python实现余弦相似度文本比较
向量空间模型VSM:
VSM的介绍:
一个文档可以由文档中的一系列关键词组成,而VSM则是用这些关键词的向量组成一篇文档,其中的每个分量代表词项在文档中的相对重要性。
VSM的例子:
比如说,一个文档有分词和去停用词之后,有N个关键词(或许去重后就有M个关键词),文档关键词相应的表示为(d1,d2,d3,...,dn),而每个关键词都有一个对应的权重(w1,w1,...,wn)。对于一篇文档来说,或许所含的关键词项比较少,文档向量化后的向量维度可能不是很大。而对于多个文档(2篇文档或两篇文档以上),则需要合并所有文档的关键词(关键词不能重复),形成一个不重复的关键词集合,这个关键词集合的个数就是每个文档向量化后的向量的维度。打个比方说,总共有2篇文档A和B,其中A有5个不重复的关键词(a1,a2,a3,a4,a5),B有6个关键词(b1,b2,b3,b4,b5,b6),而且假设b1和a3重复,则可以形成一个简单的关键词集(a1,a2,a3,a4,a5,,b2,b3,b4,b5,b6),则A文档的向量可以表示为(ta1,ta2,ta3,ta4,ta5,0,0,0,0,0),B文档可以表示为(0,0,tb1,0,0,tb2,tb3,tb4,tb5,tb6),其中的tb表示的对应的词汇的权重。
最后,关键词的权重一般都是有TF-IDF来表示,这样的表示更加科学,更能反映出关键词在文档中的重要性,而如果仅仅是为数不大的文档进行比较并且关键词集也不是特别大,则可以采用词项的词频来表示其权重(这种表示方法其实不怎么科学)。
TF-IDF权重计算:
TF的由来:
以前在文档搜索的时候,我们只考虑词项在不在文档中,在就是1,不在就是0。其实这并不科学,因为那些出现了很多次的词项和只出现了一次的词项会处于等同的地位,就是大家都是1.按照常理来说,文档中词项出现的频率越高,那么就意味着这个词项在文档中的地位就越高,相应的权重就越大。而这个权重就是词项出现的次数,这样的权重计算结果被称为词频(term frequency),用TF来表示。
IDF的出现:
在用TF来表示权重的时候,会出现一个严重的问题:就是所有 的词项都被认为是一样重要的。但在实际中,某些词项对文本相关性的计算来说毫无意义,举个例子,所有的文档都含有汽车这个词汇,那么这个词汇就没有区分能力。解决这个问题的直接办法就是让那些在文档集合中出现频率较高的词项获得一个比较低的权重,而那些文档出现频率较低的词项应该获得一个较高的权重。
为了获得出现词项T的所有的文档的数目,我们需要引进一个文档频率df。由于df一般都比较大,为了便于计算,需要把它映射成一个较小的范围。我们假设一个文档集里的所有的文档的数目是N,而词项的逆文档频率(IDF)。计算的表达式如下所示:

通过这个idf,我们就可以实现罕见词的idf比较高,高频词的idf比较低。
TF-IDF的计算:
TF-IDF = TF * IDF
有了这个公式,我们就可以对文档向量化后的每个词给予一个权重,若不含这个词,则权重为0。
余弦相似度的计算:
有了上面的基础知识,我们可以将每个分好词和去停用词的文档进行文档向量化,并计算出每一个词项的权重,而且每个文档的向量的维度都是一样的,我们比较两篇文档的相似性就可以通过计算这两个向量之间的cos夹角来得出。下面给出cos的计算公式:
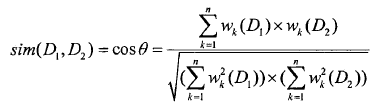
分母是每篇文档向量的模的乘积,分子是两个向量的乘积,cos值越趋向于1,则说明两篇文档越相似,反之越不相似。
文本比较实例:
对文本进行去停用词和分词:
文本未分词前,如下图所示:

文本分词和去停用词后,如下图所示:

- 词频统计和文档向量化
对经过上一步处理过的文档,我们可以统计每个文档中的词项的词频,并且将其向量化,下面我直接给出文档向量化之后的结果。注意:在这里由于只是比较两篇文档的相似性,所以我只用了tf来作为词项的权重,并未使用tf-idf:

向量化后的结果是:
[1,1,1,1,1,1,1,1,1,1,1,1,1,1]
- 两篇文档进行相似度的计算,我会给出两篇文档的原文和最终计算的相似度:
文档原文如下所示:

文档A的内容

文档B的内容

余弦相似度代码实现:
import math
# 两篇待比较的文档的路径
sourcefile = '1.txt'
s2 = '2.txt' # 关键词统计和词频统计,以列表形式返回
def Count(resfile):
t = {}
infile = open(resfile, 'r', encoding='utf-8')
f = infile.readlines()
count = len(f)
# print(count)
infile.close() s = open(resfile, 'r', encoding='utf-8')
i = 0
while i < count:
line = s.readline()
# 去换行符
line = line.rstrip('\n')
# print(line)
words = line.split(" ")
# print(words) for word in words:
if word != "" and t.__contains__(word):
num = t[word]
t[word] = num + 1
elif word != "":
t[word] = 1
i = i + 1 # 字典按键值降序
dic = sorted(t.items(), key=lambda t: t[1], reverse=True)
# print(dic)
# print()
s.close()
return (dic) def MergeWord(T1,T2):
MergeWord = []
duplicateWord = 0
for ch in range(len(T1)):
MergeWord.append(T1[ch][0])
for ch in range(len(T2)):
if T2[ch][0] in MergeWord:
duplicateWord = duplicateWord + 1
else:
MergeWord.append(T2[ch][0]) # print('重复次数 = ' + str(duplicateWord))
# 打印合并关键词
# print(MergeWord)
return MergeWord # 得出文档向量
def CalVector(T1,MergeWord):
TF1 = [0] * len(MergeWord) for ch in range(len(T1)):
TermFrequence = T1[ch][1]
word = T1[ch][0]
i = 0
while i < len(MergeWord):
if word == MergeWord[i]:
TF1[i] = TermFrequence
break
else:
i = i + 1
# print(TF1)
return TF1 def CalConDis(v1,v2,lengthVector): # 计算出两个向量的乘积
B = 0
i = 0
while i < lengthVector:
B = v1[i] * v2[i] + B
i = i + 1
# print('乘积 = ' + str(B)) # 计算两个向量的模的乘积
A = 0
A1 = 0
A2 = 0
i = 0
while i < lengthVector:
A1 = A1 + v1[i] * v1[i]
i = i + 1
# print('A1 = ' + str(A1)) i = 0
while i < lengthVector:
A2 = A2 + v2[i] * v2[i]
i = i + 1
# print('A2 = ' + str(A2)) A = math.sqrt(A1) * math.sqrt(A2)
print('两篇文章的相似度 = ' + format(float(B) / A,".3f")) T1 = Count(sourcefile)
print("文档1的词频统计如下:")
print(T1)
print()
T2 = Count(s2)
print("文档2的词频统计如下:")
print(T2)
print()
# 合并两篇文档的关键词
mergeword = MergeWord(T1,T2)
# print(mergeword)
# print(len(mergeword))
# 得出文档向量
v1 = CalVector(T1,mergeword)
print("文档1向量化得到的向量如下:")
print(v1)
print()
v2 = CalVector(T2,mergeword)
print("文档2向量化得到的向量如下:")
print(v2)
print()
# 计算余弦距离
CalConDis(v1,v2,len(v1))
python实现余弦相似度文本比较的更多相关文章
