R语言学习 - 热图美化
实际应用中,异常值的出现会毁掉一张热图。这通常不是我们想要的。为了更好的可视化效果,需要对数据做些预处理,主要有对数转换,Z-score转换,抹去异常值,非线性颜色等方式。
data <- c(rnorm(5,mean=5), rnorm(5,mean=20), rnorm(5, mean=100), c(600,700,800,900,10000))
data <- matrix(data, ncol=5, byrow=T)
data <- as.data.frame(data)
rownames(data) <- letters[1:4]
colnames(data) <- paste("Grp", 1:5, sep="_")
data
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 6.61047 20.946720 100.133106 600.000000 5.267921
b 20.80792 99.865962 700.000000 3.737228 19.289715
c 100.06930 800.000000 6.252753 21.464081 98.607518
d 900.00000 3.362886 20.334078 101.117728 10000.000000
# 对数转换
# +1是为了防止对0取对数;是加1还是加个更小的值取决于数据的分布。
# 加的值一般认为是检测的低阈值,低于这个值的数字之间的差异可以忽略。
data_log <- log2(data+1)
data_log
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 2.927986 4.455933 6.660112 9.231221 2.647987
b 4.446780 6.656296 9.453271 2.244043 4.342677
c 6.659201 9.645658 2.858529 4.489548 6.638183
d 9.815383 2.125283 4.415088 6.674090 13.287857
data_log$ID = rownames(data_log)
data_log_m = melt(data_log, id.vars=c("ID")) p <- ggplot(data_log_m, aes(x=variable,y=ID)) + xlab("samples") + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + theme(legend.position="top") + geom_tile(aes(fill=value)) + scale_fill_gradient(low = "white", high = "red")
ggsave(p, filename="heatmap_log.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")
data_ori <- "Grp_1;Grp_2;Grp_3;Grp_4;Grp_5
a;6.6;20.9;100.1;600.0;5.2
b;20.8;99.8;700.0;3.7;19.2
c;100.0;800.0;6.2;21.4;98.6
d;900;3.3;20.3;101.1;10000"
data <- read.table(text=data_ori, header=T, row.names=1, sep=";", quote="") # 去掉方差为0的行,也就是值全都一致的行
data <- data[apply(data,1,var)!=0,]
data
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 6.6 20.9 100.1 600.0 5.2
b 20.8 99.8 700.0 3.7 19.2
c 100.0 800.0 6.2 21.4 98.6
d 900.0 3.3 20.3 101.1 10000.0 # 标准化数据,获得Z-score,并转换为data.frame
data_scale <- as.data.frame(t(apply(data,1,scale))) # 重命名列
colnames(data_scale) <- colnames(data)
data_scale
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a -0.5456953 -0.4899405 -0.1811446 1.7679341 -0.5511538
b -0.4940465 -0.2301542 1.7747592 -0.5511674 -0.4993911
c -0.3139042 1.7740182 -0.5936858 -0.5483481 -0.3180801
d -0.2983707 -0.5033986 -0.4995116 -0.4810369 1.7823177
data_scale$ID = rownames(data_scale)
data_scale_m = melt(data_scale, id.vars=c("ID")) p <- ggplot(data_scale_m, aes(x=variable,y=ID)) + xlab("samples") + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + geom_tile(aes(fill=value)) + scale_fill_gradient(low = "white", high = "red")
ggsave(p, filename="heatmap_scale.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")

data_ori <- "Grp_1;Grp_2;Grp_3;Grp_4;Grp_5
a;6.6;20.9;100.1;600.0;5.2
b;20.8;99.8;700.0;3.7;19.2
c;100.0;800.0;6.2;21.4;98.6
d;900;3.3;20.3;101.1;10000"
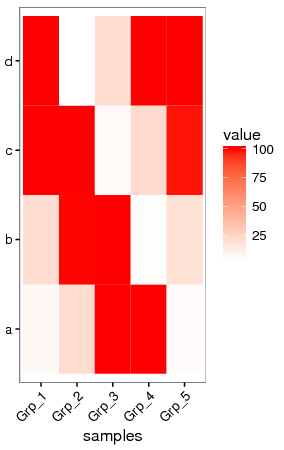
data <- read.table(text=data_ori, header=T, row.names=1, sep=";", quote="") data[data>100] <- 100
data
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 6.6 20.9 100.0 100.0 5.2
b 20.8 99.8 100.0 3.7 19.2
c 100.0 100.0 6.2 21.4 98.6
d 100.0 3.3 20.3 100.0 100.0 data$ID = rownames(data)
