HBase使用教程
1 基本介绍
1.1 前言
HBase – Hadoop Database。是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样。HBase在Hadoop之上提供了相似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
还有一个不同的是HBase基于列的而不是基于行的模式。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。利用HBase技术可在便宜PC
Server上搭建起大规模结构化存储集群。
2 安装和使用
2.1 下载
HBase的官方站点http://www.apache.org/dyn/closer.cgi/hbase/上面能够下载到各种版本号。眼下用最新版本号是0.98.2,建议下载stable文件夹下的稳定版本号。
2.2 安装
安装依赖基础要求
1. Linux操作系统
依据HBase的官方介绍。HBase没有在windows下測试过,因而,我们都是将HBase安装在Linux操作系统上。
我本机安装的Ubuntu 12.04的虚拟机。
2. Jdk
HBase须要jdk支持其运行。jdk版本号要求是1.6及其以上。
这里暂且把Linux虚拟机的安装和虚拟机上jdk的安装过程跳过,能够參照网上其它相关资料运行。
HBase的安装方法比較简单,将我们下载的HBase的安装包hbase-0.94.20.tar.gz复制到Linux的根文件夹下。
接着运行下面命令和配置。之后启动HBase:
1. 解压缩安装包
root@ubuntu:/# tar xfz hbase-0.94.20.tar.gz
root@ubuntu:/# cd hbase-0.94.20
2. 配置数据存储文件夹
正如官方文档描写叙述的那样,这时我们能够直接启动HBase,这种话,使用的数据存储文件夹为 /tmp/hbase-${user.name},也就意味着,我们一旦重新启动Linux。我们先前存储的数据就将丢失。
Linux下运行下面命令:
root@ubuntu:/# cd /hbase-0.94.20/conf/
root@ubuntu:/hbase-0.94.20/conf# vi hbase-site.xml
之后,改动配置文件内容为:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?
>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///hbase_data/hbase</value>
</property>
</configuration>
3. 启动HBase
root@ubuntu:/hbase-0.94.20/conf# ../bin/start-hbase.sh
starting master, logging to/hbase-0.94.20/bin/../logs/hbase-root-master-ubuntu.out
至此。单机模式启动HBase已经完毕了。HBase的停止脚本是同样文件夹下的stop-hbase.sh。
2.3 HBase安装模式
在上一节中我们提到,我们安装的是单机模式。单机模式表示,我们全部的服务都运行在一个JVM上,包含HBase和Zookeeper。
另外,HBase还有两种安装模式:伪分布式模式和分布式模式。
伪分布式模式是把进程运行在一台机器上。但不是一个JVM。
全然分布式模式就是把整个服务被分布在各个节点上了 。
伪分布式模式和分布式模式依赖安装较多其它组件和服务。安装过程较为复杂。将会在还有一篇文章中专门介绍。
3 開始一个样例
大多数技术人员happy的时候開始了。
我们開始一个简单的Helloworld。
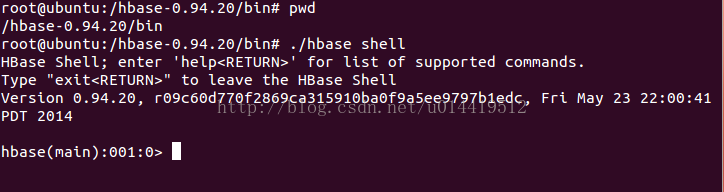
3.1 使用HBase shell连接HBase
使用HBase自带的client连接工具。连接到HBase:
3.2 创建User表
输入下面命令并运行:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
3.3 对User表简单地增删改查
往User表中插入一条信息:

查询刚才插入的信息:

3.4 检查数据存储文件夹
我们看一下之前我们配置的数据存储文件夹的变化:

我们能够看到,在之前配置的数据存储文件夹下。已经新加入了一些用于存储我们刚才存入的数据的文件了。
4 HBase基础定义和概念
4.1 表
HBase是一个数据库,数据以表的形式存储在Hbase中。
正如我们在hello world中定义中的User表相似,HBase的表的结构例如以下所看到的:
|
Row Key |
Time Stamp |
ColumnFamily contents |
ColumnFamily anchor |
|
"com.cnn.www" |
t9 |
|
anchor:cnnsi.com = "CNN" |
|
"com.cnn.www" |
t8 |
|
anchor:my.look.ca = "CNN.com" |
|
"com.cnn.www" |
t6 |
contents:html = "<html>..." |
|
|
"com.cnn.www" |
t5 |
contents:html = "<html>..." |
|
|
"com.cnn.www" |
t3 |
contents:html = "<html>..." |
|
4.2 行、列族、列
行以rowkey作为唯一标示。Rowkey是一段字节数组,这意味着,不论什么东西都能够保存进去,比如字符串、或者数字。行是按字典的排序由低到高存储在表中。
列族是列的集合。要准确表示一个列。须要“列族:列名”的方式。比如Hello world中的name列,应该被表示为“personalinfo:name”。
值得注意的是,列族被要求在创建表时指定,但列不须要,能够随时使用的时候创建。另外,一个列族的成员在文件系统上都存储在一起,因而列族中的全部列的存取方式都是一致的。
HBase的存储优化就都针对列族级别,比如,我们能够考虑将经常须要一起取出来分析的信息。都存储在一个列族上。
5 HBase经常使用的操作
为了方便大家开发过程中高速查询,这里分类介绍最常见的HBase命令。HBase shell中支持的全部命令,能够通过help命令来列举出来。例如以下所看到的:
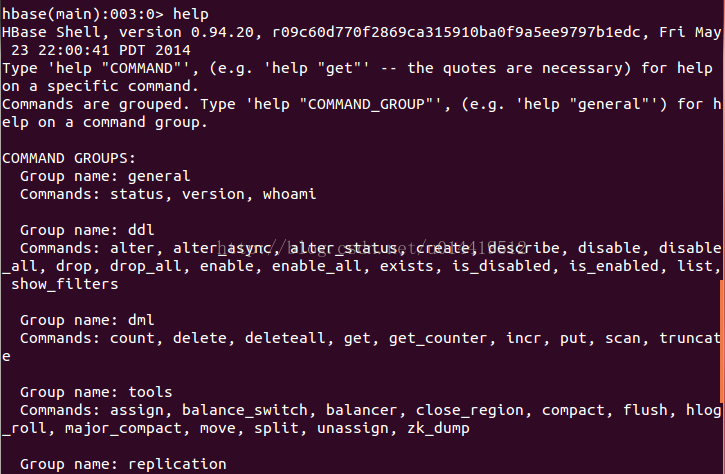
这里仅仅是截取了前部分命令。尚有部分命令不能再上图中显示。
5.1 一般命令
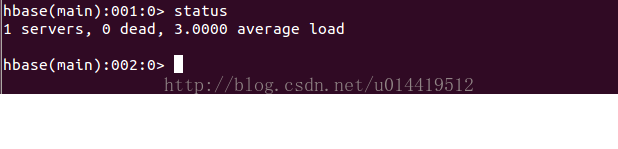
5.1.1 status
功能:查询server状态
使用:
5.1.2 version
功能:查询HBase版本号信息
使用:

5.1.3 whoami
功能:查看连接的用户
使用:

5.2 DDL命令
5.2.1 Create创建表
功能:创建一个表。正如之前提到的,创建一个表时,不指定详细的列名,但要指定列族名。
使用:create ‘表名’,’列族名1’,’列族名2’

5.2.2 disable失效表
功能:失效一个表。当须要改动表结构、删除表时,须要先运行此命令。
使用:

5.2.3 enable使失效表有效
功能:使表有效。
在失效表以后,须要运行此命令,以使得表可用。
使用:

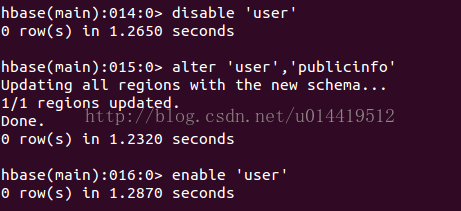
5.2.4 alter改动表结构
功能:改动表结构。包含新增列族、删除列族等
使用:
新增列族(记得在运行alter之前。要先disable表)
删除列族
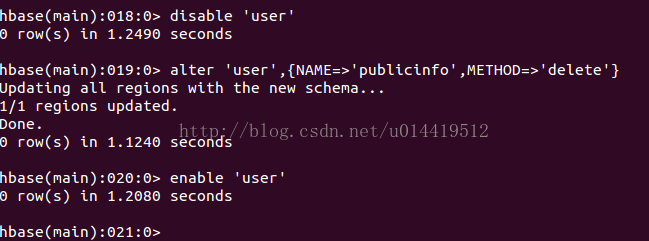
重命名列族
列族不能被重命名。重命名一个列族的通常途径是使用API创建一个有着期望名称的新的列族,然后将数据复制过去,最后再删除旧的列族。
5.2.5 describe查看表结构
功能:查看表结构
使用:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
5.2.6 list列举数据库中的全部表
功能:查看数据库中全部的表
使用:
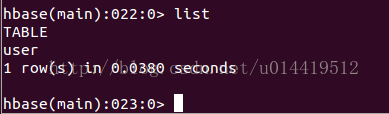
5.2.7 drop删除表
功能:删除指定的表
使用:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
5.3 DML命令
5.3.1 put插入数据
功能:插入一条数据到指定的表中。对于同一个rowkey,假设运行两次put,则第二次被觉得是更新操作。
使用:put ‘表名’,’列族名1:列名1’,’值’

5.3.2 get获取数据
功能:获取数据
使用:
获取指定rowkey的指定列族指定列的数据

获取指定rowkey的指定列族全部的数据
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
获取指定rowkey的全部数据
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
获取指定时间戳的数据

5.3.3 Count计算表的行数
功能:计算表的行数
使用:

5.3.4 put更新数据
详见5.3.1
5.3.5 scan全表扫描数据
功能:扫描全表全部数据
使用:

5.3.6 delete删除数据
功能:删除表中的数据
使用:
删除指定rowkey的指定列族的列名的数据
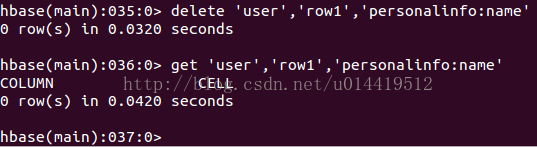
删除指定rowkey的指定列族的数据
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
5.3.7 deleteall删除整行数据
功能:删除整行数据
使用:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
5.3.8 truncate删除全表数据
功能:删除表中全部的数据。正如你看到的,在HBase的help命令里并没有
使用:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxNDQxOTUxMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" />
HBase使用教程的更多相关文章
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- 一条数据的HBase之旅,简明HBase入门教程-开篇
常见的HBase新手问题: 什么样的数据适合用HBase来存储? 既然HBase也是一个数据库,能否用它将现有系统中昂贵的Oracle替换掉? 存放于HBase中的数据记录,为何不直接存放于HDFS之 ...
- 【HBase基础教程】1、HBase之单机模式与伪分布式模式安装(转)
在这篇blog中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建hbase伪分布式环境的前提是我们已经搭建好了hadoop完全分布式环境,搭建ha ...
- Hbase入门教程--单节点伪分布式模式的安装与使用
Hbase入门简介 HBase是一个分布式的.面向列的开源数据库,该技术来源于 FayChang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像 ...
- HBase入门教程ppt
HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群.HBase利用Hado ...
- HBase入门教程
# 背景 最近看到公司一个项目用到hbase, 之前也一直想看下hbase.个人理解Hbase作为一个nosql数据库,逻辑模型感觉跟关系型数据库有点类似.一个table,有row即行,列.不过列是一 ...
- Ubuntu: GlusterFS+HBase安装教程
HBase通常安装在Hadoop HDFS上,但也能够安装在其它实现了Hadoop文件接口的分布式文件系统上.如KFS. glusterfs是一个集群文件系统可扩展到几peta-bytes. 它集合了 ...
- 一条数据的HBase之旅,简明HBase入门教程4:集群角色
[摘要] 本文主要介绍HBase与HDFS的关系,一些关键进程角色,以及在部署上的建议 HBase与HDFS 我们都知道HBase的数据是存储于HDFS里面的,相信大家也都有这么的认知: HBase是 ...
- 一条数据的HBase之旅,简明HBase入门教程3:适用场景
[摘要] 这篇文章继HBase数据模型之后,介绍HBase的适用场景,以及与一些关键场景有关的周边技术生态,最后给出了本文的示例数据 华为云上的NoSQL数据库服务CloudTable,基于Apach ...
随机推荐
- POJ 3258 River Hopscotch (二分法)
Description Every year the cows hold an event featuring a peculiar version of hopscotch that involve ...
- Oracle获取最近执行的SQL语句
注意:不是每次执行的语句都会记录(如果执行的语句是能在该表找到的则ORACLE不会再次记录,就是说本次执行的语句和上次或者说以前的语句一模一样则下面语句就查不出来的): select last_loa ...
- 大数据学习——linux常用命令(二)四
系统管理操作 1 挂载外部存储设备 可以挂载光盘.硬盘.磁带.光盘镜像文件等 1/ 挂载光驱 mkdir /mnt/cdrom 创建一个目录,用来挂载 mount -t iso9660 ...
- IDEA将Maven项目中src源代码下的xml配置文件编译进classes
遇到这样的情况,maven项目启动报错,src中某个包下面的xml文件找不到. eclipse编译项目会自动将xml配置文件编译进classes,IDEA却不行 在报错项目的pom.xml文件中添加: ...
- 12.3——类作用域,构造函数,友元,static类成员
类作用域: (1)成员函数在类外定义时,因为函数体还有形参列表都出现在成员名之后,都是在类作用域内定义,所以不用加域作用符 来引用其他的成员. (2)函数的返回值不一定需要在类的作用域中,但是若是返回 ...
- python-web apache mod_python 模块的安装
安装apache 下载mod_python 编译安装 测试 下载mod_python,下载地址:mod_python 在GitHub 上面, 下载之后:目录结构如下: 安装依赖: #查找可安装的依赖 ...
- 钱币兑换问题---hdu1284(完全背包)
Problem Description 在一个国家仅有1分,2分,3分硬币,将钱N兑换成硬币有很多种兑法.请你编程序计算出共有多少种兑法. Input 每行只有一个正整数N,N小于32768. ...
- java多线程编程01---------基本概念
一. java多线程编程基本概念--------基本概念 java多线程可以说是java基础中相对较难的部分,尤其是对于小白,次一系列文章的将会对多线程编程及其原理进行介绍,希望对正在多线程中碰壁的小 ...
- Spring Boot使用MyBatis 3打印SQL的配置
普通Spring下的XML文件配置: <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE co ...
- how to read openstack code: loading process
之前我们了解了neutron的结构,plugin 和 extension等信息.这一章我们看一下neutron如何加载这些plugin和extension.也就是neutron的启动过程.本文涉及的代 ...