python多线程爬取世纪佳缘女生资料并简单数据分析
一. 目标
作为一只万年单身狗,一直很好奇女生找对象的时候都在想啥呢,这事也不好意思直接问身边的女生,不然别人还以为你要跟她表白啥的,况且工科出身的自己本来接触的女生就少,即使是挨个问遍,样本量也太少,毕竟每个人的标准都会有差异的。这时候想到婚恋网站,上面不就有现成的数据吗,刚好最近也在学习爬虫,如果能用爬虫把数据爬取下来,既练习了爬虫技术,又获得了想要的数据,一举两得。不如说干就干。
从接触爬虫以来,也爬过几十个网站,虽说是入门练习,没找那种数据价值很高,反爬比较严重的网站,但也有不少数据价值不错的网站,比如豆瓣电影,简书,汽车之家,房天下等,这些网站基本上也没动用什么高级一点的反爬技术,然而,在爬取世纪佳缘的时候就有点坑了,整个网站页面大部分都是js渲染出来的,而且ajax数据请求接口还挖空心思地给你玩声东击西手段,我寻思着这网站数据价值也不至于那么大,这么藏着掖着,要么是后台开发小哥闲着没事在修炼反爬仙丹,要么是事出反常必有妖,由于之前注册了个三无账号,资料都是乱写的,居然也会收到大量需要花钱才能看到的情书,所以猜测这数据之中怕是藏着什么猫腻,于是乎,除了抓取女生资料外,又多了个目标:看看数据中藏了什么秘密。
!
二. 网页分析
在世纪佳缘主页,有个搜索入口,可以根据条件搜索女生数据。本次选取的是湖南省年龄在20-35岁,身高153-170cm的女生为爬取对象。
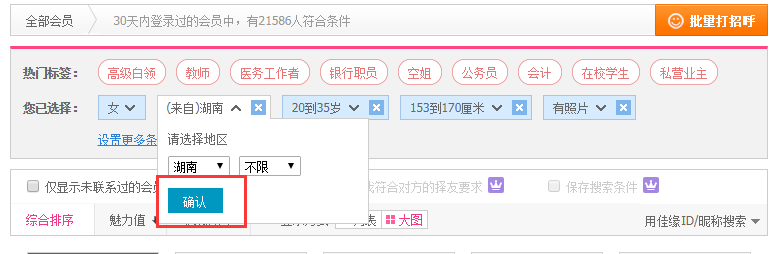
条件设置好以后,点击确定就可以看到发送了一条带有搜索条件参数的get请求

然而,当你以为这就能获取到搜索结果,那就大错特错了,这个请求只是一个障眼法。
以下是一大段废话,是我寻找真实请求接口的时候爬过的坑,在这里记录一下,直接看结果请跳到这里
我们用requests发送一个同样的请求试试,看看返回来的是啥
import requests
URL = "http://search.jiayuan.com/v2/index.php?key=&sex=f&stc=1:43,2:20.35,3:153.170,23:1&sn=default&sv=1&p=1&pt=864&ft=off&f=select&mt=u"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
resp = requests.get(URL, headers=HEADERS)
with open("search.html", "w", encoding="utf8") as fp:
fp.write(resp.content.decode())
我们把返回结果保存在search.html文件中,在浏览器中打开这个html文件
