Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍
- k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等。
- kubernetes1.9版本发布2017年12月15日,每三个月一个迭代版本, Workloads API成为稳定版本,这消除了很多潜在用户对于该功能稳定性的担忧。还有一个重大更新,就是测试支持了Windows了,这打开了在kubernetes中运行Windows工作负载的大门。
- CoreDNS alpha可以使用标准工具来安装CoreDNS
- kube-proxy的IPVS模式进入beta版,为大型集群提供更好的可扩展性和性能。
- kube-router的网络插件支持,更方便进行路由控制,发布,和安全策略管理
Kubernetes 架构
Kubernetes 最初源于谷歌内部的 Borg,提供了面向应用的容器集群部署和管理系统。Kubernetes 的目标旨在消除编排物理 / 虚拟计算,网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的原语上进行自助运营。Kubernetes 也提供稳定、兼容的基础(平台),用于构建定制化的 workflows 和更高级的自动化任务。 Kubernetes 具备完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。 Kubernetes 还提供完善的管理工具,涵盖开发、部署测试、运维监控等各个环节。
Borg 简介
Borg 是谷歌内部的大规模集群管理系统,负责对谷歌内部很多核心服务的调度和管理。Borg 的目的是让用户能够不必操心资源管理的问题,让他们专注于自己的核心业务,并且做到跨多个数据中心的资源利用率最大化。
Borg 主要由 BorgMaster、Borglet、borgcfg 和 Scheduler 组成,如下图所示
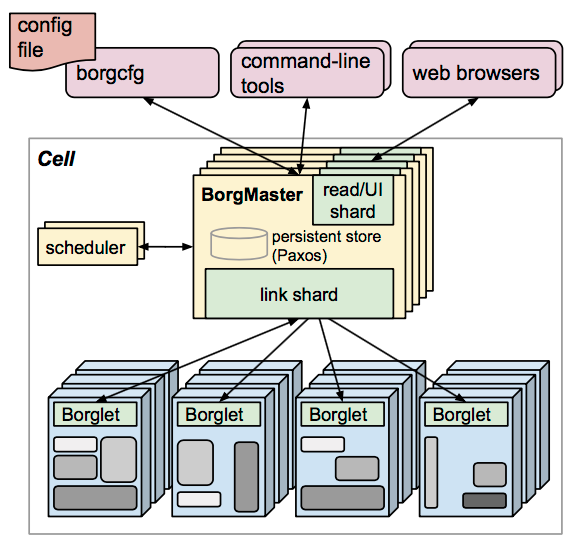
- BorgMaster 是整个集群的大脑,负责维护整个集群的状态,并将数据持久化到 Paxos 存储中;
- Scheduer 负责任务的调度,根据应用的特点将其调度到具体的机器上去;
- Borglet 负责真正运行任务(在容器中);
- borgcfg 是 Borg 的命令行工具,用于跟 Borg 系统交互,一般通过一个配置文件来提交任务。
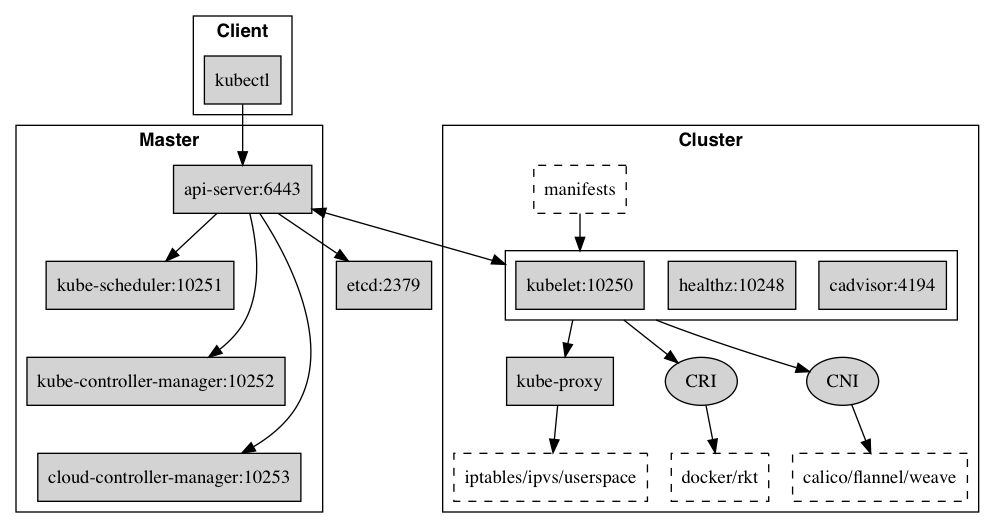
Kubernetes 架构
Kubernetes 借鉴了 Borg 的设计理念,比如 Pod、Service、Labels 和单 Pod 单 IP 等。Kubernetes 的整体架构跟 Borg 非常像,如下图所示
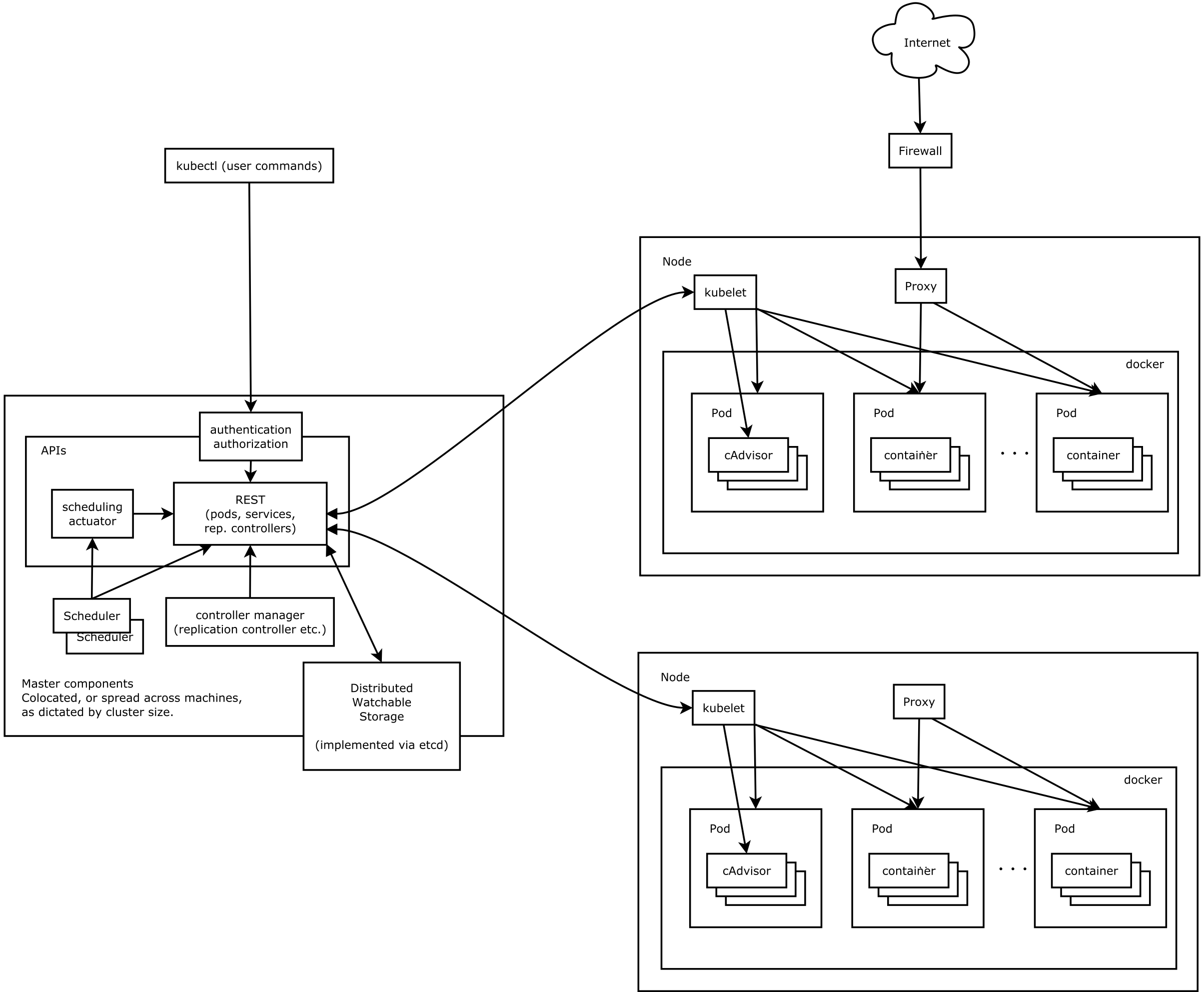
Kubernetes 主要由以下几个核心组件组成:
- etcd 保存了整个集群的状态;
- kube-apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- kube-controller-manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- kube-scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
- kubelet 负责维持容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI),默认的容器运行时为 Docker;
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的 Add-ons:
- kube-dns 负责为整个集群提供 DNS 服务
- Ingress Controller 为服务提供外网入口
- Heapster 提供资源监控
- Dashboard 提供 GUI
- Federation 提供跨可用区的集群
- Fluentd-elasticsearch 提供集群日志采集、存储与查询
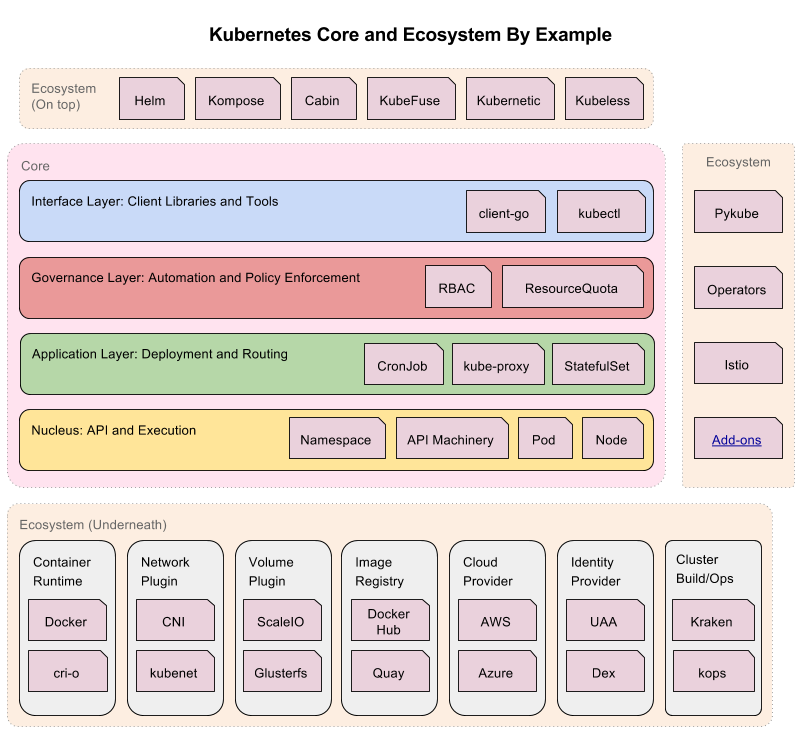
分层架构
Kubernetes 设计理念和功能其实就是一个类似 Linux 的分层架构,如下图所示
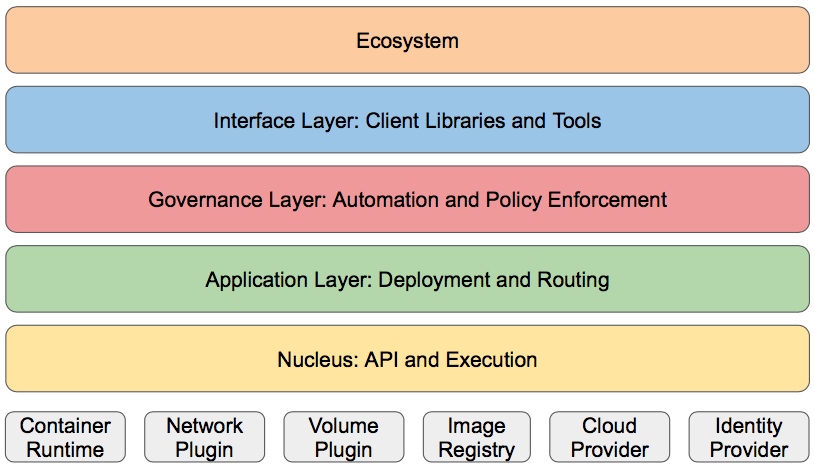
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
核心组件
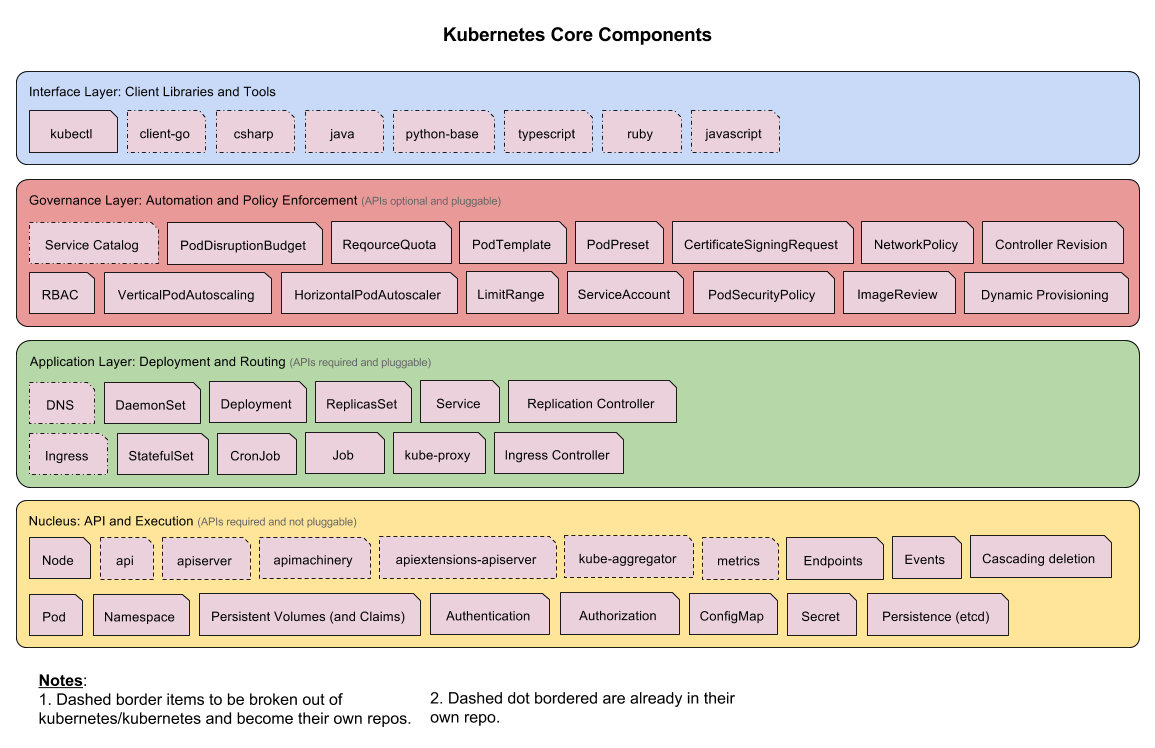
核心 API
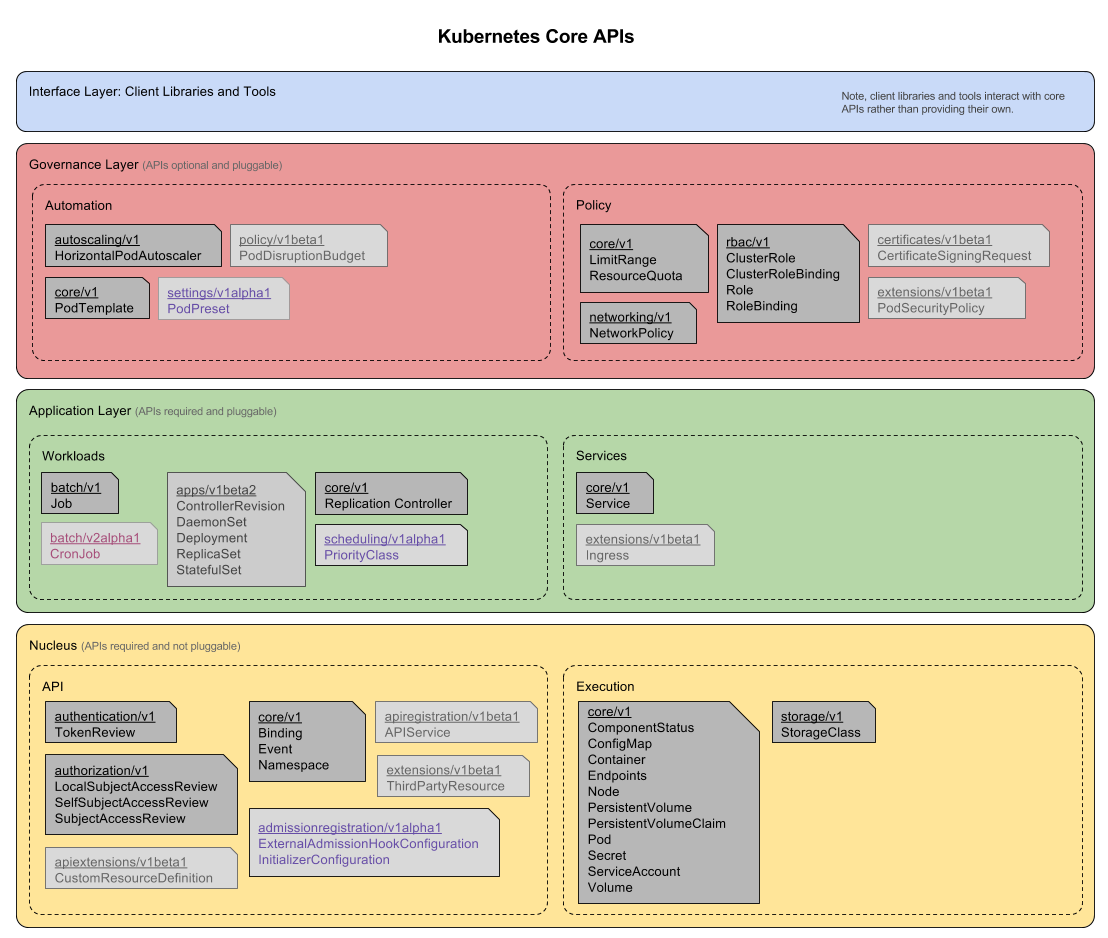
生态系统
关于分层架构,可以关注下 Kubernetes 社区正在推进的 Kubernetes architectural roadmap, 中文参考 :https://feisky.gitbooks.io/kubernetes/。
简单总结:
- k8s 高可用2个核心 ==apiserver master== and ==etcd==
- ==apiserver master==:(需高可用)集群核心,集群API接口、集群各个组件通信的中枢;集群安全控制;
