越大,处理速度越快
Hbase配置
自定义 hbase-site 添加
# zookeeper服务自动拉起
hbase.reginserver.restart.on.zk.expire=true
Server配置
HBase Master Maximum Memory 设置成4G
# RegionServer处理个数
Number of Handlers per RegionServer设置成100
Timeouts配置
Zookeeper Session Timeout设置成2分钟超时
HBase RPC Timeout 设置成2分钟超时
4.10 显示配置信息
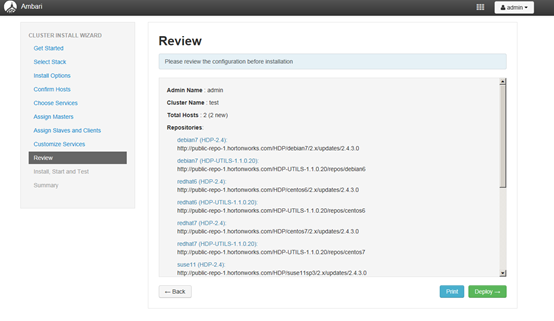
4.11 开始安装
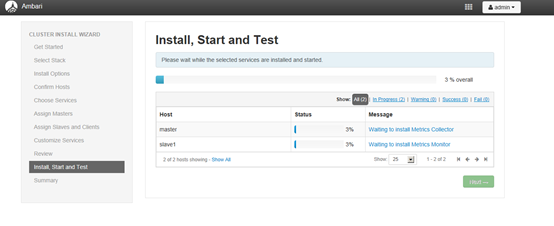
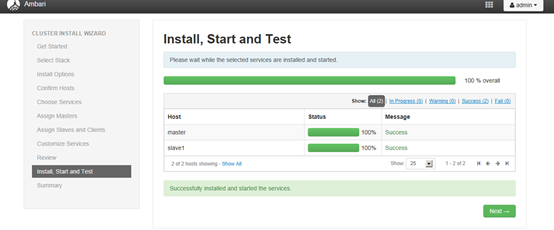
安装完毕
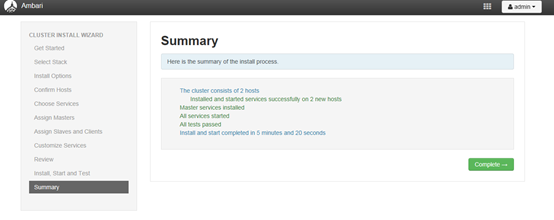
4.12 安装其他组件
此时选择安装spark和spark依赖的一些服务,服务可以分散化,避免master节点消耗过多
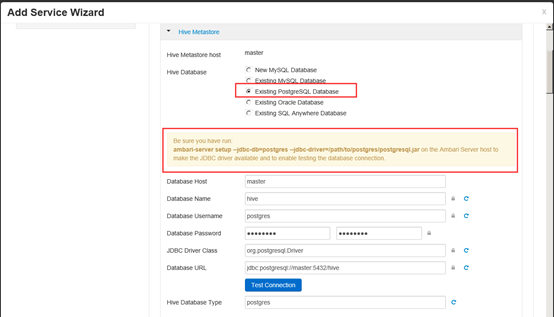
安装hive需要hive数据库
此时需要修改postgres数据库的外网访问权限
vim
/var/lib/pgsql/data/pg_hba.conf
在文件末尾追加一行
host all all
0.0.0.0/0 md5
表示允许地址在0.0.0.0-255.255.255.255范围内的客户端,通过MD5加密的密码,使用任意用户连接任意数据库。
修改完成之后,重启一下数据库
查看可执行命令
service postgresql
–help
执行重启命令
service postgresql
restart

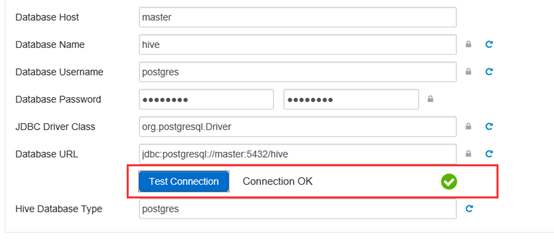
将数据库的jdbc驱动文件上传到master节点下
创建目录,将驱动jar包上传到该目录下
/usr/drivers/postgres
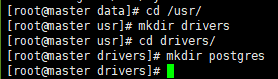
在master服务器调用命令指定服务使用的驱动jar
ambari-server
setup --jdbc-db=postgres --jdbc-driver=/usr/drivers/postgres/postgresql-9.3-1102-jdbc4.jar

建立数据库表
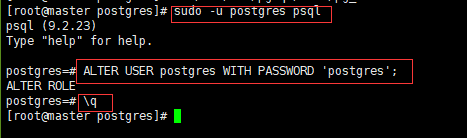
首先修改一下master节点数据库的登录名的密码
sudo -u postgres
psql
ALTER USER
postgres WITH PASSWORD 'postgres';
\q
然後使用数据库连接工具进行数据库连接:
IP:master节点的ip
端口号:5432(默认)
维护数据库:postgres
用户名:postgres
密码postgers
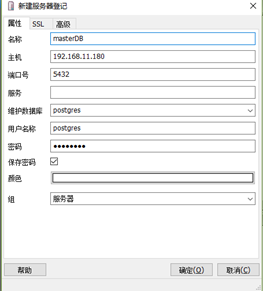
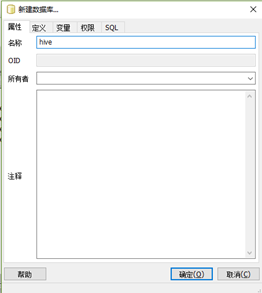
连接数据库后新建一个hive数据表
链接测试通过
准备安装
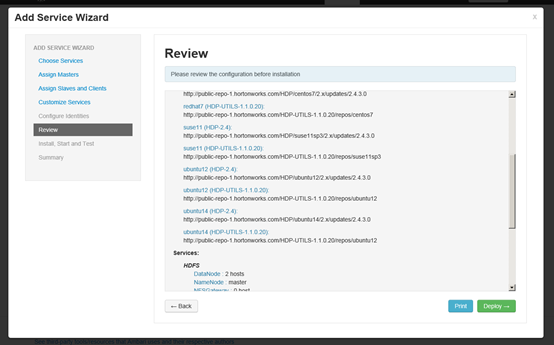
