自定义UDF函数应用异常
自定义UDF函数应用异常
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
定义函数PlatformConvert:
实现传入hive表中string类型字段,通过查询中间表,返回int类型主键id值
public class PlatformConvert extends UDF{
public IntWritable evaluate(Text s) throws Exception{
if(s==null){
return null;
}
PlatformDimension platformDimension = new PlatformDimension(s.toString());
IDimensionConverter convert = new DimensionConverterImpl();
int id=0;
id = convert.getDimensionIdByValue(platformDimension);
return new IntWritable(id);
}
}
UDF函数功能:例如参数为all,返回值为1;参数为website,返回值为2.
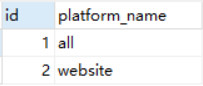
将定义好的UDF函数上传到虚拟机,并创建函数名称为p_con的临时函数
add jar /root/data/Fun.jar; create temporary function p_con as 'myudf.DateConvert';
创建stats_view_depth_tmp表

查询表stats_view_depth_tmp,并将pl字段值转化成中间表对应的id

报错内容大致意思为:不能执行自定义的函数
出现以上错误可能的情况
- jar不包含所有依赖项。可能不包括所有的依赖关系导致不能加载对应依赖的类信息。
- JVM版本不同导致。如果使用jdk8进行编译,并且集群运行jdk7,那么它也将失败
- 蜂巢版本。有时候,蜂巢API变化很小,足够不兼容。可能不是这种情况,但是确保集群中拥有相同版本的hadoop和hive来编译UDF
- info调用后应该始终检查是否为空parse()
具体错误信息还需将进一步查看日志,只列出了关键信息
2017-07-23 19:20:15,558 ERROR [main]: impl.DimensionConverterImpl (DimensionConverterImpl.java:getDimensionIdByValue(71)) - 操作数据库出现异常
java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1094)
2017-07-23 19:20:15,561 ERROR [main]: CliDriver (SessionState.java:printError(960)) - Failed with exception java.io.IOException:org.apache.hadoop.hive.ql.metadata.HiveException: Unable to execute method public org.apache.hadoop.io.IntWritable UDF.PlatformConvert.evaluate(org.apache.hadoop.io.Text) throws java.lang.Exception on object UDF.PlatformConvert@7105159b of class UDF.PlatformConvert with arguments {website:org.apache.hadoop.io.Text} of size 1
java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to execute method public org.apache.hadoop.io.IntWritable UDF.PlatformConvert.evaluate(org.apache.hadoop.io.Text) throws java.lang.Exception on object UDF.PlatformConvert@7105159b of class UDF.PlatformConvert with arguments {website:org.apache.hadoop.io.Text} of size 1
at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:154)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to execute method public org.apache.hadoop.io.IntWritable UDF.PlatformConvert.evaluate(org.apache.hadoop.io.Text) throws java.lang.Exception on object UDF.PlatformConvert@7105159b of class UDF.PlatformConvert with arguments {website:org.apache.hadoop.io.Text} of size 1
at org.apache.hadoop.hive.ql.exec.FunctionRegistry.invoke(FunctionRegistry.java:981)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
Caused by: java.io.IOException: java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
Caused by: java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1094)
信息点:提示数据库异常
Access denied for user 'root'@'localhost' (using password: YES)
以上信息大致推断数据库连接异常。
[错误解析]
主要原因: 执行自定义UDF函数的节点的和要查询中间表所在数据库不在同一个节点上而连接数据库的URL为jdbc:mysql://127.0.0.1:3306/bigdata
解决办法:1.修改中间表所在数据的权限设置
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
给所有root用户赋予所有权限。这样,即使不在同一节点上也可以相互操作对方的数据库
2.修改连接数据库的URL
jdbc:mysql://192.168.23.1:3306/bigdata
设置为要操作数据库所对应的ip
3.重新打包上传,并创建函数
重新执行

