【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址:
baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc

机器之心
---------------------------------------------------------------------------------------------
上周,DeepMind在 Nature 发表论文,用 AI 复现大脑的导航功能。
今天,DeepMind 在 Nature Neuroscience 发表新论文,该研究中他们根据神经科学中的多巴胺学习模型的局限,强调了多巴胺在大脑最重要的智能区域即前额叶皮质发挥的整体作用,并据此提出了一种新型的元强化学习证明。DeepMind 期望该研究能推动神经科学自 AI 研究的启发。
近期,AI 系统已经掌握多种视频游戏(例如 Atari 的经典游戏 Breakout 和 Pong)的玩法。虽然其表现令人印象深刻,但 AI 仍然依赖于数千小时的游戏经验才能达到并超越人类玩家的表现。而人类仅需数分钟就可以掌握视频游戏的基本玩法。
对大脑何以能在如此少的经验下学到那么多这一问题的探究推动了元学习(meta-learning)或「学习如何学习」理论的发展。人们认为我们是在两个时间尺度上学习的:短期学习聚焦于学习特定实例,长期学习主要学习抽象技能或用于完成任务的规则。正是该组合帮助我们高效地学习,并在新任务上快速灵活地应用知识。在 AI 系统中重新创建这种元学习结构,即元强化学习(meta-RL),已被证明在推动快速、单次的智能体学习中卓有成效(参见 DeepMind 论文《Learning to reinforcement learn》以及 OpenAI 的相关研究《RL2: Fast Reinforcement Learning via Slow Reinforcement Learning》)。然而,大脑中允许该过程的特定机制目前在神经科学中基本未得到解释。
在 DeepMind 刚发表在 Nature Neuroscience 的新论文《Prefrontal cortex as a meta-reinforcement learning system》中,研究者使用了 AI 研究中开发出来的元强化学习框架来探索大脑中的多巴胺所发挥的帮助学习的作用。多巴胺是人们所熟悉的大脑快乐信号,通常被认为是 AI 强化学习算法中使用的奖励预测误差信号的类比。这些系统学习通过反复试错来行动,这是由奖励推动的。DeepMind 指出多巴胺的作用不仅仅是使用奖励来学习过去动作的价值,它发挥的是整体作用,特别是在前额叶区域,它允许我们高效、快速和灵活地在新任务上学习。
研究者通过虚拟重建神经科学领域中的六个元强化学习实验来测试该理论,每个实验需要一个智能体使用相同的基础原则或技能集(但在某些维度上有所变化)来执行任务。研究者使用标准的深度强化学习技术(代表多巴胺)训练了一个循环神经网络(代表前额叶),然后对比该循环网络的活动动态和神经科学实验之前研究成果的真实数据。循环网络是很好的元学习代理,因为它们可以内化过去的动作和观察,然后在多种任务训练中利用那些经验。
DeepMind 重建的一个实验是 Harlow 实验,这是一个 1940 年代出现的心理测试,用于探索元学习的概念。在原始测试中,向一组猴子展示两个不熟悉的物体并让它们进行选择,只有一个物体能带来食物奖励。这两个物体被展示了 6 次,每次展示中两个物体的左右位置都是随机的,因此猴子必须学会哪个物体能带来食物奖励。然后,它们被展示了两个全新的物体,这时也是只有一个能带来食物奖励。通过该训练过程,猴子发展出了一种策略来选择奖励相关的物体:它学会了在第一次选择时进行随机选择,然后基于奖励反馈选择特定的物体,而不是左边或右边的位置。该实验证明了猴子可以内化任务的基础原则,并学习一种抽象的规则结构,即学会学习。
DeepMind 使用虚拟计算机屏幕和随机选择的图像模拟了一个类似的测试,他们发现「meta-RL agent」的学习方式与 Harlow 实验中的动物非常相似,这种相似性即使在展示完全没见过的全新图像时也会存在。

在 DeepMind 模拟的 Harlow 实验中,智能体必须将关注点移向它认为与奖励相关的目标。
实际上,DeepMind 研究团队发现 meta-RL 智能体能 快速学习适应 有 不同规则和结构的大量任务。而且由于该循环神经网络学习了如何适应多种任务,因此它还学到了如何高效学习的通用法则。
