Linux IO 概念(2)
在上一篇IO底层的概念中杂合了很多模糊的概念,受知识水平的限制,只是从网上抄了很多过来.从linux一切皆文件的设计哲学,介绍了文件描述符,从进程的运行内存分配,进程的切换,介绍了进程的阻塞,以及引出了阻塞IO.
在讲到阻塞IO的时,候受限于知识水平,也没有实际操作过,还是没有理解进程和IO函数的调用关系,IO又是如何操作磁盘,文件描述符又是怎样工作,进程怎么去拷贝字节流,
了解linuxIO的最终目的我是想知道JavaIO和JavaNIO在虚拟机中是如何调用的,虚拟机作为一个linux进程又是如何跟底层IO进行交互的.这些问题最终还是要去图书馆查阅书籍才能理解的更清楚,
下面继续在网络上搬迁别人家的博客
注:以下下文章整理自网络
阻塞IO
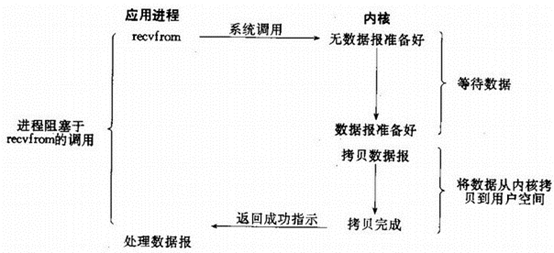
非阻塞IO

多路复用IO,
多路复用IO是为了处理多个IO问价句柄的数据操作,一个典型场景是当有很多socket服务监听不同端口以接收数据时,如果采用阻塞IO则需要多线程,每个线程和进程负责一个端口socket.但是,大量的线程和进程往往造成CPU的浪费
linuxIO多路复用技术提供一个单进程,单线程内监听多个IO读写时间的机制,其基本原理是各个IO将句柄设置为非阻塞IO,然后将各个IO句柄注册到linux提供的IO复用函数上(select,poll或者epoll),如果某个句柄的IO数据就绪,则函数返回,由于开发者进行该IO数据处理.多路复用函数帮我们进行了多个非阻塞IO数据是否就绪的轮询操作,只不过IO多路复用函数的轮询更有效率,因为函数一次性传递文件描述符到内核态,在内核态中进行轮询(epoll则是进行等待边缘事件的触发),不必反复进行用户态和内核态的切换
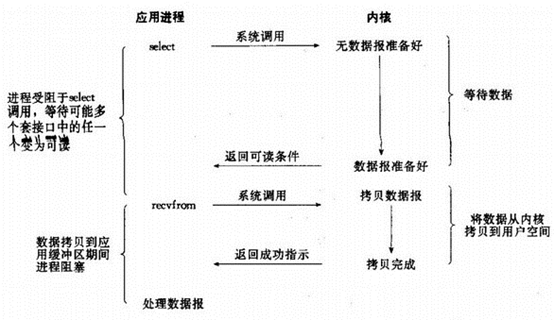
linuxIO的多路复用技术主要的实现方式,select,poll,和epoll,过根据触发方式不同,与是否需要轮询的的不同
SELECT
select是Linux最早支持的多路IO复用函数,其函数原型为:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* errorfds, struct timeval* timeout);
参数nfds是所有文件描述符的数量+1,而readfds、writefds和errorfds分别为等待读、写和错误IO操作的文件描述符的集合,而timeout是超时时间,超过timeout时间select将返回(0表示不阻塞,NULL则是没有超时时间)。
select的返回值是有可用的IO操作的文件描述符数量,如果超时返回0,如果发生错误返回-1。
select函数需要和四个宏配合使用:FD_SET()、FD_CLR()、FD_ZERO()和FD_ISSET()。具体使用不再介绍,可以参考资料[7,8]的相关内容,下面介绍select函数的内部实现原理和主要流程:
1、使用copy_from_user从用户空间拷贝fd_set到内核空间;
2、遍历所有fd,调用其对应的poll函数,再由poll函数调用__pollwait函数;
3、poll函数会判断当前文件描述符上的IO操作是否就绪,并利用__pollwait的主要工作就是把当前进程挂到设备的等待队列中,但这并不代表进程会睡眠;
4、poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值;
5、如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout使进程进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程,更新fd_set后select返回;
6、如果超过超时时间schedule_timeout,还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd,流程如上;