执行成功!
创建zj表,并插入数据

自定义函数platidutf,dateidudf同上面的自定义行数作用一致
通过自定义的函数查询,并将对应的属性值转化成上文展示中间表的id值
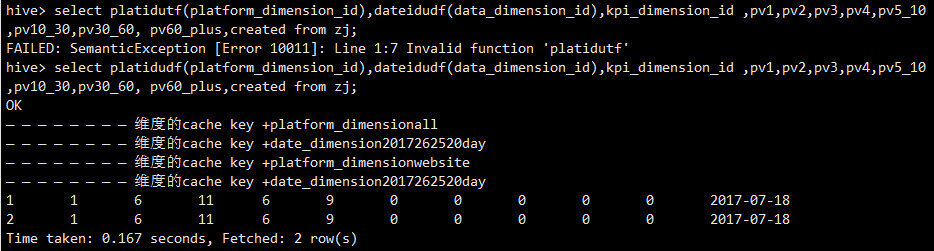
如果将上一步操作查询出来的数据插入到提前定义的表stats_view_depth1
操作语句
from zj insert into table stats_view_depth1 select platidudf(platform_dimension_id),dateidudf(data_dimension_id),kpi_dimension_id ,pv1,pv2,pv3,pv4,pv5_10,pv10_30,pv30_60, pv60_plus,created ;
执行后报错如下:
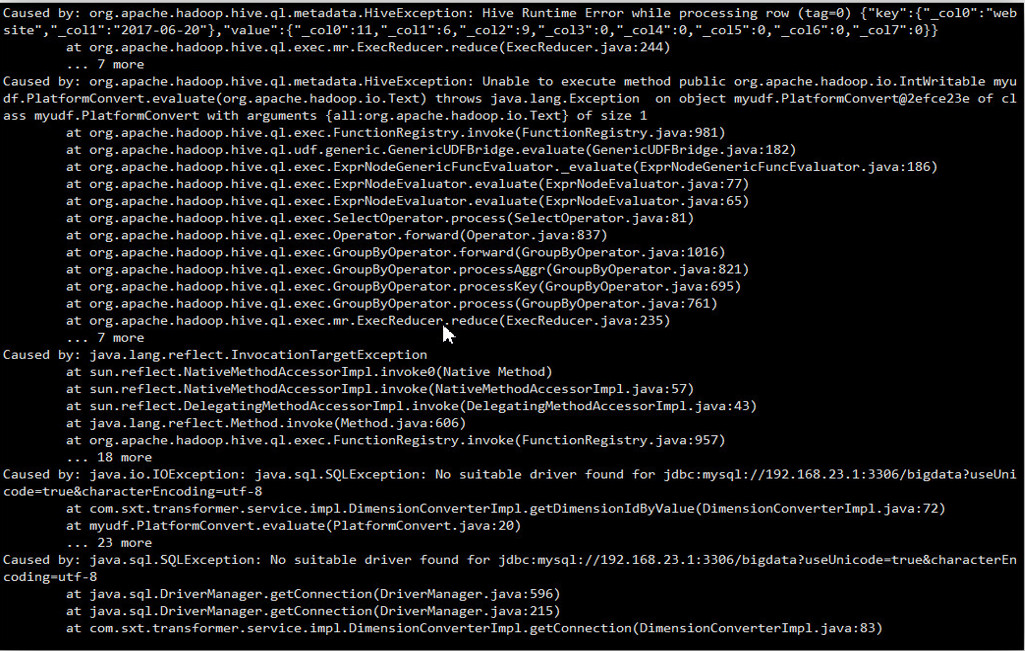 执行后报错如下:
执行后报错如下:
后面提示信息:No suitable sriver found for jdbc…,大致意思时没有找到合适的驱动
报错原因:yarn下没找到数据库的驱动包hadoop-2.6.5/share/hadoop/yarn
因为插入操作需要执行mapreduce作业,上文案例,通过自定义函数查询操作,没有执行mapreduce作业,对应的数据库驱动是从hive目录下加载,所以运行正常。
解决办法:将hive目录下的数据库启动拷贝到hadoop-2.6.5/share/hadoop/yarn目录下
再次执行,一切正常。

