《master the game of GO wtth deep neural networks and tree search》研究解读
现在”人工智能“如此火爆的一大直接原因便是deepmind做出的阿尔法狗打败李世石,从那时开始计算机科学/人工智能成为了吹逼的主流。记得当时还是在学校晚新闻的时候看到的李世石输的消息,这个新闻都是我给打开的hhhhh,对当时场景的印象还是蛮深的。现在涵哥就带大家追根溯源,看看把人工智能推上吹逼大道的研究与技术到底是怎么一回事。
在研读aphago工作原理前建议先学完david silver的RL基础课,这样读起来才有意思。
文章分了五个小块,分别是:
supervised learning of policy networks
reinforcement learning of policy networks
reinforcement learning of value networks
searching with policy and value networks
evaluating the playing strength of AlphaGO
如果用一句话说明白alphaGO是怎么工作的,那应该是“combines the policy and value network with MCTS”.
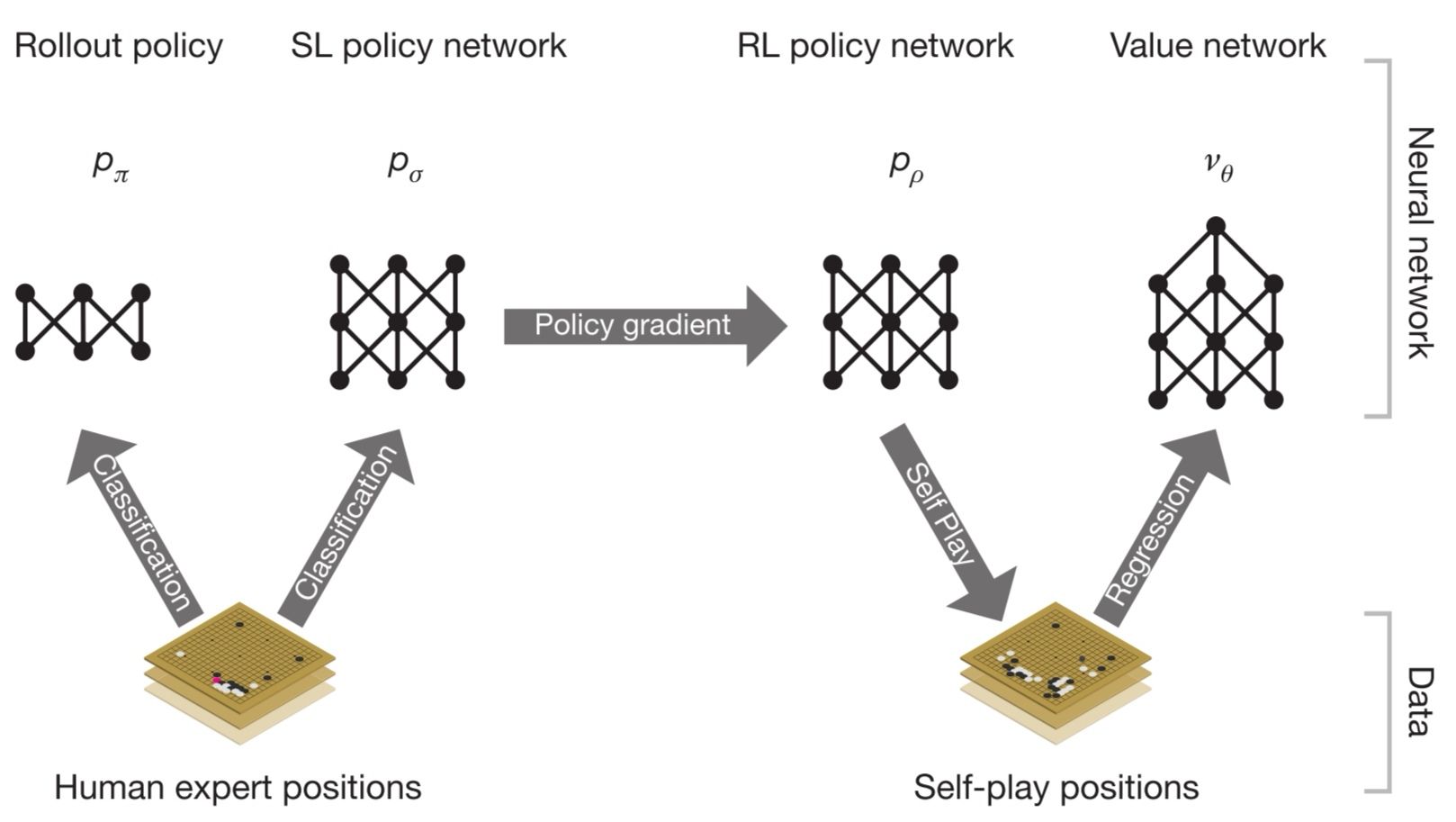
