mysql优化-----多列索引的左前缀规则
索引优化策略 1:索引类型 1.1B-tree索引
关注的是:Btree索引的左前缀匹配规则,索引在排序和分组上发挥的作用。 注:名叫btree索引,大的方面看都用的二叉树、平衡树。但具体的实现上,各引擎稍有不同。比如,严格的说,NDB引擎,使用的是T-tree。Myisam,innodb中,默认用B-tree索引。 凡是tree系列的,可理解为”排好序的、快速查找、的结构”。是排好序的,所以查询某个范围就很快。 btree索引的常见误区:在where条件常用的列上都加上索引,
例: where cat_id=3 and price>100 ; //查询第3个栏目,100元以上的商品
误: cat_id上,和, price上都加上索引.
错:只能用上cat_id或Price索引,因为是独立的索引,同时只能用上1个,因为每个索引都是针对整个表建的,而where and查询是在排好序的大范围内再查找小的。(mysql5.6以后做了稍微改进,把多列索引进行merge但是效果不好),因此要使用多列索引。 在多列上建立索引后,查询哪个列,索引都将发挥作用:
误: 多列索引上,索引发挥作用,需要满足左前缀要求(btree索引的左前缀规则) B-tree多列索引:
a,b列各加上索引:index(a)和index(b)
Where a=3 and b=5 ,首先根据a查找到a=3的一小段,然后在从这小段中查找b=5的,此时b的索引已经发挥不了作用了。因为b的索引就不是在a的那一小段里面建的。b是针对整个表建的索引。 以 index(a,b,c) ,Where a=3 and b=5 and c=4 为例,联合索引是先根据a划分大类(a是有序的),再根据b在a里面划分小的(a里面的b是有序的),在根据c在b里面划分更小的(c在b里面是有序的)。就是这样查找的(这是tree系列的索引和查找方式)。 Where b=5 and c=4,索引就用不到了,因为首先是根据a分的大类。现在找b=5的,每一个a的区间都可能有b=5的所以首先排好序的a就进不去。 Where a=4 and c=4,a索引用到,c用不到。每段b里面都可能有c=4的。 多列索引:左前缀规则,中间断线就不行了。否则只能使用到部分。
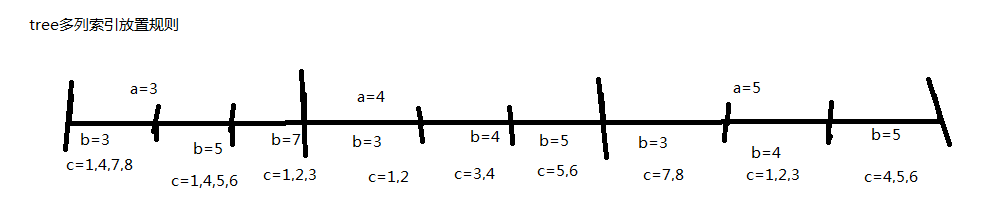
index(a,b,c):
语句 索引是否发挥作用
Where a=3 是,只使用了a列
Where a=3 and b=5 是,使用了a,b列
Where a=3 and b=5 and c=4 是,使用了abc
Where b=3 or where c=4 否
Where a=3 and c=4 a列能发挥索引,c索引也就不能使用了
Where a=3 and b>10 and c=7 A能利用,b能利用, b是一个范围,在这个范围里面的b[10,20]b[20,30]里面都有可能c=7,所以C不能利用
同上,where a=3 and b like ‘xxxx%’ and c=7 A能用,B能用,C不能用 多列索引经典题目:
http://www.zixue.it/thread-9218-1-4.html 假设某个表有一个联合索引(c1,c2,c3,c4)一下——只能使用该联合索引的c1,c2,c3部分,tree系列里面:c1是有序的,c2在c1里面是有序的,c3在c2里面是有序的,c4在c3里面是有序的。 A where c1=x and c2=x and c4>x and c3=x
B where c1=x and c2=x and c4=x order by c3
C where c1=x and c4= x group by c3,c2
D where c1=x and c5=x order by c2,c3
E where c1=x and c2=x and c5=? order by c2,c3 create table t4 (
c1 tinyint(1) not null default 0,
c2 tinyint(1) not null default 0,
c3 tinyint(1) not null default 0,
c4 tinyint(1) not null default 0,
c5 tinyint(1) not null default 0,
index c1234(c1,c2,c3,c4)
);
insert into t4 values (1,3,5,6,7),(2,3,9,8,3),(4,3,2,7,5); 对于A:where c1=x and c2=x and c4>x and c3=x,
等价c1=x and c2=x and c3=x and c4>x
因此 c1,c2,c3,c4都能用上. 如下: mysql> explain select * from t4 where c1=1 and c2=2 and c4>3 and c3=3 \G
id: 1
select_type: SIMPLE
table: t4
type: range //使用索引的方式,使用的是范围索引(c4)
possible_keys: c1234
key: c1234
key_len: 4 //4列#可以看出c1,c2,c3,c4索引都用上
ref: NULL
rows: 1
Extra: Using where 对于B: select * from t4 where c1=1 and c2=2 and c4=3 order by c3
