使用 Spring Cloud Sleuth、Elastic Stack 和 Zipkin 做微服务监控
关于迁移微服务架构,最常被提及的挑战莫过于监控。每个微服务应独立于其他服务的运行环境,所以他们之间不会共享如数据源、日志文件等资源。
然而,较容易的查看服务的调用历史,并且能够查看多个微服务的请求传播是微服务架构的重要需求。获取服务日志不是此问题的正确解决之道,所以这里我要分享一些很有帮助的第三方工具,以方便在创建微服务的时候应用,如Sping Boot和Spring Cloud。
Tools工具
Spring Cloud Sleuth. 作为Spring Cloud项目的库之一,通过添加相关HTTP请求头,记录微服务随后的调用过程。借助于于MDC(映射诊断的上下文),可以轻易的获取上下文中的值,并显示在相关日志中。
Zipkin. 一款分布式追踪系统,用于收集每个独立服务请求的时间。有一个简单的管理控制台,可视化显示服务调用的时间统计。
Elastic Stack (ELK). Elasticsearch, Logstash, 及Kibana,通常三者一起使用,用来实时查找、分析、可视乎日志数据。
可能你以前没有开发过Java或是微服务,但你们大部分的人都或许听说过Elasticsearch和Kibana。例如你在浏览Docker Hub时,你就会看到在流行的镜像中很多项目使用到了上述工具。在我们的案例中,我将使用这些镜像。感谢Docker镜像,让我能轻易的在本机安装完全的Elastic Stack环境。接下来让我们开始Elasticsearch容器吧。
关于迁移微服务架构,最常被提及的挑战莫过于监控。每个微服务应独立于其他服务的运行环境,所以他们之间不会共享如数据源、日志文件等资源。
然而,较容易的查看服务的调用历史,并且能够查看多个微服务的请求传播是微服务架构的重要需求。获取服务日志不是此问题的正确解决之道,所以这里我要分享一些很有帮助的第三方工具,以方便在创建微服务的时候应用,如Sping Boot和Spring Cloud。
docker run - d - it--name es - p 9200: 9200 - p 9300: 9300 - e
"discovery.type=single-node" docker.elastic.co /
elasticsearch / elasticsearch: 6.1 .1
在开发模式下运行 Elasticsearch 最方便,因为我们不需要提供额外的配置。如果你想在生产环境下启动 ,需要将 Linux 核心配置项 vm.max_map_count 设置为不小于 262144 的数。修改这个配置的过程在不同的操作系统下是不同的。如果在 Windows 下使用 Docker Toolbox,需要通过 docker-machine 来设置。
docker - machine ssh
sudo sysctl - w vm.max_map_count = 262144
然后运行 Kibana 容器并将其连接到 Elasticsearch。
docker run - d - it--name kibana--link es: elasticsearch - p 5601: 5601 docker.elastic.co / kibana / kibana: 6.1 .1
