Presto: SQL on Everything
Presto是FB开源出来的实时分析引擎,可以federated的从多种数据源去读取数据,做联合查询,支持实时Interactive BI或bath ETL的需求


从其问题域来看,基本是和spark是重合的,那么两者区别是什么?
https://stackoverflow.com/questions/50014017/why-presto-is-faster-than-spark-sql


这两个答案说的比较清楚,
所以可以看出,Presto并没有什么创新的东西,对于Spark而言,主要是做减法,降低overhead,提升性能
所以Presto更偏实时一些,更适用于MPP的场景,较为简单的SQL
Presto的架构和查询流程,都是典型的MPP方式
特点是,执行都是pipeline的方式,所有中间数据和状态都放在内存中,这样比spark那样落盘,再读出的方式要快
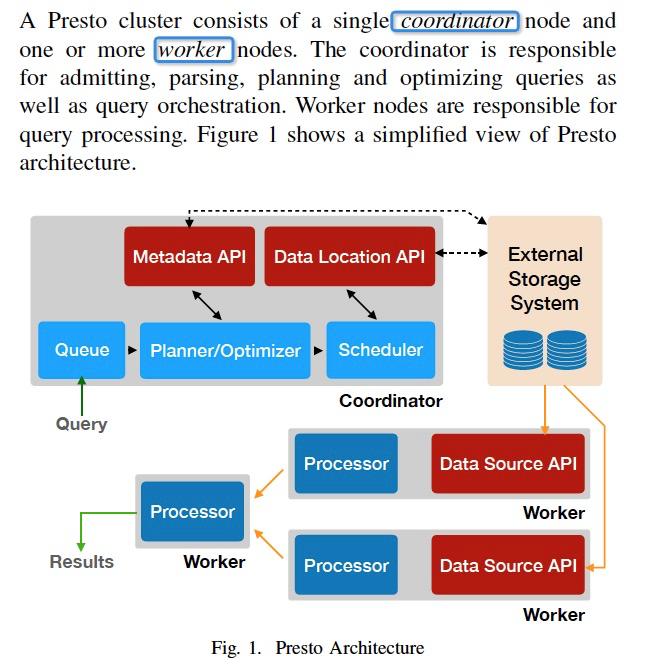

查询过程,
首先是parsing,并形成逻辑计划,
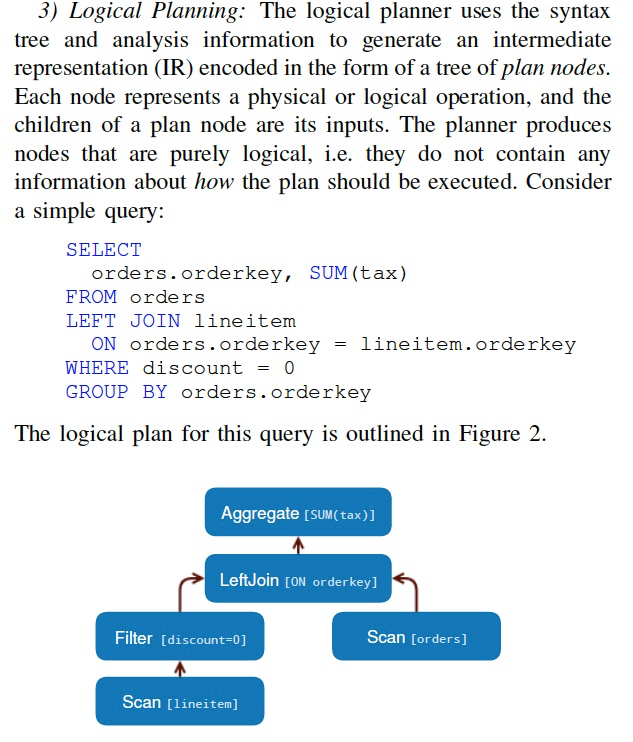
接着是查询优化,和生成物理执行计划
Presto的查询优化没啥创新的
需要注意的是,
首先他也有stage的概念,和spark一样,stage里面可以直接local完成的,所以上面的逻辑计划,
被分成5个stage,stage之间需要shuffle,做过流系统的都知道,一旦shuffle,性能就不行了,对cpu,网络,buffer的消耗都很大
Inter-node,节点间的并行,通过在不同的worker上并行相同的task,处理不同的数据split

