[转帖]Zookeeper
Zookeeper
https://www.cnblogs.com/zhang-qc/p/8877082.html
Zookeeper其实是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务。提供分布式锁服务这基本的服务(类似google chubby),同时也支持许多其他的服务,例如配置维护、命名管理、集群管理、组服务、分布式消息队列、分布式通知/协调。
ZooKeeper所提供的服务主要是通过:数据结构(Znode)+原语+watcher机制,三个部分来实现的。
使用ZooKeeper来进行分布式通知和协调能够大大降低系统之间的耦合(使用到了发布/订阅模式)。
数据模型
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统
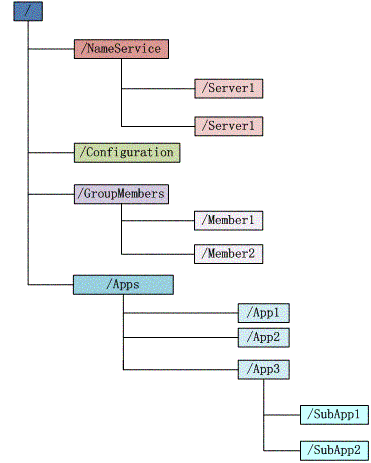
具有如下特点:
- 每个子目录项都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
节点的类型:
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
顺序节点
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为"%10d"(10位数字,没有数值的数位用0补充,例如"0000000001")。当计数值大于232-1时,计数器将溢出。
监控
客户端可以在节点上设置watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
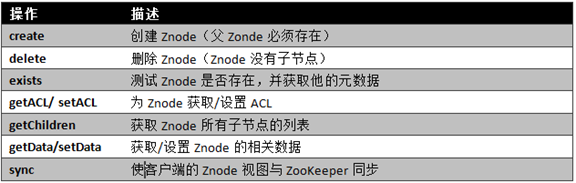
基本操作与实例
在ZooKeeper中有9个基本操作,如下图所示:
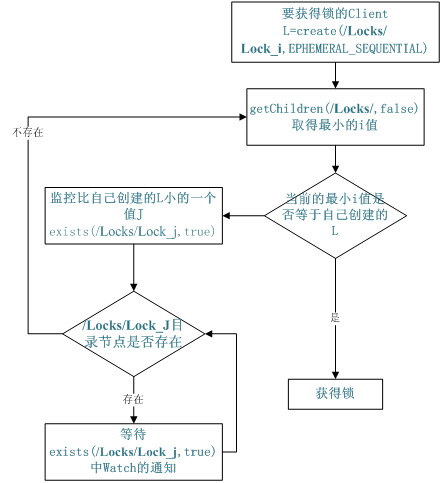
共享锁:
需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void getLock() throws KeeperException, InterruptedException{ List<String> list = zk.getChildren(root, false); String[] nodes = list.toArray(new String[list.size()]); Arrays.sort(nodes); if(myZnode.equals(root+"/"+nodes[0])){ doAction(); } else{ waitForLock(nodes[0]); } } void waitForLock(String lower) throws InterruptedException, KeeperException { Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ mutex.wait(); } else{ getLock(); } } |
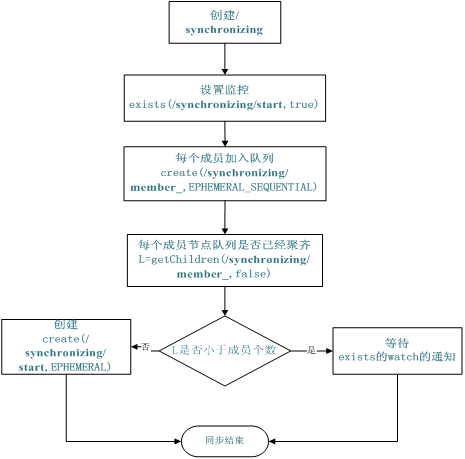
队列管理
Zookeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void addQueue() throws KeeperException, InterruptedException{ zk.exists(root + "/start",true); zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) { List<String> list = zk.getChildren(root, false); if (list.size() < size) { mutex.wait(); } else { zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } }} |
当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下
|
1
2
3
4
5
6
7
8
|