- ==etcd== :(需高可用)集群的数据中心,用于存放集群的配置以及状态信息,非常重要,如果数据丢失那么集群将无法恢复;因此高可用集群部署首先就是etcd是高可用集群;
- kube-scheduler:调度器 (内部自选举)集群Pod的调度中心;默认kubeadm安装情况下--leader-elect参数已经设置为true,保证master集群中只有一个kube-scheduler处于活跃状态;
- kube-controller-manager: 控制器 (内部自选举)集群状态管理器,当集群状态与期望不同时,kcm会努力让集群恢复期望状态,比如:当一个pod死掉,kcm会努力新建一个pod来恢复对应replicas set期望的状态;默认kubeadm安装情况下--leader-elect参数已经设置为true,保证master集群中只有一个kube-controller-manager处于活跃状态;
- kubelet: agent node注册apiserver
- kube-proxy: 每个node上一个,负责service vip到endpoint pod的流量转发,老版本主要通过设置iptables规则实现,新版1.9基于kube-proxy-lvs 实现 更好性能和负载拓展
部署示意图
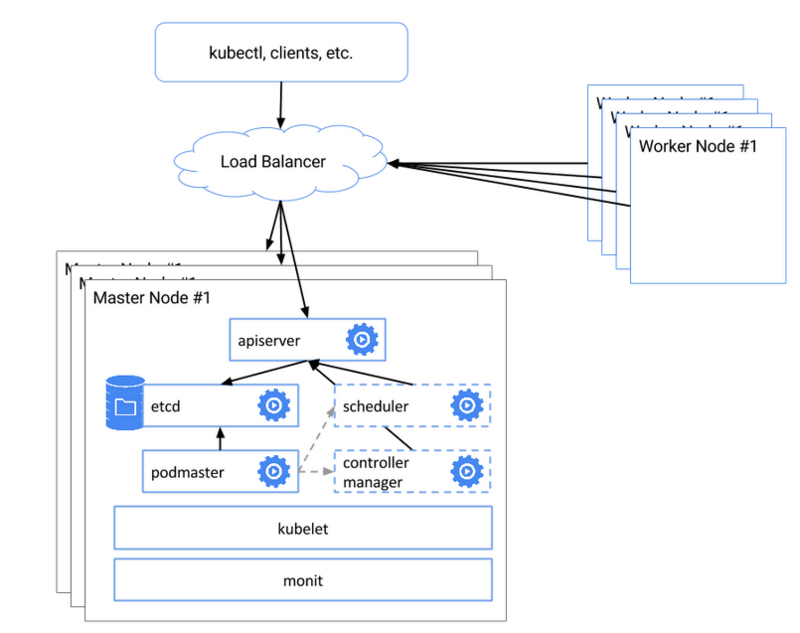

- 集群ha方案,我们力求简单,使用keepalive 监听一个vip来实现,(当节点不可以后,会有vip漂移的切换时长,取决于我们设置timeout切换时长,测试会有10s空档期,如果对高可用更高要求 可以用lvs或者nginx做 4层lb负载 更佳完美,我们力求简单够用,可接受10s的api不可用)
- etcd和master 测试采用 3节点共用部署,(生成环境可以考虑etcd和master分离或者等kubeadm ha正式版推出)
部署环境
最近在部署k8s 1.9集群遇到一些问题,整理记录,或许有助需要的朋友。
因为kubeadm 简单便捷,所以集群基于该项目部署,目前bete版本不支持ha部署,github说2018年预计发布ha 版本,可我们等不及了 呼之欲来。。。| 环境 | 版本 |
|---|---|
| Centos | CentOS Linux release 7.3.1611 (Core) |
| Kernel | Linux etcd-host1 3.10.0-514.el7.x86_64 |
| yum base repo | http://mirrors.aliyun.com/repo/Centos-7.repo |
| yum epel repo | http://mirrors.aliyun.com/repo/epel-7.repo |
| kubectl | v1.9.0 |
| kubeadmin | v1.9.0 |
| docker | 1.12.6 |
| docker localre | devhub.beisencorp.com |
| 主机名称 | 相关信息 | 备注 |
|---|---|---|
| etcd-host1 | 10.129.6.211 | master和etcd |
| etcd-host2 | 10.129.6.212 | master和etcd |
| etcd-host3 | 10.129.6.213 | master和etcd |
| Vip-keepalive | 10.129.6.220 | vip用于高可用 |
环境部署 (我们使用本地离线镜像)
环境预初始化
- Centos Mini安装 每台机器root
- 设置机器名
hostnamectl set-hostname etcd-host1- 停防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl disable firewalld- 关闭Swap
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab- 关闭防火墙
systemctl disable firewalld && systemctl stop firewalld && systemctl status firewalld
- 关闭Selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
getenforce- 增加DNS
echo nameserver 114.114.114.114>>/etc/resolv.conf- 设置内核
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.conf
#若问题
执行sysctl -p 时出现:
sysctl -p
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解决方法:
modprobe br_netfilter
ls /proc/sys/net/bridge配置keepalived
- VIP Master 通过控制VIP 来HA高可用(常规方案)
- 到目前为止,三个master节点 相互独立运行,互补干扰. kube-apiserver作为核心入口, 可以使用keepalived 实现高可用, kubeadm join暂时不支持负载均衡的方式,所以我们
- 安装
