几种访问HDFS文件的客户端的总结
HDFS是英文Hadoop Distributed File System的缩写,中文翻译为Hadoop分布式文件系统,它是实现分布式存储的一个系统,所以分布式存储有的特点,HDFS都会有,HDFS的架构图:
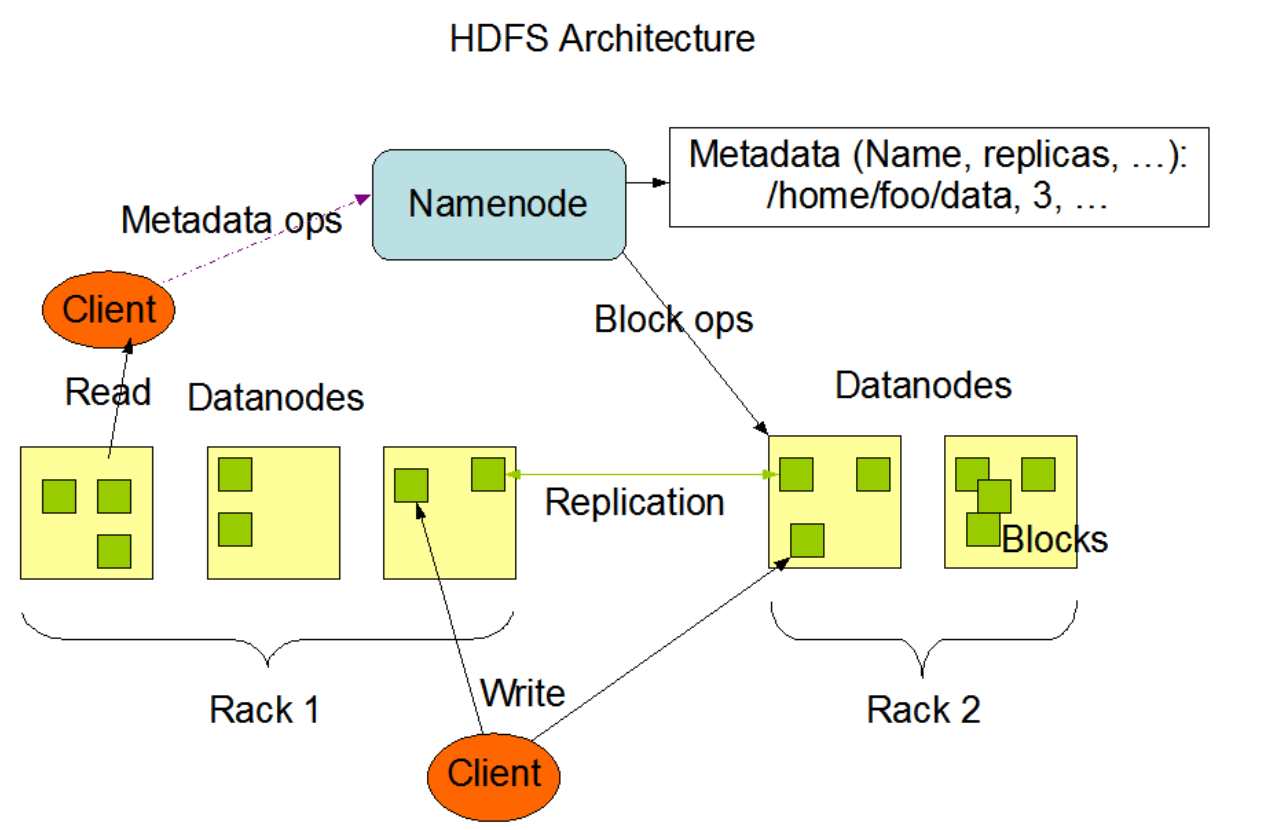
上图中HDFS的NameNode其实就是对应着分布式存储的Storage master,主要是用来存储元数据的,根据这些元数据就可以管理所有的机器节点和数据块
上图的Rack是机架的意思,也就是说机器可以放在不同的机架上
- 操作NameNode上的元数据
- 向DataNode上写数据
- 向DataNode上读数据
在安装HDFS的时候,除了NameNode和DataNode两个角色外,我们还发现有一个SecondaryNameNode,这个角色主要是为了提高NameNode的性能而存在的,我们后面会详细讲解
HDFS WEB UI

然后就会出现HDFS中的根目录下所有的文件:
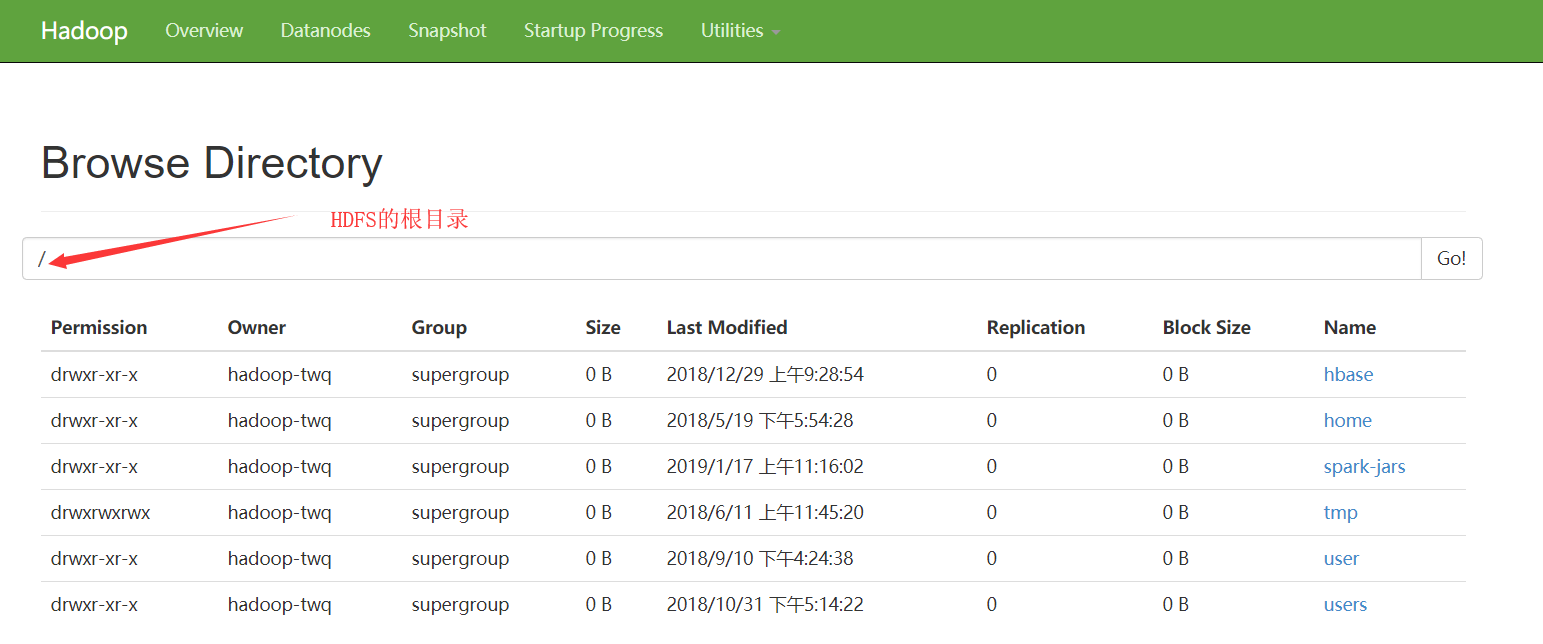
上面的方式是我们常见的访问HDFS文件的方式之一,这种使用的方式也是很方便的。

这篇文章,我们重点分别来详细看一下Overview、Datanodes以及Utilities三个模块
Overview

- 第1处的master:9999表示当前HDFS集群的基本路径。这个值是从配置core-site.xml中的fs.defaultFS获取到的。
- 第2处的Started表示集群启动的时间
- 第3处的Version表示我们使用的Hadoop的版本,我们使用的是2.7.5的Hadoop
- 第4处的Compiled表示Hadoop的安装包(hadoop-2.7.5.tar.gz)编译打包的时间,以及编译的作者等信息
- 第5处的Cluster ID表示当前HDFS集群的唯一ID