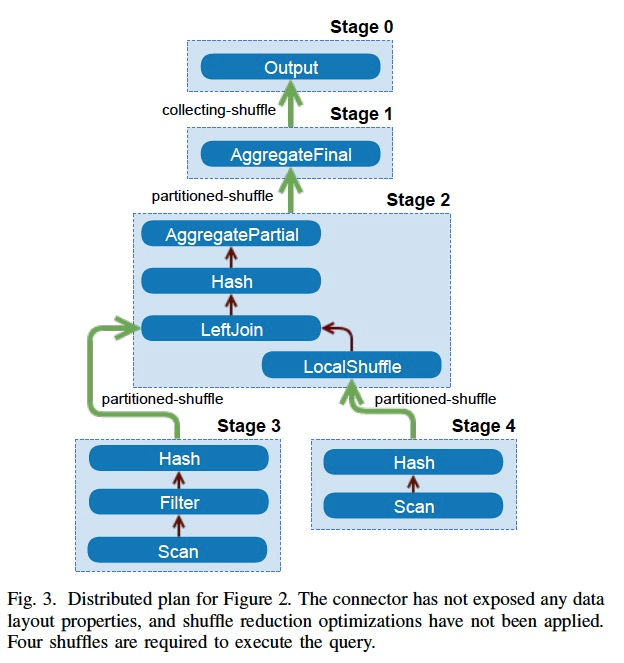
所以思路一定是要尽量减少shuffle,思路也比较直观,比如做join,如果相同join id的数据都在一个节点,就不用shuffle
这个就叫,Data Layout Properties,数据分布

还有,Node Properties,根据node的属性来,减少不必要的shuffle,合并stage


再者,看看Intra-node,节点内的并行,通过thread,这个应该是Presto的特点,可以大大提升查询性能
右图可以看出,在pipeline1,pipeline2中加了很多并发的thread来并行的做

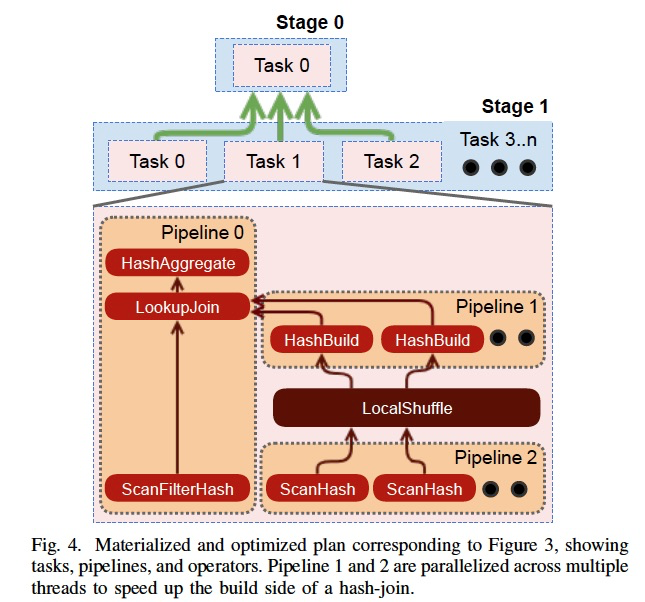
计划生成完后,就是调度,
Coordinator将plan stages以可执行tasks,分发到各个workers上去,task一个执行单元
Task中又包含很多pipelines,pipeline由operators组成

调度分为3种,
Stage调度,可以all in,或分阶段
all in,延迟会小,但会耗费更多的资源

Task Scheduling,

Split Scheduling
最终还要给各个leaf stage分配splits,因为leaf stage必须要被分配splits后才能启动
presto这里的优化,先只会enumerate一小批的splits,分配给各个task,不会一下把所有的splits都捞出来分配,优点下面也说了


调度完,最后就是执行
Query Execution
开始执行,driver loop开始pass split
这里产生page的概念,source从split读出的结构就是pages,Operator的输入输出也是pages,类似spark中的RDD
从右图可以看出,page是一种以column方式组织的结构,便于AP


第二步是shuffle,
presto是延迟优先的,所以shuffle的中间结果不能落盘,放在memory buffer里面
其他worker通过Http Long-Polling的方式来拉数据
同时要监控,output和input的buffer的使用情况,来调整并发,避免内存占用过高
output buffer太大了,让写并发降一些,如果input buffer太大,让读并发降些,这样也会触发前面的写并发的反压

最后是把结果写出,
写吞吐如果要高,多开写并发,但是写并发高,对存储的要求就比较高,
比如对于S3,每个并发都需要写一个文件,会导致很多小文件,查询起来就很麻烦
Presto采用的是adaptive来决定写并发

