SQL索引碎片的产生,处理过程。
本文参考
https://www.cnblogs.com/CareySon/archive/2011/12/22/2297568.html
https://www.jb51.net/softjc/126055.html
本文需要对“索引”和MSSQL中数据的“存储方式”有一定了解。
软件经常在使用一段时间过后会无缘无故卡顿,这是因为在数据库(MSSQL)频繁的插入和更新的操作过程中会产生分页,在分页的过程中产生碎片导致的。所以,对于碎片需要定时的处理。基本上所有的办法都是基于对索引的重建和整理,只是方式不同。
- 删除索引并重建
- 使用DROP_EXISTING语句重建索引
- 使用ALTER INDEX REBUILD语句重建索引
- 使用ALTER INDEX REORGANIZE
以上方式各有优缺点,下面存储过程主要使用3,4
先看一个整理碎片的存储过程,然后采用作业的方式定时执行。
Create PROCEDURE [dbo].[proc_rebuild_index]
@ret INT OUTPUT
AS
SET NOCOUNT ON
BEGIN
DECLARE @fldDefragFragment INT = 10;
DECLARE @fldRebuildFragment INT = 30;
DECLARE @fldMinPageCount INT = 1000;
DECLARE @fldTable VARCHAR(256);
DECLARE @fldIndex VARCHAR(256);
DECLARE @fldPercent INT;
DECLARE @Sql VARCHAR(256);
declare @DBID int;
BEGIN TRY
SET @ret = -1;
set @DBID = db_id();
-- 获取索引碎片状况
DECLARE curIndex CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR
SELECT
TBL.NAME TABLE_NAME
,IDX.NAME INDEX_NAME
,AVGP.AVG_FRAGMENTATION_IN_PERCENT
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(@DBID, NULL,NULL, NULL, 'LIMITED') AS AVGP
INNER JOIN SYS.INDEXES AS IDX
ON AVGP.OBJECT_ID = IDX.OBJECT_ID
AND AVGP.INDEX_ID = IDX.INDEX_ID
INNER JOIN SYS.TABLES AS TBL
ON AVGP.OBJECT_ID = TBL.OBJECT_ID
INNER JOIN SYS.DM_DB_PARTITION_STATS PS
ON AVGP.OBJECT_ID = PS.OBJECT_ID
AND AVGP.INDEX_ID = PS.INDEX_ID
WHERE
AVGP.INDEX_ID >= 1
AND AVGP.AVG_FRAGMENTATION_IN_PERCENT >= @fldDefragFragment
AND PS.RESERVED_PAGE_COUNT >= @fldMinPageCount;
-- 打开游标
OPEN curIndex;
-- 获取游标
FETCH NEXT FROM curIndex
INTO @fldTable,@fldIndex,@fldPercent;
WHILE @@FETCH_STATUS = 0
BEGIN
--碎片率大于30,重建索引
IF @fldPercent >= @fldRebuildFragment
BEGIN
SET @Sql = 'ALTER INDEX ' + @fldIndex + ' ON ' + @fldTable + ' REBUILD';
EXEC(@Sql);
END
ELSE
--碎片率小于30,重组索引
BEGIN
SET @Sql = 'ALTER INDEX ' + @fldIndex + ' ON ' + @fldTable + ' REORGANIZE';
EXEC(@Sql);
END
-- 获取游标
FETCH NEXT FROM curIndex
INTO @fldTable,@fldIndex,@fldPercent;
END
-- 关闭游标
CLOSE curIndex;
DEALLOCATE curIndex;
SET @ret = 0;
END TRY
BEGIN CATCH
SET @ret = -1;
DECLARE @ErrorMessage nvarchar(4000);
DECLARE @ErrorSeverity int;
DECLARE @ErrorState int;
SELECT
@ErrorMessage = ERROR_MESSAGE()
, @ErrorSeverity = ERROR_SEVERITY()
, @ErrorState = ERROR_STATE();
RAISERROR( @ErrorMessage, @ErrorSeverity, @ErrorState);
RETURN;
END CATCH;
END
下面直观的看一下碎片产生的过程
--创建测试表
if object_id('test') is not null
drop table test
go
create table test
(
col1 int,
col2 char(985),
col3 varchar(10)
)
Go
--创建聚焦索引
create CLUSTERED index cix on test(col1);
go
--插入数据
declare @var int
set @var=100
while (@var<900)
begin
insert into test(col1, col2, col3)
values (@var, 'xxx', '')
set @var=@var+100
end;
--查看页存储情况
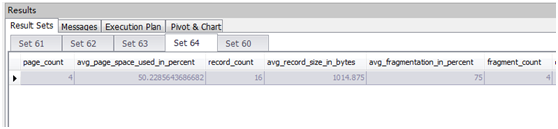
select page_count, avg_page_space_used_in_percent, record_count,
avg_record_size_in_bytes, avg_fragmentation_in_percent, fragment_count,
* from [master].sys.dm_db_index_physical_stats(db_id(), OBJECT_ID('test'), null, null, 'sampled')

--然后做更新操作后,继续查看页存储情况。
update test set col3='更新测试' where col1=100

--再次插入数据后查看页存储情况
declare @var int
set @var=100
while (@var<900)
begin
insert into test(col1, col2, col3)
values (@var, '插入测试', '')
set @var=@var+100
end;
--下面看下对碎片整理之前和之后的IO
set statistics io on
select * from test
alter index cix on test rebuild
select * from test
set statistics io off
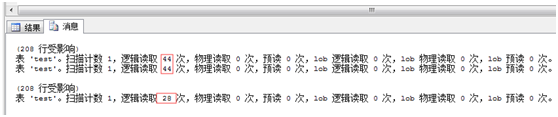
明显的逻辑读取减少了。从而提高了性能
SQL索引碎片的产生,处理过程。的更多相关文章
- sql索引碎片产生的原理 解决碎片的办法(sql碎片整理)(转)
本文讲述了SQL SERVER中碎片产生的原理,内部碎片和外部碎片的概念.以及解决碎片的办法和填充因子.在数据库中,往往每一个对于某一方面性能增加的功能也会伴随着另一方面性能的减弱.系统的学习数据库知 ...