最后我们开启声明了输入了输出的 Logstash。我们将输入声明为 TCP,它在我们的示例应用中是兼容 LogstashTcpSocketAppender 的日志记录器。Elasticsearch 被声明为输出。每个微服务的名称都会被加上 micro 前缀并加入索引。Logstash 还有很多其它可用的输入输出插件,可以在这里查看[译者注:这里应该有一个链接,但是原文没有加链接]。另一个输入方式是使用 RabbitMQ 和 Spring AMQPAppender,我在博文中说明了:如何在 Logstash、Elasticsearch 和 RabbitMQ 之间传输日志。
docker run - d - it--name logstash - p 5000: 5000 logstash - e
'input { tcp { port => 5000 codec => "json" } } output {
elasticsearch { hosts => ["192.168.99.100"] index =>
"micro-%{serviceName}"} }'
微服务
现在来看个微服务的示例。本文是我另一篇博文——使用 Spring Cloud、Eureka 和 Zuul 创建微服务——的延续,其示例架构和使用的示例与前文相同。示例源代码在 GitHub(logstash 分支)上。我曾经提到要使用 Logback 库来向 Logstash 发送日志数据。除了 Logback 的 3 个依赖库,我们还要添加用于 Zipkin 集成和 Spring Cloud Sleuth 入门的一些库。下面是用于微服务的 pom.xml 代码段:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.9</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
还有一个 Logback 的配置文件放在 src/main/resources 目录。这里有一段 logback.xml 中的代码。我们可以在配置中声明需要发送到 Logstash 的 mdc、logLevel、message 等日志字段。我们还添加了一个服务名称字段,用于 Elastic - 创建用于搜索的索引。
<appender name="STASH" class="net.logstash.logbackappender.LogstashTcpSocketAppender">
<destination>192.168.99.100:5000</destination>
<encoder class="net.logstash.logback.encoder LoggingEventCompositeJsonEncoder">
<providers>
<mdc />
<context />
<logLevel />
<loggerName />
<pattern>
<pattern> { "serviceName": "account-service" } </pattern>
</pattern>
<threadName />
<message />