我们先从最基础的policy approximator引入。supervised learning of policy network 是一个由CNN+rectifier_nonlinearities+softmax组成的十三层的神经网络,输入the board state representation也就是当前的棋盘图像(用s表示),输出a probability distribution over all legal moves也就是选择所有符合规则的下一步走法中每一种的可能性(用a表示)。训练数据集来自KGS GO Sever即库存的人类大师对局,采用随机梯度上升法(SGA)进行训练优化————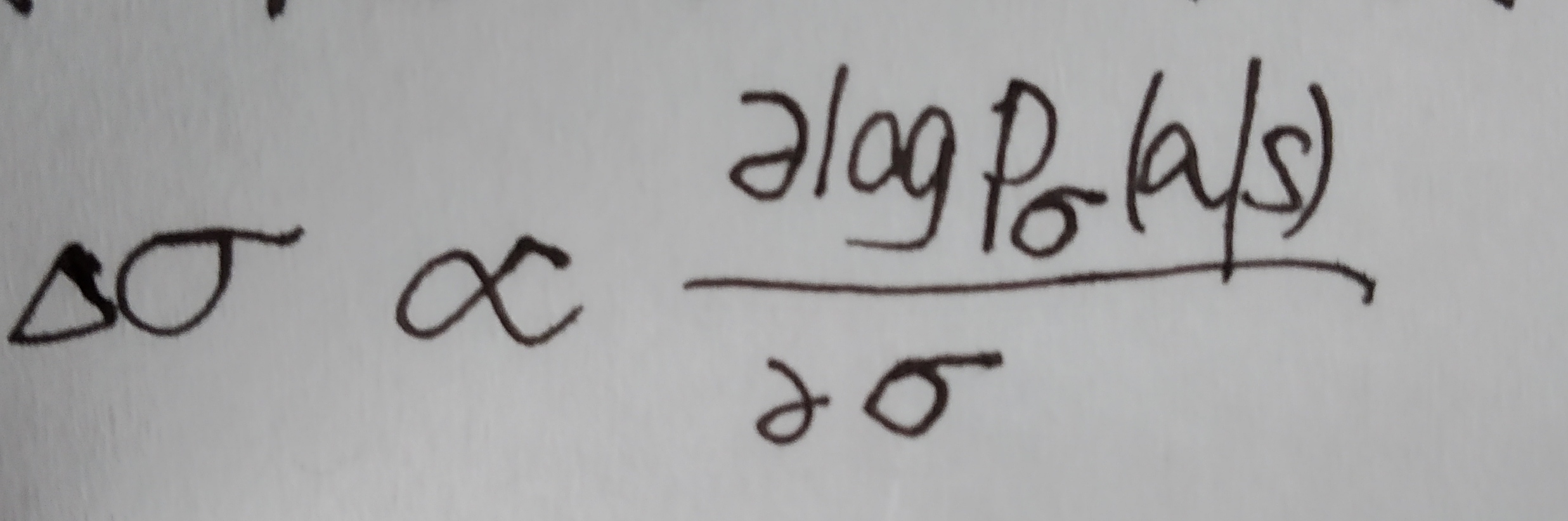 。
。
因为对SLpolicynetwork太笨重不满意,deepmind又训练了rollout policy,a linear softmax of small pattern features with weight pai,它极度快速,延时只有2μs,而policy network需要3ms。
有了第一阶段的尝试,我们把policy gradient拿来用,进入第二阶段。用pρ 表示我们的RL policy network,其结构与pσ 相同,参数初始化为ρ=σ,训练数据通过self play产生。wew play games between the current pρ and a random selected previous iteration of pρ ,也就是说通过当前迭代版本的pρ 和随机选择的先前迭代版本的pρ 之间对局产生训练数据,然后用SGA方法优化pρ ——————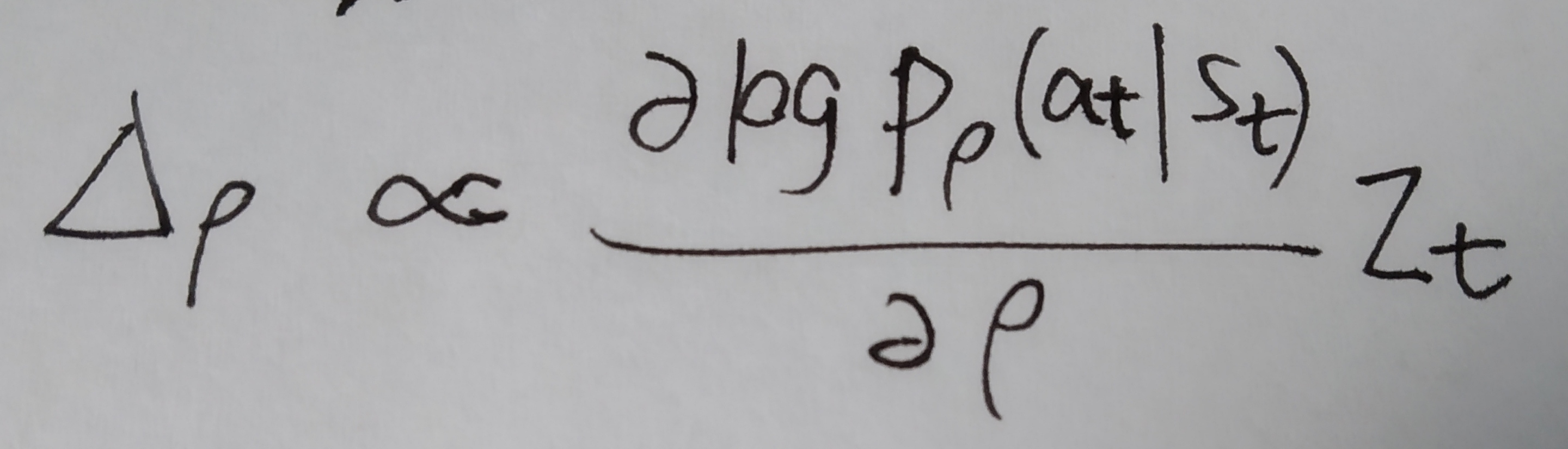 。
