mysql 为啥用b+ 树
原因就是为了减少磁盘io次数,因为b+树所有最终的子节点都能在叶子节点里找见,
所以非叶子节点只需要存`索引范围和指向下一级索引(或者叶子节点)的地址` 就行了,
不需要存整行的数据,所以占用空间非常小,直到找到叶子节点才加载进来整行的数据。
B树非叶子节点也会存数据,所以不适合mysql(以后研究下mongo为啥用b树 再补充)
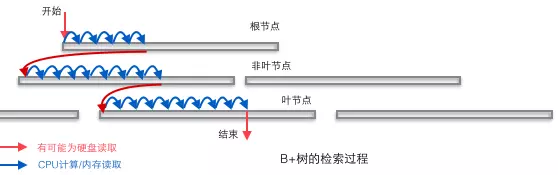
B+树适合作为数据库的基础结构,完全是因为计算机的内存-机械硬盘两层存储结构。内存可以完成快速的随机访问(随机访问即给出任意一个地址,要求返回这个地址存储的数据)但是容量较小。而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。

真实数据库中的B+树应该是非常扁平的,可以通过向表中顺序插入足够数据的方式来验证InnoDB中的B+树到底有多扁平。我们通过如下图的CREATE语句建立一个只有简单字段的测试表,然后不断添加数据来填充这个表。通过下图的统计数据(来源见参考文献1)可以分析出几个直观的结论,这几个结论宏观的展现了数据库里B+树的尺度。
1 每个叶子节点存储了468行数据,每个非叶子节点存储了大约1200个键值,这是一棵平衡的1200路搜索树!
2 对于一个22.1G容量的表,也只需要高度为3的B+树就能存储了,这个容量大概能满足很多应用的需要了。如果把高度增大到4,则B+树的存储容量立刻增大到25.9T之巨!
3 对于一个22.1G容量的表,B+树的高度是3,如果要把非叶节点全部加载到内存也只需要少于18.8M的内存(如何得出的这个结论?因为对于高度为2的树,1203个叶子节点也只需要18.8M空间,而22.1G从良表的高度是3,非叶节点1204个。同时我们假设叶子节点的尺寸是大于非叶节点的,因为叶子节点存储了行数据而非叶节点只有键和少量数据。),只使用如此少的内存就可以保证只需要一次磁盘IO操作就检索出所需的数据,效率是非常之高的。


mysql 为啥用b+ 树的更多相关文章
- 从MongoDB及mysql 谈B/B+树
一 B树的由来 B树指的是一类树,包括B-树,B+树,B*树等,是一种自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B树允许每个节点有更多的子节点.B树是专门为外部存储器设计的,如磁盘,它对于读 ...
- 为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生 在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查 ...
- 为什么MySQL索引使用B+树
为什么MySQL索引使用B+树 聚簇索引与非聚簇索引 不同的存储引擎,数据文件和索引文件位置是不同的,但是都是在磁盘上而不是内存上,根据索引文件.数据文件是否放在一起而有了分类: 聚簇索引:数据文件和 ...
- MySQL 为什么使用 B+ 树来作索引?
什么是索引? 所谓的索引,就是帮助 MySQL 高效获取数据的排好序的数据结构.因此,根据索引的定义,构建索引其实就是数据排序的过程. 平时常见的索引数据结构有: 二叉树 红黑树 哈希表 B Tree ...
- MySQL索引之B+树
MySQL索引大都存储在B+树中,除此还有R树和hash索引.B+树的基础还是B树. B树由2部分组成,节点和索引.下面将构建一个B树,每个节点存2个数据,每个节点有前,中,后三个索引.插入数字的顺序 ...
- MySQL InnoDB引擎B+树索引简单整理说明
本文出处:http://www.cnblogs.com/wy123/p/7211742.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- 011-数据结构-树形结构-B+树[mysql应用]、B*树
一.B+树概述 B+树是B树的变种,有着比B树更高的查询效率. 一棵 B+ 树需要满足以下条件: 节点的子树数和关键字数相同(B 树是关键字数比子树数少一) 节点的关键字表示的是子树中的最大数,在子树 ...
- mysql为什么用b+树做索引
关键字就是key的意思 一.B-Tree的性质 1.定义任意非叶子结点最多只有M个儿子,且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点的儿子数为[M/2, M]: ...
- 2020-05-18:MYSQL为什么用B+树做索引结构?平时过程中怎么加的索引?
福哥答案2020-05-18:此答案来自群员:因为4.0成型那个年代,B树体系大量用于文件存储系统,甚至当年的Longhorn的winFS都是基于b树做索引,开源而且好用的也就这么个体系了.B+树的磁 ...
随机推荐
- Java项目部分总结
一.数据库sql操作: 1.三表查询的时候,最后的条件由于当前字段必须判断是属于哪个表,所以需要注明根据哪个表中的字段进行判断: 并且再在后面加上limit的时候,需要注意先进行添加,避免系统不能识别 ...
- jmeter学习笔记(二十二)——监听器插件之jp@gc系列
一.jp@gc - Actiive Threads Over Time 不同时间活动用户数量展示 下面是一个阶梯加压测试的图标 二.jp@gc - Transactions per Second ...
- java程序员常用的cmd命令
1.查看端口号或者进程号使用情况 1.1.查看所有端口占用情况 C:\Users\Administrator>netstat -ano 活动连接 协议 本地地址 (ip:端口) 外部地址 状态 ...
- gRPC应用C++
1. gRPC简述 RPC,远程方法调用,就是像调用本地方法一样调用远程方法. gRPC是Google实现的一种RPC框架,基于HTTP/2标准设计,带来诸如双向流.流控.头部压缩.单 TCP 连接 ...
- 【转】高性能网络编程7--tcp连接的内存使用
当服务器的并发TCP连接数以十万计时,我们就会对一个TCP连接在操作系统内核上消耗的内存多少感兴趣.socket编程方法提供了SO_SNDBUF.SO_RCVBUF这样的接口来设置连接的读写缓存,li ...
- Nginx基于域名的虚拟主机
一.基于域名的虚拟主机 修改配置文件/usr/local/nginx/conf/nginx.conf 创建新的虚拟主机的根目录和默认网页index.html 重新加载nginx的配置文件 查看两个虚拟 ...
- SQL进阶系列之7用SQL进行集合运算
写在前面 集合论是SQL语言的根基,因为这种特性,SQL也被称为面向集合语言 导入篇:集合运算的几个注意事项 注意事项1:SQL能操作具有重复行的集合(multiset.bag),可以通过可选项ALL ...
- P3375 模板 KMP字符串匹配
P3375 [模板]KMP字符串匹配 来一道模板题,直接上代码. #include <bits/stdc++.h> using namespace std; typedef long lo ...
- 【转】TUN/TAP虚拟网络设备
转: 原文:https://www.cnblogs.com/wyzhou/p/9286864.html ------------------------------------------------ ...
- drf序列化器与反序列化
什么是序列化与反序列化 """ 序列化:对象转换为字符串用于传输 反序列化:字符串转换为对象用于使用 """ drf序列化与反序列化 &qu ...