yum install -y keepalived- 配置keepalived.conf
cat >/etc/keepalived/keepalived.conf <<EOL
global_defs {
router_id LVS_k8s
}
vrrp_script CheckK8sMaster {
script "curl -k https://10.129.6.220:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 61
# 主节点权重最高 依次减少
priority 120
advert_int 1
#修改为本地IP
mcast_src_ip 10.129.6.211
nopreempt
authentication {
auth_type PASS
auth_pass sqP05dQgMSlzrxHj
}
unicast_peer {
#注释掉本地IP
#10.129.6.211
10.129.6.212
10.129.6.213
}
virtual_ipaddress {
10.129.6.220/24
}
track_script {
CheckK8sMaster
}
}
EOL- 启动
systemctl enable keepalived && systemctl restart keepalived
- 结果
[root@etcd-host1 k8s]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availabilitymonitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2018-01-19 10:27:58 CST; 8h ago
Main PID: 1158 (keepalived)
CGroup: /system.slice/keepalived.service
├─1158 /usr/sbin/keepalived -D
├─1159 /usr/sbin/keepalived -D
└─1161 /usr/sbin/keepalived -D
Jan 19 10:28:00 etcd-host1 Keepalived_vrrp[1161]: Sending gratuitous ARP on ens32 for 10.129.6.220
Jan 19 10:28:05 etcd-host1 Keepalived_vrrp[1161]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens32 for 10.129.6.220- 依次配置 其他2台从节点master 配置 修改对应节点 ip
- master01 priority 120
- master02 priority 110
- master03 priority 100
Etcd https 集群部署
Etcd 环境准备
#机器名称
etcd-host1:10.129.6.211
etcd-host2:10.129.6.212
etcd-host3:10.129.6.213
#部署环境变量
export NODE_NAME=etcd-host3 #当前部署的机器名称(随便定义,只要能区分不同机器即可)
export NODE_IP=10.129.6.213 # 当前部署的机器 IP
export NODE_IPS="10.129.6.211 10.129.6.212 10.129.6.213" # etcd 集群所有机器 IP
# etcd 集群间通信的IP和端口
export ETCD_NODES=etcd-host1=https://10.129.6.211:2380,etcd-host2=https://10.129.6.212:2380,etcd-host3=https://10.129.6.213:2380
Etcd 证书创建(我们使用https方式)
创建 CA 证书和秘钥
- 安装cfssl, CloudFlare 的 PKI 工具集 cfssl 来生成 Certificate Authority (CA) 证书和秘钥文件
- 如果不希望将cfssl工具安装到部署主机上,可以在其他的主机上进行该步骤,生成以后将证书拷贝到部署etcd的主机上即可。本教程就是采取这种方法,在一台测试机上执行下面操作。
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
chmod +x cfssl_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssljson_linux-amd64
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo生成ETCD的TLS 秘钥和证书
为了保证通信安全,客户端(如 etcdctl) 与 etcd 集群、etcd 集群之间的通信需要使用 TLS 加密,本节创建 etcd TLS 加密所需的证书和私钥。
- 创建 CA 配置文件:
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
EOF - ==ca-config.json==:可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个 profile;