c1 ,c2索引用上了,在c2用到索引的基础上,c3是排好序的,因此不用额外排序,c3,c4没发挥作用. mysql> explain select * from t4 where c1=1 and c2=2 and c4=3 order by c3 \G
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234
key: c1234 //使用了多列索引,但是不一定所有的列都用到了,
key_len: 2 //2列发挥了作用c1c2,
ref: const,const
rows: 1
Extra: Using where
1 row in set (0.00 sec) mysql> explain select * from t4 where c1=1 and c2=2 and c4=3 order by c5 \G
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234
key: c1234 //多列索引使用到了
key_len: 2 //只是使用到了多列索引中的2列c1c2
ref: const,const
rows: 1
Extra: Using where; Using filesort //Usingfilesort是二次排序,在磁盘或者内存里面,c5是没有顺序的所以取出来之后要排序。 D语句:where c1=x and c5=x order by c2,c3,C1确定的基础上,c2是有序的,C2之下C3是有序的,因此c2,c3发挥的排序的作用.
因此,没用到filesort。只能使用一个索引,c2,c3的索引能够用来排序。 mysql> explain select * from t4 where c1=1 and c5=2 order by c2,c3 \G
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234 //多列索引使用到了
key: c1234
key_len: 1 //只是使用到了多列索引中的1列c1,
ref: const
rows: 1
Extra: Using where //没有Using filesort的文件排序,因为c2c3是排好序的 mysql> explain select * from t4 where c1=1 and c5=2 order by c3 \G
id: 1
select_type: SIMPLE
table: t4
partitions: NULL
type: ref
possible_keys: c1234
key: c1234
key_len: 1
ref: const
rows: 1
filtered: 20.00
Extra: Using index condition; Using where; Using filesort //要排序,因为c3跳过了c2,所以要文件排序(比如国家下面的省,先要国家排序后在省排序。现在跳过国家去排省就要重新排序了),没法利用索引了。 E: where c1=x and c2=x and c5=? order by c2,c3
这一句等价与 elect * from t4 where c1=1 and c2=3 and c5=2 order by c3;
因为c2的值既是固定的,参与排序时并不考虑 mysql> explain select * from t4 where c1=1 and c2=3 and c5=2 order by c2,c3 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234
key: c1234
key_len: 2 //用到了2列索引,
ref: const,const
rows: 1
Extra: Using where //没有用到文件排序,说明c2c3索引都用到了, mysql> explain select * from t4 where c1=1 and c5=2 order by c2,c3 \G
id: 1
select_type: SIMPLE
table: t4
partitions: NULL
type: ref
possible_keys: c1234
key: c1234
key_len: 1 //用到了1列索引,
ref: const
rows: 1
filtered: 20.00
Extra: Using index condition; Using where //不用排序,因为先根据cw2排序然后根据c3排序,而c2c3是已经排好序的 mysql> explain select * from t4 where c1=1 and c5=2 order by c3,c2 \G
id: 1
select_type: SIMPLE
table: t4
partitions: NULL
type: ref
possible_keys: c1234
key: c1234
key_len: 1 //用到了1列索引,
ref: const
rows: 1
filtered: 20.00