<logstashMarkers />
<stackTrace /> </providers>
</encoder>
</appender>
Spring Cloud Sleuth 的配置是非常简单的。我们只需要添加 spring-cloud-starter-sleuth 依赖到 pom.xml 并且加上 @Bean 注解。在这个例子中,我声明了 AlwaysSampler 类,它会导出所有的span——不过还有其他选择,比如 PercentageBasedSampler 类,它会覆盖span的一部分。
@Bean
public AlwaysSampler defaultSampler() {
return new AlwaysSampler();
}
Kibana
之后,开始 ELK docker 容器,我们需要运行我们的微服务。这里有 5 个Spring Boot 应用需要运行:
discovery-service
account-service
customer-service
gateway-service
zipkin-service
在推出所有这些服务之后,我们可以尝试调用一些服务,例如,
http://localhost:8765/api/customer/customers/{id}
它会对客户帐户服务进行调用。所有的日志将会被存储在 Elasticsearch 并且以 micro-%{serviceName} 为索引。日志可以在 Kibana 工具中被搜索,这项功能可以在 管理 -> 索引 中找到 模式。让 Kibana 在 http://192.168.99.100:5601 中可用,并在之后运行它,输入 micro-*,我们会得到一个索引模式的提示。在发现这个功能里,我们可以让我们输入的模式匹配日志,并做一个时间线的虚拟化。
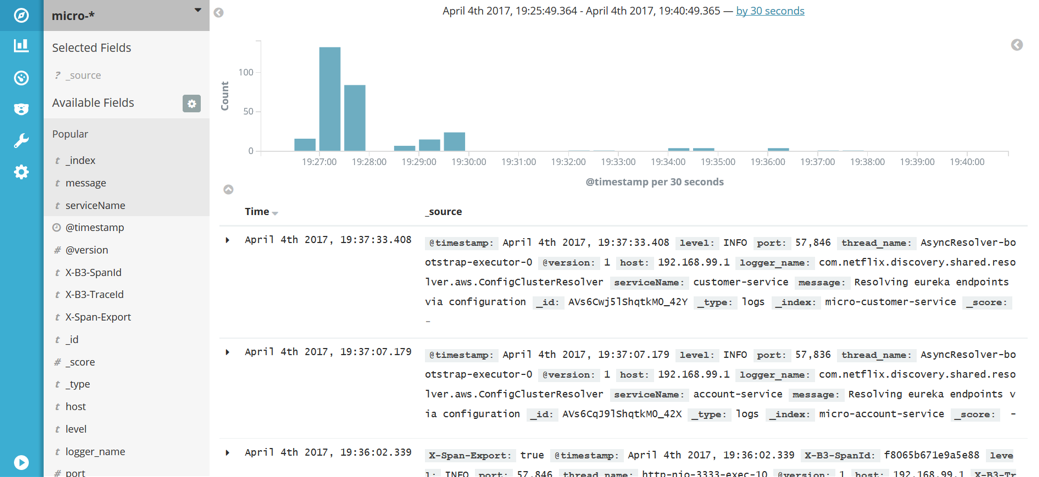
Kibana是一个相当直观和用户友好的工具。我不会详细描述如何使用Kibana,因为你可以轻松地通过查阅文档或仅通过UI知道。最重要的是它能够通过过滤标准来搜索日志。在下图中,有一个通过检索由Spring Cloud Sleuth添加到请求标题中的X-B3-TraceId字段来搜索日志的示例。Sleuth还增加了X-B3-TraceId来标记单个微服务的请求。我们可以选择在结果列表中展示哪些字段; 在本示例中,我选择了message和和serviceName,如下图的左侧边窗所示。
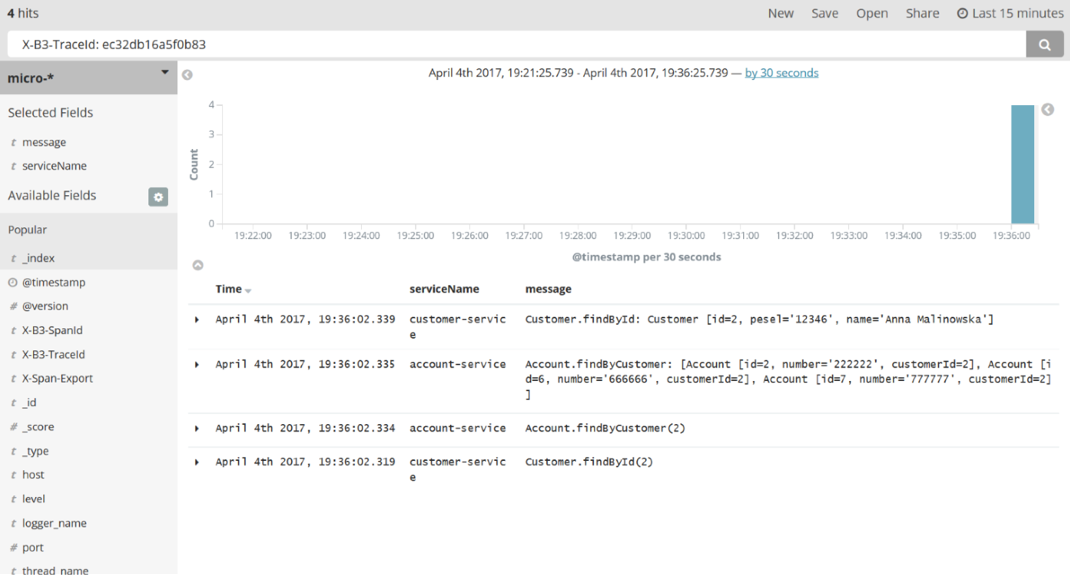
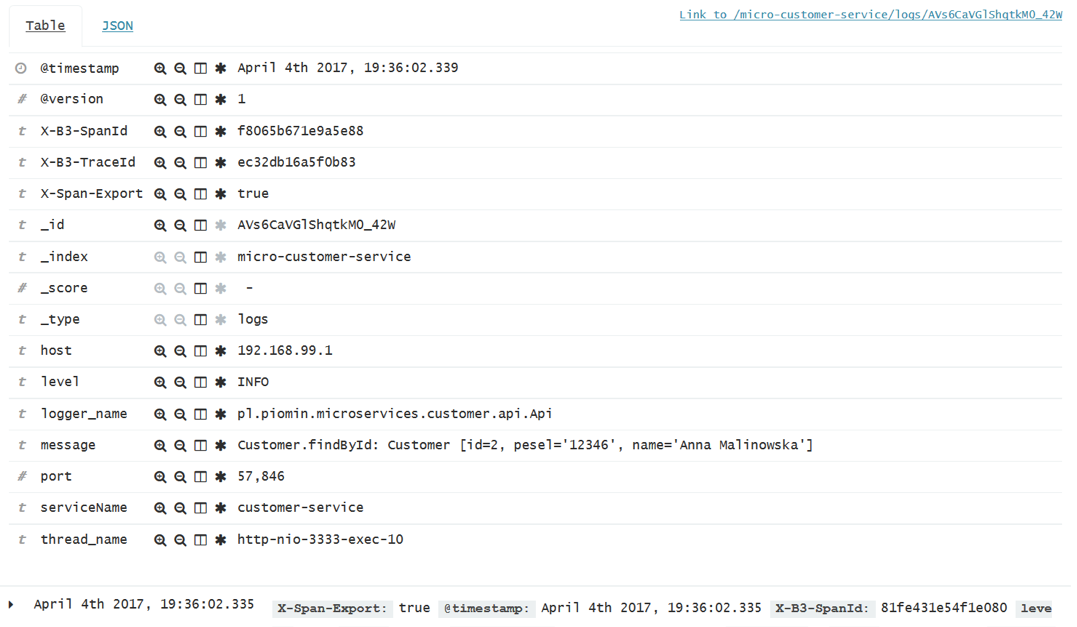
这是一张关于单个请求细节的截图。在展开每个日志行之后它是可见的。
Zipkin
Spring Cloud Sleuth也可以发送追踪统计到Zipkin。这是相比存储在Elastic Stack数据之外另外一类数据。它们是针对每个请求的计时统计。Zipkin UI非常简洁。你可以通过类如时间、服务名以及端点名称这类查询条件过滤 请求。
如下这张图展示的与Kibana展示相同的请求 (http://localhost:8765/api/customer/customers/{id}).