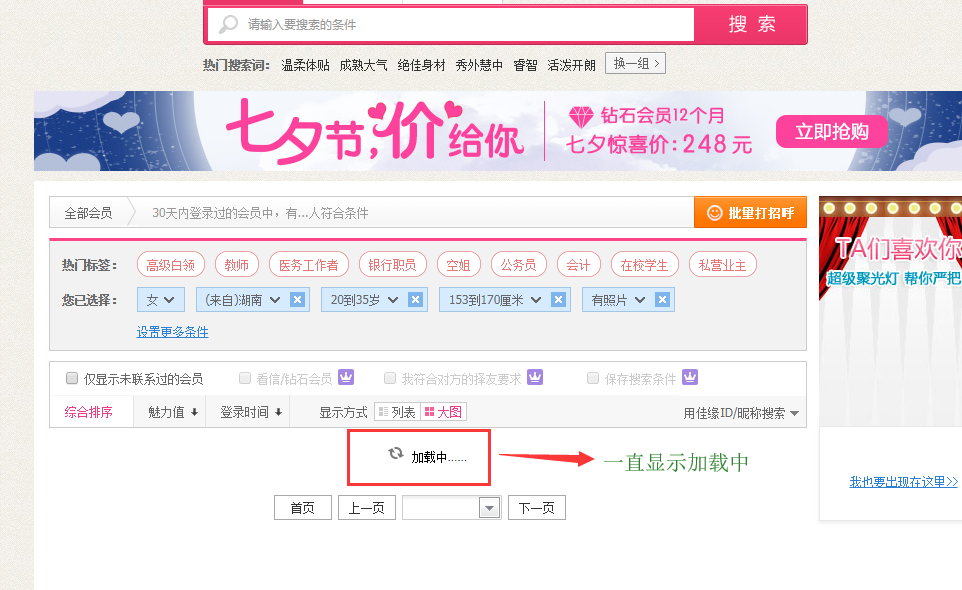
可以看到并没有返回我们想要的搜索结果的数据,这个页面停留几秒钟之后会弹出一个登录框,起先以为是需要登陆才能返回搜索结果,于是把cookie加上,但是仍然返回同样的结果。事实上,这个请求除了返回一些页面通用的HTML代码外,还返回一些css文件和js文件,其中有个js文件中定义了判断是否登录的函数

判断是否登录的大概思路是:在登陆页面输入账号密码登陆后,后台会告诉浏览器端设置一个名为PROFILE的cookie,所以判断是否登录就只需要通过js去获取这个cookie是否存在,如果存在则说明登陆过,不存在则说明没登陆。由于我们是通过requests发送的请求,直接把登陆后的cookie发送给后台服务器,虽然服务器端知道我们登陆了,但是返回来的js再次检查浏览器端的cookie时,并没有发现这个cookie(因为没有在浏览器设置)所以就不会进行后续的操作了,比如发送ajax请求获取用户信息等。
其实上面只是简单描述一下登陆检查思路,实际上世纪佳缘的登陆判断并没有这么简单,其中涉及到很多的js文件,而且这些文件相当一部分是通过document.write()的方式写入的,所以很多代码都很隐蔽,但是登陆检测不是我们的重点,我们只需要知道通过直接发送上述的get请求是获取不到我们想要的搜索结果的。
场面一度陷入了尴尬。。。
既然数据不是通过get直接返回的,数据总得有个返回方式吧,我猜肯定是js检测到用户登陆后,接着通过发送ajax请求获取到,然后再渲染到网页上的。那么接口在哪里呢?这时候首先想到的当然是抓包分析,大不了把所有请求都挨个分析一遍,肯定能揪出来。
打开fidller,把所有可疑请求挨个分析了一遍,依然没有找到我要的数据。可怕,居然能绕过抓包软件!!我虽然知道这是不大可能的事,但是此刻思维已经受到创伤。场面再次陷入尴尬。。。
既然抓包不行,那就硬着头皮再去读js源码吧,刚好是个机会来提升一下JavaScript功力。
从哪里读起呢?既然我想要知道搜索结果怎么获取的,那就先看看js是如何把搜索结果渲染出来的吧,或许从这里可以找到数据的源头。按F12,点到element栏,找到放搜索结果的div容器,然后在该元素设置一个断点,使该元素下的子元素被修改时程序运行终止(即当js试图往这个div容器渲染搜索结果列表的时候,程序中断):
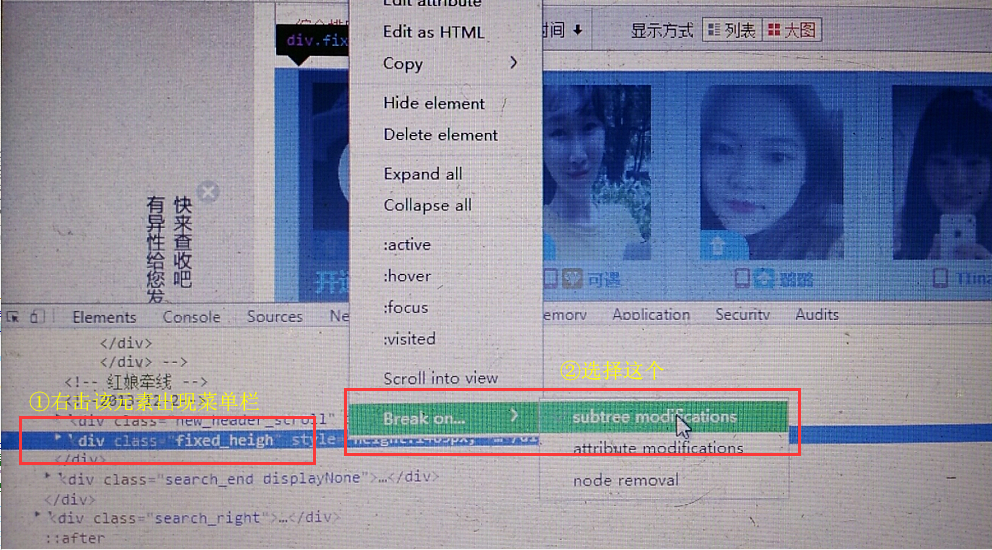
刷新网页,可以看到程序中断在jQuery.js文件中,点击运行按钮运行几步后,就进入了index_v2.js,再运行十几步后,我发现渲染出来第一条搜索结果,并且多次点击运行按钮后,有一个函数反复出现,有戏!