- ==signing==:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE;
- ==server auth==:表示 client 可以用该 CA 对 server 提供的证书进行验证;
- ==client auth==:表示 server 可以用该 CA 对 client 提供的证书进行验证;
cat > ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF - "CN":Common Name,kube-apiserver 从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;
- "O":Organization,kube-apiserver 从证书中提取该字段作为请求用户所属的组 (Group);
==生成 CA 证书和私钥==:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
ls ca*
==创建 etcd 证书签名请求:==
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"10.129.6.211",
"10.129.6.212",
"10.129.6.213"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF- hosts 字段指定授权使用该证书的 etcd 节点 IP;
- 每个节点IP 都要在里面 或者 每个机器申请一个对应IP的证书
生成 etcd 证书和私钥:
cfssl gencert -ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
ls etcd*
mkdir -p /etc/etcd/ssl
cp etcd.pem etcd-key.pem ca.pem /etc/etcd/ssl/
#
#其他node
rm -rf /etc/etcd/ssl/*
scp -r /etc/etcd/ssl root@10.129.6.211:/etc/etcd/
scp -r root@10.129.6.211:/root/k8s/etcd/etcd-v3.3.0-rc.1-linux-amd64.tar.gz /root
将生成好的etcd.pem和etcd-key.pem以及ca.pem三个文件拷贝到目标主机的/etc/etcd/ssl目录下。
下载二进制安装文件
到 https://github.com/coreos/etcd/releases 页面下载最新版本的二进制文件:
wget http://github.com/coreos/etcd/releases/download/v3.1.10/etcd-v3.1.10-linux-amd64.tar.gz
tar -xvf etcd-v3.1.10-linux-amd64.tar.gz
mv etcd-v3.1.10-linux-amd64/etcd* /usr/local/bin创建 etcd 的 systemd unit 文件
mkdir -p /var/lib/etcd # 必须先创建工作目录
cat > etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/local/bin/etcd \\
--name=${NODE_NAME} \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--initial-advertise-peer-urls=https://${NODE_IP}:2380 \\
--listen-peer-urls=https://${NODE_IP}:2380 \\
--listen-client-urls=https://${NODE_IP}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${NODE_IP}:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=${ETCD_NODES} \\
--initial-cluster-state=new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF- 指定 etcd 的工作目录和数据目录为 /var/lib/etcd,需在启动服务前创建这个目录;
- 为了保证通信安全,需要指定 etcd 的公私钥(cert-file和key-file)、Peers 通信的公私钥和 CA 证书(peer-cert-file、peer-key-file、peer-trusted-ca-file)、客户端的CA证书(trusted-ca-file);
- --initial-cluster-state 值为 new 时,--name 的参数值必须位于 --initial-cluster 列表中;
启动 etcd 服务
mv etcd.service /etc/systemd/system/
systemctl daemon-reload
systemctl enable etcd
systemctl start etcd
systemctl status etcd验证服务
etcdctl \