public void process(WatchedEvent event) { if(event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated){ System.out.println("得到通知"); super.process(event); doAction(); } } |
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
---------------------------------------------------------------------------------------------------------------------
zab协议
最基本的一致性算法是Paxos,但是存在如下的一些问题:
- 活锁问题:由于不存在leader,则存在P1和P2都提交了proposal,但是其中1个的n较小会被拒绝,所以立马提出更大n的proposal,所以两边不断提出更大n的proposal,始终不能commit;
- 复杂度问题:base-paxos协议中还存在这样那样的问题,于是各种变种paxos出现了,比如为了解决活锁问题,出现了multi-paxos;为了解决通信次数较多的问题,出现了fast-paxos;为了尽量减少冲突,出现了epaxos。可以看到,工业级实现需要考虑更多的方面,诸如性能,异常等等。这也是为啥许多分布式的一致性框架并非真正基于paxos来实现的原因
- 全序问题:对于paxos算法来说,不能保证两次提交最终的顺序,而zookeeper需要做到这点(保证所有的包之间严格的FIFO顺序)。
所以采用zab协议(zookeeper atomic broadcast),ZAB在Paxos算法上做了重要改造,和Paxos有着明显的不同。
- 可靠传输:如果消息m被一台服务器送达,它最终会被送达到所有服务器
- 全序:如果一台服务器上消息a在消息b前送达,那么在所有服务器上a将比b先送达。如果a和b是已传输过的消息,那么要么a在b前送达,要么b在a前送达(即不可能有同时发生的情况)
- 因果序:如果一个发送者在消息a送达后再发送消息b,那么a必须排在b之前。如果发送者在送达b后再发送消息c,那么c必须排在b之后
- 有序传输:数据发出和数据送达的顺序严格一致,即消息m被送达当且仅当m前发送的所有消息都已被送达。(推论:如果m丢失,m后的所有消息必须丢弃)
- 关闭后没有消息:一旦FIFO通道关闭,不会再从它收到消息。
唯一id保证:
ZooKeeper事务id(zxid)来标记整体顺序,zxid由周期(epoch)和计数器(counter)组成,各为32位整数,因此zxid也可以记为一个整数对(epoch, count)。epoch的值代表leader的改变,leader对每个提案只是简单地递增zxid以得到一个唯一的zxid值。Leader激活算法会保证只有一个leader使用一个特定的epoch,因此这个简单的算法可以保证每个提案都有一个唯一的id。
法定人数设定:
“法定人数”代表一组服务器,必须满足任意两个法定人数对之间至少有一个共同的服务器。因此典型情况下,任意一个法定人数至少有(n/2+1)台服务器即可满足要求,这里n是ZooKeeper服务中的总服务器数。也有其它的构成法定人数的方法,例如PBFT中是2n/3+1,或者对每台服务器分配投票的权重,最后只需要加权的服务器投票数和超过1/2即可。
follower对于提案的认可:认可意味着服务器已将提案保存到持久化存储上,并且发送ACK。
- Leader激活:在这个阶段,leader建立起正确的状态并准备发起提案
- 消息激活:在这个阶段,leader接受消息以发起或协调消息传输follower对于提案的认可:认可意味着服务器已将提案保存到持久化存储上,并且发送ACK。
Leader激活满足的条件:
当且仅当followers中的法定人数(leader也算)与该leader达成同步,即它们有相同的状态。这个状态包含leader认为所有已提交的提案,以及让followers跟随本leader的提案(NEW_LEADER提案)。具体使用什么leader选举算法不关心,只要保证如下两点:
- leader已经获知所有followers的最大的zxid
- 一个服务器间的法定人数已经确认会跟随leader