Extra: Using index condition; Using where; Using filesort //要排序,因为先根据c3排序再根据c2排序,(比如国家下面的省,先要国家排序后在省排序。现在跳过国家去排省就要重新排序了) mysql> explain select * from t4 where c1=1 and c2=3 and c5=2 order by c3,c2 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t4
partitions: NULL
type: ref
possible_keys: c1234
key: c1234
key_len: 2
ref: const,const
rows: 1
filtered: 20.00
Extra: Using index condition; Using where //没有排序,虽然c3在c2的前面,但是c2是定值。 mysql> select cat_id,avg(shop_price) from goods group by cat_id;
+--------+-----------------+
| cat_id | avg(shop_price) |
+--------+-----------------+
| 2 | 823.330000 |
| 3 | 1746.066667 |
| 4 | 2297.000000 |
| 5 | 3700.000000 |
| 8 | 75.333333 |
| 11 | 31.000000 |
| 13 | 33.500000 |
| 14 | 54.000000 |
| 15 | 70.000000 |
+--------+-----------------+ mysql> explain select cat_id,avg(shop_price) from goods group by cat_id \G;
id: 1
select_type: SIMPLE
table: goods
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 31
filtered: 100.00
Extra: Using temporary; Using filesort //分组操作的时候要先排序,这里Using temporary根据cat_id进行排序,使用的是临时表排序,如果将cat_id加上索引,那么cat_id已经排好序了,就不需要使用临时表来排序。(有可能加了索引还是使用了临时表,那是因为mysql做了自动优化.) mysql> alter table goods add index catid_index(cat_id); 对于C where c1=x and c4= x group by c3,c2
只用到c1索引,因为group by c3,c2的顺序无法利用c2,c3索引
mysql> explain select * from t4 where c1=1 and c4=2 group by c3,c2 \G
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234
key: c1234
key_len: 1 #只用到c1,因为先用c3后用c2分组,导致c2,c3索引没发挥作用
ref: const
rows: 1
Extra: Using where; Using temporary; Using filesort//并且还要排序 mysql> explain select * from t4 where c1=1 and c4=2 group by c2,c3 \G
id: 1
select_type: SIMPLE
table: t4
type: ref
possible_keys: c1234
key: c1234
key_len: 1
ref: const
rows: 1
Extra: Using where
1 row in set (0.00 sec)
1.2 hash索引(数据散的放的)
在memory表里,默认是hash索引,hash的理论查询时间复杂度为O(1),O(1)是说任意给一行,理论上一次就能够找到。 疑问: 既然hash的查找如此高效,为什么不都用hash索引?
答:1:hash函数计算后的结果是随机的,如果是在磁盘上放置数据,随机查询是非常慢的。虽然算这行数据在哪里算的很快,但是去取这行数据的时候就很慢。
比如主键为id为例, 那么随着id的增长, id对应的行,在磁盘上随机放置. 2: 不法对范围查询进行优化,随机的范围查找慢。 3: 无法利用前缀索引. 比如在btree中,field列的值"hellopworld并加索引查询xx=helloword,自然可以利用索引, xx=hello,也可以利用索引(左前缀索引),而利用hash索引,因为hash('helloword')和hash('hello')就是截然不同的结果,所以没法利用前缀优化。 4: 排序也无法利用hash索引来优化. 5: 必须回行.就是说 通过索引拿到数据位置,必须回到表中取数据
mysql优化-----多列索引的左前缀规则的更多相关文章
- 【转】MYSQL数据库四种索引类型的简单使用--MYSQL组合索引“最左前缀”原则
MYSQL数据库索引类型包括普通索引,唯一索引,主键索引与组合索引,这里对这些索引的做一些简单描述: (1)普通索引 这是最基本的MySQL数据库索引,它没有任何限制.它有以下几种创建方式: 创建索引 ...
