CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的
Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时间来排谁先执行
这里会有几个问题,Timestamp是什么,由谁来打,什么时候打上Timestamp
首先每个T需要有一个unique的timestamp,这个在单机很容易实现;
其次,Timestamp必须是单调递增的
最后,不同的schema会选择在不同的时间给txn打上timestamp,可能是txn刚到的时候,也可能是txn执行完的时候
Timestamp可以有多种形式,系统时间,逻辑counter,或者hybrid

Basic Timestamp Ordering Protocol
设计比较直觉,
首先,给每个object加上,读时间戳,写时间戳,表示最后一次读写该对象的时间
读的时候,拿当前事务ts和写ts比较,如果写ts比较新,那么读需要abort,因为,你不能读一个未来的值;
写的时候,要同时比较该对象的读,写ts,比较写是因为你不能用过去的值覆盖未来的值,比较读,是因为如果有未来的txn读过这个值,你就不能再更新
同时,这里无论读写,都会把当前的value,copy到local进行缓存,这是避免txn频繁冲突,因为对于一个txn数据应该可以重复读的,所以如果不缓存,那么如果这个值被别的txn改了,会很容易导致txn abort



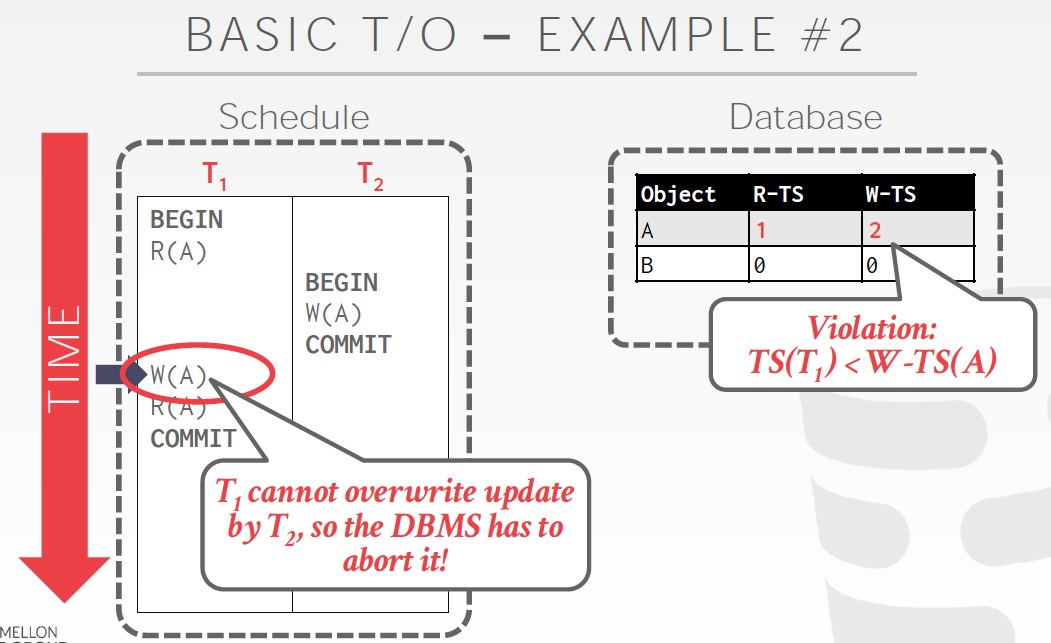
例子,
T1在更新A的时候,ts已经小于W-TS,所以不能更新,需要abort
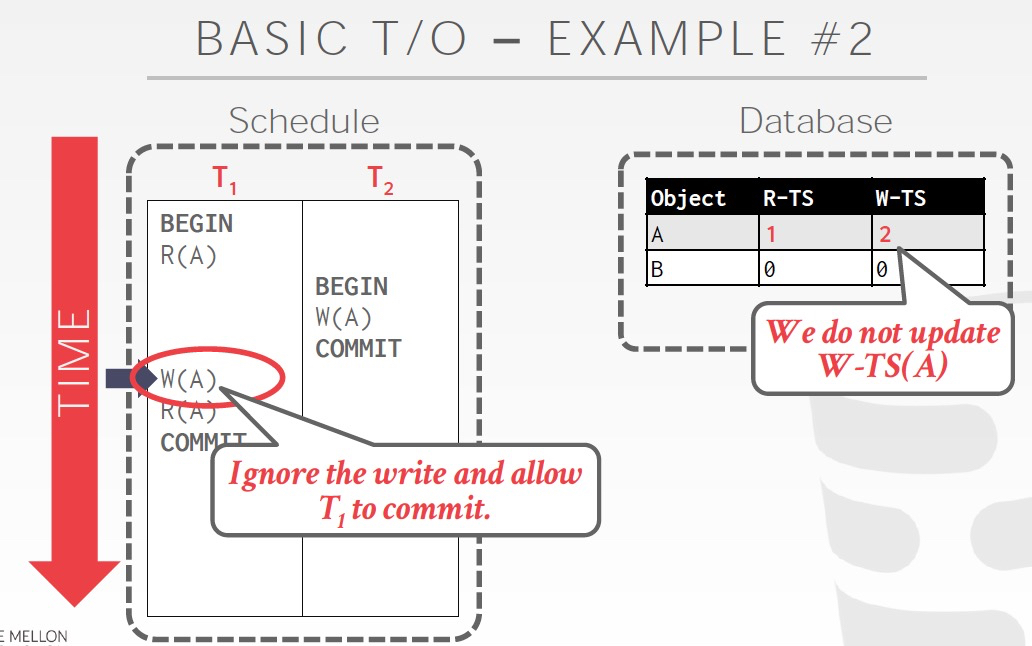
Thomas write rule,一种降低abort概率的方法
思路如果txn在write的时候发现,W-TS大,即未来的时间,那么直接跳过这个write,因为这个write反正都是被覆盖的,所以不关键;