。
接下来进入training pipeline的最后阶段,以position evaluation为核心。在此之前我们已经把policy network做好了,也就是准备好了"策略",然后需要有一套对当前棋局的评估器,来评估从当前棋局出发依照策略p最后结果输还是赢。estimating a value function vp(s) that predicts the outcome from position s of game played by using policy p for both players。vp(s) = E[zt|st=s,at...T ~p] 。
We approximate the value function using a value network vθ(s) with weight θ , vθ(s) ≈ vpρ(s) ≈ v*(s) 。vθ(s) 结构和pρ (s)大致相似,只是输出为一个单纯的回归。训练时以state-outcome pairs (s,z)的regression作数据集,通过SGD最小化vθ(s)和corresponding outcome z之间的MSE来优化参数——————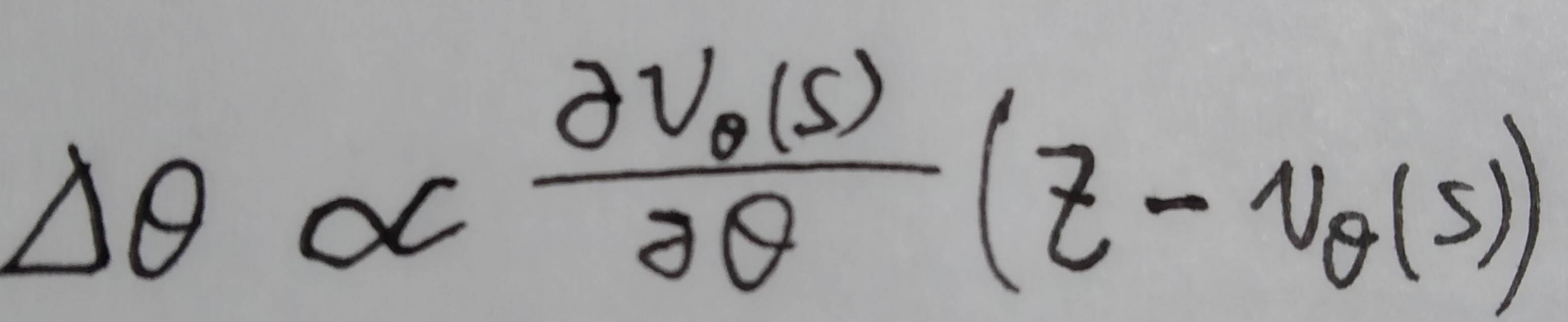 。
。
到现在准备好了策略policy和价值评估器value network,是时候借助蒙特卡洛树搜索(MCTS)对全局建模了。
