Ranger部署
一、Apache Ranger是什么?
Apache Ranger是一个框架,Hadoop上对于保护数据数据安全性的安全框架。用于在整个Hadoop平台上启用,监视和管理全面的数据安全性。
二、特性
Apache Ranger具有以下特性:
- 集中式安全管理,可在中央UI或使用REST API管理所有与安全相关的任务。
- 使用Hadoop组件/工具执行特定操作和/或操作的精细授权,并通过中央管理工具进行管理
- 跨所有Hadoop组件标准化授权方法。
- 增强了对不同授权方法的支持-基于角色的访问控制,基于属性的访问控制等。
- 在Hadoop的所有组件中集中审核用户访问和管理操作(与安全性相关)。
三、ranger内部结构
1、包含的组件如下:
- Ranger Admin 用户管理策略,提供WebUI和RestFul接口
- Ranger UserSync 用于将Unix系统或LDAP用户/组同步到RangerAdmin
- Ranger TagSync 同步Atlas中的Tag信息
- Ranger KMS
2、依赖的组件如下:
- JDK 运行RangerAdmin RangerKMS
- RDBMS 1.存储授权策略 2.存储Ranger 用户/组 3.存储审核日志
- Solr(可选) 存储审核日志
- HDFS(可选) 存储审核日志
- Kerberos(可选) 确保所有请求都被认证
3、当前2.1.0支持的组件如下:
- YARN
- HDFS
- SOLR
- KYLIN
- ATLAS
- OZONE
- HBASE
- KNOX
- KAFKA
- NIFI-REGISTRY
- ELASTICSEARCH
- HIVE
- STORM
- NIFI
- SQOOP
- PRESTO
4、处理流程如下:

四、安装
Ranger当前在GitHub中最新版本是2.1.0,从官网下载的源码包最新版本是2.0.0。安装ranger需要源码安装,官方没有提供编译好的二进制包,同时,对于要使用ranger部署的Hadoop组件,需要考虑到版本之间的兼容性。如下是我在做测试的时候,所使用的版本。
| ranger版本 | 2.1.0 |
| hadoop版本 | 2.9.2 |
| hbase版本 | 2.0.2 |
| hive版本 | 3.1.2 |
注:在测试的时候我使用hive2.x、hbase1.3和1.4都不能正常的使用,报错信息看后面ranger hive与ranger hbase相关的错误信息。
1、官网下载源码包
下载方式1:从GitHub下载,下载方式如下:
# git clone https://github.com/apache/ranger.git #默认下载最新版本,下载位置随意,例如:
/data1/hadoop/ranger/
或者
# git clone https://github.com/apache/incubator-ranger.git
注:下载需要使用到git命令,请自行安装。
如果是centos,可以使用
# yum install git -y
如果是ubuntu
# apt-get update
#apt-get install git -y
如果是内网机器,可以使用yum代理或者下载rpm包(centos)、dep包(Ubuntu)
下载方式2:从官网下载源码tar包
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/ranger/2.0.0/apache-ranger-2.0.0.tar.gz
2、下载maven
编译安装需要使用到maven,下载如下:
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.2/binaries/apache-maven-3.6.2-bin.tar.gz 解压
做软连接
#ln -s apache-maven-3.6.-bin maven 添加环境变量
# vim ~/.bashrc
export MAVEN_HOME=/data1/hadoop/maven
export PATH=${MAVEN_HOME}/bin:$PATH
3、编译安装
# cd ranger
# mvn clean compile package assembly:assembly install -DskipTests -Drat.skip=true
(安装过程漫长,需要等待!!!),注意:源码安装需要JDK环境 我这里使用的是从GitHub下载的源代码进行编译安装的,其他方式都一样的操作。
编译过程看网络,看机器,时间不定,基本来说需要20分钟以上,我第一次编译花了两个多小时。机器不咋地,使用的kvm虚拟机。
编译完成如下:

如果出现绿色的BUILD SUCCESS说明编译成功。
编译完成以后,在当前目录下的target目录下会生成相应的tar包文件,如下:
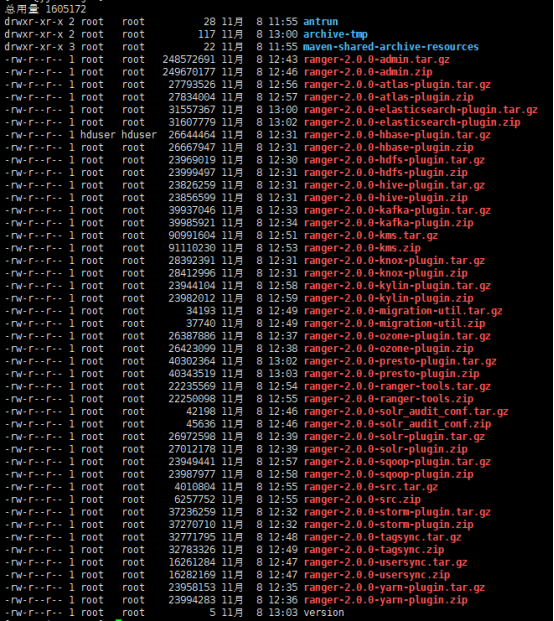
接下来就可以使用这些编译完成二进制tar文件。
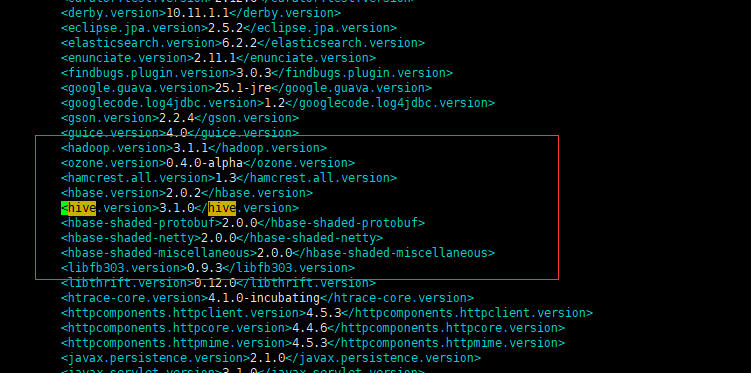
如果在编译安装的时候,需要对Hadoop、hbase、hive等相应的版本有要求,那么可以在下载的源代码目录下有一个pom.xml文件,这里面修改对于Hadoop组件的版本,我当初就是没有修改,导致后面在使用的时候,出现很多版本兼容性问题。
列如:我的安装目录
/data1/hadoop/ranger/ranger 第一个ranger是我自己创建的,第二个ranger是GitHub下载的时候自动生成的。
五、安装ranger-admin
安装ranger-admin的机器可以不在Hadoop集群内部,可以是随便一台。这里我就安装在当前机器上。
1、解压admin软件包
# tar zxvf ranger-2.1.-SNAPSHOT-admin.tar.gz -C /data/ranger
2、修改install.properties文件