Leader选举完成后一台服务器会被指定为leader并等待followers的连接,其他服务器尝试连接到leader。Leader将和followers同步,通过发送followers缺失的提案(DIFF),但如果followers缺失太多提案,将发送一个完整的快照(SNAP)。
新leader通过获知的最大zxid来确定新的zxid,如前最大zxid的epoch位是e,则leader使用(e+1, 0)作为新的zxid。在leader和follower同步后,leader会发出一个NEW_LEADER提案。一旦NEW_LEADER提案被提交,leader就算完全激活并开始收发其他提案。
具体的策略如下:
- 选举拥有 proposal 最大值(即 zxid 最大) 的节点作为新的 leader:由于所有提案被 COMMIT 之前必须有合法数量的 follower ACK,即必须有合法数量的服务器的事务日志上有该提案的 proposal,因此,只要有合法数量的节点正常工作,就必然有一个节点保存了所有被 COMMIT 消息的 proposal 状态。
- 新的 leader 将自己事务日志中 proposal 但未 COMMIT 的消息处理。
- 新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息。
消息激活阶段(广播):十分类似于二阶段的提交过程
- leader以相同的顺序向所有followers发送提案,且这一顺序和收到请求的顺序保持一致。因为使用了FIFO通道,于是保证followers也按此顺序收到提案。
- followers以收到提案的顺序处理消息。这意味着消息将被有序地ACK且leader按此顺序收到ACK,仍然是由FIFO通道保证。这也意味着如果某提案上的消息m被写到非易失性存储(硬盘)上,所有在m前提出的提案上的消息也已被写到非易失性存储上。
- 当法定人数的followers全部ACK某消息后,leader会发出一个COMMIT提案。因为所有消息是按序ACK的,leader发出COMMIT且followers收到该提案也是按序的。
- COMMIT按序被处理。提案被提交后意味着followers可以分发提案上的消息了(发送给客户端)。
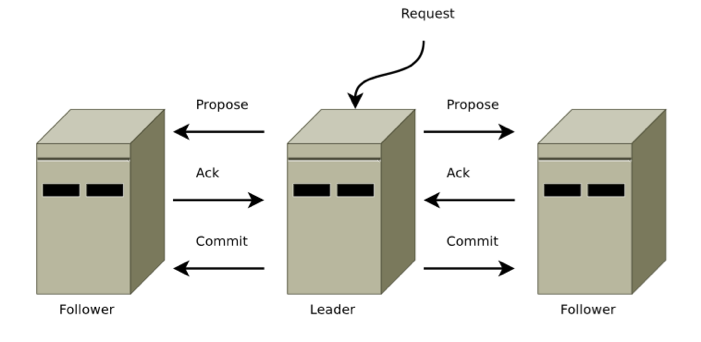
与Paxos的区别:主要在于需要保证所有的proposal的有序
zab与raft的相同点:
- 都使用timeout来重新选择leader.
- 采用quorum来确定整个系统的一致性(也就是对某一个值的认可),这个quorum一般实现是集群中半数以上的服务器,zookeeper里还提供了带权重的quorum实现.
- 都由leader来发起写操作.
- 都采用心跳检测存活性.
- leader election都采用先到先得的投票方式.
部分不同点(不一定准确):
- zab用的是epoch和count的组合来唯一表示一个值, 而raft用的是term和index.
- zab的follower在投票给一个leader之前必须和leader的日志达成一致,而raft的follower则简单地说是谁的term高就投票给谁.
- raft协议的心跳是从leader到follower, 而zab协议则相反.
- raft协议数据只有单向地从leader到follower(成为leader的条件之一就是拥有最新的log), 而zab协议在discovery阶段, 一个prospective leader需要将自己的log更新为quorum里面最新的log,然后才好在synchronization阶段将quorum里的其他机器的log都同步到一致.
参考:https://blog.csdn.net/mayp1/article/details/51871761 https://www.jianshu.com/p/fb527a64deee
[转帖]Zookeeper的更多相关文章
- [转帖]Zookeeper入门看这篇就够了
Zookeeper入门看这篇就够了 https://my.oschina.net/u/3796575/blog/1845035 Zookeeper是什么 官方文档上这么解释zookeeper,它是一个 ...
- [转帖]Zookeeper vs etcd vs Consul比较
Zookeeper vs etcd vs Consul比较 https://it.baiked.com/consul/2341.html 需要转型 加强学习. 如果使用预定义的端口,服务越多,发生冲突 ...