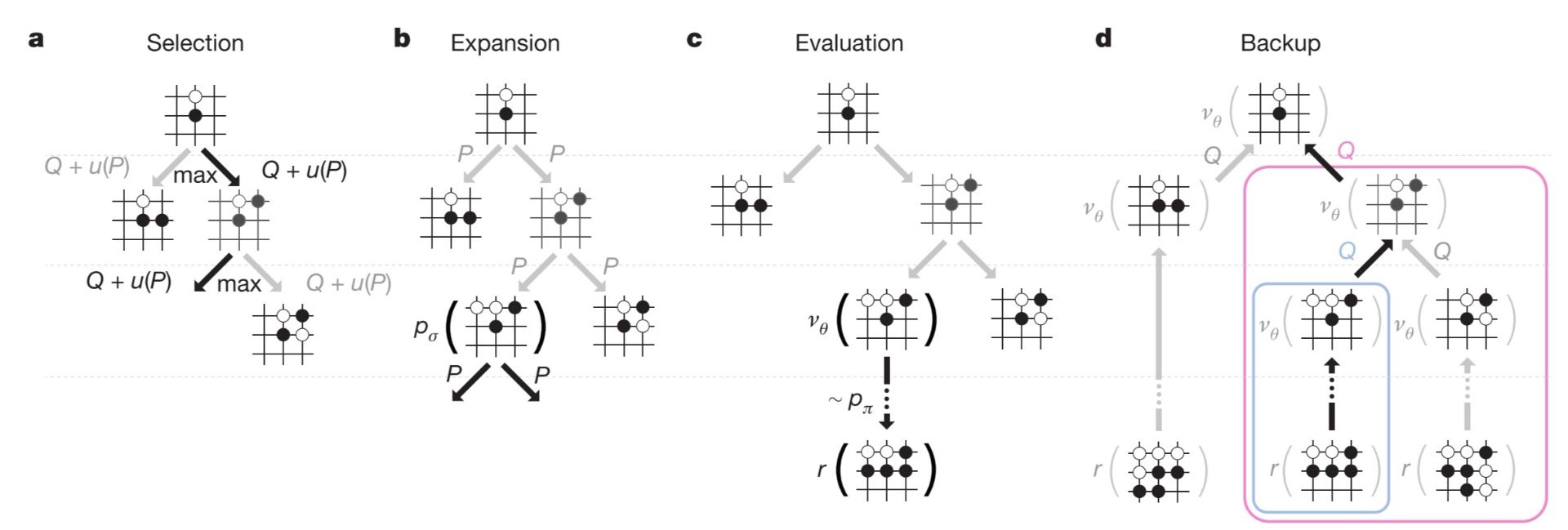
AlphaGO 用MCTS将policy network 和value network结合到一起,通过MCTS的前向搜索选择下一步的行为(就是下一步棋落到哪)。"MCTS with policy and value networks"包含四个核心操作,分别是select,expansion,evaluation,backup。
搜索树的每条边(s,a)存储着action value Q(s,a),visit count N(s,a)和prior probability P(s,a),每个节点是棋局的state。从树根state开始,通过simulation即模拟对局(没有备份操作的完整对局episode)遍历这棵树。对于任意simulation的每个时间步,基于at = argmax( Q(st,a) + u(st,a) )选择action,其中 。对于每一场simulation————遍历走到叶子节点sL时如果还没到simulation的END便进行expansion操作向下扩展。P(s,a)=pσ(a|s)。到达当前simulation的END时,通过V(sL)来评估叶子节点——V(sL) = (1- λ )vθ(sL) + λzL 。vθ(sL)用了value network,zL 是基于rollout policy pπ 一直下到结束的outcome。