深度学习-强化学习(RL)概述笔记
强化学习(Reinforcement Learning)简介
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
它主要包含四个元素,环境状态,行动,策略,奖励, 强化学习的目标就是获得最多的累计奖励。RL考虑的是智能体(Agent)与环境(Environment)的交互问题,其中的agent可以理解为学习的主体,它一般是咱们设计的强化学习模型或者智能体,这个智能体在开始的状态试图采取某些行动去操纵环境,它的行动从一个状态到另一个状态完成一次初始的试探,环境会给予一定的奖励,这个模型根据奖励的反馈作出下一次行动(这个行动就是当前这个模型根据反馈学来的,或者说这就是一种策略),经过不断的行动、反馈、再行动,进而学到环境状态的特征规律。一句话概括:RL的目标是找到一个最优策略,使智能体获得尽可能多的来自环境的奖励。
在每个时间步(timestep),智能体在当前状态根据观察来确定下一步的动作,因此状态和动作之间存在映射关系,这种关系就是策略,用表示:
记作a=π(s),a表示系统可以做出动作action的集合,s:系统所处状态state的集合。
学习开始时往往采用随机策略进行实验得到一系列的状态、动作和奖励样本,算法根据样本改进策略,最大化奖励。由于奖励越来越大的特性,这种算法被称作增强学习。
Markov decision processes
马尔可夫性:系统的下一个状态仅与当前状态有关,而与历史状态无关。
此处的状态是指完全可观察的全部的环境状态
回报(Return)
为最大化长期累积奖赏,定义当前时刻后的累积奖赏为回报(Return),考虑折扣因子(避免时间过长时,总回报无穷大):
值函数(Value Function)
强化学习的目标是学习到一个策略来最大化期望,即希望智能体执行一系列的动作来获得尽可能多的平均回报。为评估一个策略的期望回报,需要定义值函数.
状态值函数:在状态下获得的期望回报。
状态-动作值函数:在状态下执行动作
后获得的期望回报。
根据马尔可夫特性,二者有如下关系:
即状态值函数是动作-状态值函数
关于动作
的期望。
贝尔曼方程(Bellman equation)
其意义在于当前状态的值函数可以通过下一状态的值函数来计算。同理,状态-动作值函数也有类似关系。
计算状态值函数的目的是为了构建学习算法从数据中得到最优策略,每个策略对应着一个状态值函数,最优策略对应着最优状态值函数。
基于值函数的学习方法
求解最优策略等价于求解最优的值函数,这是求解最优策略的一种方法,称为基于值函数的学习方法,DQN采用该算法。
最优的值必然为最大值,故等式右侧的
值必然为使
取最大的
值。
由于值函数是对策略的评估,为不断优化直至选出最优策略,一种可行的方式是依据值函数选取策略更新的方式。常见的策略有两种:
- 贪婪策略
贪婪策略是一个确定性策略,即始终选取使值函数最大的策略。这是智能体对已知知识的利用(exploitation),不好更新出更好的值,但可以得到更好的测试效果用于判断算法是否有效。
- ε-greedy策略:
选取不使值函数最大的动作表示智能体对未知知识的探索(exploration),探索未知的动作会产生的未知的效果,有利于更新
分类
马尔科夫链过程
- 基于模型的(Model-based):动态规划
- 无模型的(Model-free):强化学习
- 基于值函数的(Value-based)
- 基于策略梯度的(Policy-gradient)
- 基于模型的(Model-based)
基于模型的强化学习方法(动态规划)的前提是知道环境的状态转移概率,但在实际问题中,状态转移的信息往往无法获知,由此需要数据驱动的无模型(model-free)的方法。
蒙特卡罗(Monte Carlo)方法
在无模型时,一种自然的想法是通过随机采样的经验平均来估计期望值,此即蒙特卡罗法。其过程可以总结如下:
- 智能体与环境交互后得到交互序列
- 通过序列计算出各个时刻的奖赏值
- 将奖赏值累积到值函数中进行更新
- 根据更新的值函数来更新策略
在动态规划中,为保证算法的收敛性,算法会逐个扫描状态空间中的状态,计算值函数时用到了当前状态的所有后继状态的值函数。而蒙特卡罗利用经验平均估计状态的值函数,此处的经验是指一次试验,而一次试验要等到终止状态出现才结束,因此学习速度慢,效率不高。下图较直观展示了二者的不同。
