DataPipeline数据融合重磅功能丨一对多实时分发、批量读取模式

为能更好地服务用户,DataPipeline最新版本支持:
1. 一个数据源数据同时分发(实时或定时)到多个目的地;
2. 提升Hive的使用场景:
写入Hive目的地时,支持选择任意目标表字段作为分区字段;
可将Hive作为数据源定时分发到多个目的地。
3. 定时同步关系型数据库数据时,可自定义读取策略来满足各个表的同步增量需求。
本篇将首先介绍一下一对多数据分发及批量读取模式2.0的功能,后续功能会在官微陆续发布。
一、推出「一对多数据分发」的背景
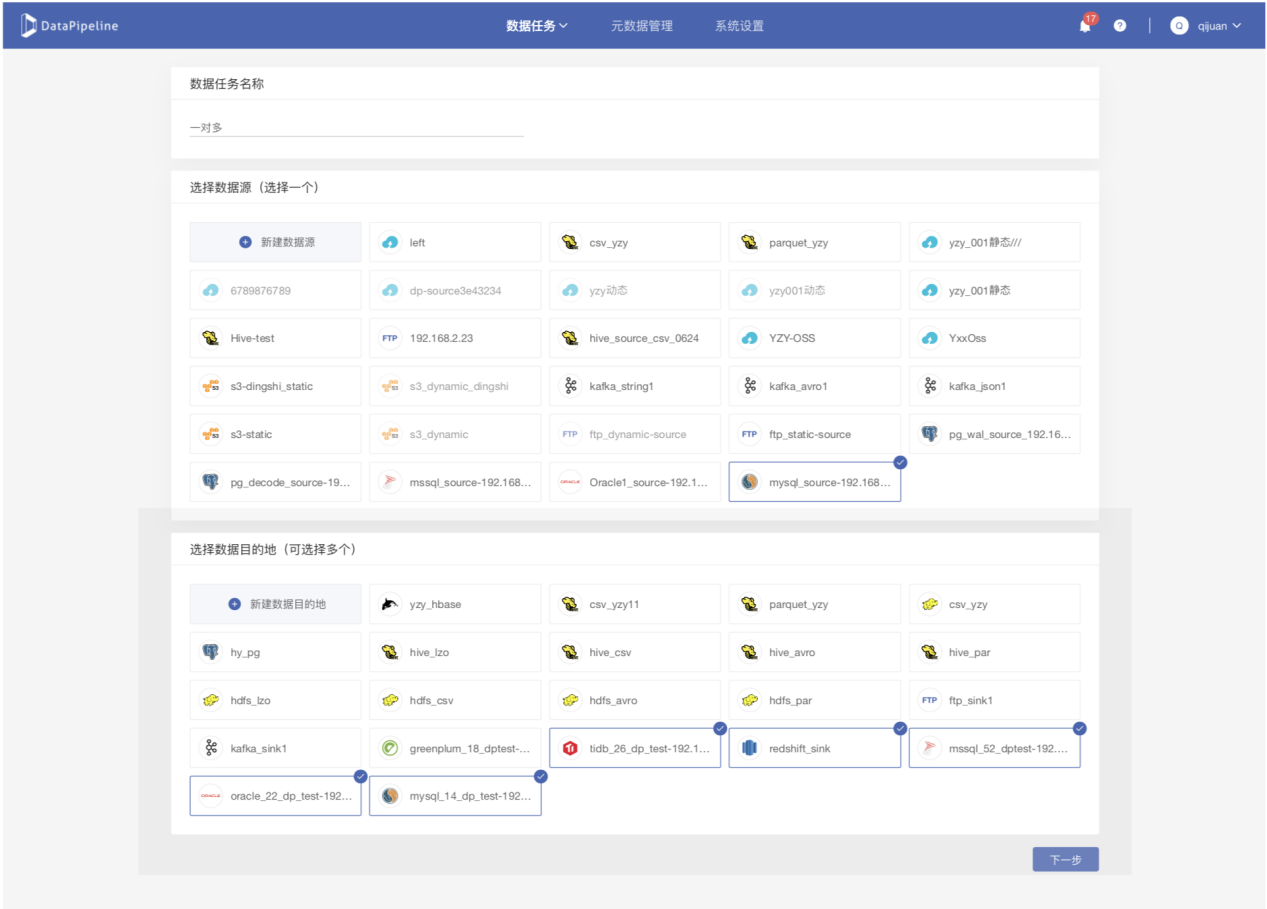
在历史版本中,DataPipeline每个任务只允许有一个数据源和目的地,从数据源读取的数据只允许写入到一张目标表。这会导致无法完美地支持客户的两个需求场景:
需求场景一:
客户从一个API数据源或者从KafkaTopic获取JSON数据后,通过高级清洗解析写入到目的地多个表或者多个数据库中,但历史版本无法同时写入到多个目的地,只能创建多个任务。这会导致数据源端会重复获取同一批数据(而且无法完全保证数据一致性),浪费资源,并且无法统一管理。
需求场景二:
客户希望创建一个数据任务,并从一个关系型数据库表实时(或定时)分发到多个数据目的地。在历史版本中,用户需要创建多个任务来解决,但创建多个任务执行该需求时会重复读取数据源同一张表的数据,比较浪费资源。客户更希望只读取一次便可直接解析为多个表,完成该需求场景。
新功能解决的问题:
1. 用户在一个数据任务中选择一个数据源后,允许选择多个目的地或者多个表作为写入对象,而不需要创建多个任务来实现该需求。
2. 用户在单个任务中针对每个目的地的类型和特性,可以单独设置各个目的地表结构和写入策略,大大减少了数据源读取次数和管理成本。
二、扩展Hive相关使用场景
历史版本中,DataPipeline支持各类型数据源数据同步到Hive目的地的需求场景。但由于每个客户的Hive使用方式、数据存储方式不同,两个需求场景在历史版本中并没有得到支持。