7、把fd_set从内核空间拷贝到用户空间,select返回。
从上面的select内部流程中可以看出,select操作既有阻塞等待,也有主动轮询,相比于纯粹的轮询操作,效率应该稍微高一些。但是其缺点仍然十分明显:
1、每次调用select,都需要把fd集合从用户态拷贝到内核态返回时还要从内核态拷贝到用户态,这个开销在fd很多时会很大;
2、每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3、select返回后,用户不得不自己再遍历一遍fd集合,以找到哪些fd的IO操作可用;
4、再次调用select时,fd数组需要重新被初始化;
5、select支持的文件描述符数量太小了,默认是1024。
POLL
poll的函数原型为int poll(struct pollfd *fds, nfds_t nfds, int timeout)。其实现和select非常相似,只是描述fd集合的方式不同,poll通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制。
pollfd中的events字段和revents分别用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
poll的实现机制与select类似,其对应内核中的sys_poll,只不过poll向内核传递pollfd数组,然后对pollfd中的每个描述符进行poll。
poll返回后,同样需要对pollfd中的每个元素检查其revents值,来得指事件是否发生。
由此可见,poll除了没有文件描述个数限制和文件描述符数组只需初始化一次以外,select的其他缺点扔存在,而存在的缺点是select和poll性能低的主要原因。
EPOLL(等下一个IO可读取才返回)
Epoll是Linux 2.6版本之后才引入的一种新的多路IO复用技术,epoll解决了select技术的所有主要缺点,可以取代select方式成为推荐的多路IO复用技术。
epoll通过epoll_create创建一个用于epoll轮询的描述符,通过epoll_ctl添加/修改/删除事件,通过epoll_wait等待IO就绪或者IO状态变化的事件发生,epoll_wait的第二个参数用于存放结果。
epoll与select、poll不同,首先,其不用每次调用都向内核拷贝事件描述信息,在第一次调用后,事件信息就会与对应的epoll描述符关联起来。另外epoll不是通过轮询,而是通过在等待的描述符上注册回调函数,当事件发生时,回调函数负责把发生的事件存储在就绪事件链表中,最后写到用户空间。
epoll返回后,该参数指向的缓冲区中即为发生的事件,对缓冲区中每个元素进行处理即可,而不需要像poll、select那样进行轮询检查。
之所以epoll能够避免效率低下的主动轮询,而完全采用效率更高的被动等待IO事件通知,是因为epoll在返回时机上支持被成为“边沿触发”(edge=triggered)的新思想,与此相对,select的触发时机被成为“水平触发”(level-triggered)。epoll同时支持这两种触发方式。
边沿触发是指当有新的IO事件发生时,epoll才唤醒进程之后返回;而水平触发是指只要当前IO满足就绪态的要求,epoll或select就会检查到然后返回,即使在调用之后没有任何新的IO事件发生。
举例来说,一个管道内收到了数据,注册该管道描述符的epoll返回,但是用户只读取了一部分数据,然后再次调用了epoll。这时,如果是水平触发方式,epoll将立刻返回,因为当前有数据可读,满足IO就绪的要求;但是如果是边沿触发方式,epoll不会返回,因为调用之后还没有新的IO事件发生,直到有新的数据到来,epoll才会返回,用户可以一并读到老的数据和新的数据。
