PyTorch如何构建深度学习模型?
简介
每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观。Pytorch就是这样一个库。
在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易。Pytorch是我迄今为止所使用的深度学习库中最灵活的,最轻松的。
在本文中,我们将以实践的方式来探索Pytorch,包括基础知识与案例研究。我们会使用numpy和Pytorch分别从头开始构建神经网络,看看他们的相似之处。
提示:本文假设你已经对深度学习有一定的了解。如果你想深入学习深度学习,请先阅读本文。
内容目录
- Pytorch概述
- 深层技术
- 在Numpy和Pytorch中构建神经网络
- 与其他深度学习库的比较
- 案例研究——使用Pytorch解决图像识别问题
Pytorch概述
Pytorch的创作者说他们有一种理念——他们希望工具能够即时运作,这也就以为这我们必须及时进行运算。这也非常适用于python的编程方式,因为我们不必去等到程序都编完而确定整个代码是否有效。我们可以轻松得运行部分代码并且可以实时检查。这个神经网络的软件,对我来说是非常好用的。
PyTorch是一个基于python的库,旨在提供灵活性作为深度学习开发平台。PyTorch的工作流程也尽可能接近python的科学计算库——numpy。
现在你可能会问,为什么我们会使用PyTorch来构建深度学习模型?我可以列出三个可能有助于回答这个问题的事情:
- 易于使用API——它就像python一样简单。
- 支持Python——就像上面所介绍的,Pytorch与python数据科学堆栈平滑集成。它跟numpy非常相似,你可能都没有注意到它们的区别。
- 动态计算图形——Pytorch不是使用特定功能的预定义图形,而是为我们提供了构建计算图形的框架,甚至可以在运行的时候更改它们。这对于我们不知道创建神经网络需要多少内存的情况非常有用。
使用Pytorch还有一些其他的优点,例如它的multiGPU支持,自定义数据加载器和简化的预处理器。
自2016年1月初发布以来,许多研究人员将其作为首选库,因为它易于构建新颖甚至极其复杂的图形。话虽如此,因为它比较新并且正在发展中,PyTorch仍然需要一段时间才能被大多数数据科学从业者采用。
深层技术
在深入了解工作细节之前,让我们来看看Pytorch的工作流程。
Pytorch构建图形所需的每行代码都定义了该图形的一个组件。即使在完全构建图形之前,我们也可以独立地对这些组件进行计算。这叫做“按运行定义”的方法。

安装PyTorch非常简单。您可以按照官方文档中提到的步骤操作,并根据您的系统规范运行命令。例如,这是我根据我选择的选项使用的命令:
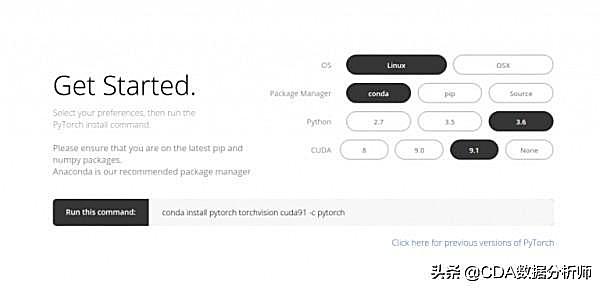
conda install pytorch torchvision cuda91 -c pytorch
开始使用Pytorch时我们应该知道的主要元素是:
- Pytorch 张量
- 数学运算
- Autograd 模块
- Optim 模块
- nn 模块
下面,我们具体看看每块元素是什么情况。
Pytorch 张量
张量只不多是多维数组。Pytorch中的张量类似于numpy的ndarray,另外张量也可以在GPU上使用。Pytorch支持各种类型的张量。
你可以定义一个简单的一位矩阵,如下所示:
# import pytorch
import torch
# define a tensor
torch.FloatTensor([2])
2
[torch.FloatTensor of size 1]
数学运算
与numpy一样,科学计算库能够有效得实现数学函数是非常有效的。Pytorch为你提供了类似的交互界面,你可以在这里使用200多个数学运算。
下面是Pytorch中的一个简单加法操作的例子:
a = torch.FloatTensor([2])
b = torch.FloatTensor([3])
a + b
5
[torch.FloatTensor of size 1]
这是python中的一个重要部分。我们还可以在我们定义的Pytorch张量上执行各种矩阵运算。例如:我们来转置二维矩阵:
matrix = torch.randn(3, 3)
matrix
0.7162 1.0152 1.1525
-0.3503 -0.9452 -1.0861
-0.1093 -0.0927 -0.0476
[torch.FloatTensor of size 3x3]
matrix.t()
0.7162 -0.3503 -0.1093
1.0152 -0.9452 -0.0927
1.1525 -1.0861 -0.0476
[torch.FloatTensor of size 3x3]
Autograd 模块
Pytorch使用了一种自动微分的技术。也就是说,我们有一个记录器记录我们执行过的操作,然后它会将操作往后执行以计算梯度。这种技术在构建神经网络时非常有用,因为我们通过计算前向传播本身的参数差异来节省一个周期的时间。
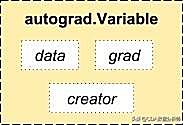
from torch.autograd import Variable
x = Variable(train_x)
y = Variable(train_y, requires_grad=False)
Optim 模块
torch.optim是一个实现用于构建神经网络的各种优化算法的模块。已经支持了大多数的常用算法,所以我们可以免去从头开始构建它们的麻烦。
下面是使用Adam optimizer 的代码:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
nn模块
Pytorch中的autograd可以很容易定义图形并计算梯度,但原始的autograd对于定义复杂的神经网络来说可能有点过于低级了。这就是nn模块可以提供帮助的地方。
nn扩展包定义了一组模块,我们可以把它看做成一个能从输入产生输出并且包含一些可训练的权重的神经网络层。
你其实可以把nn模块视作Pytorch的keras!