--endpoints=https://${NODE_IP}:2379 \
--ca-file=/etc/etcd/ssl/ca.pem \
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
cluster-health预期结果:
[root@node02 ~]# etcdctl --endpoints=https://${NODE_IP}:2379 --ca-file=/etc/etcd/ssl/ca.pem --cert-file=/etc/etcd/ssl/etcd.pem --key-file=/etc/etcd/ssl/etcd-key.pem cluster-health
member 18699a64c36a7e7b is healthy: got healthy result from https://10.129.6.213:2379
member 5dbd6a0b2678c36d is healthy: got healthy result from https://10.129.6.211:2379
member 6b1bf02f85a9e68f is healthy: got healthy result from https://10.129.6.212:2379
cluster is healthy若有失败 或 重新配置
systemctl stop etcd
rm -Rf /var/lib/etcd
rm -Rf /var/lib/etcd-cluster
mkdir -p /var/lib/etcd
systemctl start etcdk8s 安装
提取k8s rpm 包
- 默认由于某某出海问题
- 我们离线导入下rpm 仓库
- 安装官方YUM 仓库
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://yum.kubernetes.io/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF安装kubeadm kubectl cni
- 下载镜像(自行搬×××先获取rpm)
mkdir -p /root/k8s/rpm
cd /root/k8s/rpm
#安装同步工具
yum install -y yum-utils
#同步本地镜像
yumdownloader kubelet kubeadm kubectl kubernetes-cni docker
scp root@10.129.6.224:/root/k8s/rpm/* /root/k8s/rpm
- 离线安装
mkdir -p /root/k8s/rpm
scp root@10.129.6.211:/root/k8s/rpm/* /root/k8s/rpm
yum install /root/k8s/rpm/*.rpm -y
- 启动k8s
#restart
systemctl enable docker && systemctl restart docker
systemctl enable kubelet && systemctl restart kubelet镜像获取方法
- 加速器获取 gcr.io k8s镜像 ,导出,导入镜像 或 上传本地仓库
#国内可以使用daocloud加速器下载相关镜像,然后通过docker save、docker load把本地下载的镜像放到kubernetes集群的所在机器上,daocloud加速器链接如下:
https://www.daocloud.io/mirror#accelerator-doc
#pull 获取
docker pull gcr.io/google_containers/kube-proxy-amd64:v1.9.0
#导出
mkdir -p docker-images
docker save -o docker-images/kube-proxy-amd64 gcr.io/google_containers/kube-proxy-amd64:v1.9.0
#导入
docker load -i /root/kubeadm-ha/docker-images/kube-proxy-amd64- 代理或***获取 gcr.io k8s镜 ,导出,导入镜像 或 上传本地仓库
自谋生路,天机屋漏kubelet 指定本地镜像
kubelet 修改 配置以使用本地自定义pause镜像
devhub.beisencorp.com/google_containers/pause-amd64:3.0 替换你的环境镜像
cat > /etc/systemd/system/kubelet.service.d/20-pod-infra-image.conf <<EOF
[Service]
Environment="KUBELET_EXTRA_ARGS=--pod-infra-container-image=devhub.beisencorp.com/google_containers/pause-amd64:3.0"
EOF
systemctl daemon-reload
systemctl restart kubeletKubeadm Init 初始化
- 我们使用config 模板方式来初始化集群,便于我们指定etcd 集群
- devhub.beisencorp.com 使我们的 测试镜像仓库 可以改成自己或者手动导入每个机器镜像