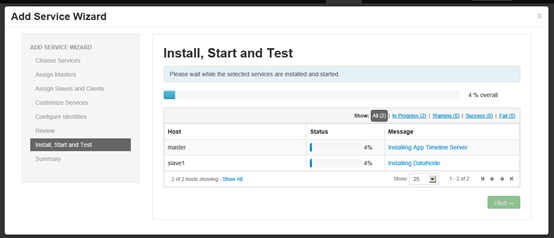
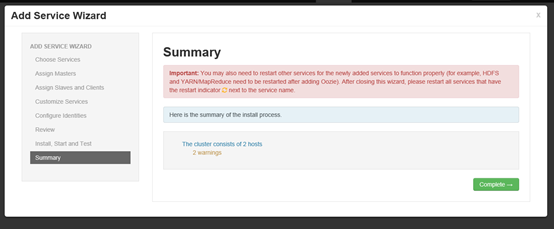
安装完毕之后需要重新启动其他服务
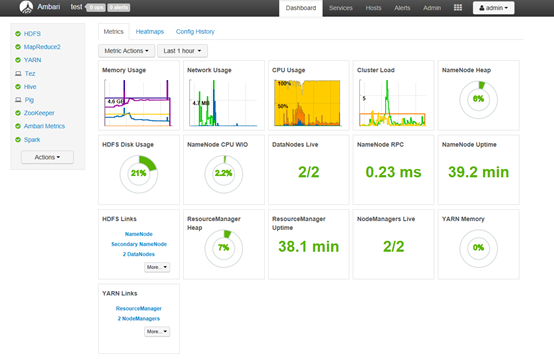
5 后置工作
5.1 python环境配置修改
#集群每个节点都执行该语句
sed -i 's/verify=platform_default/verify=disable/' /etc/python/cert-verification.cfg
禁用Python的验证,避免系统重启后集群无法验证导致各个节点服务无法通信
修改完成后可以尝试强行断开服务器电源导致服务器关机等场景测试服务器启动后是否可以正常连接集群
6 服务操作
6.1
集群监听服务
监听服务相关命令
[root@slave1 ~]# ambari-agent help
Usage: /usr/sbin/ambari-agent {start|stop|restart|status|reset
<server_hostname>}
6.2
集群管理服务
集群管理服务相关命令
[root@master ~]# ambari-server help
Using python /usr/bin/python2
Usage: /usr/sbin/ambari-server
{start|stop|restart|setup|setup-jce|upgrade|status|upgradestack|setup-ldap|sync-ldap|set-current|setup-security|refresh-stack-hash|backup|restore|update-host-names}
[options]
Use usr/sbin/ambari-server <action> --help to get details on
options available.
Or, simply invoke ambari-server.py --help to print the options.
6.3 最新版安装方式
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.2.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
修改repo文件里的资源路径到本地路径
将安装包放到http服务中
http://master/ambari/centos7/2.6.2.0-155/
选择本地化redhat7的资源
http://master/HDP/centos7/2.6.5.0-292/
http://master/HDP-GPL/centos7/2.6.5.0-292/
http://master/HDP-UTILS/
HDP-2.6.5.0资源
HDP:http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.5.0/HDP-2.6.5.0-centos7-rpm.tar.gz
Ambari 大数据集群管理的更多相关文章
- Ubuntu14.04下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentO ...