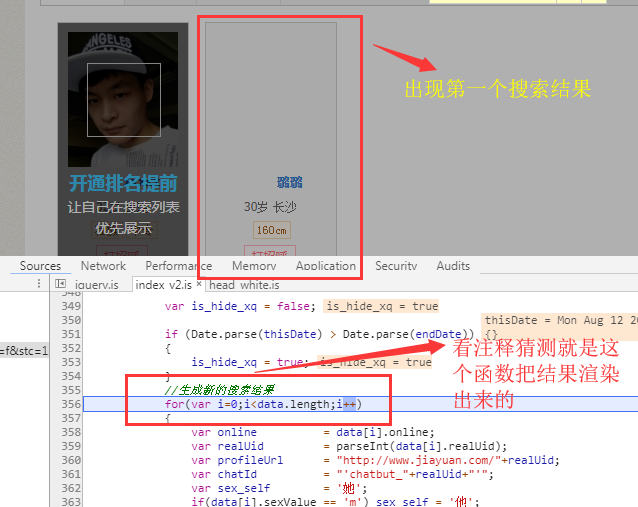
好了,知道了js是如何渲染搜索结果的,我们的目的还没达到,即数据是怎么请求到的。我推测既然数据是在这个js文件中渲染的,那么数据也应该是在同一个文件中获取洛,而且一般都是通过ajax方式获取,所以抱着试一试的 心态,我在这个js文件下按下ctr+f进行搜索,然后输入ajax,果然,出现了18条结果,其中第一条结果十分可疑
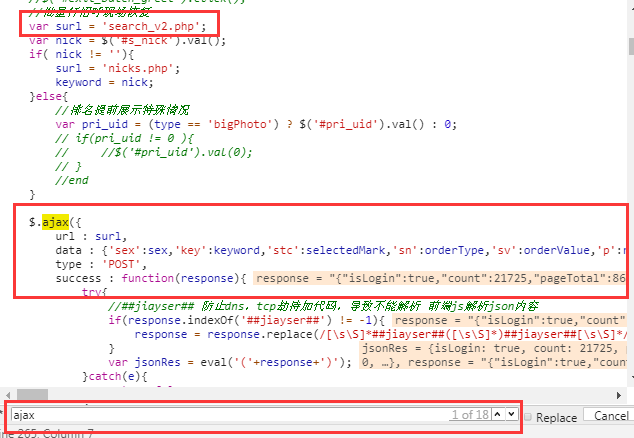
于是在ajax中的success的函数中设置一个断点,想看看返回response是什么,惊奇地发现,果然是我想要的数据,看来接口找到了。这不就是一个普通的ajax请求吗,赶紧再次用fidller抓包看看是不是我眼瞎漏掉了这个请求,果不其然,这个请求是抓到了的,此时想抠掉自己的双眼。。。哎,粗心导致浪费了大量时间,不过,分析js的过程中,还是学了不少新知识。

好了,找到了真正的数据请求接口,下面就来分析一下这个请求和服务器有哪些数据交互,先看向服务器发送了啥,点击WebForm看看post表单数据:

再来看看服务返回了啥:
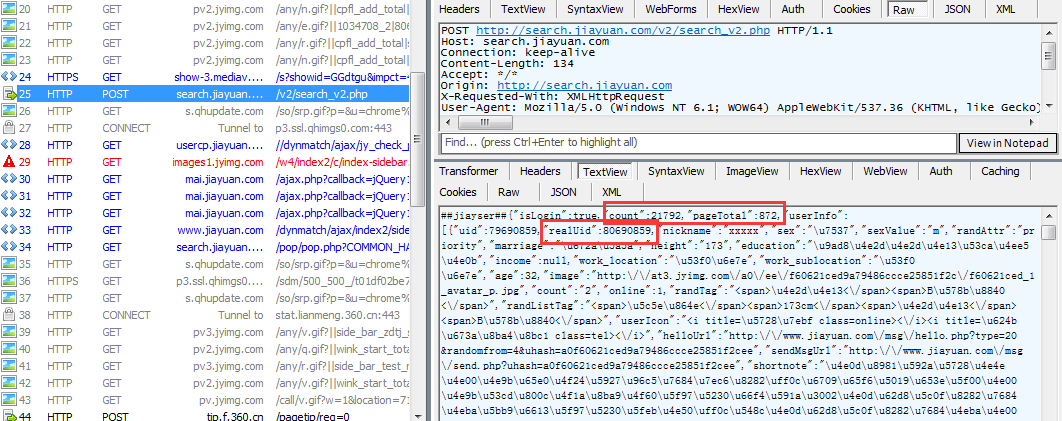
返回结果中可以看到count、pagetotal、realuid等字眼,分别表示搜索结果的总条数、总页面数、用户id号,其中用户id号就是我们下文要用到的构造用户详情页url的材料。在每条用户信息中我们还可以看到年龄,身高,教育程度等信息,但是这些信息不是我们需要的,除了搜索结果总条数,总页面数外,我们需要的只有用户id,有了用户id就可以构造详情页url,在详情页里面也有这些信息,到时候再去统一获取。这里可以看到返回21792条用户数据,但是这么多用户数据不是一次返回的,而是按页返回的,每页返回23条,所以我们需要一页一页的爬取这些用户的id号。
三. 开始爬虫
本次使用的是requests库+多线程的方式,python多线程在多核CPU下被说成是鸡肋,不过在爬虫这种I/O密集型的应用场合还是有用武之地的,我们把爬取结果以多行json数据的形式保存在文件中。
我们先来整理一下爬虫思路,上面通过向服务器发送post请求,获取了每页的用户id号,也知道了页面总数和用户总数,因此,可以构造两个爬虫,一个爬取所有页面的用户id号,保存在一个队列里面,另一个从队列里面取出id号构造详情页url,然后爬取详情页并解析我们需要的数据。
第一次开启爬虫的时候,开了10个线程,可能是爬的太快了,导致ip被封了,于是花了10块钱从淘宝上买了10个代理,添加到列表里面,每次发送请求的时候从列表中随机选一个代理,另外,程序会去捕获ConnectionError,如果出现这个错误,就说明这个代理不可用了,从而需要把它从列表中移除。
爬取所有用户id
这个就很容易了,先构造一个CrawlGirlId类,这个类继承threading.Thread,开启这个爬虫后,直接向服务器发送post表单数据,只要每次修改其中的页码参数就ok了,先上代码
class CrawlGirlId(threading.Thread):
session = None
user_id_queue = None
page_queue = Queue()
POST_SEARCH_URL = "http://search.jiayuan.com/v2/search_v2.php"
def __init__(self, formdata):
super(CrawlGirlId, self).__init__()
self.formdata = formdata.copy() # 浅复制,因为每个线程都需要修改formdata["p"],如果共享同一个的话会出乱子
def run(self):
global craw_pages_finished
while True:
try:
page = str(self.page_queue.get(False)) # false,在队列为空时产生Empty异常
self.formdata["p"] = page
except Empty:
craw_pages_finished = True # 爬取所有页面的id号结束