- 第6处的Block Pool ID表示当前HDFS的当前的NameNode的ID,我们知道通过HDFS Federation (联盟)的配置,我们可以为一个HDFS集群配置多个NameNode,每一个NameNode都会分配一个Block Pool ID
Summary
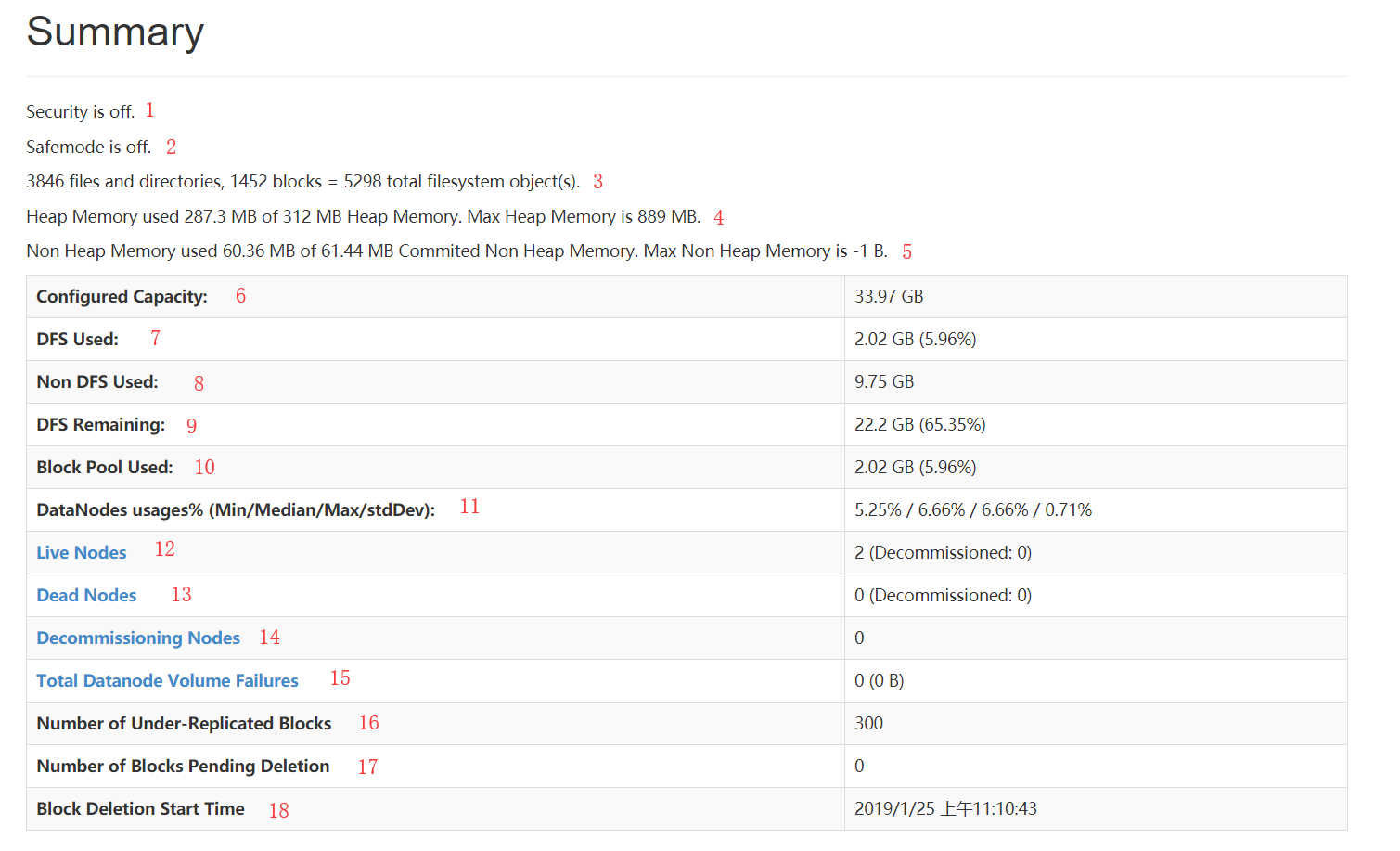
- 第1处的Security is off表示当前的HDFS集群没有启动安全机制
- 第2处的Safemode is off表示当前的HDFS集群不在安全模式,如果显示的是Safemode is on的话,则表示集群处于安全模式,那么这个时候的HDFS集群是不能用的
- 第3处表示当前HDFS集群包含了3846个文件或者目录,以及1452个数据块,那么在NameNode的内存中肯定有3846 + 1452 = 5298个文件系统的对象存在
- 第4处表示NameNode的堆内存(Heap Memory)是312MB,已经使用了287.3MB,堆内存最大为889MB,对
- 第5处表示NameNode的非堆内存的使用情况,有效的非堆内存是61.44MB,已经使用了60.36MB。没有限制最大的非堆内存,但是非堆内存加上堆内存不能大于虚拟机申请的最大内存(默认是1000M)
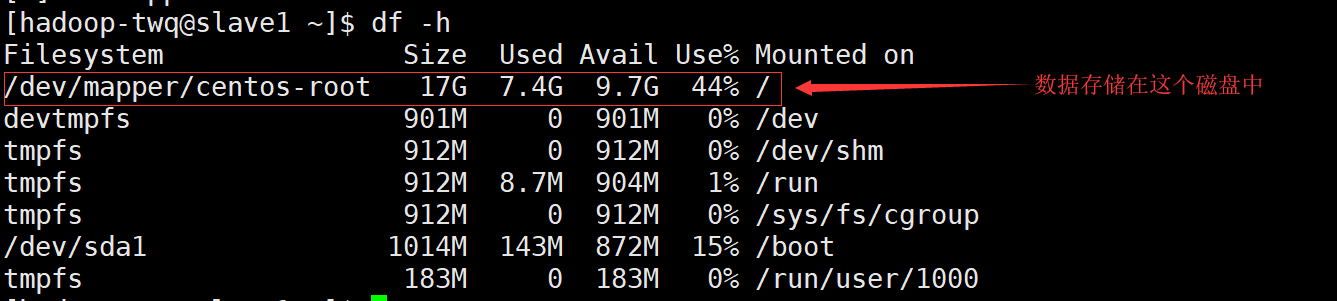
- 第6处的Configured Capacity表示当前HDFS集群的磁盘总容量。这个值是通过:Total Disk Space - Reserved Space计算出来的。Total Disk Space表示所在机器所在磁盘的总大小,而Reserved Space表示一个预留给操作系统层面操作的空间。Reserved space空间可以通过dfs.datanode.du.reserved(默认值是0)在hdfs-site.xml文件中进行配置。我们这边的总容量为什么是:33.97GB呢,我们可以通过du -h看一下两个slave的磁盘使用情况,如下:
- 第7处DFS Used表示HDFS已经使用的磁盘容量,说白了就是HDFS文件系统上文件的总大小(包含了每一个数据块的副本的大小)
- 第8处Non DFS Used表示在任何DataNodes节点上,不在配置的dfs.datanode.data.dir里面的数据所占的磁盘容量。其实就是非HDFS文件占用的磁盘容量
配置dfs.datanode.data.dir就是DataNode数据存储的文件目录
- 第9处DFS Remaining = Configured Capacity - DFS Used - Non DFS Used。这是HDFS上实际可以使用的总容量
- 第10处Block Pool Used表示当前的Block Pool使用的磁盘容量
- 第11处DataNodes usages%表示所有的DataNode的磁盘使用情况(最小/平均/最大/方差)
- 第12处Live Nodes表示存活的DataNode的数量。Decommissioned表示已经下线的DataNode
- 第13处Dead Nodes表示已经死了的DataNode的数量。Decommissioned表示已经下线的DataNode
- 第14处Decommissioning Nodes表示正在下线的DataNode的数量。
- 第15处Total Datanode Volume Failures表示DataNode上数据块的损坏大小
- 第16处Number of Under-Replicated Blocks表示没有达到备份数要求的数据块的数量
- 第17处Number of Blocks Pending Deletion表示正要被删除的数据块