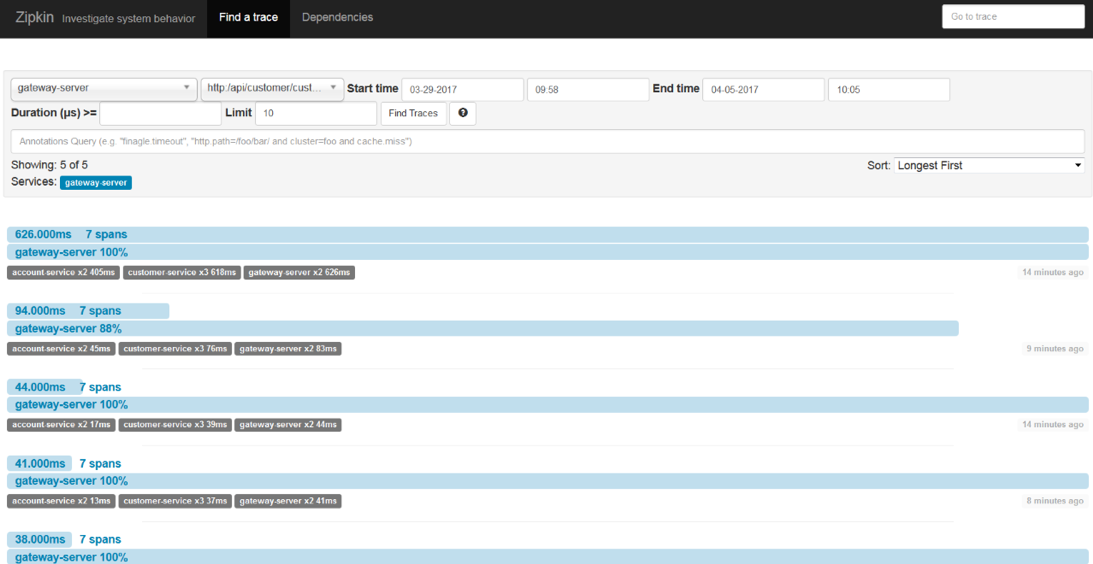
我们总是可以通过单击每个请求查看它的明细。然后,你可以看到类似下面这样的图片。一开始,这个请求被API网关处理,接着,网关发现Eureka服务器上的客户服务并调用该服务。客户服务也需要发现账户服务然后调用它。在这个视图里,你可以很容易的发现哪个操作是最耗时的。
总结
微服务系统顾名思义就是一组相对小而独立的应用集。在你的系统里微服务的数量没有上限。他们的数量甚至可以达到几百上千。考虑到我们所讨论的上千的独立应用,彼此可以独立启动。所以,为了成功监控如此庞大的系统,我们必须得集中的收集、储存日志与追踪数据。使用如Elastic Stack和Zipkin之类的工具,使得监控微服务的系统不再是难事。当然也有一些其他的工具,例如:Hystrix 和 Turbine,可以针对所有传入请求提供实时度量指标。
使用 Spring Cloud Sleuth、Elastic Stack 和 Zipkin 做微服务监控的更多相关文章
- spring cloud实战与思考(二) 微服务之间通过fiegn上传一组文件(上)
需求场景: 微服务之间调用接口一次性上传多个文件. 上传文件的同时附带其他参数. 多个文件能有效的区分开,以便进行不同处理. Spring cloud的微服务之间接口调用使用Feign.原装的Feig ...