cat <<EOF > config.yaml
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
etcd:
endpoints:
- https://10.129.6.211:2379
- https://10.129.6.212:2379
- https://10.129.6.213:2379
caFile: /etc/etcd/ssl/ca.pem
certFile: /etc/etcd/ssl/etcd.pem
keyFile: /etc/etcd/ssl/etcd-key.pem
dataDir: /var/lib/etcd
networking:
podSubnet: 10.244.0.0/16
kubernetesVersion: 1.9.0
api:
advertiseAddress: "10.129.6.220"
token: "b99a00.a144ef80536d4344"
tokenTTL: "0s"
apiServerCertSANs:
- etcd-host1
- etcd-host2
- etcd-host3
- 10.129.6.211
- 10.129.6.212
- 10.129.6.213
- 10.129.6.220
featureGates:
CoreDNS: true
imageRepository: "devhub.beisencorp.com/google_containers"
EOF- 初始化集群
kubeadm init --config config.yaml - 结果
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
as root:
kubeadm join --token b99a00.a144ef80536d4344 10.129.6.220:6443 --discovery-token-ca-cert-hash sha256:ebc2f64e9bcb14639f26db90288b988c90efc43828829c557b6b66bbe6d68dfa- 查看node
[root@etcd-host1 k8s]# kubectl get node
NAME STATUS ROLES AGE VERSION
etcd-host1 noReady master 5h v1.9.0
[root@etcd-host1 k8s]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"} - 问题记录
如果使用kubeadm初始化集群,启动过程可能会卡在以下位置,那么可能是因为cgroup-driver参数与docker的不一致引起
[apiclient] Created API client, waiting for the control plane to become ready
journalctl -t kubelet -S '2017-06-08'查看日志,发现如下错误
error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "systemd"
需要修改KUBELET_CGROUP_ARGS=--cgroup-driver=systemd为KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
systemctl daemon-reload && systemctl restart kubelet安装网络组件 podnetwork
- 我们选用kube-router
wget https://github.com/cloudnativelabs/kube-router/blob/master/daemonset/kubeadm-kuberouter.yaml
kubectl apply -f kubeadm-kuberouter.yaml- 结果
[root@etcd-host1 k8s]# kubectl get po --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-546545bc84-zc5dx 1/1 Running 0 6h
kube-system kube-apiserver-etcd-host1 1/1 Running 0 6h
kube-system kube-controller-manager-etcd-host1 1/1 Running 0 6h
kube-system kube-proxy-pfj7x 1/1 Running 0 6h
kube-system kube-router-858b7 1/1 Running 0 37m
kube-system kube-scheduler-etcd-host1 1/1 Running 0 6h
[root@etcd-host1 k8s]# 部署其他Master 节点
- 拷贝master01 配置 master02 master03
#拷贝pki 证书
mkdir -p /etc/kubernetes/pki
scp -r root@10.129.6.211:/etc/kubernetes/pki /etc/kubernetes
#拷贝初始化配置