通过边沿触发方式,epoll可以注册回调函数,等待期望的IO事件发生,系统内核会在事件发生时通知,而不必像水平触发那样去主动轮询检查状态。边沿触发和水平触发方式类似于电子信号中的电位高低变化,由此得名。
信号驱动IO
信号驱动的IO是一种半异步的IO模型。使用信号驱动I/O时,当网络套接字可读后,内核通过发送SIGIO信号通知应用进程,于是应用可以开始读取数据。
具体的说,程序首先允许套接字使用信号驱动I/O模式,并且通过sigaction系统调用注册一个SIGIO信号处理程序。当有数据到达后,系统向应用进程交付一个SIGIO信号,然后应用程序调用read函数从内核中读取数据到用户态的数据缓存中。这样应用进程都不会因为尚无数据达到而被阻塞,应用主循环逻辑可以继续执行其他功能,直到收到通知后去读取数据或者处理已经在信号处理程序中读取完毕的数据。
设置套接字允许信号驱动IO的步骤如下:
1.注册SIGIO信号处理程序。(安装信号处理器)
2.使用fcntl的F_SETOWN命令,设置套接字所有者。(设置套接字的所有者)
3.使用fcntl的F_SETFL命令,置O_ASYNC标志,允许套接字信号驱动I/O。(允许这个套接字进行信号输入输出)
信号驱动的IO内部时序流程如下所示:
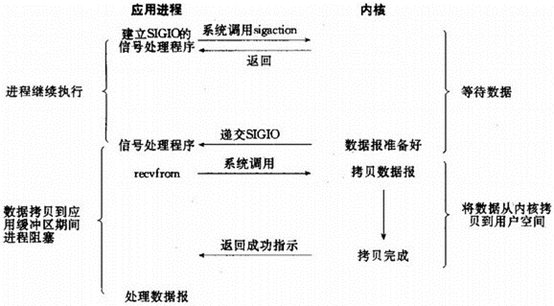
之所以说信号驱动的IO是半异步的,是因为实际读取数据到应用进程缓存的工作仍然是由应用自己负责的,而这部分工作执行期间进程依然是阻塞的,如上图中的后半部分。而在下面介绍的异步IO则是完全的异步
异步IO
异步I/O模型是一种处理与I/O重叠进行的模型。读请求会立即返回,说明read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次I/O 处理过程。
在一个进程中为了执行多个I/O请求而对计算操作和I/O 处理进行重叠处理的能力利用了处理速度与I/O速度之间的差异。当一个或多个I/O 请求挂起时,CPU可以执行其他任务;或者更为常见的是,在发起其他I/O的同时对已经完成的I/O 进行操作。
在传统的I/O模型中,有一个使用惟一句柄标识的I/O 通道。在 UNIX® 中,这些句柄是文件描述符(这等同于文件、管道、套接字等等)。在阻塞I/O中,我们发起了一次传输操作,当传输操作完成或发生错误时,系统调用就会返回。
在异步非阻塞I/O中,我们可以同时发起多个传输操作。这需要每个传输操作都有惟一的上下文,这样我们才能在它们完成时区分到底是哪个传输操作完成了。在AIO中,这是一个aiocb(AIO I/O Control Block)结构。这个结构包含了有关传输的所有信息,包括为数据准备的用户缓冲区。在产生I/O(称为完成)通知时,aiocb结构就被用来惟一标识所完成的I/O操作。
以read操作为例,一个异步IO操作的时序流程如下图所示:
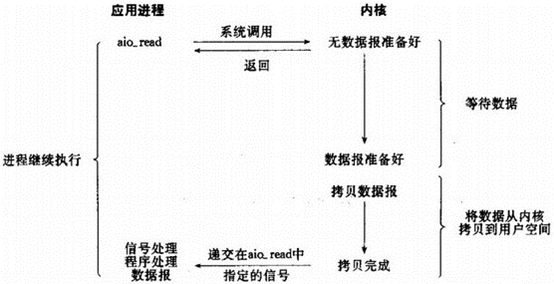
从上图中可以看出,比起信号驱动的IO那种半异步模式,异步IO中从内核拷贝数据到用户缓存空间的工作也是有系统完成的异步过程,用户程序只需要在指定的数组中引用数据即可。
数据接收后的处理程序是一个回调函数,Linux提供了两种机制实现异步IO的回调函数:
一种是信号回调函数机制,这种机制跟信号驱动的IO类似,利用信号触发回调函数的执行以处理接收的数据,这回中断正在执行的代码,而不会产生新的进程和线程;
另一种是线程回调函数机制,在这种机制下也需要编写相同的回调函数,但是这个函数将注册到异步IO的事件回调结构体对象中,当数据接收完成后将创建新的线程,在新的线程中调用回调函数进行数据处理。
各个IO模型的比较和应用场景
为了比较各个IO模型的性能,这里设计了三种最主要的应用场景,分别是单个用户连接的频繁IO操作、少量用户连接的并发频繁IO操作、大量用户连接的并发频繁IO操作。在进行性能比较时,主要考虑的是总的IO等待、系统调用情况和CPU调度切换,IO等待越少、系统调用越少、CPU调度切换越少意味着IO操作的高效率。
