bert论文笔记
摘要
BERT是“Bidirectional Encoder Representations from Transformers"的简称,代表来自Transformer的双向编码表示。不同于其他的语言模型,它是使用transformer联合所有层的左右上下文来预训练的深度双向表示。在这个表示的基础上,只需要一个额外的输出层,就可以根据特定的任务对预训练的bert进行微调,无需对特定的任务进行大量模型结构的修改。
论文贡献:
1、论证了双向预训练对语言表征的重要性。BERT使用遮蔽语言模型来实现预训练的深层双向表示。而ELMO,是使用了一个由左到右和由右到左的独立训练语言模型的浅层连接。
2、预训练的表示消除了许多特定于任务的高度工程化的模型结构的需求,bert是第一个采用fine-tuning模式,优于许多特定于任务的结构的模型。
3、在消融研究中证明,模型的双向特征是重要的贡献。
2.相关工作
基于特征的方法(feature-based)
Feature-based指利用语言模型结果,将其作为额外的特征,引入到原任务模型中。
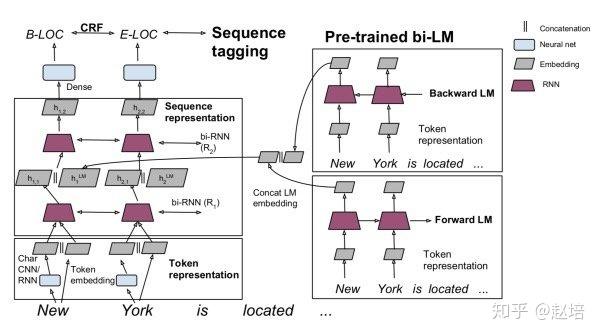
如图所示:左边是序列标注模型,即task-specific model,右边是双向的语言模型,并将语言模型结果与第一层的rnn输出进行concate操作,即特征增强。
feature-based方法分为两步:
1、先在大的语料上进行无监督的训练语言模型,得到语言模型
2、然后构造特定任务模型,如序列标注模型,使用任务语料训练任务模型,将语言模型的参数固定,任务语料经过语言模型得到的LM Embedding作为任务模型的额外特征。
基于微调的方法(fine-tuning)
Fine-tuning就是在已经训练好的语言模型基础上,加入少量具体任务的参数,例如对于分类问题在语言模型基础上增加一层softmax网络,然后在新的语料上重新进行训练,从而fine-tuning参数。
fine-tuning方法步骤:
1、先在大的语料上进行无监督的训练语言模型,得到语言模型 2、在语言模型基础上增加少量神经网络层来完成具体任务,如序列标注,分类,然后使用有标记的任务语料有监督的训练模型,这个过程语言模型的参数并不固定,依然是可以训练的。
从有监督的数据中迁移学习
迁移学习:当前任务的数据很少,如何利于预训练的模型来完成该任务。方法有许多种:如可以直接使用最后的输出来做下游任务,也可以直接使用某一层网络,或者使用fine-tuning方式。 总之,迁移学习关心的问题是:什么是“知识”以及如何更好的运用之前得到的“知识”。方法和手段就很多,fine-tuning只是其中的一种手段。----迁移学习与fine-tuning有什么区别?
3.BERT
这部分介绍bert的细节和实现,首先介绍BERT模型的结构和输入表示,接下来是论文核心创新-预训练任务,预训练和fine-tuning紧随其后,最后是BERT和GPT的区别。
3.1模型结构
BERT的结构基于多层双向的Transformer编码器。
表示层的数量(即Transformer块)为L, 隐藏尺寸为H,自注意头的个数为A,在所有例子中,将前馈/过滤器的大小设置为4H,即H=768时是3072,【为什么是4倍,H为什么是768】
bert两个模型大小结果为:
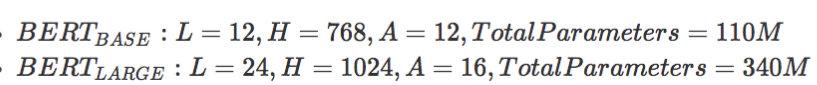
3.2输入表示
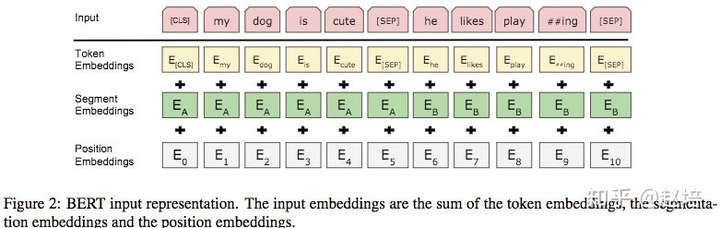
输入可以是单个文本句子或者一对句子,一个输入序列中,输入嵌入是词嵌入(token embedding)、句子嵌入(segment emebdding)和位置嵌入(position embedding)的总和。
1、词嵌入使用WordPiece嵌入。一文读懂BERT中的WordPiece
2、使用学习到的位置嵌入,支持的序列长度最长可达512个标记。[预训练的?]