Presto: SQL on Everything的更多相关文章
- Hive sql和Presto sql的一些对比
最近由于工作上和生活上的一些事儿好久没来博客园了,但是写博客的习惯还是得坚持,新的一年需要更加努力,困知勉行,终身学习,每天都保持空杯心态.废话不说,写一些最近使用到的Presto SQL和Hive ...
- facebook Presto SQL分析引擎——本质上和spark无异,分解stage,task,MR计算
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,适用于交互式分析查询,可支持众多的数据源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的接口开发数据源连接 ...
- 探究Presto SQL引擎(3)-代码生成
vivo 互联网服务器团队- Shuai Guangying 探究Presto SQL引擎 系列:第1篇<探究Presto SQL引擎(1)-巧用Antlr>介绍了Antlr的基本用法 ...
- 探究Presto SQL引擎(4)-统计计数
作者:vivo互联网用户运营开发团队 - Shuai Guangying 本篇文章介绍了统计计数的基本原理以及Presto的实现思路,精确统计和近似统计的细节及各种优缺点,并给出了统计计数在具体业务 ...
- 探究Presto SQL引擎(1)-巧用Antlr
一.背景 自2014年大数据首次写入政府工作报告,大数据已经发展7年.大数据的类型也从交易数据延伸到交互数据与传感数据.数据规模也到达了PB级别. 大数据的规模大到对数据的获取.存储.管理.分析超出了 ...
- presto的动态化应用(一):presto节点的横向扩展与伸缩
一.presto动态化概述 近年来,基于hadoop的sql框架层出不穷,presto也是其中的一员.从2012年发展至今,依然保持年轻的活力(版本迭代依然很快),presto的相关介绍,我们就不赘述 ...
- Presto 学习
Presto 基础知识与概念学习可以参考这些博客: presto 0.166概述 https://www.cnblogs.com/sorco/p/7060166.html Presto学习-prest ...
- presto调研和json解析函数的使用
presto简单介绍 presto是一个分布式的sql交互式查询引擎.可以达到hive查询效率的5到10倍.支持多种数据源的秒级查询. presto是基于内存查询的,这也是它为什么查询快的原因.除了基 ...
- sqlalchemy presto 时间比较
大数据统计时,需要计算开仓订单减掉经纪商时间差,等于n 小时 或 星期几的订单. presto sql语句如下: select sum(profit) from t_table where open_ ...
随机推荐
- IOS之NSString NSData char 相互转换
转自:http://blog.csdn.net/xialibing103/article/details/8513312 1.NSString转化为UNICODE String:(NSString*) ...
- AI涉及到数学的一些面试题汇总
[LeetCode] Maximum Product Subarray的4种解法 leetcode每日解题思路 221 Maximal Square LeetCode:Subsets I II (2) ...
- 浅谈Python设计模式 - 享元模式
声明:本系列文章主要参考<精通Python设计模式>一书,并且参考一些资料,结合自己的一些看法来总结而来. 享元模式: 享元模式是一种用于解决资源和性能压力时会使用到的设计模式,它的核心思 ...
- Unity 渲染教程(四):第一个光源
将法线从物体空间转换到世界空间. 使用方向光. 计算漫反射和镜面高光反射. 实现能量守恒. 使用金属的工作流程. 利用Unity的基于物理规则渲染的算法. 这是关于渲染基础的系列教程的第四部分.前面的 ...
- Codeforces B. Bad Luck Island(概率dp)
题目描述: Bad Luck Island time limit per test 2 seconds memory limit per test 256 megabytes input standa ...
- php中的设计模式---工厂模式及单例模式
这两个练习放在一起处理. 在python中,这些模式都有的. 要记得三大类模式:创建型,结构型,行为型. NotFoundException.php <?php namespace Bookst ...
- js动画--链式运动
前面几节我们只是讲述了一种运动,这节课我将讲述链式运动:就以一个动作接着一个动作完成. 对于这个实现,我们只需要改变一下就可以实现了,设置一个回调函数. var timer; window.onloa ...
- oracle-shell备份
获取PAH写入脚本 cat /home/oracle/.bash_profile 编写脚本oadbbak.sh PATH backuptime=`date +%Y%m%d%H%M%S` exp use ...
- js不常用,但很实用的功能
=============== 通知: 博主已迁至<掘金>码字,博客园可能以后不再更新,掘金地址:https://juejin.im/post/5a1a6a6551882534af25a8 ...
- 利用python jieba库统计政府工作报告词频
1.安装jieba库 舍友帮装的,我也不会( ╯□╰ ) 2.上网寻找政府工作报告 3.参照课本三国演义词频统计代码编写 import jieba txt = open("D:\政府工作报告 ...