重要的是,研究者发现大多数学习发生在循环网络中,这也支持了 DeepMind 的假设,即多巴胺在元学习过程中扮演的角色比以前认为的更重要。传统观点认为,多巴胺加强前额叶系统中的突触联系,从而强化特定的行为。在 AI 中,这一现象意味着,随着类似多巴胺的奖励信号学习到解决任务的正确方式,它们会调整神经网络中的人工突触权重。然而在一般的实验中,神经网络中的权重是固定的,这意味着权重在学习过程中不能进行调整。
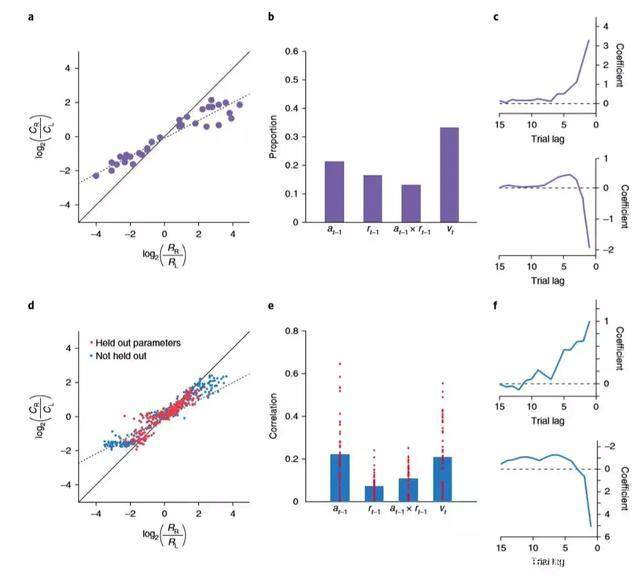
模拟循环网络中编码动作和奖励历史的独立单元。
因此,DeepMind 研究团队提出了 meta-RL 智能体,它能解决并适应新的任务。这种智能体表明类似多巴胺的奖励不仅用于调整权重,它们还传输和编码关于抽象任务和规则结构的重要信息,使得智能体能够更快适应新任务。
长期以来,神经科学家们发现前额叶皮质中有类似的神经激活模式,这种模式适应速度快且灵活,但他们一直找不到一个合理的解释。前额叶皮质不依赖缓慢的突触权重变化来学习规则结构,而是使用在多巴胺中直接编码的基于模型的抽象信息,这个思路为其多功能性提供了更合理的解释。
为了证明导致人工智能元强化学习的关键因素也存在于大脑之中,DeepMind 研究者提出了一个理论。该理论不仅符合多巴胺和前额叶皮质的现有知识,而且也解释了神经科学和心理学的一系列神秘发现。尤其是,该理论揭示了大脑中如何出现结构化的、基于模型的学习,多巴胺本身为什么包含基于模型的信息,以及前额叶皮质的神经元如何适应与学习相关的信号。对人工智能的深入了解可以帮助解释神经科学和心理学的发现,这也强调了领域之间可以互相提供价值。放眼未来,他们期望在强化学习智能体中设计新的学习模型时,可以从特定的脑回路组织中获得许多逆向思维的益处。
论文:Prefrontal cortex as a meta-reinforcement learning system

论文地址:https://www.nature.com/articles/s41593-018-0147-8
预印论文地址:https://www.biorxiv.org/content/biorxiv/early/2018/04/06/295964.full.pdf
摘要:过去 20 年来,对基于奖励学习的神经科学研究已经收敛到了一类规范模型上,其中神经递质多巴胺通过调整神经元之间突触连接的强度在情景、动作和奖励之间建立关联。然而,近期出现的许多研究向这个标准模型提出了挑战。我们现在利用人工智能中的近期进展来引入一种新的基于奖励的学习理论。这里,多巴胺系统训练了另一个大脑区域——前额叶,来将其作为独立的学习系统。这个新的研究视角适应了启发标准模型的那些发现,并且还能很好地处理宽泛的经验观察,为未来的研究提供全新的基础。
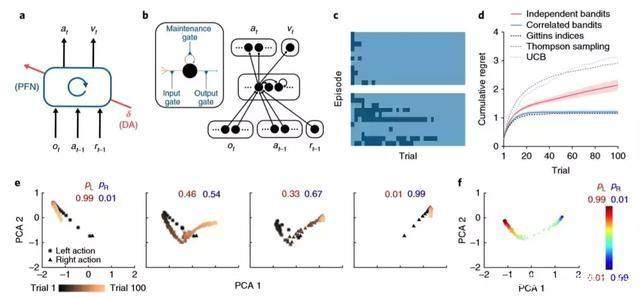
上图展示了 meta-RL 在多个 episode 上学习如何高效地学习每一个 episode。
其中 a 为智能体架构、b 为 DeepMind 模拟中实现的具体神经网络结构、c 为试验模型在带有伯努利奖励参数的摇臂赌博机问题上的行为、d 为 meta-RL 网络在摇臂赌博机问题上独立训练的性能,最后的 e 为循环神经网络激活模式在独立实验中的进化可视化。
------------------------------------------------------------------------
【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法的更多相关文章
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- (待续)【转载】 DeepMind发Nature子刊:通过元强化学习重新理解多巴胺
原文地址: http://www.dataguru.cn/article-13548-1.html -------------------------------------------------- ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 【转载】 强化学习(九)Deep Q-Learning进阶之Nature DQN
原文地址: https://www.cnblogs.com/pinard/p/9756075.html ------------------------------------------------ ...