3、对于输入序列在开始加一个特殊的分类嵌入([CLS]),这个特殊的标记的最终的输出作为分类任务中的句向量,而对于非分类任务,这个标记的输出可以忽略。
4、 句子打包在一起形成输入序列,使用两种方法区分这些句子。方法一、两个句子之间使用特殊标记([SEP])将它们分开;方法二、给第一个句子的每个token添加一个可训练的句子A嵌入,给第二个句子的每个token添加可训练的句子B的嵌入。 5、对于单句的输入,使用句子A的嵌入。
3.3 预训练任务
预训练时使用mask 语言模型和Next Sentence Prediction多任务训练方式。
3.3.1mask 语言模型
直观上,深层双向建模比单向或者双向的浅层连接效果好,但是,在标准的条件语言模型只能从左到右或者从右到左进行训练,因为在深层双向建模过程中会使得每个单词在多层上下文中间接的“看到自己”.
为了训练深层双向表示,按一定比例对输入标记随机mask,然后仅预测这些被mask的标记。 在实验中,每个序列随机mask 15%的标记, 并让模型预测这些被mask的标记。
这里有两个缺点:第一个缺点是,在预训练和微调之间造成了不匹配,因为在微调时不会出现[MASK]标记。所以,并不是总是用[MASK]标记替换被选择的单词,而是,训练数据随机选择15%进行标记,在这15%的候选标记中,80%使用[MASK]替换被选择的单词,10%用一个随机单词替换被选择单词, 10%保持被选择单词不变。

.
这样做的效果就是Transformer不知道它将要预测哪些单词,或者哪些单词已经被随机替换,因此它被迫保持每个输入标记的上下文的表示。另外,因为随机替换只发生在1.5%的标记,这似乎不会损害模型的语言理解能力。 第二个缺点,使用Transformer的每批数据只有15%的标记被预测,这意味着模型需要更多的预训练步骤进行收敛。论文证明,Transformer比从左到右的模型稍微慢一些,但是效果远远超过了它增加的预训练模型的成本。
3.3.2 下一句预测
在许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是建立在理解两个文本句子之间的关系基础上,这不是语言建模直接可以捕获到的。为了训练一个理解句子关系的模型,我们预训练了一个下一句预测的二分类任务,这个任务就是为每个训练前的例子选择句子A和句子B,50%的情况下B是真的在A后面的下一个句子,50%的情况是来自语料库随机句子。 这个任务的增加对句子级别的任务非常有益。
3.4预训练过程
为了生成每个训练输入序列,我们从语料库中采样两段文本,称其为“句子”。第一个句子添加A嵌入,第二个句子添加B嵌入,50%的情况下B是A后面的下一句,50%的情况下它是随机选取的一个句子,这是为“下一句预测"任务所做的。两句话合起来的长度要小于等于512。语言模型的mask过程是在使用WordPiece序列化句子后,以均匀的15%的概率遮蔽标记,不考虑部分词片的影响。 论文中使用batch size为256(256 * 512 = 128000个标记)的批大小进行训练,使用Adam优化算法并设置学习率为1e-4, \beta1 = 0.9, \beta2 = 0.999, L2权重衰减是0.01,并且前10000步学习率热身,然后线性衰减,drop值设置为0.1, 使用gelu激活函数。 训练损失是mask 语言模型和下一句预测似然值的平均值。
3.5fine-tuning
对于分类任务,bert使用最后[CLS]的embedding作为整体的句向量,进行分类。
在fine-tuning过程中,除了训练次数、batch size和学习率外,大多数模型超参数与预训练相同。
另外大的数据集对超参数的选择敏感性远远低于小数据集。
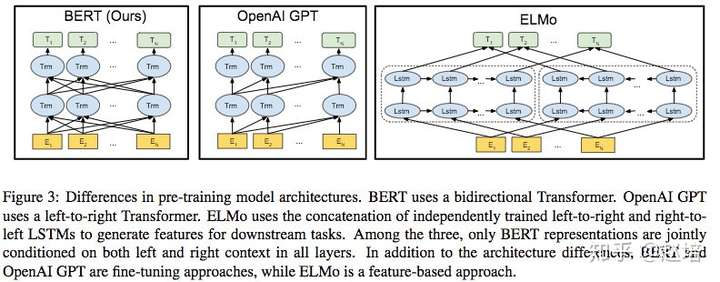
3.6bert与GPT的对比
主要的区别就是BERT使用了双向语言模型,并使用mask语言模型和下一句预测联合训练。
4、实验
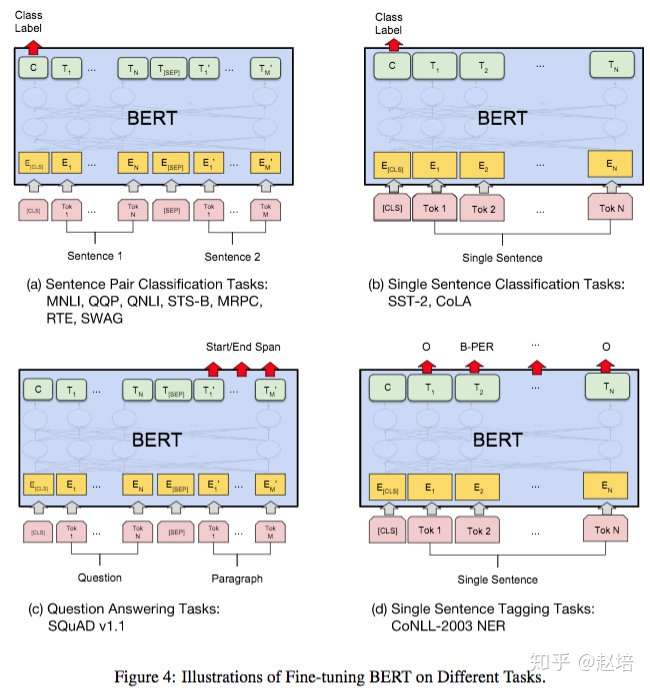
4 消融试验
4.1预训练任务的影响
bert的通过mask语言模型预训练的深层双向模型是最重要的改进。为了验证这个,论文做了两个模型:
1、No NSP:模型使用mask语言模型但是没有预测下一句话
2、LTR&No NSP:模型使用从左到右的语言模型,而不是mask语言模型,另外该模型也未经预测下一句话任务的预训练。