data_m = melt(data, id.vars=c("ID")) p <- ggplot(data_m, aes(x=variable,y=ID)) + xlab("samples") + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + geom_tile(aes(fill=value)) + scale_fill_gradient(low = "white", high = "red")
ggsave(p, filename="heatmap_nooutlier.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")
data_ori <- "Grp_1;Grp_2;Grp_3;Grp_4;Grp_5
a;6.6;20.9;100.1;600.0;5.2
b;20.8;99.8;700.0;3.7;19.2
c;100.0;800.0;6.2;21.4;98.6
d;900;3.3;20.3;101.1;10000" data <- read.table(text=data_ori, header=T, row.names=1, sep=";", quote="")
data$ID = rownames(data)
data_m = melt(data, id.vars=c("ID"))
# 获取数据的最大、最小、第一四分位数、中位数、第三四分位数
summary_v <- summary(data_m$value)
summary_v
Min. 1st Qu. Median Mean 3rd Qu. Max.
3.30 16.05 60.00 681.40 225.80 10000.00
# 在最小值和第一四分位数之间划出6个区间,第一四分位数和中位数之间划出6个区间,中位数和第三四分位数之间划出5个区间,最后的数划出5个区间
break_v <- unique(c(seq(summary_v[1]*0.95,summary_v[2],length=6),seq(summary_v[2],summary_v[3],length=6),seq(summary_v[3],summary_v[5],length=5),seq(summary_v[5],summary_v[6]*1.05,length=5)))
break_v
[1] 3.135 5.718 8.301 10.884 13.467 16.050 24.840
[8] 33.630 42.420 51.210 60.000 101.450 142.900 184.350
[15] 225.800 2794.350 5362.900 7931.450 10500.000
# 安照设定的区间分割数据
# 原始数据替换为了其所在的区间的数值
data_m$value <- cut(data_m$value, breaks=break_v,labels=break_v[2:length(break_v)])
break_v=unique(data_m$value)
data_m
ID variable value
1 a Grp_1 8.301
2 b Grp_1 24.84
3 c Grp_1 101.45
4 d Grp_1 2794.35
5 a Grp_2 24.84
6 b Grp_2 101.45
7 c Grp_2 2794.35
8 d Grp_2 5.718
9 a Grp_3 101.45
10 b Grp_3 2794.35
11 c Grp_3 8.301
12 d Grp_3 24.84
13 a Grp_4 2794.35
14 b Grp_4 5.718
15 c Grp_4 24.84
16 d Grp_4 101.45
17 a Grp_5 5.718
18 b Grp_5 24.84
19 c Grp_5 101.45
20 d Grp_5 10500
# 虽然看上去还是数值,但已经不是数字类型了
# 而是不同的因子了,这样就可以对不同的因子赋予不同的颜色了
> is.numeric(data_m$value)
[1] FALSE
> is.factor(data_m$value)
[1] TRUE
break_v
#[1] 8.301 24.84 101.45 2794.35 5.718 10500
#18 Levels: 5.718 8.301 10.884 13.467 16.05 24.84 33.63 42.42 51.21 … 10500 # 产生对应数目的颜色
gradientC=c('green','yellow','red')
col <- colorRampPalette(gradientC)(length(break_v))
col
#[1] "#00FF00" "#66FF00" "#CCFF00" "#FFCB00" "#FF6500" "#FF0000"
p <- ggplot(data_m, aes(x=variable,y=ID)) + xlab("samples") + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + geom_tile(aes(fill=value)) # 与上面不同的地方,使用的是scale_fill_manual逐个赋值
p <- p + scale_fill_manual(values=col)
ggsave(p, filename="heatmap_nonlinear.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")
data_rowname <- rownames(data)
data_rowname <- as.vector(rownames(data))
data_rownames <- rev(data_rowname)
data_log_m$ID <- factor(data_log_m$ID, levels=data_rownames, ordered=T)
p <- ggplot(data_log_m, aes(x=variable,y=ID)) + xlab(NULL) + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + theme(legend.position="top") + geom_tile(aes(fill=value)) + scale_fill_gradient(low = "white", high = "red")
ggsave(p, filename="heatmap_log.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")
R语言学习 - 热图美化的更多相关文章
- R语言学习 - 热图简化
绘制热图除了使用ggplot2,还可以有其它的包或函数,比如pheatmap::pheatmap (pheatmap包中的pheatmap函数).gplots::heatmap.2等. 相比于gg ...