- python计算余弦复杂度
import numpy as np from sklearn.metrics.pairwise import cosine_similarity a = np.array([1, 2, 3, 4]) ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- 余弦相似度及基于python的三种代码实现、与欧氏距离的区别
1.余弦相似度可用来计算两个向量的相似程度 对于如何计算两个向量的相似程度问题,可以把这它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向.两条线段之间形成一个夹角, ...
- Python 余弦相似度与皮尔逊相关系数 计算
夹角余弦(Cosine) 也可以叫余弦相似度. 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异. (1)在二维空间中向量A(x1,y1)与向量B(x2,y2 ...
- python结巴分词余弦相似度算法实现
过余弦相似度算法计算两个字符串之间的相关度,来对关键词进行归类.重写标题.文章伪原创等功能, 让你目瞪口呆.以下案例使用的母词文件均为txt文件,两种格式:一种内容是纯关键词的txt,每行一个关键词就 ...
- 【Math】余弦相似度 和 Pearson相关系数
http://cucmakeit.github.io/2014/11/13/%E4%BF%AE%E6%AD%A3%E4%BD%99%E5%BC%A6%E7%9B%B8%E4%BC%BC%E5%BA%A ...
- python 对比图片相似度
最近appium的使用越来越广泛了,对于测试本身而言,断言同样是很重要的,没有准确的断言那么就根本就不能称之为完整的测试了.那么目前先从最简单的截图对比来看.我这里分享下python的图片相似度的代码 ...
- 相似度度量:欧氏距离与余弦相似度(Similarity Measurement Euclidean Distance Cosine Similarity)
在<机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)>一文中,我们通过计算文本特征向量之间 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
随机推荐
- cygwin中修改path变量
1.在家目录建立 .bash_profile 文件. 2.在该文件添加: export PATH=/my/path/:$PATH 3.解释,/my/path/为你要添加的目录,为什么不在.bashrc ...
- C# 接口、抽象类、以及事件
接口.抽象类,用于项目集成,如: Interface icls = appid == "A" ? new ClassA() : new ClassA();icls.func(&qu ...
- C# 调用JS Eval,高效率
/// <summary> /// 动态计算表达式 /// </summary> class JSCaller { /// <summary> /// 动态计算表达 ...
- C++ GDI图形设备接口
一.概念 1. GDI:(Graphics Device Interfase)图形设备接口,是一个应用程序与输出设备之间的中介. 一方面,GDI向应用程序提供一个与设备无关的编程环境,另一方面,它又以 ...
- JSP+SpringMVC框架使用WebUploader插件实现注册时候头像图片的异步上传功能
一.去官网下载webuploader文件上传插件 https://fex.baidu.com/webuploader/ 下载好后把它放到Javaweb项目的文件夹中(我放到了webcontent下面的 ...
- mongo数据库的一些命令(对于新同学,按照我的步骤连一遍即可)
进入mongo mongo 查看数据库 show dbs;/show databases(); 第一个命令简单(admin和local数据库是系统自带的) 进入/创建数据库 use 数据库名字(如果有 ...
- python中的exec()函数和eval()函数
exec()函数 exec函数用于执行存储在字符串中的python语句 >>> exec("x=1") >>> x 但有时候,直接这样执行可能会 ...
- 启动keepalived报错(VI_1): received an invalid passwd!
一.署keepalived后测试主down掉后无法自动切换到备 查看message日志一直报此错误 [root@lb-nginx-master ~]# tailf /var/log/messages ...
- Tensorcore使用方法
用于深度学习的自动混合精度 深度神经网络训练传统上依赖IEEE单精度格式,但在混合精度的情况下,可以训练半精度,同时保持单精度网络的精度.这种同时使用单精度和半精度表示的技术称为混合精度技术. 混合 ...
- httprunner学习16-locust性能测试
前言 HttpRunner 的 yaml 脚本文件,可以结合locust做性能测试 locust环境准备 安装完成 HttpRunner 后,系统中会新增locusts命令,但不会同时安装 Locus ...