- 转:SQL 索引最左前缀原理
表结构和索引列 假设数据库中表是这样的: 我们只考虑一张表employees.titles: 索引是(emp_no,title,from_date) SHOW INDEX FROM employee ...
- MySQL优化之避免索引失效的方法
在上一篇文章中,通过分析执行计划的字段说明,大体说了一下索引优化过程中的一些注意点,那么如何才能避免索引失效呢?本篇文章将来讨论这个问题. 避免索引失效的常见方法 1.对于复合索引的使用,应按照索引建 ...
- mysql之多列索引
mysql的多列索引是经常会遇到的问题,怎样才能有效命中索引,是本文要探讨的重点. 多列索引使用的Btree,也就是平衡二叉树.简单来说就是排好序的快速索引方式.它的原则就是要遵循左前缀索引. 多个索 ...
- 性能测试四十二:sql案例之联合索引最左前缀
联合索引:一个索引同时作用于多个字段 联合索引的最左前缀: A.B.C3个字段--联合索引 这个时候,可以使用的查询条件有:A.A+B.A+C.A+B+C,唯独不能使用B+C,即最左侧那个字段必须匹配 ...
- mysql 优化实例之索引创建
mysql 优化实例之索引创建 优化前: pt-query-degist分析结果: # Query 23: 0.00 QPS, 0.00x concurrency, ID 0x78761E301CC7 ...
- MySQL索引解析(联合索引/最左前缀/覆盖索引/索引下推)
本节内容: 1)索引基础 2)索引类型(Hash索引.有序数组.B+树) 3)索引的几个常见问题 1)联合索引 2)最左前缀原则 3)覆盖索引 4)索引下推 1. 索引基础 索引对查询的速度有着至关重 ...
- Mysql优化系列之索引性能
实际上,前面的数据类型和表结构设计优化不能算优化,只能算规范,也就是说在设计表的时候,应该且必须做到这些 索引是sql优化的核心部分,在<高性能Mysql>中单独抽出一章讲,也印证了其重要 ...
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
随机推荐
- response.sendRedirect()使用注意事项
用response.sendRedirect做转向其实是向浏览器发送一个特殊的Header,然后由浏览器来做转向,转到指定的页面,所以用sendRedirect时,浏览器的地址栏上可以看到地址的变化. ...
- PHP文件上传设置和处理(单文件)
<!--upload.php内容--><?php /* 修改php.ini的设置 file_uploads必须是On upload_max_filesize 设置上传文件的大小,此值 ...
- 【BZOJ2653】middle(主席树,二分)
题意:一个长度为n的序列a,设其排过序之后为b,其中位数定义为b[n/2],其中a,b从0开始标号,除法取下整. 给你一个长度为n的序列s. 回答Q个这样的询问:s的左端点在[a,b]之间,右端点在[ ...
- 定时任务-Quartz
Quartz Quartz w3c教程 参考:https://blog.csdn.net/lkl_csdn/article/details/73613033 Quartz 的使用 https://ww ...
- ROS下使用ASUS Xtion Pro Live
一.ROS官网hydro版本OpenNI安装 3. Installation 3.1 Ubuntu installation To install only openni_camera: sudo a ...
- Flink学习(一)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- 【Windows7】win7启动 报错 AutoIt错误,不能打开脚本文件
解决方法: 1.开始-->运行-->regedit 2.按照下图 3.
- android开发教程之使用线程实现视图平滑滚动示例
最近一直想做下拉刷新的效果,琢磨了好久,才走到通过onTouch方法把整个视图往下拉的步骤,接下来就是能拉下来,松开手要能滑回去啊.网上看了好久,没有找到详细的下拉刷新的例子,只有自己慢慢琢磨了.昨天 ...
- Thinking in React(翻译)
下面是React官方文档中的Thinking inReact文章的翻译,第一次翻译英文的文章,肯定有非常多不对的地方,还望多多包涵. 原文地址:https://facebook.github.io/r ...
- 怎么下载google商店的扩展程序?
首先,你有机会进入到了外网! 浏览器输入:chrome://extensions 复制唯一的ID进入:http://crx.2333.me/ ,然后下载即可!