动态规划:
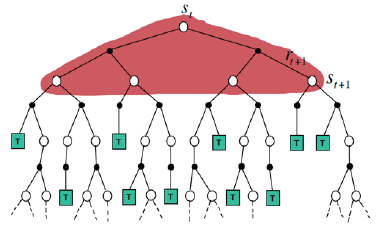
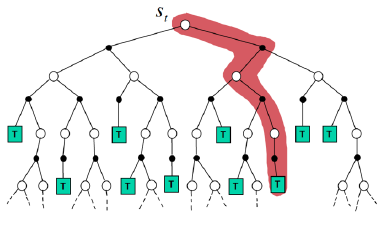
在蒙特卡罗中,如果采用确定性策略,每次试验的轨迹都是一样的,因此无法进一步改进策略。为了使更多状态-动作对参与到交互过程中,即平衡探索和利用,常用ε-greedy策略来产生动作 ,以保证每个状态-动作对都有机会作为初始状态,在评估状态-动作值函数时,需要对每次试验中所有状态-动作对进行估计。
时序差分方法(Temporal Difference)
由于蒙特卡罗需要获得完整轨迹,才能进行策略评估并更新,效率较低。时序差分法结合了动态规划和蒙特卡罗,即模拟一段轨迹(一步或者几步),然后利用贝尔曼方程进行自迭代更新,如下图所示:
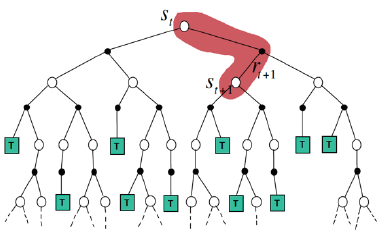
对该方法的通俗理解:
你需要从A点出发,经过B点后到C点,你有两个路段(A-B,B-C)的估计用时,在一次实验中,经过A-B路段后得到一个准确用时,根据这个准确用时和B-C路段的估计用时即可得到新的全路段估计用时(即更新)。
上述例子体现了TD学习的主要原则:不必等到实验结束再沿着实验路径进行更新。
区别
蒙特卡罗使用的是值函数最原始的定义,即利用所有奖赏的累积和来估计值函数;
动态规划和时序差分则利用一步预测方法来计算当前状态值函数,不同的是,动态规划利用模型计算后继状态,时序差分利用实验得到后继状态。
*************************************************************
强化学习的算法简介
(1)通过价值选行为:
Q learning,Sarsa,Deep Q Network
(2)直接选行为:
Policy Gradients
(3)想象环境,并从中学习:
Model based RL
强化学习方法汇总--强化学习算法分类
分类一:
(1)不理解环境(Model-Free RL)
代表方法--Q learning,Sarsa,Policy Gradients
例如机器人在现实世界的探索只能按部就班一步一步等待现实世界的反馈,决定下一次的行动
(2)理解环境(Model-Based RL)
为现实世界建模,Model-Based比Model-Free多出了一个虚拟环境,它采用的方式依然是Model-Free RL中的方法Q learning,Sarsa,Policy Gradients,它的优势就是可以通过想象预判接下来要发生的所有情况,然后根据所有情况中最好的一种进行采取下一步的策略,例如AlphaGo
分类二:
(1)基于概率(Policy-Based RL)
是强化学习最直接的一种,它能通过 感官分析所处的环境,直接输出下一步所采取的行动的概率,然后根据概率采取行动,所以每种行动都有可能被选中,只是可能性不同。
代表方法--Policy Gradients...
(2)基于价值(Value-Based RL)
它输出所有动作的价值,然后根据最高价值来选择动作
代表方法--Q learning,Sarsa...
相比Policy-Based RL的方法,Value-Based RL更为坚定,毫不留情,就选价值最高的,而对Policy-Based RL来说即使概率最高也不一定被选择到。
对于连续的动作基于价值的方法是无能为力的。对于连续的动作确定其分布就能选择特定动作,这也是基于概率方法的优点之一。
(3) Actor-Critic--结合Policy-Based RL与Value-Based RL的优点
Policy Gradients...----(Actor)基于概率作出动作
Q learning,Sarsa...----(Critic)给出动作的价值
结合 基于概率(Policy-Based RL)--Policy Gradients...与基于价值(Value-Based RL)--Q learning,Sarsa...创造出更有利的方法Actor-Critic
(Actor)基于概率做出动作,(Critic)对于做出的动作给出动作的价值,这样在原有的基础上加速了学习过程。
分类三:
(1)回合更新(Monte-Carlo update)
每回合等待游戏结束再更新
代表方法--基础版Policy Gradients,Monte-Carlo Learning...