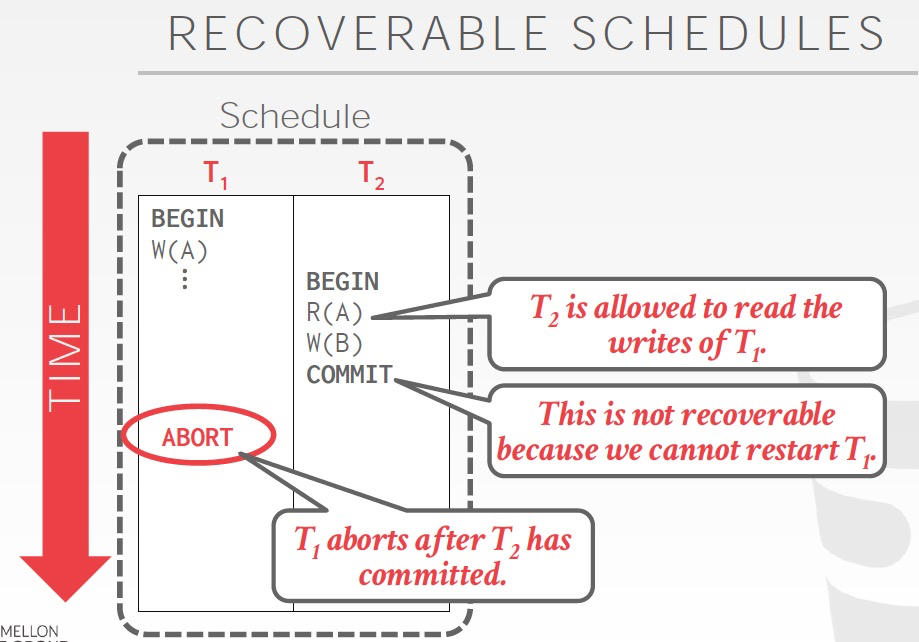
用Basic T/O产生的shedule是不可recoverable的
什么叫recoverable,当你commit的时候,你所依赖的所有txn已经完成commit;
这样才是可恢复的,不然你commit完后,数据库crash了,那么你之前看到的或依赖的txn还没有commit就丢失了,但你的结果已经完成commit,就产生不一致

Basic T/O的问题,
1. 不可recoverable
2. overhead比较重,需要每次读写都更新ts,而且还需要把数据copy到local
3. 长txn会starve,比较难成功,因为很容易被冲突,abort