需求场景一:
动态分区字段。历史版本中,用户只允许选择时间类型字段作为分区字段。在真实的客户场景中除了按照时间做分区策略外,客户希望指定Hive表任意字段作为分区字段。
需求场景二:
客户希望除了以Hive作为目的地,定时写入数据到Hive外,客户还希望使用DataPipeline可以定时分发Hive表数据到各个应用系统,解决业务需求。
新功能解决的问题:
1. 允许用户指定目的地Hive表中任何字段作为分区字段,并支持选择多个分区字段。
2. 新增Hive数据源,可作为数据任务读取对象。
三、推出「批量读取模式2.0功能」的背景
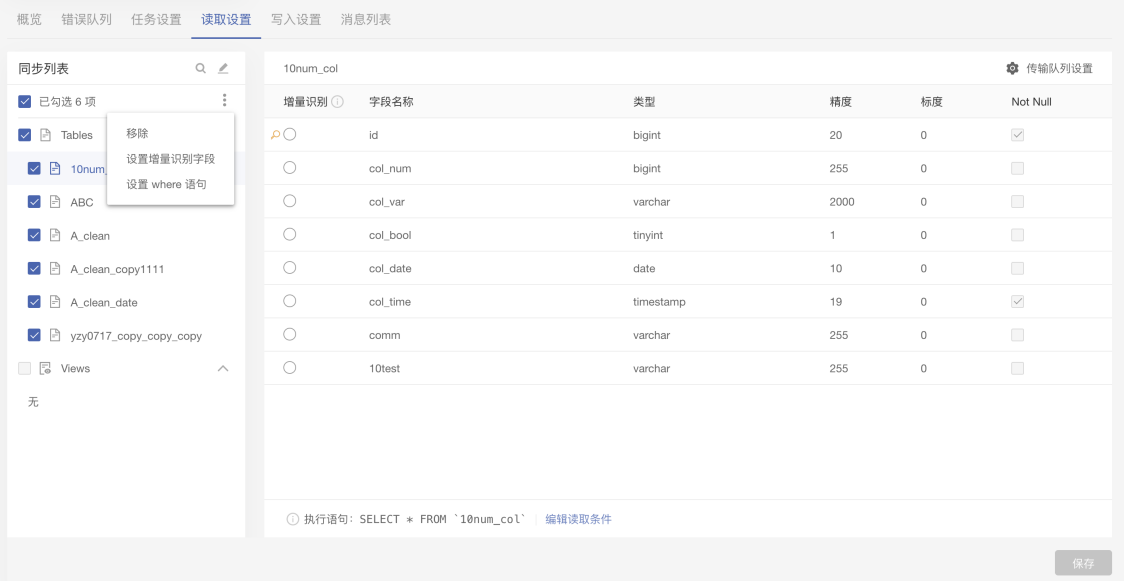
需求场景:
关系型数据库(以MySQL为例)的表没有权限读取BINLOG,但在业务上客户需要定期同步增量数据,在权限只有SELECT情况下,需要做到增量数据的同步任务。
新版本出现之前,DataPipeline在用户选择批量读取模式时提供了增量识别字段的功能,可以选择自增字段或者更新时间字段作为条件完成增量数据的同步,但部分表可能没有这种类型的字段,或者增量同步的逻辑不通(比如:只同步过去1小时的数据,或只同步到5分钟前的数据等)。
新功能解决的问题:
1. 在关系型数据库作为数据源的情况下,允许用户针对每一个表设置WHERE读取条件,并提供lastmax方法。
2. 使用该函数DataPipeline会取该任务下已同步数据中某一个字段的最大值,用户可以使用该值作为WHERE语句读取条件。
3. 用户使用last_max()函数,在首次执行该语句或对应字段暂无数值时,则会忽略该函数相关的读取条件。
4. 允许用户结合其他数据库提供的方法编辑读取条件:
例:以时间字段作为读取条件,每次只同步一小时前的数据,且只同步未曾读取的数据。
SELECT * FROMtable1 WHEREupdate_time > 'last_max(update_time)' ANDupdate_time<= DATE_SUB(NOW(), INTERVAL 24 HOUR)