- sql索引碎片产生的原理 解决碎片的办法(sql碎片整理)
本文讲述了SQL SERVER中碎片产生的原理,内部碎片和外部碎片的概念.以及解决碎片的办法和填充因子.在数据库中,往往每一个对于某一方面性能增加的功能也会伴随着另一方面性能的减弱.系统的学习数据库知 ...
- SQL索引碎片整理脚本
原文发布时间为:2011-02-23 -- 来源于本人的百度文章 [由搬家工具导入] reindex是比较好的选择,速度快,但是他不能在线操作INDEXDEFRAG 比较慢,但是可以在线操作rebui ...
- SQL Server2005索引碎片分析和解决方法
SQL Server2005索引碎片分析和解决方法 本文作者(郑贤娴),请您在阅读本文时尊重作者版权. 摘要: SQL Server,为了反应数据的更新,需要维护表上的索引,因而这些索引会形成碎片.根 ...
- 提升SQL Server速度整理索引碎片
转载:http://wenku.baidu.com/view/f64c8a707fd5360cba1adbea.html SQL Server2005索引碎片分析和解决方法 毫无疑问,给表添加索引 ...
- SQL Server索引进阶第十一篇:索引碎片分析与解决
相关有关索引碎片的问题,大家应该是听过不少,也许也很多的朋友已经做了与之相关的工作.那我们今天就来看看这个问题. 为了更好的说明这个问题,我们首先来普及一些背景知识. 知识普及 我们都知道,数据库中的 ...
- sql server 表索引碎片处理
DBCC SHOWCONTIG (Transact-SQL) SQL Server 2005 其他版本 更新日期: 2007 年 9 月 15 日 显示指定的表或视图的数据和索引的碎片信息. 重要提示 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- 转:sql server索引碎片和解决方法
毫无疑问,给表添加索引是有好处的,你要做的大部分工作就是维护索引,在数据更改期间索引可能产生碎片,所以一些维护是必要的.碎片可能是你查询产生性能问题的来源. 那么到底什么是索引碎片呢?索引碎片实际上有 ...
随机推荐
- Unity3D for iOS初级教程:Part 1/3(上)
转自:http://www.cnblogs.com/alongu3d/archive/ 如果图片看不到,请查看原文 这篇教材是来自教程团队成员 Christine Abernathy, 他是Faceb ...
- 笔记||Python3之对象的方法
什么是对象的方法? python中的一切类型的数据都是对象. 对象:数据和方法 对象数据:如 a = 'sfd' 对象方法:其实就是属于该对象的函数 对象的方法调用:对象.方法 字符串对象常用的方法: ...
- jquery (内置遍历数组的函数,事件)
内置遍历数组的函数: 1. $.map(array, function() { }); 取到数组或者对象array中每一项进行遍历 然后在function中处理: var attr = [1,2,3 ...
- IoTClient开发5 - ModBusRtu协议
前言 前面我们介绍了ModBusTcp协议.今天我们接着来介绍ModBusRtu协议.和ModBusTcp不同的是ModBusRtu基于串口通信,ModBusTcp是基于Tcp以太网通信. 所以我们在 ...
- ruby on rails测试
Rspec测试 Rspec(基本测试) 安装 group :development, :test do gem 'rspec-rails', '~> 3.5' end rails generat ...
- js重学
js重学 数据类型 基本数据类型: Undefined.Null.Number.Boolean.String 复杂数据类型:Object Object:由一组无序键值对组成 typeof 未定义--u ...
- 《Java基础知识》Java常量的申明和使用
常量就是从程序开始运行到结束都不变的量.在 Java 程序设计中,使用关键字“final”来声明一个常量,例如下面的程序代码. 这里的 x 是一个常量,但是是在某个方法内的常量,也可以称为成员常量(作 ...
- css应用视觉设计
应用视觉设计:创建一个 CSS 线性渐变 HTML元素的背景色并不局限于单色.css还提供了颜色过渡,也就是渐变.可以通过background里面的linear-gradient()来实现线性渐变,下 ...
- 多个 .NET 框架
目录 应用程序编程接口 C# 和 .NET 版本控制 .NET Standard 目前存在多个 .NET 框架. Microsoft 的宗旨是在最大范围的操作系统和硬件平台上提供 .NET 实现. 下 ...
- 基于vue+leaflet+echart的足迹分享评论平台
(其实题目是随便取的,目的只是用来证明Vue+leaflet+springboot技术栈的可行性) 效果 小专栏不支持上传视频?想看的话可以去我的知乎看最新的文章,那个应该可以.在这里 主要功能描述 ...