- R语言学习 - 热图绘制heatmap
生成测试数据 绘图首先需要数据.通过生成一堆的向量,转换为矩阵,得到想要的数据. data <- c(1:6, 6:1, 6:1, 1:6, (6:1)/10, (1:6)/10, (1:6)/ ...
- R语言学习 - 线图绘制
线图是反映趋势变化的一种方式,其输入数据一般也是一个矩阵. 单线图 假设有这么一个矩阵,第一列为转录起始位点及其上下游5 kb的区域,第二列为H3K27ac修饰在这些区域的丰度,想绘制一张线图展示. ...
- R语言学习 - 线图一步法
首先把测试数据存储到文件中方便调用.数据矩阵存储在line_data.xls和line_data_melt.xls文件中 (直接拷贝到文件中也可以,这里这么操作只是为了随文章提供个测试文件,方便使用. ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- R语言学习路线和常用数据挖掘包(转)
对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑到论坛上吼一嗓子,然后欣然or悲伤的离去,一直到遇到下一个问题再回来.当然,这不是最好的学习方式,最好的方式是——看书.目前,市面上介绍R语言的 ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习路线图-转帖
本文分为6个部分,分别介绍初级入门,高级入门,绘图与可视化,计量经济学,时间序列分析,金融等. 1.初级入门 <An Introduction to R>,这是官方的入门小册子.其有中文版 ...
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
随机推荐
- jquery验证插件validate自定义扩展
<script src="${pageContext.request.contextPath}/resources/js/jquery-1.12.0.min.js" type ...
- BZOJ 1037: [ZJOI2008]生日聚会Party 四维DP
1037: [ZJOI2008]生日聚会Party Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1650 Solved: 971[Submit][ ...
- MPMoviePlayerController属性方法简介
属性 说明 @property (nonatomic, copy) NSURL *contentURL 播放媒体URL,这个URL可以是本地路径,也可以是网络路径 @property (nonatom ...
- OC学习篇之---类的初始化方法和点语法的使用
昨天介绍了OC中类的定义和使用:http://blog.csdn.net/jiangwei0910410003/article/details/41657603,今天我们来继续学习类的初始化方法和点语 ...
- luogu 2627 修建草坪
题目大意: 一个数列,取出一些数使得它们的总和最大且没有k个连续 思路: 首先我们可以找到一个nk的dp dp方程:dp[i]=dp[i-1]+sum[i]-sum[j] (sum[j]尽量小) 然后 ...
- 第六周 Leetcode 446. Arithmetic Slices II - Subsequence (HARD)
Leetcode443 题意:给一个长度1000内的整数数列,求有多少个等差的子数列. 如 [2,4,6,8,10]有7个等差子数列. 想了一个O(n^2logn)的DP算法 DP[i][j]为 对于 ...
- windows7 RDP修改
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\TerminalServer\WinStations\RDP Tcp\PortNumber”.
- Python---scikit-learn(sklearn)模块
Python在机器学习方面一个非常强力的模块---scikit-learn模块,它作为数据挖掘和数据分析方面的一个简单而有效的工具,主要包括6大功能:分类(Classification),回归(Reg ...
- Windows Java环境变量配置
安装步骤略过... 环境变量配置 新建环境变量: JAVA_HOME C:\Program Files\Java\jdk1.6 将路径替换为自己的安装路径. 新建环境变量: classpath ...
- bzoj 1618: [Usaco2008 Nov]Buying Hay 购买干草【背包】
好像是完全背包吧分不清了-- 好像是把数组二维压一维的时候,01背包倒序,完全背包正序 ```cpp include include using namespace std; const int N= ...