import torch
# define model
model = torch.nn.Sequential(
torch.nn.Linear(input_num_units, hidden_num_units),
torch.nn.ReLU(),
torch.nn.Linear(hidden_num_units, output_num_units),
)
loss_fn = torch.nn.CrossEntropyLoss()
现在你已经了解了Pytorch的基本组件,你可以轻松地从头开始构建自己的神经网络。下面让我们继续吧!
使用Numpy与Pytorch分别构建一个神经网络
在上文中提到,Pytorch和Numpy非常相似,那我们来看看为什么。在本节中,我们将利用一个简单的神经网络来实现二进制分类的问题。
## Neural network in numpy
import numpy as np
#Input array
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Output
y=np.array([[1],[1],[0]])
#Sigmoid Function
def sigmoid (x):
return 1/(1 + np.exp(-x))
#Derivative of Sigmoid Function
def derivatives_sigmoid(x):
return x * (1 - x)
#Variable initialization
epoch=5000 #Setting training iterations
lr=0.1 #Setting learning rate
inputlayer_neurons = X.shape[1] #number of features in data set
hiddenlayer_neurons = 3 #number of hidden layers neurons
output_neurons = 1 #number of neurons at output layer
#weight and bias initialization
wh=np.random.uniform(size=(inputlayer_neurons,hiddenlayer_neurons))
bh=np.random.uniform(size=(1,hiddenlayer_neurons))
wout=np.random.uniform(size=(hiddenlayer_neurons,output_neurons))
bout=np.random.uniform(size=(1,output_neurons))
for i in range(epoch):
#Forward Propogation
hidden_layer_input1=np.dot(X,wh)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1=np.dot(hiddenlayer_activations,wout)
output_layer_input= output_layer_input1+ bout
output = sigmoid(output_layer_input)
#Backpropagation
E = y-output
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_output) *lr
bout += np.sum(d_output, axis=0,keepdims=True) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh += np.sum(d_hiddenlayer, axis=0,keepdims=True) *lr
print('actual : ', y, ' ')
print('predicted : ', output)
现在,让我们试试来寻找我们的简单案例在两种库中的不同(不同之处已注释)。
## neural network in pytorch
import torch #不同
#Input array
X = torch.Tensor([[1,0,1,0],[1,0,1,1],[0,1,0,1]]) #不同
#Output
y = torch.Tensor([[1],[1],[0]]) #不同
#Sigmoid Function
def sigmoid (x):
return 1/(1 + torch.exp(-x)) #不同
#Derivative of Sigmoid Function
def derivatives_sigmoid(x):
return x * (1 - x)
#Variable initialization
epoch=5000 #Setting training iterations
lr=0.1 #Setting learning rate
inputlayer_neurons = X.shape[1] #number of features in data set
hiddenlayer_neurons = 3 #number of hidden layers neurons
output_neurons = 1 #number of neurons at output layer
#weight and bias initialization
wh=torch.randn(inputlayer_neurons, hiddenlayer_neurons).type(torch.FloatTensor) #不同
bh=torch.randn(1, hiddenlayer_neurons).type(torch.FloatTensor)
wout=torch.randn(hiddenlayer_neurons, output_neurons) #不同
bout=torch.randn(1, output_neurons) #不同
for i in range(epoch):
#Forward Propogation
hidden_layer_input1 = torch.mm(X, wh) #不同
hidden_layer_input = hidden_layer_input1 + bh
hidden_layer_activations = sigmoid(hidden_layer_input)
output_layer_input1 = torch.mm(hidden_layer_activations, wout) #不同
output_layer_input = output_layer_input1 + bout
output = sigmoid(output_layer_input1)
#Backpropagation
E = y-output
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hidden_layer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = torch.mm(d_output, wout.t()) #不同