在单个用户连接频繁的IO操作中,可以采用单线程单进程的方式,这样可以不用考虑进程内部的CPU调度,只需关注IO等待和系统调用的频率。从上面各个IO模型的流程时序图来看,AIO的用户程序在执行Io操作时没有任何Io等待,而且只需要调用IO操作时一次系统调用,由于是异步操作,信号操作的回传不需要进行系统调用,连由内核返回用户态的系统调用都省了,因此效率最高。
在信号驱动的IO模型中,IO等待时间要比基本的阻塞式IO和多路复用IO要少,只需要等待数据从内核到用户缓存的操作。但是信号驱动的IO模型和多路复用IO的系统调用次数一样,需要两次系统调用,共四次上下文切换,而基本的阻塞模式只需要一次系统调用。在IO频繁的场景下,还是基本阻塞IO效率最高,其次为信号驱动IO,然后是多路复用IO。
基本非阻塞IO的性能最差,因为在IO等待期间不仅不交出CPU控制权,还一遍又一遍进行昂贵的系统调用操作进行主动轮询,而主动轮询对于IO操作和业务操作都没有实际的意义,因此CPU计算资源浪费最严重。
在单个用户连接的频繁IO操作中,性能排名有好到差为:AIO>基本阻塞IO>信号IO>epoll>poll>select>基本非阻塞IO。
在少量用户下的频繁IO操作中,基本阻塞IO一般要使用多线程操作,因此要产生额外的线程调度工作。虽然由于线程较少,远少于系统的总进程数,但是由于IO操作频繁,CPU切换还是会集中在IO操作的各个线程内。
对于基本阻塞IO和多路复用IO来讲,虽然多路IO复用一次系统调用可以完成更多的IO操作,但是在IO操作完成后对于每个IO操作还是要系统调用将内核中的数据取回到用户缓存中,因此系统调用次数仍然比阻塞IO略多,但线程切换的开销更大。特别对于select来说,由于select内部采用半轮询方式,效率不如阻塞方式,因此在这种少量用户连接的IO场景下,还不能只通过理论判断基本阻塞IO和select方式孰优孰劣。
其他的IO模型类似于单用户下,不再分析,由此得出在少量用户连接IO操作下的IO模型性能,由好到坏依次为AIO>信号IO>epoll>基本阻塞IO?poll>select>基本非阻塞IO。
在大量,甚至海量用户的并发频繁IO操作下,多路IO复用技术的性能会全面超越简单的多线程阻塞IO,因为这时大量的CPU切换操作将显著减少CPU效率,而多路复用一次完成大量的IO操作的优势更加明显。对于AIO和信号IO,在这种场景下依然有着更少的IO等待和更少的系统调用操作,性能依然最好。
由此可见,在大量用户的并发频繁IO操作下,IO性能由好到差依次为AIO>信号IO>epoll>poll>select>基本阻塞IO>基本非阻塞IO。
https://mp.weixin.qq.com/s?__biz=MzI4NTEzMjc5Mw==&mid=2650554708&idx=1&sn=4fa4e599c5028825fda5ead907ec86a6&chksm=f3f833c2c48fbad49fda347833f14f553f764fc0e46ae71073d0b31028f7ec4f85b60d448e9a#rd
Linux IO 概念(2)的更多相关文章
- Linux IO 概念(2)【转】
转自:https://www.cnblogs.com/qq289736032/p/9188455.html 在上一篇IO底层的概念中杂合了很多模糊的概念,受知识水平的限制,只是从网上抄了很多过来.从l ...
- Linux IO 概念(1)
基础概念 文件描述fd 文件描述符(file description),用于表述指向文件引用的抽象话题概念 文件描述符在形式上是一个非负整数,实际上它是一个索引值,指向内核为每一个进程所维护的该进程打 ...
- 【知乎网】Linux IO 多路复用 是什么意思?
提问一: Linux IO多路复用有 epoll, poll, select,知道epoll性能比其他几者要好.也在网上查了一下这几者的区别,表示没有弄明白. IO多路复用是什么意思,在实际的应用中是 ...