注:ranger-admin依赖数据库,需要存储信息。安装数据库操作请自行百度。
# cd /data/ranger/ranger-2.1.-SNAPSHOT-admin
修改install.properties文件,需要修改的信息如下: (1)数据库配置:
- SQL_CONNECTOR_JAR=/usr/share/java/mysql-connector-java.jar #sql连接器,需要从官网下载,然后修改成该名字,当然也可以自己定义
- db_root_user=root #数据库用户名
db_host=localhost #数据库主机,如果不在一台机器,请修改
- db_root_password=***** #数据库密码
以下三个属性是用于设置ranger数据库的
db_name=ranger #数据库名字
db_user=root #管理数据库的用户
db_password=**** #密码
(2)、审计日志
如果没有安装solr,这里可以全部注释
audit_store=solr
audit_solr_urls=http://localhost:6083/solr/ranger_audits
audit_solr_user=solr
(3)、策略管理配置
policymgr_external_url=http://localhost:6080 #配置用户名和端口,如果不想使用默认值,可以修改。
这里需要注意:ranger在连接数据库的时候,对于密码强度要求很高,当然,这也是由于数据库的密码策略导致的,如果设置的密码不符合数据库的密码策略,那么ranger连接数据库会失败,同时,还需要在数据库里面赋予相应的权限。如下:
Mysql5.7数据库密码策略:大小写+数字+特殊字符+密码长度>8
create database ranger #创建数据库
grant all on *.* to ‘root’@’%’ identified by ‘your password’;
Flush privileges;
3、安装solr
solr用于存储审计信息,solr可以单独安装,可以安装单节点,也可以部署为集群,这里使用ranger自带的方式安装。
(1) 修改配置
在当前目录下的contrib/solr_for_audit_setup目录下,修改install.properties文件
完整目录如下:
[hduser@yjt solr_for_audit_setup]$ pwd
/data/ranger/ranger-2.1.0-SNAPSHOT-admin/contrib/solr_for_audit_setup
修改如下配置文件:
SOLR_INSTALL=true
JAVA_HOME=/data/jdk
SOLR_DOWNLOAD_URL=http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/8.3.0/solr-8.3.0.tgz #solr下载地址
SOLR_INSTALL_FOLDER=/data/solr #安装目录,这个随意
SOLR_RANGER_HOME=/data/solr/ranger_audit_server
SOLR_RANGER_PORT=6083 #默认端口
SOLR_DEPLOYMENT=standalone #部署模式(单节点部署),还有solrcloud(集群)模式
SOLR_RANGER_DATA_FOLDER=/data/solr/ranger_audit_server/data #数据存放目录
官方文档在配置的时候是配置的/data1/hadoop/ranger/ranger/security-admin/contrib/solr_for_audit_setup这个目录下的install.properties文件,也就是在源码的配置文件中修改。
(2) 初始化solr
在当前目录下执行setup.sh进行初始
#./setup.sh
4、初始化ranger-admin
# cd /data/ranger/ranger-2.1.-SNAPSHOT-admin
#./setup.sh
如果初始化ok,启动admin
如果执行的过程中报:
SQLException : SQL state: 42000 com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Access denied for user 'root'@'%' to database 'ranger' ErrorCode: 1044
连接数据库,执行:
UPDATE mysql.user SET Grant_priv='Y', Super_priv='Y' WHERE User='root';
5、启动ranger-admin
#ranger-admin start 或者 #./ews/ranger-admin-services.sh start 启动服务
Ranger的默认端口是6080,如果需要修改,请修改install.properties配置文件。
查看当前的端口信息:

浏览器连接测试:http://192.168.4.50:6080
登录界面用户名和密码为: admin/admin
登录进去以后界面如下:
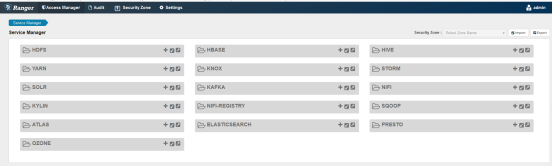
接下来,配置其他的比如策略等等就在这里面配置就可以了。
当然需要同步用户的话,还需要配置userSync或者ldap等等组件
借鉴:
https://www.jianshu.com/p/d9941b8687b7
Ranger部署的更多相关文章
- ranger部署文档(记)
目录 概览... 2 1. ranger-admin. 2 2. ranger-user-sync. 2 3. ranger-*-plugins. 2 安装... 3 1 ...