scp -r root@10.129.6.211://root/k8s/config.yaml /etc/kubernetes/config.yaml- 初始化 master02 master03
#初始化
kubeadm init --config /etc/kubernetes/config.yaml 部署成功 验证结果
为了测试我们把master 设置为 可部署role
默认情况下,为了保证master的安全,master是不会被调度到app的。你可以取消这个限制通过输入:
kubectl taint nodes --all node-role.kubernetes.io/master-录制终端验证 结果

-验证
[zeming@etcd-host1 k8s]$ kubectl get node
NAME STATUS ROLES AGE VERSION
etcd-host1 Ready master 6h v1.9.0
etcd-host2 Ready master 5m v1.9.0
etcd-host3 Ready master 49s v1.9.0
[zeming@etcd-host1 k8s]$ kubectl get po --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default nginx01-d87b4fd74-2445l 1/1 Running 0 1h
default nginx01-d87b4fd74-7966r 1/1 Running 0 1h
default nginx01-d87b4fd74-rcbhw 1/1 Running 0 1h
kube-system coredns-546545bc84-zc5dx 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host1 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host2 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host3 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host1 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host2 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host3 1/1 Running 0 3d
kube-system kube-proxy-gk95d 1/1 Running 0 3d
kube-system kube-proxy-mrzbq 1/1 Running 0 3d
kube-system kube-proxy-pfj7x 1/1 Running 0 3d
kube-system kube-router-bbgpq 1/1 Running 0 3h
kube-system kube-router-v2jbh 1/1 Running 0 3h
kube-system kube-router-w4cbb 1/1 Running 0 3h
kube-system kube-scheduler-etcd-host1 1/1 Running 0 3d
kube-system kube-scheduler-etcd-host2 1/1 Running 0 3d
kube-system kube-scheduler-etcd-host3 1/1 Running 0 3d
[zeming@etcd-host1 k8s]$主备测试
- 关闭 主节点 master01 观察切换到 master02 机器
- master03 一直不管获取node信息 测试高可用
while true; do sleep 1; kubectl get node;date; done观察主备VIP切换过程
#观察当Master01主节点关闭后,被节点VIP状态 BACKUP 切换到 MASTER
[root@etcd-host2 net.d]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2018-01-22 13:54:17 CST; 21s ago
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Received advert with higher priority 120, ours 110
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Entering BACKUP STATE
#切换到 MASTER
[root@etcd-host2 net.d]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2018-01-22 13:54:17 CST; 4min 6s ago
Jan 22 14:03:02 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Entering MASTER STATE
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) setting protocol VIPs.
