Python 信息提取-爬虫

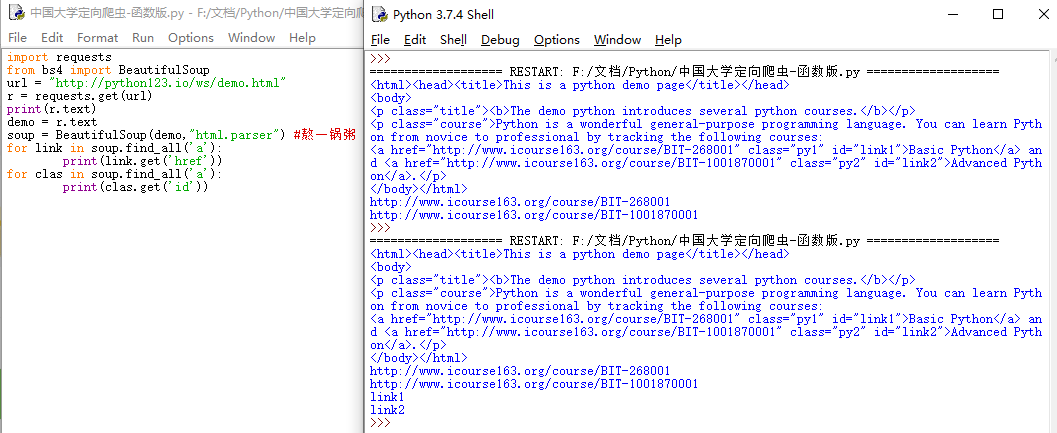

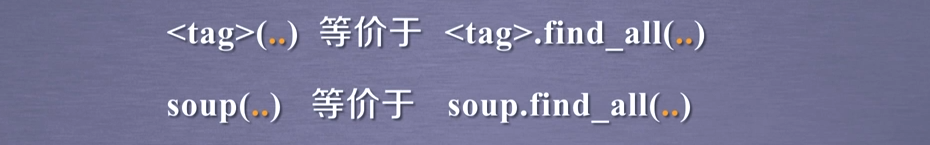

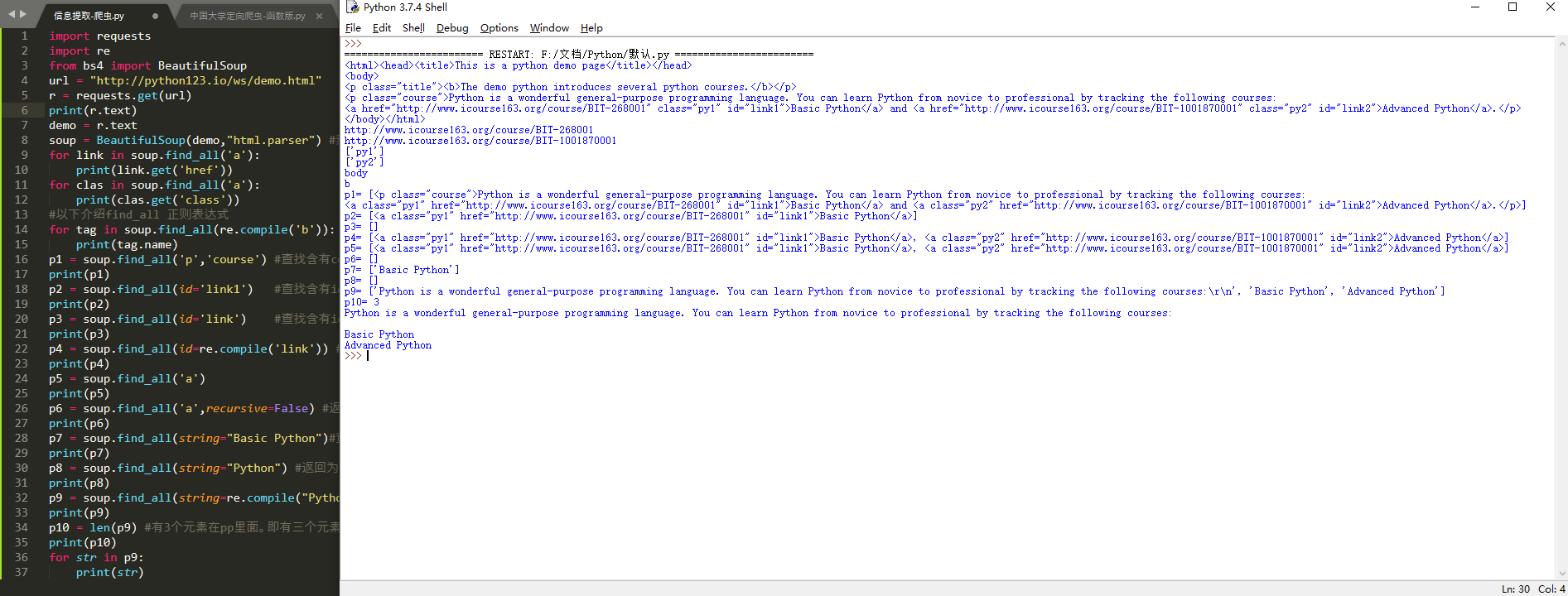
import requests
import re
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅粥
for link in soup.find_all('a'):
print(link.get('href'))
for clas in soup.find_all('a'):
print(clas.get('class'))
#以下介绍find_all 正则表达式
for tag in soup.find_all(re.compile('b')): #查找所有以b开头的标签,第一个属性
print(tag.name)
p1 = soup.find_all('p','course') #查找含有course的p标签内容
print(p1)
p2 = soup.find_all(id='link1') #查找含有id='link1'属性的标签内容,注意:属性不等于文本
print(p2)
p3 = soup.find_all(id='link') #查找含有id='link'属性的标签内容,没有,所以返回未空,即[]
print(p3)
p4 = soup.find_all(id=re.compile('link')) #使用正则表达式查找id属性含有link的内容
print(p4)
p5 = soup.find_all('a') #返回不为空,说明soup的子孙节点含有a标签
print(p5)
p6 = soup.find_all('a',recursive=False) #返回为空,说明soup的子节点无a标签
print(p6)
p7 = soup.find_all(string="Basic Python")#查找正文为且仅为Basic Python的元素
print(p7)
p8 = soup.find_all(string="Python") #返回为空
print(p8)
p9 = soup.find_all(string=re.compile("Python")) #正则表达式查找含有Python的元素,返回列表类型
print(p9)
p10 = len(p9) #有3个元素在pp里面。即有三个元素含Python
print(p10)
for str in p9:
print(str)
Python 信息提取-爬虫的更多相关文章
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
随机推荐
- Dockerfile 定制镜像