Mysql权限设置正确,但仍无法远程访问。通过telnet发现3306端口未打开。
Mysql默认只绑定127.0.0.1,即:只有在本机才能访问3306端口。
- 修改配置文件中的bind-address或注释
- 重启MySQL。再通过远程访问就可以了,telnet可以发现端口也打开了
通过改表法
mysql -u root -p123
mysql>use mysql;
update user set host = '%' where user = 'root';
mysql>select host, user from user;
通过授权法
1. 从任何主机都可以连接到mysql服务器
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
2.指定连接数据库的主机
GRANT ALL PRIVILEGES ON *.* TO ‘root’@'192.168.101.234' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
自定义UDF函数应用异常的更多相关文章
- 如何给Apache Pig自定义UDF函数?
近日由于工作所需,需要使用到Pig来分析线上的搜索日志数据,散仙本打算使用hive来分析的,但由于种种原因,没有用成,而Pig(pig0.12-cdh)散仙一直没有接触过,所以只能临阵磨枪了,花了两天 ...
- 047 SparkSQL自定义UDF函数
一:程序部分 1.需求 Double数据类型格式化,可以给定小数点位数 2.程序 package com.scala.it import org.apache.spark.{SparkConf, Sp ...
- Hive与MapReduce相关排序及自定义UDF函数
原文链接: https://www.toutiao.com/i6770870821809291788/ Hive和mapreduce相关的排序和运行的参数 1.设置每个reduce处理的数据量(单位是 ...
- Spark注册UDF函数,用于DataFrame DSL or SQL
import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions._ object Test2 { def ...
- 自定义udf添加一列
//创建得分窗口字典 var dict= new mutable.HashMap[Double, Int]() ){ dict.put(result_Score(i),i) } //自定义Udf函数 ...
- 自定义Hive函数
7. 函数 7.1 系统内置函数 查看系统自带的函数:show functions; 显示自带的函数的用法:desc function upper(函数名); 详细显示自带的函数的用法:desc fu ...
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- sparksql 自定义用户函数(UDF)
自定义用户函数有两种方式,区别:是否使用强类型,参考demo:https://github.com/asker124143222/spark-demo 1.不使用强类型,继承UserDefinedAg ...
- Spark(十三)【SparkSQL自定义UDF/UDAF函数】
目录 一.UDF(一进一出) 二.UDAF(多近一出) spark2.X 实现方式 案例 ①继承UserDefinedAggregateFunction,实现其中的方法 ②创建函数对象,注册函数,在s ...
随机推荐
- 当css样式表遇到层
(附:White-space:pre可以是样式表里卖弄body的属性,作用是保持html源代码的空格与换行,等同<pre>标签.) Css样式表可以通过被封在层里的方式来限制页面所修饰的内 ...
- 137 Single Number II 数组中除了一个数外,其他的数都出现了三次,找出这个只出现一次的数
给定一个整型数组,除了一个元素只出现一次外,其余每个元素都出现了三次.求出那个只出现一次的数.注意:你的算法应该具有线性的时间复杂度.你能否不使用额外的内存来实现?详见:https://leetcod ...
- 在nginx上部署vue项目(history模式)--demo实列;
在很早之前,我写了一篇 关于 在nginx上部署vue项目(history模式) 但是讲的都是理论,所以今天做个demo来实战下.有必要让大家更好的理解,我发现搜索这类似的问题还是挺多的,因此在写一篇 ...
- 贴图、纹理、材质的区别是什么? 还有shader
贴图.纹理.材质的区别是什么? 还有shader 整个 CG 领域中这三个概念都是差不多的,在一般的实践中,大致上的层级关系是:材质 Material包含贴图 Map,贴图包含纹理 Texture.纹 ...
- qconshanghai2014
主题演讲 容器化的云——CohesiveFT首席技术官 Chris Swan 建设强大的工程师文化——Spotify工程总监 Kevin Goldsmith 软件项目变更的管理和生存之道——jClar ...
- qconshanghai2015
http://2015.qconshanghai.com/schedule 大会日程 2015年10月15日 星期四 08:30 开场致辞 地点 光大宴会厅 专题 主题演讲 数据分析与移动开发工具 ...
- Excel数据直接到DataTable--->DB
1) Excel数据直接导入到临时生成的DataTable using (OleDbConnection selectConnection = new OleDbConnection("Pr ...
- vue在使用ajax获取数据时,两种方法(jquery和vue_resource)
@{ Layout = null;} <!DOCTYPE html> <html><head> <meta name="viewport ...
- maven编译报错 -source 1.5 中不支持 lambda(或diamond) 表达式,编码 UTF-8 的不可映射字符
在用maven编译项目是由于项目中用了jdk 1.8, 编译是报错 -source 1.5 中不支持 lambda 表达式. 错误原因: Maven Compiler 插件默认会加 -source ...
- AJPFX关于学习java遇到的问题:对算法和数据结构不熟悉
为什么我先拿“数据结构和算法”说事捏?这玩意是写程序最最基本的东东.不管你使用 Java 还是其它的什么语言,都离不开它.而且这玩意是跨语言的,学好之后不管在哪门语言中都能用得上. 既然“数据结构和算 ...