- 第18处Block Deletion Start Time表示可以删除数据块的时间。这个值等于集群启动的时间加上配置dfs.namenode.startup.delay.block.deletion.sec的时间,其中配置dfs.namenode.startup.delay.block.deletion.sec默认是0秒
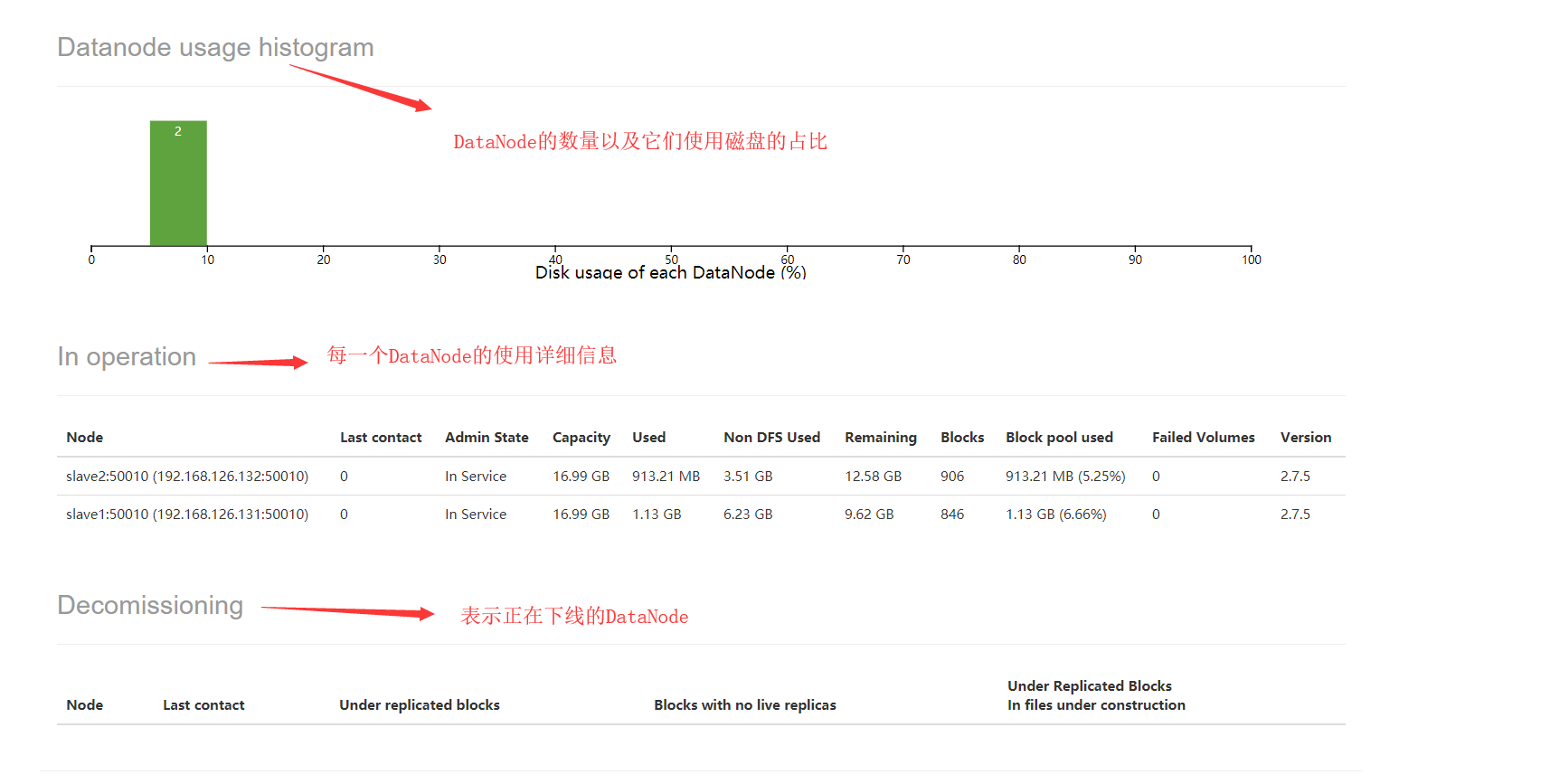
上面有一个Admin State我们有必要说明下,Admin State可以取如下的值:
- In Service,表示这个DataNode正常
- Decommission In Progress,表示这个DataNode正在下线
- Decommissioned,表示这个DataNode已经下线
- Entering Maintenance,表示这个DataNode正进入维护状态
- In Maintenance,表示这个DataNode已经在维护状态

我们这里详细总结下Browse the file system,对于Logs我们在HDFS日志的查看总结中讲解
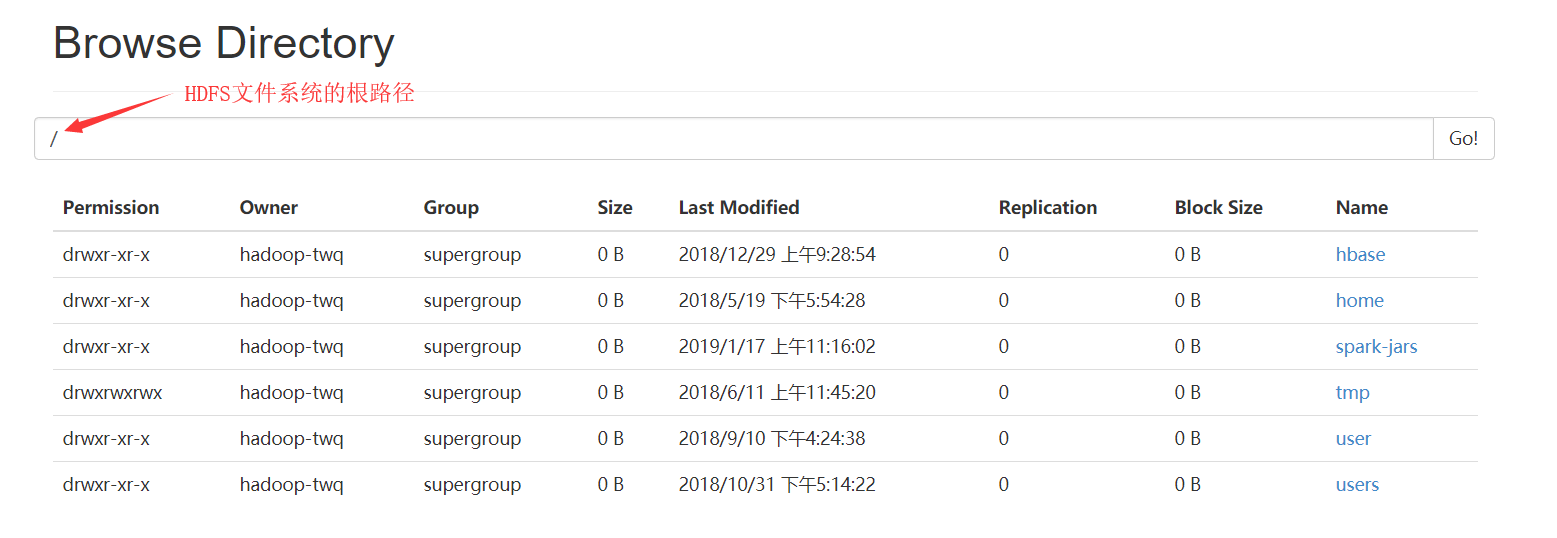
- Permission:表示该文件或者目录的权限,和Linux的文件权限规则是一样的
- Owner:表示该文件或者目录的所有者
- Group:表示该文件或者目录的所有者属于的组
- Size:表示该文件或者目录的大小,如果是目录的话则一直显示0B
- Last Modified:表示该文件或者目录的最后修改时间
- Replication:表示该文件或者目录的备份数,如果是目录的话则一直显示0
- Block Size:表示该文件的数据块的大小,如果是目录的话则一直显示0B
- Name:表示文件或者目录的名字
HDFS Shell命令HDFS提供了和Linux类似的命令来访问文件系统,比如在Linux中想看下文件目录/home/hadoop-twq/test中有哪些文件,我们可以执行:ls /home/hadoop-twq/test