从上一篇文章中我们可以了解到,镜像的定制实际上就是定制每一层所添加的配置.文件等信息,但是命令毕竟只是命令,每次定制都得去重复执行这个命令,而且还不够直观,如果我们可以把每一层修改.安装.构建.操作的 ...
- 零基础攻略!如何使用kubectl和HPA扩展Kubernetes应用程序
现如今,Kubernetes已经完全改变了软件开发方式.Kubernetes作为一个管理容器化工作负载及服务的开源平台,其拥有可移植.可扩展的特性,并促进了声明式配置和自动化,同时它还证明了自己是管理 ...
- Mybatis:CRUD操作
提示: Mapper配置文件的命名空间为对应接口包名+接口名字,这个经常会忘记和搞错的!! select标签 在接口中编写三个查询方法 //获取全部用户List<User> selectU ...
- [考试反思]1102csp-s模拟测试98:苟活
好像没有什么粘文件得分的必要(本来就没多少分了也丢不了多少了) 而且从这次开始小绿框不代表首杀而代表手速了2333 其实我挺菜的,牛一个frepoen送掉100分才跟我并列%%%milkfun mik ...
- [考试反思]1011csp-s模拟测试69:无常
承蒙大脸skyh的毒奶,加之以被kx和Parisb以及板儿逼剥夺了一中午的睡眠(其实还有半个晚上)RP守恒终于失效了,连续两场没考好 RP也是不够了,竟然考原题,而且还不换题,连样例都一模一样只不过加 ...
- [考试反思]0924csp-s模拟测试51:破碎
总参赛人数:15 有点菜. 不知道是撞了什么大运没有滚出A层. 但是一回到A层就暴露出了一个大问题:码速. 不是调试速度,,就是纯粹码的速度... 边讲考试状态边说吧... 上来肝T1.一看,是个换根 ...
- Oracle“ORA-00979:不是GROUP BY 表达式”解决方式
今天在工作中碰到一个问题,用group by 语句进行分组时出现ORA-00979错误. 代码如下: select R.ORDER_NO, R.PRODUCT_CODE, R.REGION_NO, R ...
- day2 上午 游戏 对应关系--->判断素数---->多重背包 神题
#include<iostream> using namespace std; int n; ; ]; long long p[maxn]; long long dp[maxn][maxn ...
- 获取Centos的Docker CE
Docker文档 Docker提供了一种在容器中运行安全隔离的应用程序的方法,它与所有依赖项和库打包在一起. 获取Centos的Docker CE 一.OS要求 要安装Docker Engine-Co ...
- TCP协议--TCP三次握手和四次挥手
TCP三次握手和四次挥手 TCP有6种标示:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急) 一.TCP三次握手 第一次握手 客户端向服务器发出连 ...