相较于之前的一对一设置,新版本上线后用户可以通过批量设置增量识别字段、批量移除、批量修改表名称等,批量地操作一些表,批量地做一些动态修改,减少用户配置成本。例如,现在需要在200张表的名称后面都加一个data_warehouse,不同于以往的逐一添加,现在可以批量添加这些前缀后缀。
DataPipeline每一次版本的迭代都凝聚了团队对企业数据使用需求的深入思索,其它新功能还在路上,很快就会跟大家见面了,希望能够切实帮助大家更敏捷高效地获取数据。
DataPipeline数据融合重磅功能丨一对多实时分发、批量读取模式的更多相关文章
- 最新2.7版本丨DataPipeline数据融合产品最新版本发布
此次发布的2.7版本在进一步优化产品底层数据处理逻辑的同时更加注重提升用户在数据融合任务的日常管理.运行监控及资源分配等管理方面的功能增强与优化,力求帮助大家更为直观.便捷.稳定地管理数据融合任务,提 ...
- Atitit 数据融合merge功能v3新特性.docx
Atitit 数据融合merge功能v3新特性.docx 1.1. 版本历史1 1.2. 生成sql结果1 1.3. 使用范例1 1.4. 核心代码1 1.1. 版本历史 V2增加了replace部分 ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- DataPipeline丨新型企业数据融合平台的探索与实践
文 |刘瀚林 DataPipeline后端研发负责人 交流微信 | datapipeline2018 一.关于数据融合和企业数据融合平台 数据融合是把不同来源.格式.特点性质的数据在逻辑上或物理上有机 ...
- Tapdata 实时数据融合平台解决方案(五):落地
作者介绍:TJ,唐建法,Tapdata 钛铂数据 CTO,MongoDB中文社区主席,原MongoDB大中华区首席架构师,极客时间MongoDB视频课程讲师. 通过前面几篇文章,我们从企业数据整合与分 ...