那么在HDFS中也存在ls命令查看某个文件目录中有哪些文件,比如:hadoop fs -ls hdfs://master:9999/user/hadoop-twq/test
当然,我们也可以将hdfs://master:9999去掉,如下:hadoop fs -ls /user/hadoop-twq/test
那为什么可以去掉呢?因为当我们执行hadoop fs的命令的时候,程序会自动去Hadoop的配置core-site.xml中读取配置fs.defaultFS的值## hdfs dfs效果和hadoop fs的效果是一模一样的
hdfs dfs -ls hdfs://master:9999/user/hadoop-twq/test
Hadoop官网的 https://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/FileSystemShell.htmlHDFS文件恢复机制有一个命令我们得特别强调下,那么就是rm的命令,HDFS中的rm命令是删除文件的意思,但是用这个命令删除文件的时候并不是真正的删除,而是将文件放到对应的Trash目录中(其实和window电脑的回收站是一样的意思),但是这个Trash机制默认不是打开的,我们需要在core-site.xml中打开如下的配置:<!--单位是:分钟。默认值是0,表示禁用Trash机制-->
<!--下面的意思是保存删除的文件在.Trash文件目录中5分钟-->
<property>
<name>fs.trash.interval</name>
<value>5</value>
</property>
那么在一个HDFS文件被删除后,5分钟之内还是可以从Trash目录中恢复出来的。比如,我们删除一个文件:hadoop fs -rm -r /user/hadoop-twq/cmd-那么上面删除的文件就会move到文件目录hdfs://master:9999/user/hadoop-twq/.Trash/180326230000/user/hadoop-twq/下,保存5分钟,在5分钟之内我们都可以通过下如的命令进行数据的恢复:adoop fs -cp hdfs://master:9999/user/hadoop-twq/.Trash/180326230000/user/hadoop-twq/* /user/hadoop-twq如果我们确定直接删除文件,并不需要进行保存的话,我们可以选择不保存文件到Trash目录下:hadoop fs -rm -r -skipTrash /user/hadoop-twq/cmd-20180326
Http方式访问HDFS在使用Http访问HDFS之前,我们需要打开webhdfs,可以通过如下的配置打开:<!--打开NameNode和DataNode的 WebHDFS (REST API)-->
<!-- 这个参数默认是ture,即默认WebHDFS是打开的-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
然后,我们可以在Linux上使用命令curl通过http url的方式访问HDFS文件,比如:curl -i "http://master:50070/webhdfs/v1/user/hadoop-twq/cmd/error.txt?op=LISTSTATUS"
返回的是一个Json,如下:HTTP/1.1200 OK
Cache-Control: no-cache
Expires: Sun,27 Jan 201901:03:02 GMT
Date: Sun,27 Jan 201901:03:02 GMT
Pragma: no-cache
Expires: Sun,27 Jan 201901:03:02 GMT