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: Sending gratuitous ARP on ens32 for 10.129.6.220
验证集群高可用
#观察 master01 关机后状态变成NotReady
[root@etcd-host3 ~]# while true; do sleep 1; kubectl get node;date; done
Tue Jan 22 14:03:16 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 Ready master 19m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0
Tue Jan 22 14:03:17 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 NotReady master 19m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0
#恢复Master主节点后,出现VIP偏移过来,api恢复
The connection to the server 10.129.6.220:6443 was refused - did you specify the right host or port?
Tue Jan 23 14:14:05 CST 2018
The connection to the server 10.129.6.220:6443 was refused - did you specify the right host or port?
Tue Jan 23 14:14:07 CST 2018
Tue Jan 23 14:14:18 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 NotReady master 29m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0
Tue Jan 23 14:14:20 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 Ready master 29m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0参观文档
#k8s 官方文档
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
#kubeadm ha 项目文档
https://github.com/indiketa/kubeadm-ha
https://github.com/cookeem/kubeadm-ha/blob/master/README_CN.md
https://medium.com/@bambash/ha-kubernetes-cluster-via-kubeadm-b2133360b198
#kubespray 之前的kargo ansible项目
https://github.com/kubernetes-incubator/kubespray/blob/master/docs/ha-mode.md
#若有问题或转载请注明出处 By ZemingKubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】的更多相关文章
- [K8s 1.9实践]Kubeadm 1.9 HA 高可用 集群 本地离线镜像部署
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,北森等等. kubernetes1.9版本发布2017年12月15日,每是那三个月一个迭代, W ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- 实现CI/CDk8s高可用集群搭建总结以及部署API到k8s
实现CI/CD(Centos7.2)系列二:k8s高可用集群搭建总结以及部署API到k8s 前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署 ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
随机推荐
- ARM64编译工具链下载
下面是自制的用于编译ARMv8指令的交叉编译工具链: 1.运行在PC上,支持SVE指令,不支持SVE ACLE,版本GCC9.2 https://pan.baidu.com/s/1_NnwajWCel ...
- Spring Boot Admin 2.1.0
原文:https://blog.csdn.net/forezp/article/details/86105850 Spring Boot Admin简介 Spring Boot Admin是一个开源社 ...
- 让Linux中的Nginx支持中文文件名
原文:https://blog.csdn.net/soeben/article/details/79525964 首先你的服务器需要安装了UTF-8字符集在命令行里输入env|grep LANG如果显 ...
- 【会话技术】Cookie技术 案例:访问时间
创建时间:6.30 代码: package cookie; import java.io.IOException; import java.text.SimpleDateFormat; import ...
- [转]【Servlet】Servlet的访问过程
创建时间:6.15 Servlet的访问过程 1. 画图描述整个访问过程: *每次访问service()方法都会创建一对新的request和response对象,都不一样 2. 访问过程2: 问题:对 ...
- Detectron2源码阅读笔记-(三)Dataset pipeline
构建data_loader原理步骤 # engine/default.py from detectron2.data import ( MetadataCatalog, build_detection ...
- python基础语法18 类的内置方法(魔法方法),单例模式
类的内置方法(魔法方法): 凡是在类内部定义,以__开头__结尾的方法,都是类的内置方法,也称之为魔法方法. 类的内置方法,会在某种条件满足下自动触发. 内置方法如下: __new__: 在__ini ...
- java 构造实例
Person父类 package com.oracle.demo03; public class Person { private String name; private int age; //需要 ...
- [RN] 解决小米手机安装应用报:INSTALL_FAILED_USER_RESTRICTED问题
解决小米手机安装应用报:INSTALL_FAILED_USER_RESTRICTED问题 https://blog.csdn.net/u013023845/article/details/821082 ...
- Windows空间清理2
最近听说有同事因为电脑C盘不足,让别人重装电脑解决了,感觉有点意料之外又有点情理之中. 一方面居然有某些做技术的同事不知道要如何高效的清理自己的磁盘空间,要花一天时间重装系统.然后装软件.再配置各种开 ...