print("craw pages finished: %s" % threading.current_thread())
break
else:
proxy = random.choice(proxies)
try:
page_resp = self.session.post_str(url=self.POST_SEARCH_URL, data=self.formdata, proxies=proxy)
except ConnectionError:
with global_lock:
proxies.remove(proxy) # 说明这个代理无效或被封,移除
else:
self.parse_girl_id(page_resp)
time.sleep(0.5)
def parse_girl_id(self, page_resp):
ret = re.sub(r"##jiayser##/{0,2}", "", page_resp)
ret_dict = json.loads(ret)
userinfo = ret_dict["userInfo"]
for i in range(0, len(userinfo)):
uid = userinfo[i]["realUid"]
self.uid_queue.put(uid) # block 默认为True,即如果队列满了则阻塞至队列有空位
@classmethod
def init_spider(cls, session, formdata, uid_queue):
cls.uid_queue = uid_queue
cls.session = session
while True:
if cls.get_first_page(formdata):
break
@classmethod
def get_first_page(cls, formdata):
formdata["p"] = "1"
proxy = random.choice(proxies)
try:
resp = cls.session.post_str(url=cls.POST_SEARCH_URL, data=formdata, proxies=proxy)
except ConnectionError:
with global_lock:
proxies.remove(proxy) # 说明这个代理无效或被封,移除
return False
else:
ret = re.sub(r"##jiayser##/{0,2}", "", resp)
ret_dict = json.loads(ret)
userinfo = ret_dict["userInfo"]
for i in range(1, len(userinfo)): # 第一个是本人信息,剔除
uid = userinfo[i]["realUid"]
cls.uid_queue.put(uid) # block 默认为True,即如果队列满了则阻塞至队列有空位
page_total = int(ret_dict["pageTotal"]) - 5 # 减去5是防止页面总数在爬取过程中减少,所以这个值动态获取其实更好
count = ret_dict["count"]
print("page_total: %s, count: %s" % (page_total, count))
for page in range(2, page_total): # 从第二页开始,第一页已经获取了
cls.page_queue.put(page)
return True
这个代码看起来有点长,但是逻辑很简单,之所以长是因为最后面的那个get_first_page函数,这个函数的作用也很简单,就是解析第一页的内容(即第一次post请求返回的数据),第一页单独处理,首先是因为第一页的第一个用户其实返回的是本人的信息,这个是不需要爬取的,所以第一页需要把第一条信息剔除,我觉得这个剔除的逻辑单独挑出来写比较好一点,其次是因为我们需要知道总页面是多少,才能知道爬虫爬到那一页就要停止,这是首先需要解决的问题,所以这两个逻辑放在一起就形成了get_first_page函数。get_first_page函数是在init_spider函数中调用的,这个函数其实就是类的初始化,因为这个类的实例会共享一些变量,所以把这些设置为类变量,并在该函数中初始化。