- Hinton“深度学习之父”和“神经网络先驱”,新论文Capsule将推翻自己积累了30年的学术成果时
Hinton“深度学习之父”和“神经网络先驱”,新论文Capsule将推翻自己积累了30年的学术成果时 在论文中,Capsule被Hinton大神定义为这样一组神经元:其活动向量所表示的是特定实体类型 ...
- Mean Shift Tracking: 2000-2012回顾 (新论文更新)
参考: Mean Shift Tracking: 2000-2012回顾 (新论文更新) ECCV2016要来了,估计深度学习要一统天下了吧
随机推荐
- 网站检测空链、死链工具(Xenu)
网站常用检测空链.死链工具,Xenu是很小但是功能强大的检查网站404链接的软件,支持多线程,无需安装可直接打开使用.步骤如下: 网站的链接一般都成千上万,如果存在大量的空链接将大大的影响用户体验,怎 ...
- Caused by: java.lang.IllegalStateException: Ambiguous mapping found
Caused by: java.lang.IllegalStateException: Ambiguous mapping found. Cannot map ‘myCockpitMgrControl ...
- [Exception] java.util.MissingFormatArgumentException
java.util.MissingFormatArgumentException: Format specifier 's' at java.util.Formatter.format(Formatt ...
- flask处理数据,页面实时刷新展示
背景: 后端 flask(python)处理数据,页面实时刷新,类似于打包页面的动态展示,展示效果如图: 代码如下: 前端主要使用以下循环处理, 2--- 2秒刷新一次 {% if 0 == stop ...
- Handling skewed data---trading off precision& recall
preision与recall之间的权衡 依然是cancer prediction的例子,预测为cancer时,y=1;一般来说做为logistic regression我们是当hθ(x)>=0 ...
- django 时间格式(全局修改,不用过滤器)
百度了一圈,很没创意的用过滤器,前端每次显示时间表格都要用过滤器,这种挺烦的.隐约记得以前见过没有用过滤器的.换google https://stackoverflow.com/questions/5 ...
- [CodeForces - 906D] Power Tower——扩展欧拉定理
题意 给你 $n$ 个 $w_i$ 和一个数 $p$,$q$个询问,每次询问一个区间 $[l,r] $,求 $w_l ^{w_{l+1}^{{\vdots}^{w_r}}} \ \% p$ 分析 由扩 ...
- RabbitMQ交换机、RabbitMQ整合springCloud
目标 1.交换机 2.RabbitMQ整合springCloud 交换机 蓝色区域===生产者 红色区域===Server:又称Broker,接受客户端的连接,实现AMQP实体服务 绿色区域===消费 ...
- Processing中和值域相关的函数
今天在群里有人问了个问题:请教下啊,群里能有高手讲讲norm(), lerp(), map()么,英文的实在是没看懂呀?鉴于很多人初学Processing都没弄明白这3个函数的用法,我这里简单介绍一下 ...
- PHP查询oracle数据显示乱码问题
1.Linux下 执行前脚本前先执行一下命令export NLS_LANG="SIMPLIFIED CHINESE_CHINA.AL32UTF8" 2.Windows下在代码里添加 ...