- 关于在真实物理机器上用cloudermanger或ambari搭建大数据集群注意事项总结、经验和感悟心得(图文详解)
写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentOS6.5版本)和clo ...
- centos7 ambari2.6.1.5+hdp2.6.4.0 大数据集群安装部署
前言 本文是讲如何在centos7(64位) 安装ambari+hdp,如果在装有原生hadoop等集群的机器上安装,需要先将集群服务停掉,然后将不需要的环境变量注释掉即可,如果不注释掉,后面虽然可以 ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- Ubuntu14.04下Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)(在线或离线)
第一步: Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一) 第二步: Cloudera Manager安装之时间服务器和时间客户端(Ub ...
- 大数据集群Linux CentOS 7.6 系统调优篇
大数据集群Linux CentOS 7.6 系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.设置主机hosts文件 1>.修改主机名 [root@node100 ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 全网最详细的大数据集群环境下多个不同版本的Cloudera Hue之间的界面对比(图文详解)
不多说,直接上干货! 为什么要写这么一篇博文呢? 是因为啊,对于Hue不同版本之间,其实,差异还是相对来说有点大的,具体,大家在使用的时候亲身体会就知道了,比如一些提示和界面. 安装Hue后的一些功能 ...
- 全网最详细的大数据集群环境下如何正确安装并配置多个不同版本的Cloudera Hue(图文详解)
不多说,直接上干货! 为什么要写这么一篇博文呢? 是因为啊,对于Hue不同版本之间,其实,差异还是相对来说有点大的,具体,大家在使用的时候亲身体会就知道了,比如一些提示和界面. 全网最详细的大数据集群 ...
随机推荐
- Win10家庭版激活方法
由于电脑换过主板,系统过了段时间显示未激活的状态,当时没注意随着主板口袋里的密匙,当作垃圾一起扔了,在网上试了几种方式,以下这个方法让我成功激活了系统 对开始菜单点击右键,选择Windows Powe ...
- Octave计算数据
设A=[1 2;3 4;5 6] B=[11 12;13 14;15 16] A.*B = :对A以及B中的对应的元素进行相乘 11 24 39 56 75 96 A.^2 :对A中的每一个元 ...
- mysql语法总结及例子
1. DDL相关 a. -- 查询所有数据库 show databases;-- 删除数据库drop database ladeng; b. -- use `数据库名称`; 表示使用此数据库 use ...
- 【oi模拟赛】长乐中学-不知道多少年
改造二叉树 [题目描述] 小Y在学树论时看到了有关二叉树的介绍:在计算机科学中,二叉树是每个结点最多有两个子结点的有序树.通常子结点被称作"左孩子"和"右孩子" ...
- java异常处理机制详解
java异常处理机制详解 程序很难做到完美,不免有各种各样的异常.比如程序本身有bug,比如程序打印时打印机没有纸了,比如内存不足.为了解决这些异常,我们需要知道异常发生的原因.对于一些常见的异常,我 ...
- 第04组 Alpha冲刺(2/4)
队名:斗地组 组长博客:地址 作业博客:Alpha冲刺(2/4) 各组员情况 林涛(组长) 过去两天完成了哪些任务: 1.收集各个组员的进度 2.写博客 展示GitHub当日代码/文档签入记录: 接下 ...
- C#开发BIMFACE系列26 服务端API之获取模型数据11:获取单个面积分区信息
系列目录 [已更新最新开发文章,点击查看详细] 在<C#开发BIMFACE系列25 服务端API之获取模型数据9:获取楼层对应面积分区列表>一文中介绍了如何获取单个模型中单个楼层包 ...
- vscode源码分析【三】程序的启动逻辑,性能问题的追踪
第一篇: vscode源码分析[一]从源码运行vscode 第二篇:vscode源码分析[二]程序的启动逻辑,第一个窗口是如何创建的 启动追踪 代码文件:src\main.js 如果指定了特定的启动参 ...
- 为什么 Java 不是纯面向对象语言?
什么是纯面向对象语言? 纯面向对象语言或完全面向对象语言是指完全面向对象的语言,它支持或具有将程序内的所有内容视为对象的功能.它不支持原始数据类型(如 int,char,float,bool 等).编 ...
- ASP.NET(1)
1.IIS安装问题,先装VS再装IIS,处理程序映射有问题,使用VS自带的控制台输入命令,注册路径 2.开发模式,一般处理程序,使用IO操作读取html文件,使前后端分离 3.post请求和get请求 ...