Date: Sun,27 Jan 201901:03:02 GMT
Pragma: no-cache
Content-Type: application/json
Transfer-Encoding: chunked
Server:Jetty(6.1.26) {
"FileStatuses":
{"FileStatus":
[
{
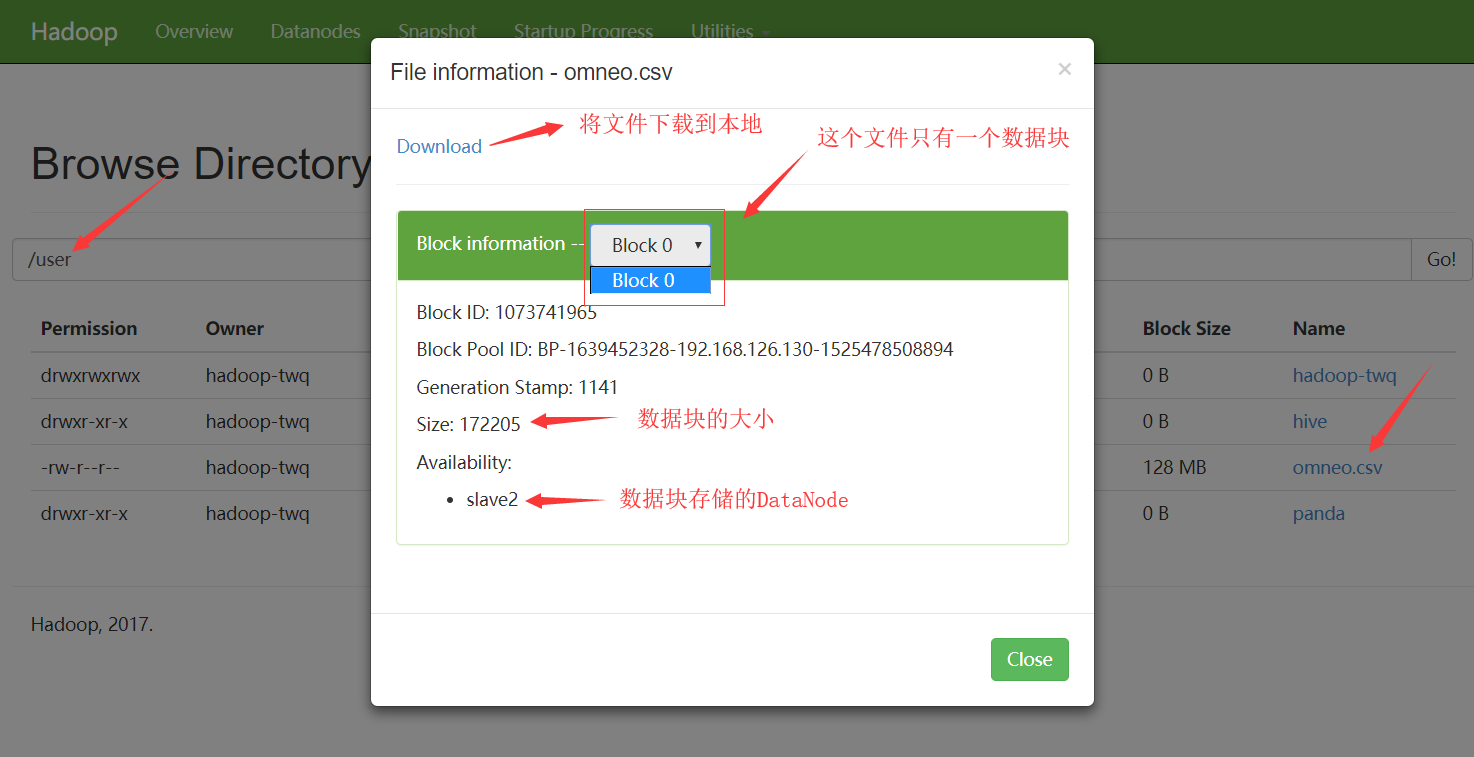
"accessTime":1543310078655, ## 表示访问时间
"blockSize":134217728, ## 表示设置的数据块的大小(这里是128M)
"childrenNum":0, ## 表示含有多少个子文件
"fileId":36514, ## 唯一ID
"group":"supergroup", ## 文件所属组
"length":0, ## 文件的大小
"modificationTime":1543310078685, ## 文件修改时间
"owner":"hadoop-twq", ## 文件所有者
"pathSuffix":"", ## 路径后缀
"permission":"644", ## 文件权限
"replication":1, ## 文件对应的数据块的备份数
"storagePolicy":0, ## 存储策略
"type":"FILE" ## 类型,这里是文件
}
]
}
}
几种访问HDFS文件的客户端的总结的更多相关文章
- Structure Streaming和spark streaming原生API访问HDFS文件数据对比
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. Structure Stream访问方式 code examples import org.apache.sp ...