回看,backup,更新这一场simulation所走过的所有边。每条边的visit count和mean evaluation对从它这儿走过的所有simulations进行累加,si L 表示第i次simulation(总共做了n次simulations)的叶子节点,1(s,a,i)表示第i次simulation的时候(s,a)这条边是否被走过。
。对于每一场simulation————遍历走到叶子节点sL时如果还没到simulation的END便进行expansion操作向下扩展。P(s,a)=pσ(a|s)。到达当前simulation的END时,通过V(sL)来评估叶子节点——V(sL) = (1- λ )vθ(sL) + λzL 。vθ(sL)用了value network,zL 是基于rollout policy pπ 一直下到结束的outcome。回看,backup,更新这一场simulation所走过的所有边。每条边的visit count和mean evaluation对从它这儿走过的所有simulations进行累加,si L 表示第i次simulation(总共做了n次simulations)的叶子节点,1(s,a,i)表示第i次simulation的时候(s,a)这条边是否被走过。 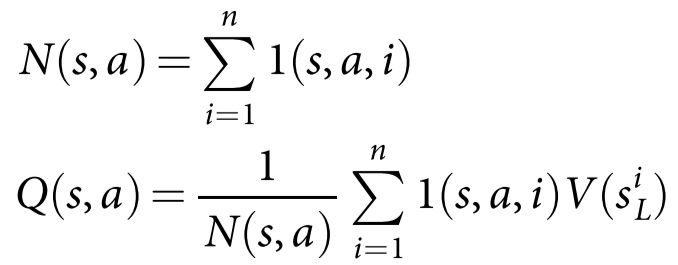
search做完之后,从根结点位置选择访问次数最多的move。至此我们的AlphaGO就正式出道了,这时我仿佛听到上天对它说了句——开始你牛逼闪闪发光的一年吧!