乐观锁,基于的假设,冲突极少发生,否则乐观锁的成本反而更加高
所以基于这样的假设,那么算法可以进一步优化,OCC算法
分3个阶段,
1. 每个txn都创建一个独立的workspace,无论读写,都把数据copy到自己的workspace里面进行操作
2. validate,这个txn是否和其他txn冲突
3. 如果不冲突,把变更合并到global数据库


可以看到,其中比较难的是第二步,validation
validation就是判断当前txn和所有其他的txn是否有WR或WW冲突
首先假设同时只有一个txn进行validation,即serial validation
然后txn的ts是在validation阶段的开始被assign的,这个很关键
如何check当前txn和其他所有的txn之间是否有冲突?
如果Ti 先于 Tj,那么我们要满足以下3个条件中的一个

1. Ti在Tj开始之前,完成所有3个阶段,就是串行执行,这个肯定没有冲突

2. Ti在Tj开始Write phase前完成,并且Ti没有写任何会被Tj读到的对象

例子,
T1写了A,而在T2中会读到A,这样就不满足上面的条件2

这种情况是安全的,因为这个时候T2也已经结束了,并且T2只是读了A当并没有写任何数据
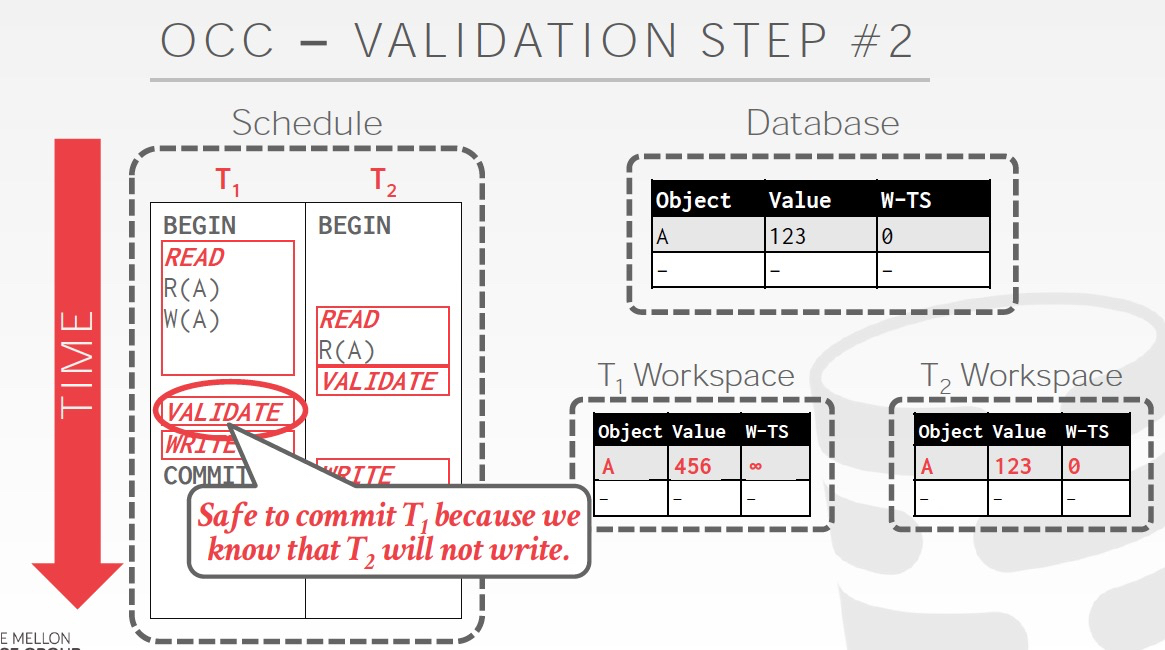
3. Ti的Read phase比Tj的Read phase早结束,并且Ti没有写任何会被Tj读或写到的对象