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += torch.mm(hidden_layer_activations.t(), d_output) *lr #不同
bout += d_output.sum() *lr
wh += torch.mm(X.t(), d_hiddenlayer) *lr #不同
bh += d_output.sum() *lr
print('actual : ', y, ' ')
print('predicted : ', output)
与其他神经网络库对比
在一个基准测试脚本里,成功证明了Pytorch在训练长短期记忆网络(LSTM)方面由于所有其他主要的深度学习库,在每个epoch下都具有最低的中值时间。
Pytorch中用于数据加载的API设计得很好。数据集,采样器和数据加载器的接口都是特定的。
在比较TensorFlow中的数据加载工具(读取器,队列等)时,我发现Pytorch的数据加载模块非常易于使用。此外,我们在构建神经网络时,Pytorch毫无缺陷的,我们并不需要依赖像keras这样的第三方高级库。
另一方面,我不太建议使用Pytorch进行部署,因为Pytorch尚未发展到这一步。正如Pytorch的开发人员所说:“我们看到的是用户首先创建一个Pytorch模型,当他们准备将他们的模型部署到生产中时,他们只需要将其转换成Caffe2模型,然后将其运送到其他平台。”
案例研究——在Pytorch中解决一个图像识别问题
我们下面来解决Analytics Vidhya社区里的深度学习问题——手写数字识别。我们先来看看问题是什么样子的:
我们的任务是识别图像,图像中是给定的28*28图像的阿拉伯数字。我们有一组用于训练的图像,其他的图像用于测试我们的模型。
首先,我们下载训练集与测试集。数据集包含所有图像的压缩文件,训练集和测试集对应的名字是train.csv和test.csv。数据集中没有其他内容,仅仅是“.png”格式的原始图像。
下面让我们开始吧:
第一步:准备
a)导入所有会用到的库
# import modules
%pylab inline
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
b)让我们设置一个种子值,那么我们就可以控制我们的模型随机数了。
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)
c)第一步就是设置目录路径,方便妥善保管!
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'data')
# check for existence
os.path.exists(root_dir), os.path.exists(data_dir)
步骤1:数据加载与处理
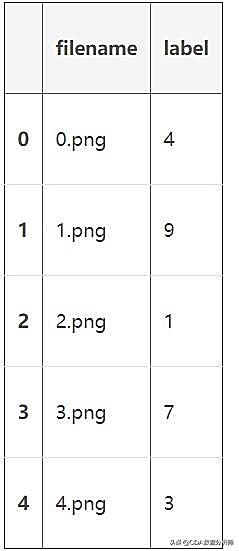
a)现在让我们来看我们的数据集,它是.csv的格式,文件名也是与标签相对应的。
# load dataset
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'Test.csv'))
sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv'))
train.head()
b)我们来看看数据集是什么样的,我们读取数据集中的图片并将它显示出来。
# print an image
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()

d)为了便于数据操作,我们将所有图像存储为numpy数组。
# load images to create train and test set
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
for img_name in test.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = train.label.values
e)由于这是一个典型的机器学习问题,我们创建了一个测试集来测试我们的模型是否能够正常运行。我们采用7:3的分割比例来设置训练集与测试集。
# create validation set
split_size = int(train_x.shape[0]*0.7)
train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]
步骤二:建立模型
a)接下来就是主体部分了,让我们先来定义神经网络的架构。我们定义了一个具有输入层,隐藏层和输出层的3层神经网络。输入与输出中的神经元的数量是固定的,因为输入的是我们训练集中28*28的图像,输出的是十个类别。在隐藏层中我们设置了50个神经元,这里,我们使用Adam算法作为我们的优化算法,这就是梯度下降法的有效变体。
import torch
from torch.autograd import Variable
# number of neurons in each layer
input_num_units = 28*28
hidden_num_units = 500
output_num_units = 10
# set remaining variables
epochs = 5
batch_size = 128
learning_rate = 0.001
b)下面该训练我们的模型了。
# define model
model = torch.nn.Sequential(
torch.nn.Linear(input_num_units, hidden_num_units),
torch.nn.ReLU(),
torch.nn.Linear(hidden_num_units, output_num_units),
)
loss_fn = torch.nn.CrossEntropyLoss()
# define optimization algorithm
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
## helper functions
# preprocess a batch of dataset
def preproc(unclean_batch_x):
"""Convert values to range 0-1"""
temp_batch = unclean_batch_x / unclean_batch_x.max()
return temp_batch
# create a batch
def batch_creator(batch_size):
dataset_name = 'train'
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, batch_size)
batch_x = eval(dataset_name + '_x')[batch_mask]
batch_x = preproc(batch_x)
if dataset_name == 'train':
batch_y = eval(dataset_name).ix[batch_mask, 'label'].values