其余代码都很好理解了,把每页的用户id都保存到一个队列中。
爬取详情页
点开一个详情页,就可以知道用户详情页的url格式为域名+用户id+一个固定参数。这个就很好办了,用户id在上面已经获取了,只需要字符串拼接一下就很容易得出详情页url了。
同样是构建一个类CrawlDetailPage,继承自threading.Thread
class CrawlDetailPage(threading.Thread):
DETAIL_URL = "http://www.jiayuan.com/%s?fxly=search_v2"
lock = threading.Lock()
error_lock = threading.Lock() def __init__(self, user_id_queque, session, f, t_name):
super(CrawlDetailPage, self).__init__(name=t_name)
self.user_id_queque = user_id_queque # 往url队列贴了个标签而已,实际上并不会新建一个队列,所以内存占用不会增加
self.session = session
self.fp = f
self.item = {} def run(self):
global craw_finished
while not craw_finished:
try:
user_id = self.user_id_queque.get(True, timeout=0.5)
except Empty:
if craw_pages_finished:
craw_finished = True
print("id empty: %s" % threading.current_thread())
else:
print("%s 正在爬取id=%s小姐姐资料" % (threading.current_thread(), user_id))
detail_url = self.DETAIL_URL % user_id
proxy = random.choice(proxies)
try:
resp = self.session.get_str(url=detail_url, proxies=proxy)
except ConnectionError:
with global_lock:
proxies.remove(proxy) # 说明这个代理无效或被封,移除
else:
self.item = {
"user_id": user_id,
}
self.parse_detail(resp)
time.sleep(0.5)
# print("id=%s小姐姐资料爬取完毕" % user_id)
print("exit craw: %s" % threading.current_thread()) def parse_detail(self, resp):
try:
html_element = etree.HTML(resp) # 解析网页代码
member_main_info = html_element.xpath("//div[@class='member_info_r yh']")[0]
nickname = member_main_info.xpath("//div[@class='member_info_r yh']/h4/text()")[0] main_info = member_main_info.xpath("//div[@class='member_info_r yh']/h6/text()")[0]
age = main_info.split("岁")[0]
marriage = main_info.split(",")[1] # 注意这里是中文的逗号 base_info = member_main_info.xpath("//div[@class='member_info_r yh']//div[@class='fl pr']//text()")
degree = base_info[1]
height = base_info[4]
# cars = base_info[7]
salary = base_info[10]
house = base_info[13]