- 【转帖】云平台发现服务构建:为什么不使用ZooKeeper
http://www.chinacloud.cn/show.aspx?id=19979&cid=16 [日期:2015-04-29] 来源:dockerone 作者: [字体:大 中 小] ...
- 【转帖】为什么不要把ZooKeeper用于服务发现
http://www.infoq.com/cn/news/2014/12/zookeeper-service-finding ZooKeeper是Apache基金会下的一个开源的.高可用的分布式应用协 ...
- 【转帖】基于Zookeeper的服务注册与发现
http://www.techweb.com.cn/network/hardware/2015-12-25/2246973.shtml 背景 大多数系统都是从一个单一系统开始起步的,随着公司业务的快速 ...
- [转帖]很遗憾,没有一篇文章能讲清楚ZooKeeper
很遗憾,没有一篇文章能讲清楚ZooKeeper https://os.51cto.com/art/201911/606571.htm [51CTO.com原创稿件]互联网时代是信息爆发的时代,信息的高 ...
- [转帖]从0开始的高并发(一)--- Zookeeper的基础概念
从0开始的高并发(一)--- Zookeeper的基础概念 https://juejin.im/post/5d0bd358e51d45105e0212db 前言 前面几篇以spring作为主题也是有些 ...
- [转帖]【ZOOKEEPER系列】Paxos、Raft、ZAB
[ZOOKEEPER系列]Paxos.Raft.ZAB 2018-07-11 12:09:49 wangzy-nice 阅读数 2428更多 分类专栏: zookeeper 版权声明:本文为博主原 ...
- [转帖]为什么需要 Zookeeper
为什么需要 Zookeeper 柳树 学习&思考&写作 | 公众号:柳树的絮叨叨 关注他 童话 . 沈万马 等 351 人赞同了该文章 很多中间件,比如Kafka.Hadoop.HB ...
随机推荐
- Likelihood function
似然函数 统计学中,似然函数是一种关于统计模型参数的函数,表示模型参数中的似然性. 给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ ...
- 使用grok exporter 做为log 与prometheus 的桥
grok 是一个工具,可以用来解析非结构化的日志文件,可以使其结构化,同时方便查询,grok 被logstash 大量依赖 同时社区也提供了一个prometheus 的exporter 可以方便的进行 ...
- maven的安装、路径配置、修改库文件路径和eclipse中的配置、创建maven工程。
注:本文来源于:杨四郎2018 <maven的安装.路径配置.修改库文件路径和eclipse中的配置.创建maven工程> 一.maven的安装 首先,先到官网去下载maven.这里是官 ...
- HHHOJ #153. 「NOI模拟 #2」Kotomi
抽代的成分远远大于OI的成分 首先把一个点定为原点,然后我们发现如果我们不旋转此时答案就是所有位置的\(\gcd\) 如果要选择怎么办,我们考虑把我们选定的网格边连同方向和大小看做单位向量\(\vec ...
- mac切图
1.按住command键位, 两只手指点击需要切的图 2.再在右边栅格化图层 3.选中需要剪切的图层.command+c 和command+n和 command+v OK 切整张图.先 option ...
- Android Studio 之 DataBing ,不需要再一个个findViewById了
使用DataBinding,不需要再一个个findViewById了 1.在 build.gradel 中 添加下面语句 dataBinding{ enabled true } 2.在 activit ...
- idea打包web项目
打包完成的文件在如下路径
- IO多路复用之select poll epoll
参考文档: http://blog.csdn.net/tennysonsky/article/details/45745887 select(),poll(),epoll()都是I/O多路复用的机制. ...
- Octopus501工作站 安装记录
cmake libreadline-dev 没有运行程序,nvidia-smi查看GPU-Util 达到100% 解决方案:需要把驱动模式设置为常驻内存才可以,设置命令:nvidia-smi -pm ...
- activeMQ 的启动 停止 查看状态
1 启动 : 进入到activeMQ 的 bin 目录,执行 ./activemq start 开启 ,如下: 2 查看activeMQ 是不是启动的状态, ./activemq statu ...