- SLAM+语音机器人DIY系列:(三)感知与大脑——2.带自校准九轴数据融合IMU惯性传感器
摘要 在我的想象中机器人首先应该能自由的走来走去,然后应该能流利的与主人对话.朝着这个理想,我准备设计一个能自由行走,并且可以与人语音对话的机器人.实现的关键是让机器人能通过传感器感知周围环境,并通过 ...
- 数据融合(data fusion)原理与方法
数据融合(data fusion)原理与方法 数据融合(data fusion)最早被应用于军事领域. 现在数据融合的主要应用领域有:多源影像复合.机器人和智能仪器系统.战场和无人驾驶飞机.图 ...
- Tapdata 实时数据融合平台解决方案(四):技术选型
作者介绍:TJ,唐建法,Tapdata 钛铂数据CTO,MongoDB中文社区主席,原MongoDB大中华区首席架构师,极客时间MongoDB视频课程讲师. 常见搭建数据中台的技术产品 数据中台包括: ...
- MVC5 网站开发之三 数据存储层功能实现
数据存储层在项目Ninesky.DataLibrary中实现,整个项目只有一个类Repository. 目录 奔跑吧,代码小哥! MVC5网站开发之一 总体概述 MVC5 网站开发之二 创建项目 ...
随机推荐
- PAC、KNN和GridSearchCV
PCA PCA主要是用来数据降维,将高纬度的特征映射到低维度,具体可学习线性代数. 这里,我们使用sklearn中的PCA. from sklearn.decomposition import PCA ...
- Scrapy笔记08- 文件与图片
Scrapy笔记08- 文件与图片 Scrapy为我们提供了可重用的item pipelines为某个特定的Item去下载文件. 通常来说你会选择使用Files Pipeline或Images Pip ...
- 链接指示:extren"C"
C++程序有时需要调用其他语言编写的函数,最常见的是调用C语言编写的函数.像所有其他名字一样,其他语言中的函数名字也必须在C++中进行声明,并且该声明必须指定返回类型和形参列表.对于其他语言编写的函数 ...
- luogu p2622关灯问题II
luogu p2622关灯问题II 题目描述 现有n盏灯,以及m个按钮.每个按钮可以同时控制这n盏灯--按下了第i个按钮,对于所有的灯都有一个效果.按下i按钮对于第j盏灯,是下面3中效果之一:如果a[ ...
- 讲课专用——线段树——BSS
题目链接:http://codevs.cn/problem/3981/ 题解: 线段树求GSS模板题 一.一段长的区间的 GSS 有三种情况:>1 完全在左子区间>2 完全在右子区间> ...
- 【树状数组】【P3372】 【模板】线段树 1
Description 给定一个长度为 \(n\) 的序列,有 \(m\) 次操作,要求支持区间加和区间求和. Limitation \(1 \leq n,~m \leq 10^5\) 序列元素值域始 ...
- git中ignore文件配置
在项目中我们有一些文件是不能公开的,或者说是每个人需要单独配置的,那么这个时候使用 git 就不能上传这些文件.此时就需要对 .gitignore 文件进行配置. git 的忽略原则:参考 廖雪峰的g ...
- Python(三)对装饰器的理解
装饰器是 Python 的一个重要部分,也是比较难理解和使用好的部分.下面对装饰器做一下简单整理 1. 前言 装饰器实际上是应用了设计模式里,装饰器模式的思想: 在不概念原有结构的情况下,添加新的功能 ...
- 注意:MagickReadImageBlob() 引发的问题
今天发现: 如果之前的 mw 已加载了具体的图片数据后,再对这个 mw 进行: MagickReadImageBlob(mw, data, dataLen) 程序运行发生了崩溃. 最后找到原因: Ma ...
- CentOS安装Hadoop
Hadoop的核心由3个部分组成: HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode.SecondaryNameNode ...