- Linux IO模型和网络编程模型
术语概念描述: IO有内存IO.网络IO和磁盘IO三种,通常我们说的IO指的是后两者. 阻塞和非阻塞,是函数/方法的实现方式,即在数据就绪之前是立刻返回还是等待. 以文件IO为例,一个IO读过程是文件 ...
- linux io的cfq代码理解
内核版本: 3.10内核. CFQ,即Completely Fair Queueing绝对公平调度器,原理是基于时间片的角度去保证公平,其实如果一台设备既有单队列,又有多队列,既有快速的NVME,又有 ...
- I/O模型之二:Linux IO模式及 select、poll、epoll详解
目录: <I/O模型之一:Unix的五种I/O模型> <I/O模型之二:Linux IO模式及 select.poll.epoll详解> <I/O模型之三:两种高性能 I ...
- Linux磁盘概念及其管理工具fdisk
Linux磁盘概念及其管理工具fdisk [日期:2016-08-27] 来源:Linux社区 作者:chawan [字体:大 中 小] 引言:冯诺依曼体系中的数据存储器就是我们常说的磁盘或硬盘 ...
- 文档-linux io模式及select,poll,epoll
文档-Linux IO模式详解 1. 概念说明 在进行解释之前,首先要说明几个概念:- 用户空间和内核空间- 进程切换- 进程的阻塞- 文件描述符- 缓存 I/O 1.1 用户空间与内核空间 现在操作 ...
- 深入剖析Linux IO原理和几种零拷贝机制的实现
深入剖析Linux IO原理和几种零拷贝机制的实现 来源 https://zhuanlan.zhihu.com/p/83398714 零壹技术栈 公众号[零壹技术栈] 前言 零拷贝(Zero ...
随机推荐
- luoguP1829 [国家集训队]Crash的数字表格 / JZPTAB(莫比乌斯反演)
题意 注:默认\(n\leqslant m\). 所求即为:\(\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{m}lcm(i,j)\) 因为\(i*j=\gcd(i, ...
- Win10 Mactype 字体优化
1.下载安装 Mactype :http://www.mactype.net/ 2. 打开MacType Tray.exe,右键其在任务栏图标就能选择配置文件. 分享一个配置文件: [General] ...
- Java System.getProperty vs System.getenv
转自:https://www.baeldung.com/java-system-get-property-vs-system-getenv 1. Introduction The package ja ...
- 【HDU6327】Random Sequence(记忆化搜索)
点此看题面 大致题意: 给你两个序列\(a,v\),其中\(a\)数组由\(0\sim m\)组成.随机用\(1\sim m\)中的一个数替换\(a\)中的\(0\),求\(\sum_{i=1}^{n ...
- [LeetCode] 632. Smallest Range Covering Elements from K Lists 覆盖K个列表元素的最小区间
You have k lists of sorted integers in ascending order. Find the smallest range that includes at lea ...
- C# HTTP系列5 HttpWebResponse.StatusCode属性
系列目录 [已更新最新开发文章,点击查看详细] HttpWebResponse.StatusCode 属性获取响应的状态.对应 HttpStatusCode 枚举值之一. HttpStatus ...
- MySQL binlog三种模式
1.1 Row Level 行模式 日志中会记录每一行数据被修改的形式,然后在slave端再对相同的数据进行修改 优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文 ...
- 【阿里云IoT+YF3300】2.阿里云IoT云端通信Alink协议介绍
如果单单只有MQTT协议,也许很难支撑起阿里这个IoT大厦.Alink协议的出现,不仅仅是数据从传感端搬到云端,它就如基因图谱,它勾画了一个大厦的骨架,有了它,才有了IoT Studio,才有了大数据 ...
- docker搭建php环境
前言 本文根据参考文章,自己动手试了搭建PHP环境,对里面的Dockerfile的编写 做了最新的修改,以此记录,完整代码查看传送门 说明: 镜像下载过慢,可使用国内镜像加速,具体可自行查询 根据此方 ...
- python 根据文件的编码格式读取文件
因为各种文件的不同格式,导致导致文件打开失败,这时,我们可以先判断文件的编码吗格式,然后再根据文件的编码格式进行读取文件 举例:有一个data.txt文件,我们不知道它的编码格式,现在我们需要读取文件 ...