weight = base_info[16]
# nation = base_info[22] other_info = html_element.xpath("//div[@class='content_705']/div[9]")[0]
hometown = other_info.xpath(".//ul[1]/li[1]/div//text()")[0] requirment = html_element.xpath("//div[@class='content_705']/div[5]//li//div/text()")
age_boy = requirment[0]
height_boy = requirment[1]
degree_boy = requirment[3]
marriage_boy = requirment[5]
hometown_boy = requirment[6] item_info = {
"nickname": nickname,
"age": age,
"marriage": marriage,
"degree": degree,
"height": height,
# "cars": cars,
"salary": salary,
"house": house,
"weight": weight,
# "nation": nation,
"hometown": hometown,
"age_boy": age_boy,
"height_boy": height_boy,
"degree_boy": degree_boy,
"marriage_boy": marriage_boy,
"hometown_boy": hometown_boy,
}
self.item.update(item_info)
with self.lock:
self.fp.write((json.dumps(self.item, ensure_ascii=False) + "\n"))
except Exception as e: # 记录错误信息
with self.error_lock:
with open("error.txt", "a", encoding="utf8") as fp:
fp.write(str(e) + "\r\n" + resp + "\r\n\r\n")
逻辑也很简单粗暴,run方法里面从用户id队列(user_id_queque)中取一个id出来,构造详情页url,然后随机选取一个代理,发送post请求即可获得详情页面,parse_detail函数就是解析要想的数据然后写入文件了,这没啥好说的。
开启多线程爬虫
上面构建了两个爬虫,第一个爬取id的爬虫一次就能解析出二十多个id,第二个爬虫一次只能爬取一个详情页,所以第一个爬虫开启一个线程就够用了,第二个爬虫我开了10个线程,总共爬下来花了66分钟,一共爬了1.8w+条小姐姐信息,不过看起来这么多,其中就有很大的猫腻,这个后面再来看。
由于后面数据简单分析是用的jupyter notebook,这里不方便贴代码,所以就把爬虫代码和数据分析代码一起放到了GitHub上。
四. 简单数据分析
数据拿到了,终于可以窥探小姐姐的小秘密了,激动的我赶紧把近两万行数据整体从上到下滑了一遍,不滑不知道,一滑下一跳,刚开始滑动的时候,小姐姐的昵称长长短短看得眼花缭乱,越到后面越不对劲,咋的总有几个相同的影子在眼睛里晃来晃去,仔细一看,不得了,原来存在大量相同的昵称,而且id号和其他信息都一样,这明显是重复的数据

难道是程序重复爬取了?这应当不应该啊,所有需要爬取的页面都是放在同一个队列之中,是用循环生成的从第一页到最后一页的独一无二的整数,从队列中弹出后就应该没有了,所以应该不至于一个页面被重复爬取,那要么就是不同页面存在相同的用户id,于是在浏览器中一直翻到一百多页,果然发现大量重复的信息。
数据读取和去重
知道了数据造假后,我想知道到底有多少是不重复的,于是打开jupyter notebook,用pandas去一下重就知道了,把这近2w的数据按行读到一个列表中,然后构造出DataFrame对象,再统计一下数据总数

总数18451,没毛病
去重后

居然2w变成2k,造假了近10倍,一个全国闻名的婚恋网站居然玩这种把戏!可怕!