另外deepmind还提到了他们在研究中发现的一个有意思现象:SL policy network比RL policy network表现好,而RL value network 比SL policy network 表现好,作者说“persumably because humans select a diverse beam of promising moves,whereas RL optimizes for the single best move”哈哈哈。
为了培(xun)养(lian)AlphaGO,他的父亲(deepmind)不惜砸重金,采用异步MCTS,40个搜索线程在48个CPU上做simulations,用8个并行计算GPU训练神经网络。另外deepmind也尝试了分布式MCTS,使用了40个搜索线程,1202个CPU,176个GPU。
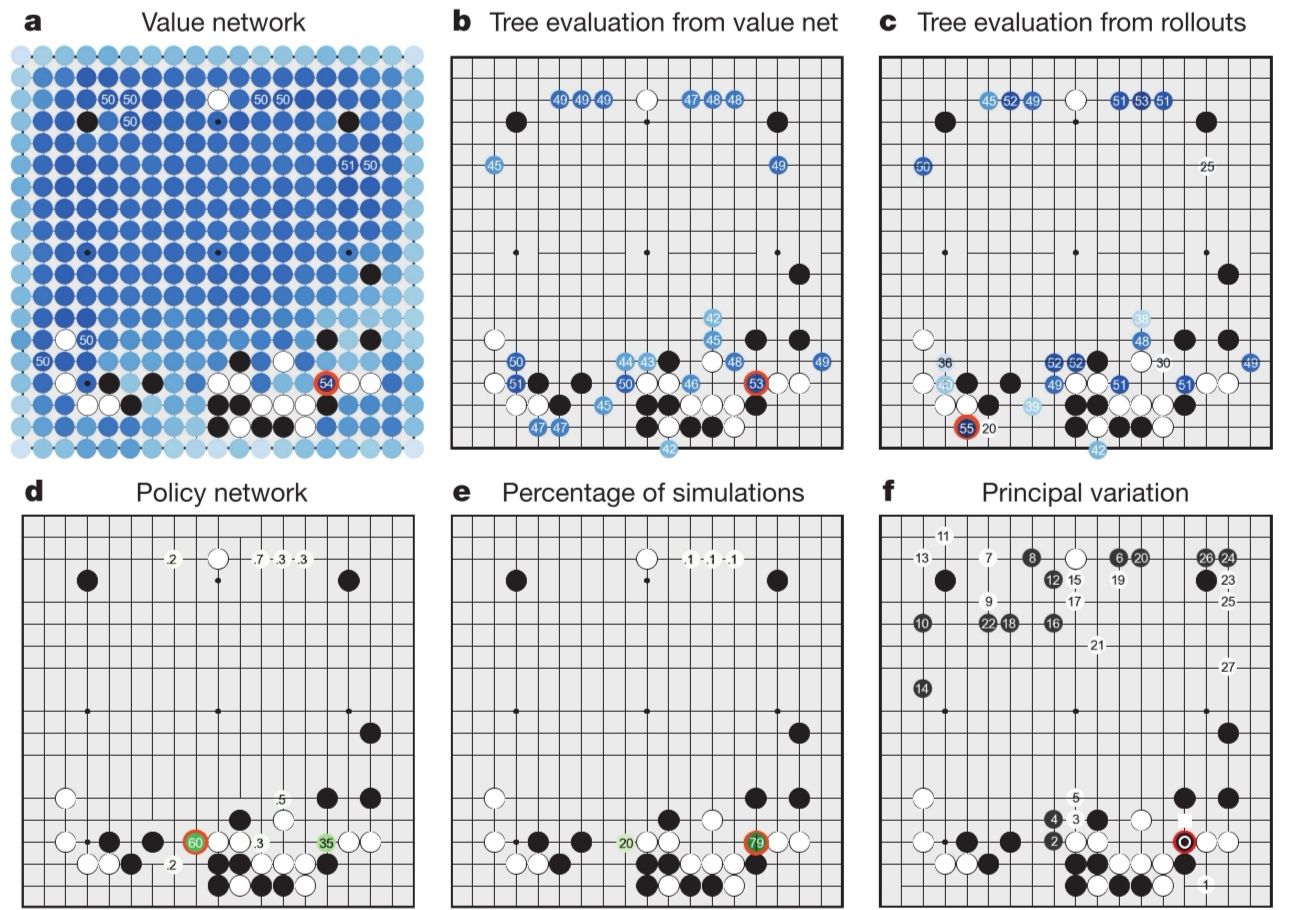
“evaluating the playing strength of AlphaGO”这一小段我不想说了,王婆卖瓜自卖自夸,谁爱看自己去看吧。
注:对于具体method我没做太多分享,但以后想写了可能还会补充一些,我觉得alphaGO的突破之处在于成功用MCTS把policy network和value network结合到了一起。再厉害它也是在前人的基础上做的,并不是自己另辟新路,技术的发展一贯如此。至于本文为啥中英文混体,是因为我思前想后拿不定主意一些地方该怎么用纯中文来表达,这些地方英文来表达是最能传达本意的,所以直接从论文上撸下来了,莫怪莫怪。最后建议自己读一下《master the game of go with deep neaural network and tree search》的原文。链接:https://www.nature.com/articles/nature16961.pdf
《master the game of GO wtth deep neural networks and tree search》研究解读的更多相关文章
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- Mastering the game of Go with deep neural networks and tree search浅析
Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." ...