例子,
这个例子T1在validation的时候,T2没有读或写A,所以安全的,把T1的结果提交到Database
然后这个时候T2读A,是不会有问题的

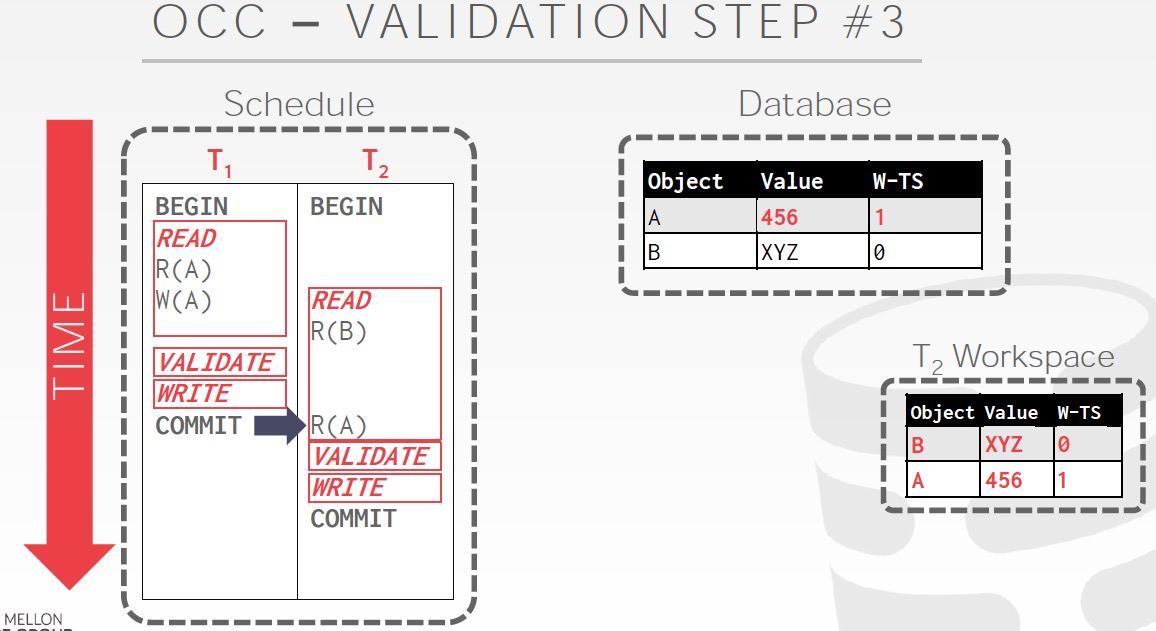
OCC算法的性能问题,
也要把数据copy到本地,比较高的overhead
Validation和Write会成为瓶颈,因为这里需要串行
Abort的代价更高,因为这里txn已经做完了,才会validation判断是否要abort

OCC算法,还有明显的性能问题,当txn很多的时候,每个txn提交,都需要去判断是否和其他的txn冲突,就算没有冲突,但是每次比较的代价也是非常高的
所以提出Partition-based T/O,如果数据水平划分成很多partition,那么在每个partition上的txn就会变少,比较txn之间的冲突的效率就会提升

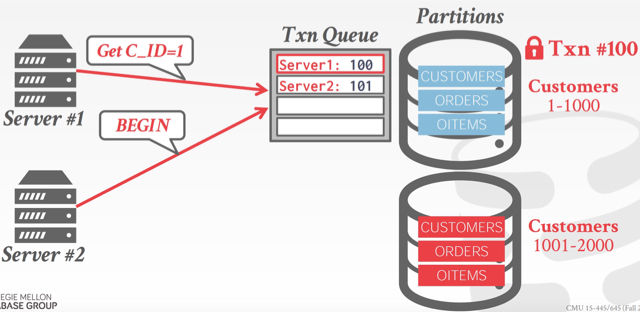

Partitioned T/O的性能问题是,
如果每个txn都只访问一个partition,那么性能会比较好

幻读
之前的txn都是读写,但是没有insert或delete
所以对于下面的情况,2PL是不管用的,因为锁机制只能锁已经存在的tuple,所以这个问题是Phantom,幻读