- Spring Cloud Gateway简单入门,强大的微服务网关
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 简介 见名知义,Spring Cloud Gateway是用于微服务场景的网关组件,它是基于Spring WebFlu ...
- spring cloud实战与思考(三) 微服务之间通过fiegn上传一组文件(下)
需求场景: 用户调用微服务1的接口上传一组图片和对应的描述信息.微服务1处理后,再将这组图片上传给微服务2进行处理.各个微服务能区分开不同的图片进行不同处理. 上一篇博客已经讨论了在微服务之间传递一组 ...
- 微服务架构下使用Spring Cloud Zuul作为网关将多个微服务整合到一个Swagger服务上
注意: 如果你正在研究微服务,那必然少不了服务之间的相互调用,哪么服务之间的接口以及api就必须生成系统的管理文档了.如果你希望更好的管理你的API,你希望有一个工具能一站式地解决API相关的所有事情 ...
- Spring cloud(2)B Eureka 注册微服务到服务中心
1.在provide上添加pom(必须加上web) 如果不加 启动后就会自己关闭 <dependency> <groupId>org.springframework.clo ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- 使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
原文:http://www.cnblogs.com/ityouknow/p/8403388.html 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成, ...
- springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言 在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高.如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如 ...
- spring cloud深入学习(十三)-----使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
随机推荐
- day 09 预科
目录 函数 定义函数 函数定义的三种形式 空函数 有参函数(有参数()的函数) 无参函数 函数的返回值 函数的参数 形参 位置形参 实参 位置实参 关键字实参 函数 def twoSum(nums,t ...
- Centos7搭建Harbor私有仓库(二)
1 说明 前文Centos7搭建Harbor私有仓库(一)中成功搭建了Harbor,但,是以http方式搭建的,这里我们修改为https方式 以下基于镜像CentOS-7-x86_64-Minimal ...
- 分布式数据库中间件、产品——sharding-jdbc、mycat、drds
一般对于业务记录类随时间会不断增加的数据,当数据量增加到一定量(一般认为整型值为主的表达到千万级,字符串为主的表达到五百万)的时候,性能将遇到瓶颈,同时调整表结构也会变得非常困难.为了避免生产遇到这样 ...
- AD10生成Gerber文件详细步骤
参考:https://wenku.baidu.com/view/faf0363c195f312b3069a5d2.html
- 数据库开发-Django ORM的单表查询
数据库开发-Django ORM的单表查询 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查询集 1>.查询集相关概述 查询会返回结果的集,它是django.db.mod ...
- Pthon魔术方法(Magic Methods)-bool
Pthon魔术方法(Magic Methods)-bool 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.bool方法 __bool__: 内建函数bool(),或者对象放在逻 ...
- C++(四十五) — 类型转换(static_cast、dynamic_cast 、const_cast、reinterpreter_cast)
0.总结 (1)要转换的变量,转换前.转换后.转换后的结果. (2)一般情况下,避免进行类型转换. 1._static_cast(静态类型转换,int 转换为char) 格式:TYPE B = st ...
- 【转】TUN/TAP虚拟网络设备
转: 原文:https://www.cnblogs.com/wyzhou/p/9286864.html ------------------------------------------------ ...
- 通俗理解word2vec的训练过程
https://www.leiphone.com/news/201706/eV8j3Nu8SMqGBnQB.html https://blog.csdn.net/dn_mug/article/deta ...
- MSc in Robotics
MSc in RoboticsProgramming Methods for Robotics AssignmentIrene Moulitsas & Peter SherarCranfiel ...