- day07 eclipse使用本地 库文件 访问HDFS
常用命令 1. hdfs dfsadmin -report 查看系统的各台机器状态 HDFS的概念和特性 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件 其次,它是分 ...
- 利用JavaAPI访问HDFS的文件
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content) 一.Hadoop客户端配置 二.Java访问HDFS集群 2.1.HDFS的Java访问接口 2.2.Java访问HDFS主要编程步骤 2.3.使用FileSystem A ...
- hadoop 小文件 挂载 小文件对NameNode的内存消耗 HDFS小文件解决方案 客户端 自身机制 HDFS把块默认复制3次至3个不同节点。
hadoop不支持传统文件系统的挂载,使得流式数据装进hadoop变得复杂. hadoo中,文件只是目录项存在:在文件关闭前,其长度一直显示为0:如果在一段时间内将数据写到文件却没有将其关闭,则若网络 ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- hue上配置HA的hdfs文件(注意,HA集群必须这样来配置才能访问hdfs文件系统)
按照正常方式配置,发现无论如何也访问不了hdfs文件系统,因为我们是HA的集群,所以不能按照如下配置 将其改为 除此之外,还需要配置hdfs文件的 接着要去hadoop的目录下启动httpfs.sh ...
- python文件打开的几种访问模式
文件打开的几种访问模式 访问模式 说明 r 以只读方式打开文件.文件的指针将会放在文件的开头.这是默认模式. w 打开一个文件只用于写入.如果该文件已存在则将其覆盖.如果该文件不存在,创建新文件. a ...
- 访问hdfs里的文件
准备工作: 给hdfs里上传一份用于测试的文件 [root@master ~]# cat hello.txt hello 1 hello 2 hello 3 hello 4 [root@master ...
随机推荐
- bolt继承关系和区别
先上个图: 具体区别: IRichBolt/IBasicBolt 区别IRichBolt和IBasicBolt IRichBolt继承自IBolt和IComponent.IBasicBolt继承自I ...
- mke2fs和mkfs命令使用
1.mke2fs命令 在Linux系统下,mke2fs命令可用于创建磁盘分区上的”ext2/ext3”文件系统. (1)语法 mke2fs(选项)(参数) (2)常用选项 -b<区块大小> ...
- mybatis:updatebyexample与updateByExampleSelective
MyBatis,通常逆向工程工具生成接口和xml映射文件用于简单的单表操作. 有两个方法: updateByExample 和 updateByExampleSelective ,作用是对数据库进行 ...
- Mysql常见注意事项小记
1. 排序问题 正常如果按照某字段升序排列,空值会排到有值的前面;如果逆序排序空值排在最后. 有时候我们需要该字段为空的行数据要排到最后面去,这时只需要: order by second_parent ...
- Effective.Java第45-55条(规范相关)
45. 明智谨慎地使用Stream 46. 优先考虑流中无副作用的函数 47. 优先使用Collection而不是Stream作为方法的返回类型 48. 谨慎使用流并行 49. 检查参数有效 ...
- Codeforces Round #557 (Div. 1) 简要题解
Codeforces Round #557 (Div. 1) 简要题解 codeforces A. Hide and Seek 枚举起始位置\(a\),如果\(a\)未在序列中出现,则对答案有\(2\ ...
- 「NOI2015」小园丁与老司机
「NOI2015」小园丁与老司机 要不是这道码农题,去年就补完了NOI2015,其实两问都比较simple,但是写起来很恶心. 先解决第一问,记 \(dp[i]\) 表示老司机到达第 \(i\) 棵树 ...
- 关于MVC与三层架构
详情 回答一: 当然啊,你要明白三层架构的MVC的区别和联系: 三层架构是最基本的项目分层结果,而MVC则是三层架构的一个变体,MVC是一种好的开发模式.首先你要明白MVC分别代表的是什么意思. M ...
- 使用SqlConnectionStringBuilder构造数据库连接字符串
在实际开发过程中,很多时候会拷贝一个现有的数据库连接字符串,修改对应的数据库名.用户名.密码等配置成新的数据库连接字符串.但是有时候我们需要增加一些额外的配置,比如超时时间,最大连接池等,此时我们可以 ...
- Spring AOP 复习
Aspect Oriented Programming 通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术,利用aop可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降 ...