- Ranger安装部署 - solr安装
1. 概述 Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库: Solr是以Lucene为基础实现的文本检索应用服务.Solr部署方式有单机方式.多机Master-Slaver方法. ...
- Ranger安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Apache Ranger 编译安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Apache Ranger安装部署
1.概述 Apache Ranger提供了一个集中式的安全管理框架,用户可以通过操作Ranger Admin页面来配置各种策略,从而实现对Hadoop生成组件,比如HDFS.YARN.Hive.HBa ...
- openStack kilo 手动Manual部署随笔记录
一 ,基于neutron网络资源主机(控制节点,网络节点,计算节点)网络规划配置 1, controller.cc 节点 网络配置截图
- Ambari安装之部署本地库(镜像服务器)(二)
部署本地库(镜像服务器) (1)下载HortWorks官网上的3个库到本地(也可以在线下载,但是速度会很慢) 我们先把hortworks官网上需要下载的3个库下载到本地(这个还是需要很长时间的,当然你 ...
- Hadoop生态圈-单点登录框架之CAS(Central Authentication Service)部署
Hadoop生态圈-单点登录框架之CAS(Central Authentication Service)部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.CAS简介 CAS( ...
- Hadoop生态圈-Ranger数据安全管理框架
Hadoop生态圈-Ranger数据安全管理框架 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Ranger简介 Apache Ranger是一款被设计成全面掌握Hadoop生 ...
随机推荐
- 用cProfile做性能分析【转】
原文地址: https://www.cnblogs.com/kaituorensheng/p/4453953.html
- 2019-07-25 php错误级别及设置方法
在php的开发过程里,我们总是会有一系列的错误警告,这些错误警告在我们开发的过程中是十分需要的,因为它能够提示我们在哪里出现了错误,以便修改和维护.但在网站开发结束投入使用时,这些报错我们就要尽量避免 ...
- Matlab迭代器模式
迭代器(Iterator)模式,又叫做游标(Cursor)模式.提供一种方法访问一个容器(container)或者聚集(Aggregator)对象中各个元素,而又不需暴露该对象的内部细节.在采用不同的 ...
- Java 之 Session 包含验证码登录案例
需求: 1. 访问带有验证码的登录页面login.jsp 2. 用户输入用户名,密码以及验证码. 如果用户名和密码输入有误,跳转登录页面,提示:用户名或密码错误 如果验证码输入有误,跳转登录页面, ...
- 归并排序python实现源码
将开发过程经常用到的一些代码片段收藏起来,下面的资料是关于归并排序python实现的代码,应该能对码农们有一些用. def mergesort(arr): if len(arr) == 1: retu ...
- 大数据量高并发的数据库优化,sql查询优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- elasticsearch获取字段missing的数据
用head查询: demo如下 http://localhost:9200/sj_0505/lw_point_location/ _search post { "query": { ...
- redis 订阅者与发布者(命令行)
1.连接到redis ./bin/redis-cli -c -h 127.0.0.1 -p 6379 -a xxxxxxxx 2. 订阅管道 subscribe list1 订阅list1 3.发布 ...
- springboot通过idea打jar包
springboot打jar包 一. 检查pom文件 <packaging>jar</packaging> 二. 切换到maven窗口 三. 先c ...
- Linux命令——gdisk、fdisk、partprobe
gdisk.fdisk MBR分区表请使用fdisk分区,GPT分区表请使用gdisk分区 MBR与GPT区别参考:Linux磁盘管理——MBR 与 GPT gdisk.gdisk这两个命令参数不需要 ...