- AlphaGo论文的译文,用深度神经网络和树搜索征服围棋:Mastering the game of Go with deep neural networks and tree search
转载请声明 http://blog.csdn.net/u013390476/article/details/50925347 前言: 围棋的英文是 the game of Go,标题翻译为:<用 ...
- 论文翻译:2018_Source localization using deep neural networks in a shallow water environment
论文地址:https://asa.scitation.org/doi/abs/10.1121/1.5036725 深度神经网络在浅水环境中的源定位 摘要: 深度神经网络(DNNs)在表征复杂的非线性关 ...
- Classifying plankton with deep neural networks
Classifying plankton with deep neural networks The National Data Science Bowl, a data science compet ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- On Explainability of Deep Neural Networks
On Explainability of Deep Neural Networks « Learning F# Functional Data Structures and Algorithms is ...
随机推荐
- Javascript对this对象的理解
在JavaScript中this表示函数运行的时候自动生成的一个内部对象,只能在函数内部使用,下面是一个简单的例子: function test(){ alert(this == window); } ...
- Hadoop环境部署
1.虚拟机克隆 在VM界面点击查看-自定义-库,然后在左边我的计算机下右键点击安装好的第一个系统,然后管理-克隆,选择克隆系统所在的文件路径即可. 2.三台主机名字修改 root用户下: (1)编辑n ...
- django-模板之过滤器Add(十三)
1.add 若前后类型不匹配,就返回空. 其他的一些过滤器: first:返回列表的第一个值: last:返回列表的最后一个值: length:返回变量值的长度: linebrakebr:将纯文本中的 ...
- 使用Bind提供域名解析服务(正向解析)
小知识: 一般来讲域名比IP地址更加的有含义.也更容易记住,所以通常用户更习惯输入域名来访问网络中的资源,但是计算机主机在互联网中只能通过IP识别对方主机,那么就需要DNS域名解析服务了. DNS域名 ...
- CMMS系统中的物联监测
有条件的设备物联后,可时实查看设备运行状态,如发现异常,可提前干预.
- MIT线性代数:17.正交矩阵和Cram-Schmidt正交化
- 在线热备份数据库之innobackupex 增量备份InnoDB
在线热备份数据库之innobackupex 增量备份InnoDB 什么是增量备份?其原理是什么? 增量备份是基于上一次备份后对新增加的内容进行备份,优点相较于完整备份而言备份内容少时间短,能够节省磁盘 ...
- NOIP模拟 37
啊哈这次没什么智障低错丢rank什么的托词了STO 发现好像110我就拿满了.. 水平不行..只会简单题qaq T1 可以树上启发式合并水过(普通分治也行) T2 我连那么显然的 一劳永逸的容斥都没想 ...
- NOIP模拟 28
果然昨天和别人合照丢的脸今天都加进RP里了 T3是用了dp快速幂(???),T1,T2考试的时候把想法都写注释了. T1: #include<cstdio> using namespace ...
- NOIP 模拟17
最近状态有些不对劲,总是出现各种各样的小错误...... 这次可以说是很水的一套题(T3神仙题除外),T1就是一个优化的暴力,考场上打了一个n的四次方的程序,在距考试结束还有5分钟的时候猜想出来正解, ...