return batch_x, batch_y
# train network
total_batch = int(train.shape[0]/batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
# create batch
batch_x, batch_y = batch_creator(batch_size)
# pass that batch for training
x, y = Variable(torch.from_numpy(batch_x)), Variable(torch.from_numpy(batch_y), requires_grad=False)
pred = model(x)
# get loss
loss = loss_fn(pred, y)
# perform backpropagation
loss.backward()
optimizer.step()
avg_cost += loss.data[0]/total_batch
print(epoch, avg_cost)
# get training accuracy
x, y = Variable(torch.from_numpy(preproc(train_x))), Variable(torch.from_numpy(train_y), requires_grad=False)
pred = model(x)
final_pred = np.argmax(pred.data.numpy(), axis=1)
accuracy_score(train_y, final_pred)
# get validation accuracy
x, y = Variable(torch.from_numpy(preproc(val_x))), Variable(torch.from_numpy(val_y), requires_grad=False)
pred = model(x)
final_pred = np.argmax(pred.data.numpy(), axis=1)
accuracy_score(val_y, final_pred)
训练结果是:
0.8779008746355685
另外,测试集上的结果是:
0.867482993197279
这是一个比较完美的结果了,尤其是当我们仅仅用了一个非常简单的神经网络模型并且只训练了5个周期。
结语
我希望这篇文章能够帮助你从如何构建神经网络模型的角度去了解Pytorch。但是,文字有限,这里我们仅仅展示了很小的一方面。
来源商业新知网,原标题:Pytorch——一个简单却强大的深度学习库
PyTorch如何构建深度学习模型?的更多相关文章
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- 在R中使用Keras和TensorFlow构建深度学习模型
一.以TensorFlow为后端的Keras框架安装 #首先在ubuntu16.04中运行以下代码 sudo apt-get install libcurl4-openssl-dev libssl-d ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- 使用 PyTorch Lightning 将深度学习管道速度提高 10 倍
前言 本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,主要包括有为什么优化深度学习管道很重要.使用 PyTorch Lightning 加快实验周期的六种 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- Opencv调用深度学习模型
https://blog.csdn.net/lovelyaiq/article/details/79929393 https://blog.csdn.net/qq_29462849/article/d ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
随机推荐
- C# 利用Aspose.Words .dll将本地word文档转化成pdf(完美破解版 无水印 无中文乱码)
下载Aspose.Words .dll http://pan.baidu.com/s/1c8659k 在vs2010中新建窗体应用程序,命名为 wordtopdf 添加Aspose.Words .d ...
- NOI前总结:点分治
点分治: 点分治的题目基本一样,都是路径计数. 其复杂度的保证是依靠 $O(n)$ 找重心的,每一次至少将问题规模减小为原先的$1/2$. 找重心我喜欢$BFS$防止爆栈. int Root(int ...
- 洛谷 - P4452 - 航班安排 - 费用流
https://www.luogu.org/problemnew/show/P4452 又一道看题解的费用流. 注意时间也影响节点,像题解那样建边就少很多了. #include<bits/std ...
- Codeforces - 702A - Maximum Increase - 简单dp
DP的学习计划,刷 https://codeforces.com/problemset?order=BY_RATING_ASC&tags=dp 遇到了这道题 https://codeforce ...
- Codeforces - 466C - Number of Ways - 组合数学
https://codeforces.com/problemset/problem/466/C 要把数据分为均等的非空的三组,那么每次确定第二个分割点的时候把(除此之外的)第一个分割点的数目加上就可以 ...
- PJzhang:lijiejie的敏感目录爆破工具BBScan
猫宁!!! 参考链接: https://www.freebuf.com/sectool/85729.html https://segmentfault.com/a/1190000014539449 这 ...
- Beta版本发布!
该作业所属课程:https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass2 作业地址:https://edu.cnblogs.com/c ...
- autolayout UIImageView 根据 UILabel的宽度变换位置
仅个人学习笔记,大牛勿喷 代码写法 使用Masonry //昵称 _nameLableView = [[UILabel alloc]init]; [_nameLableView setTextColo ...
- 进程与线程(2)- python实现多进程
python 实现多进程 参考链接: https://morvanzhou.github.io/tutorials/python-basic/multiprocessing/ python中实现多进程 ...
- jsp 接收汉字参数乱码
这两天跟汉字问题较上劲了,真是考验基本功 1. ${param.userName} 乱码 解决方法: <%String name = (String)request.getParameter( ...