结果显示除去NSP任务对句级别任务造成了显著伤害。
在No NSP和LTR上,LTR在所有任务上都比No NSP表现的差,在MRPC和SQuAD上降的特别厉害,对于SQuAD来说,很明显LTR模型在区间和标记预测方面表现很差,因为标记级别的隐藏状态没有右侧上下文。 可以向ELMO那样独立训练LTR和RTL模型,并将每个标记表示为两个模型表示的连接,但是(a)这是单个双向模型参数的两倍(b)对像QA这样的任务来说不直观,因为RTL模型无法以问题为条件确定答案(c)这比深层双向模型的功能要弱得多,因为深层双向模型可以选择使用左上下文或有上下文
4.2模型大小影响
模型大小将持续提升在大型任务上的表现,如果模型得到了足够预训练训练,那么将模型扩展到极端的规模也可以在非常小的任务上带来巨大的改进。
4.3使用bert基于特征的方法
与feature-based相比,fine-tuning方式效果更好。
参考
[1] ref="https://github.com/yuanxiaosc/BERT_Paper_Chinese_Translation">BERTPaperChinese_Translation.
[2] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding.
[3] BERT模型及fine-tuning.
[4] 迁移学习与fine-tuning有什么区别?
bert论文笔记的更多相关文章
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
随机推荐
- COGS 2687 讨厌整除的小明
二次联通门 : COGS 2687 讨厌整除的小明 /* cogs 2687 讨厌整除的小明 打表出奇迹.. 考场时看了一下样例就感觉有非常鬼畜的做法.. 手搞几组数据做法就出来了... 2333 * ...
- lixuxmint系统定制与配置(3)-字体
小书匠Linux 有些系统自带的字体实在太难看了,看起来不清晰,不明确,有一个好的字体,可以带来好心情,并提高工作与效率. 1.常用中文字体 文泉驿微黑,微软雅黑,思源黑体 2.字体安装 2.1检查已 ...
- 复旦高等代数 I(15级)每周一题
[问题2015A01] 证明: 第三类分块初等变换是若干个第三类初等变换的复合. 特别地, 第三类分块初等变换不改变行列式的值. [问题2015A02] 设 $n\,(n\geq 2)$ 阶方阵 ...
- Jmeter 5.1实现图片上传接口测试
背景: 项目过程中需要抓取接口进行图片上传的接口测试,所有上传功能大同小异,无非就是参数内容不同,此处记录一下,为其他上传做一些参考 1.通过fiddler抓取到的参数如下: Content-Disp ...
- 「雅礼集训 2018 Day2」农民
传送门 Description 「搞 OI 不如种田.」 小 D 在家种了一棵二叉树,第 ii 个结点的权值为 \(a_i\). 小 D 为自己种的树买了肥料,每天给树施肥. 可是几天后,小 D 却 ...
- kubernetes入门学习系列
一.kubernetes基础概念 初识kubernetes kubernetes相关概念 二.kubernets架构和组件 kubernetes架构 kubernetes单Master架构 kuber ...
- Linux中的定时自动执行功能(at,crontab)
Linux中的定时自动执行功能(at,crontab) 概念 在Linux系统中,提供了两种提前对工作进行安排的方式 at 只执行一次 crontab 周期性重复执行 通过对这两个工具的应用可以让我们 ...
- sysfs 控制gpio
按照下面的命令点亮及熄灭LED pi@raspberrypi:/sys/class/gpio $echo 26 > exportpi@raspberrypi:/sys/class/gpio $ ...
- Confluence 实现公司wiki【转】
Confluence是一个企业级的Wiki软件,可用于在企业.部门.团队内部进行信息共享和协同编辑一.安装过程1 安装并配置mysql [root@vm1 ~]# /etc/my.cnf charac ...
- (信贷风控八)行为评分卡模型(B卡)的介绍
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...