简单分析女生对男生最低身高要求与自身身高的关系
我们都知道女生很看重男生身高,所以我比较好奇,女生对男生预期的最低身高要求与女生自身身高有什么关系呢?于是我把女生对男生最低身高要求提取出来单独为一列,并把女生从低到高排序后然后按女生身高group一下,这样就能获取到女生每个身高段对应的所有的预期男生最低身高值(比如所有162cm的女生,要求的男生最低身高组成一个集合),求出女生每个身高段预期男生最低身高的平均值和中位值,以女生身高为横坐标,女生预期的男生最低身高值为纵坐标,画图如下:
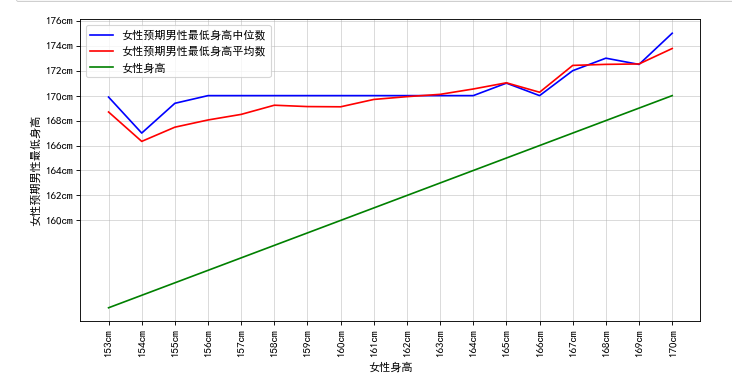
绿色代表女生自身身高值,可以看到身高越是低的女生,对身高差越有要求,但是一般也在12cm左右,这是不是证明了网传的12cm最佳身高差的说法是有一定市场的。女生越高,对身高差就没那么大要求了。
好了,写了一天终于完工了。
爬虫和jupyter代码都放在GitHub:
python多线程爬取世纪佳缘女生资料并简单数据分析的更多相关文章
- python 爬取世纪佳缘,经过js渲染过的网页的爬取
#!/usr/bin/python #-*- coding:utf-8 -*- #爬取世纪佳缘 #这个网站是真的烦,刚开始的时候用scrapy框架写,但是因为刚接触框架,碰到js渲染的页面之后就没办法 ...
- python多线程爬取斗图啦数据
python多线程爬取斗图啦网的表情数据 使用到的技术点 requests请求库 re 正则表达式 pyquery解析库,python实现的jquery threading 线程 queue 队列 ' ...
- Python 多线程爬取站酷(zcool.com.cn)图片
极速爬取下载站酷(https://www.zcool.com.cn/)设计师/用户上传的全部照片/插画等图片. 项目地址:https://github.com/lonsty/scraper 特点: 极 ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- 【Python爬虫案例学习2】python多线程爬取youtube视频
转载:https://www.cnblogs.com/binglansky/p/8534544.html 开发环境: python2.7 + win10 开始先说一下,访问youtube需要那啥的,请 ...
- python多线程爬取-今日头条的街拍数据(附源码加思路注释)
这里用的是json+re+requests+beautifulsoup+多线程 1 import json import re from multiprocessing.pool import Poo ...
- 世纪佳缘信息爬取存储到mysql,下载图片到本地,从数据库选取账号对其发送消息更新发信状态
利用这种方法,可以把所有会员信息存储下来,多线程发信息,10秒钟就可以对几百个会员完成发信了. 首先是筛选信息后爬取账号信息, #-*-coding:utf-8-*- import requests, ...
- Python爬虫入门教程: All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
- Python爬虫入门教程 14-100 All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
随机推荐
- mysql 左联结与右联结
mysql> select * from test; +----+------------+-------+-----------+ | id | name | score | subject ...
- 微信公众号_Deejo说_2019
说明: 1. 文中的内容均来自Deejo说微信公众号 2. 微信中搜索"Deejo说"公众号,可关注 麻麻英语 ——2019.09.10—— It’s my treat. 我来请客 ...
- centos6 启动docker报错
1.启动docker报错: # service docker stop Stopping docker: [ OK ] [root@RSING data2]# service docker start ...
- avalon数据已更新,视图未更新的bug修复
$computed: { pinlei() { var key = this.currentProduct.key || 'youpin'; console.log(key, "我是key& ...
- a标签伪类选择器+过度模块
a标签的伪类选择器 1.什么是a标签的伪类选择器?a标签的伪类选择器是专门用来修改a标签不同状态的样式的. 2.格式: 1):link 修改从未被访问过状态下的样式. 2):visited 修改被访问 ...
- Springboot属性加载与覆盖优先级与SpringCloud Config Service配置
参考官方文档:https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-external-config. ...
- 清除JAVA 项目中的注释
package com.lookcoder.inschool.utils; import java.io.BufferedReader; import java.io.File; import jav ...
- Win 10 MSYS2 VS Code 配置 c++ 的编译环境
博客参考 https://www.cnblogs.com/esllovesn/p/10012653.html 和 https://blog.csdn.net/bat67/article/details ...
- EF Core基本使用
Mysql: nuget 安装 Pomelo.EntityFrameworkCore.MySql Microsoft.EntityFrameworkCore.Design csprj 修改: < ...
- 分类的性能评估:准确率、精确率、Recall召回率、F1、F2
import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f ...