解决这个问题的方法,
predict locking,满足这个predict的records都lock,这个很难实现

对于predict locking一种可能的实现方式是,index locking,锁包含这个predict的index page
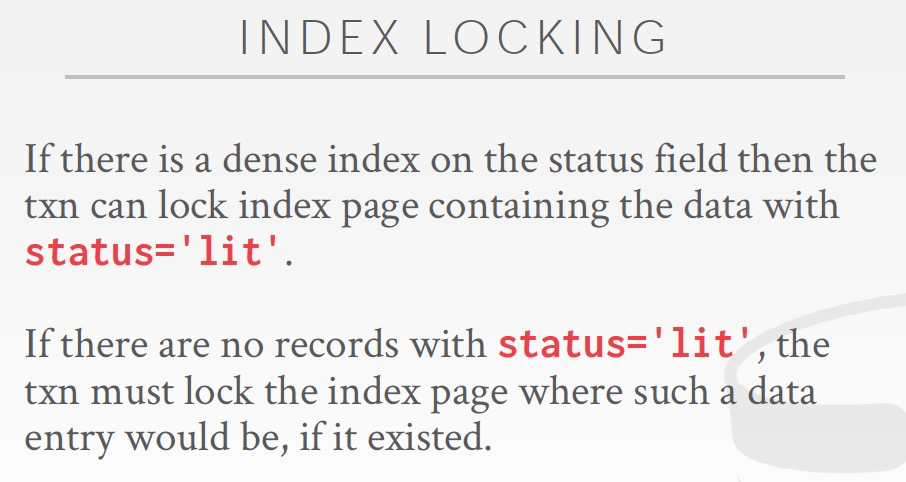
如果没有合适的index,只能锁表上的每一页或直接锁table

通过重复查询来判断是否有幻读,很低效的方式,一般数据库都不会采用

这里最后再讲一个概念,隔离级别
最强的就是之前一直在讲的,serializable,虽然有最强的一致性,但也大大牺牲了数据库的并发性
但是有的应用和场景,其实不需要那么强的一致性,所以可以牺牲一些一致性来换取一定的并发性
不同的隔离级别会产生哪些不一致情况在右图可以看出

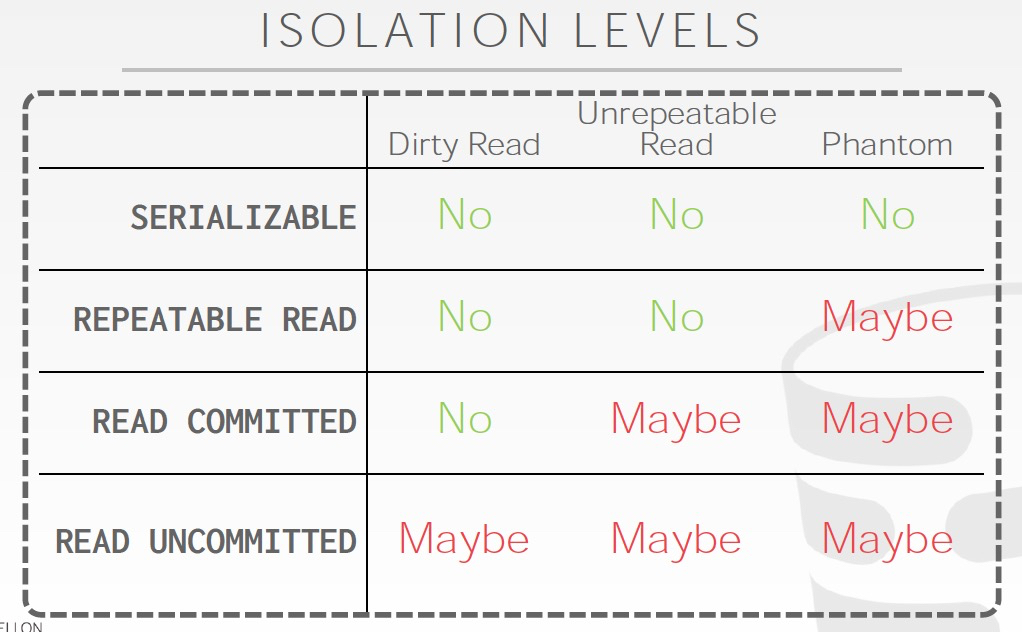
那么如何实现这些隔离级别?