(2)单步更新(Temporal-Difference update)
每回合中的每一步都进行更新,这样就可以边玩边学习
代表方法--Q Learning,Sarsa,升级版Policy Gradients...
分类四:
(1)在线学习(On-Policy)
必须本人在场,并且一定是本人边玩边学习
代表方法--Sarsa,Sarsa(λ)
(2)离线学习(off-Policy)
可以选择自己玩也可以选择看着别人玩,通过看着别人玩来学习别人的行为准则,它同样是从过往经验中学习,但是这些过往的经历没有必要自己经历,任何人的经历都能被学习,或者也不必要边玩边学习,可以白天先储存下来玩耍时的记忆,等到晚上再通过离线学习来学习白天的记忆。
代表方法--Q Learning,Deep Q Network
深度学习-强化学习(RL)概述笔记的更多相关文章
- 核函数 深度学习 统计学习 强化学习 神经网络 xx
- NLP&深度学习:近期趋势概述
NLP&深度学习:近期趋势概述 摘要:当NLP遇上深度学习,到底发生了什么样的变化呢? 在最近发表的论文中,Young及其同事汇总了基于深度学习的自然语言处理(NLP)系统和应用程序的一些最新 ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 用深度强化学习玩FlappyBird
摘要:学习玩游戏一直是当今AI研究的热门话题之一.使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强.使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理 ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- David Silver 强化学习原理 (中文版 链接)
教程的在线视频链接: http://www.bilibili.com/video/av9831889/ 全部视频链接: https://space.bilibili.com/74997410/vide ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
随机推荐
- 去掉idea的mybatis烦人的xml提示
可以在setting中自己找,也可以在顶部输入 No data sources configure , SQL dialect detection , Injected language fra ...
- 如何设置select只读不可编辑且select的值可传递(摘自百度)
selectname="role"id="role"οnfοcus="this.defaultIndex=this.selectedIndex;&qu ...
- spring boot整合websocket之使用自带tomcat启动项目报错记录
项目中用到websocket,就将原来写好的websocket工具类直接拿来使用,发现前端建立连接的时候报404,经查找发现是因为原来用的是配置的外部tomcat启动,这次是spring boot自带 ...
- 【Gamma】Scrum Meeting 4 & 助教参会记录
目录 前言 任务分配 燃尽图 会议照片 签入记录 上周助教交流总结 技术博客 一些说明 前言 第4次会议于5月29日22:00线上交流形式召开. 交流确认了各自的任务进度,并与助教进行了沟通.时长20 ...
- 【Python】[技术博客] 一些使用Python编写获取手机App日志的操作
一些使用Python编写获取手机App日志的操作 如何获取手机当前打开的App的包名 如何获取当前App进程的PID 如何查看当前App的日志 如何将日志保存到文件 如何关闭进程 如何不显示命令行窗口 ...
- oracle通过dblink连接mysql配置详解(全Windows下)
关于oracle通过dblink连接mysql,经过了两周的空闲时间研究学习,终于配置好了,真是不容易啊,仔细想想的话,其实也没花多长时间,就是刚开始走了一段弯路,所以把这次的经验分享出来,让大家少走 ...
- [Web] HTML5新特性history pushState/replaceState解决浏览器刷新缓存
转载: https://www.jianshu.com/p/cf63a1fabc86 现实开发中,例如‘商品列表页’跳转‘商品详情页’,返回时,不重新加载刷新页面,并且滚动到原来的位置. 1.首先,先 ...
- layui中的table中toolbar自定义过程
自己挖过的坑需要自己来填. layui的table默认表头工具栏右边有3个操作,分别是过滤字段.导出excel.打印功能. 在js中代码添加toolbar即可实现上面的效果: table.render ...
- Linux如何将未分配的硬盘挂载出来
情景说明 客户给了几台服务器,说500G硬盘,但到手操作的时候,使用命令查看,发现只有不到200的硬盘 [root@localhost ~]# df -h Filesystem Size Used A ...
- Qt 一张图片显示在其他组件之上
图片放在QLabel上,注意设置QLable一些属性 QImage img("test.png"); img = img.scaledToWidth(,Qt::SmoothTran ...