列出在SQL标准中,如果设置隔离级别

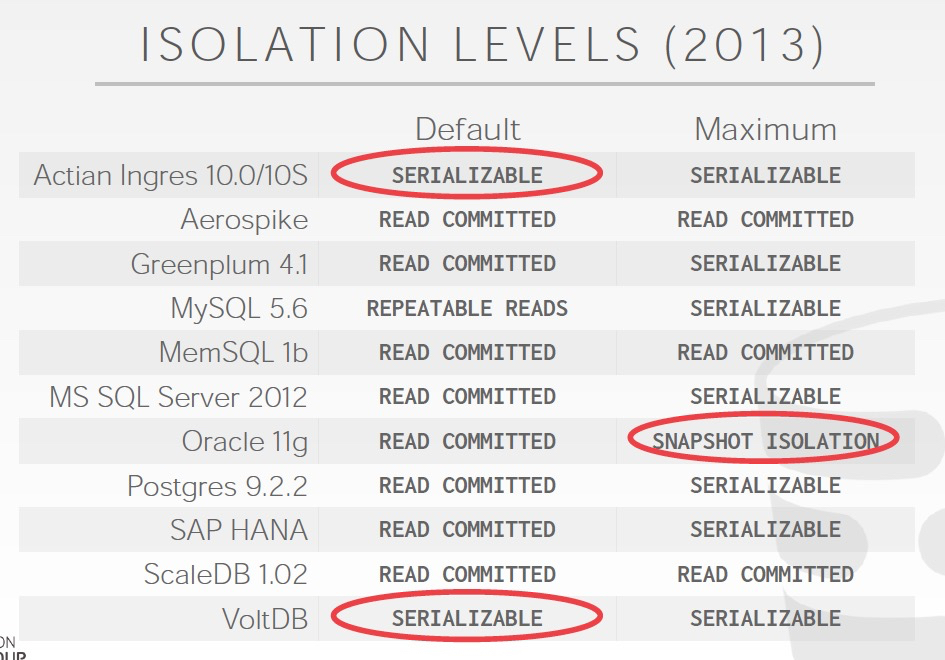
这里列存各个数据库引擎,默认的和支持的隔离级别
CMU Database Systems - Timestamp Ordering Concurrency Control的更多相关文章
- CMU Database Systems - Indexes
这章主要描述索引,即通过什么样的数据结构可以更加快速的查询到数据 介绍Hash Tables,B+tree,SkipList 以及索引的并行访问 Hash Tables hash tables可以实现 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
随机推荐
- 爬虫之cookie与代理
一, 基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达 ...
- python之编码与解码、is 与==的区别
一.编码与解码 编码的过程其实就是采用一定的编码格式将unicode字符转换成str字符的过程 非ASCII码字符按字节为单位被编码成十六进制转义字符 解码采用的编码格式跟设置和环境有关 ascii ...
- linux 利用LDAP身份集中认证
碰巧所在的公司用到了ldap 集中身份认证,所有打算研究下这套架构,但是看遍了网络上的很多教程,要么不完整,要么就是照着根本弄不出来,十月一研究了三天,结合八方资源终于弄出来了,真是不容易,哎,特此记 ...
- homebrew一直处于updating状态
vim ~/.bash_profile 增加一行 export HOMEBREW_NO_AUTO_UPDATE=true 之后再source一下
- Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD.节点数.Executor数.core数目的关系和Application,Driver,Job,Task,Stage理解 from:https://bl ...
- Spark-2.3.2 Java SparkSQL的自定义HBase数据源
由于SparkSQL不支持HBase的数据源(HBase-1.1.2),网上有很多是采用Hortonworks的SHC,而SparkSQL操作HBase自定义数据源大多数都是基于Scala实现,我就自 ...
- linux系统编程之管道(三)
今天继续研究管道的内容,这次主要是研究一下命名管道,以及与之前学过的匿名管道的区别,话不多说,进入正题: 所以说,我们要知道命名管道的作用,可以进行毫无关系的两个进程间进行通讯,这是匿名管道所无法实现 ...
- 开发指南~小程序代码构成~JSON配置
2.1 JSON 配置 JSON 是一种数据格式,并不是编程语言,在小程序中,JSON扮演的静态配置的角色. 2.1.1 一个例子 先看一个例子,打开开发工具的编辑器,在根目录下可以找到 app.j ...
- C#:抽象类PK密封类
最近在看关于C#的书,看到了抽象类和抽象方法,另外还看到了密封类和密封方法,那么二者有什么联系又有什么区别,我把最近的收获分享给大家! 1.抽象类和抽象方法: ·C#使用abstract关键字,将类或 ...
- mac pro下安装brew软件包管理工具
Homebrew简称brew,OSX上的软件包管理工具,在Mac终端可以通过brew安装.更新.卸载软件. 1.打开终端直接输入下面指令回车: ruby -e "$(curl -fsSL h ...