Lucene 6.5.0 入门Demo
Lucene 6.5.0 要求jdk 1.8
1.目录结构;
2.数据库环境;

private int id;
private String name;
private float price;
private String pic;
private String description
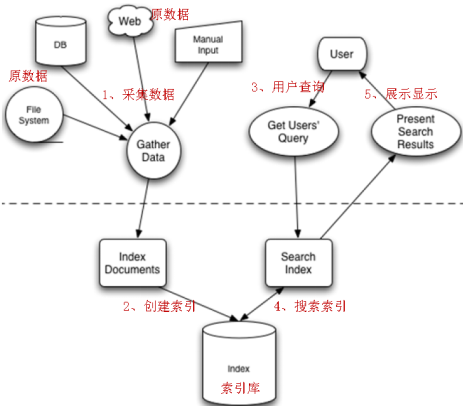
3.
Lucene是Apache的一个全文检索引擎工具包,它不能独立运行,不能单独对外提供服务。
/**
* Created by on 2017/4/25.
*/
public class IndexManager {
@Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks(); // 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<Document>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// Field id = new TextField("id", book.getId().toString(), Store.YES); Field id = new TextField("id", Integer.toString(book.getId()), Field.Store.YES);
// 图书名称
Field name = new TextField("name", book.getName(), Field.Store.YES);
// 图书价格
Field price = new TextField("price", Float.toString(book.getPrice()), Field.Store.YES);
// 图书图片地址
Field pic = new TextField("pic", book.getPic(), Field.Store.YES);
// 图书描述
Field description = new TextField("description", book.getDescription(), Field.Store.YES); // 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description); docList.add(document);
}
//JDK 1.7以后 open只能接收Path///////////////////////////////////////////////////// // 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer(); // 创建IndexWriter
// IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_6_5_0,analyzer);
IndexWriterConfig cfg = new IndexWriterConfig(analyzer); // 指定索引库的地址
// File indexFile = new File("D:\\L\a\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\")); IndexWriter writer = new IndexWriter(directory, cfg);
writer.deleteAll(); //清除以前的index
// 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
} // 关闭writer
writer.close();
} }
/**
* Created by on 2017/4/25.
*/
public class IndexSearch {
private void doSearch(Query query) {
// 创建IndexSearcher
// 指定索引库的地址
try {
// File indexFile = new File("D:\\Lpj\\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
// 1、创建Directory
//JDK 1.7以后 open只能接收Path
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 10); // 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
System.out.println("匹配出的记录总数:" + count);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc; // 通过ID获取文档
Document doc = searcher.doc(docId);
System.out.println("商品ID:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("name"));
System.out.println("商品价格:" + doc.get("price"));
System.out.println("商品图片地址:" + doc.get("pic"));
System.out.println("==========================");
// System.out.println("商品描述:" + doc.get("description"));
}
// 关闭资源
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
} @Test
public void indexSearch() throws Exception {
// 创建query对象
Analyzer analyzer = new StandardAnalyzer();
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("description", analyzer); // 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("description:java AND lucene"); doSearch(query); }

Lucene 6.5.0 入门Demo的更多相关文章
- Lucene 6.5.0 入门Demo(2)
参考文档:http://lucene.apache.org/core/6_5_0/core/overview-summary.html#overview.description 对于path路径不是很 ...
- vue入门 0 小demo (挂载点、模板、实例)
vue入门 0 小demo (挂载点.模板) 用直接的引用vue.js 首先 讲几个基本的概念 1.挂载点即el:vue 实例化时 元素挂靠的地方. 2.模板 即template:vue 实例化时挂 ...
- Omnet++ 4.0 入门实例教程
http://blog.sina.com.cn/s/blog_8a2bb17d01018npf.html 在网上找到的一个讲解omnet++的实例, 是4.0下面实现的. 我在4.2上试了试,可以用. ...
- spring web flow 2.0入门(转)
Spring Web Flow 2.0 入门 一.Spring Web Flow 入门demo(一)简单页面跳转 附源码(转) 二.Spring Web Flow 入门demo(二)与业务结合 附源码 ...
- 【SSH系列】初识spring+入门demo
学习过了hibernate,也就是冬天,经过一个冬天的冬眠,当春风吹绿大地,万物复苏,我们迎来了spring,在前面的一系列博文中,小编介绍hibernate的相关知识,接下来的博文中,小编将继续介绍 ...
- 基于springboot构建dubbo的入门demo
之前记录了构建dubbo入门demo所需的环境以及基于普通maven项目构建dubbo的入门案例,今天记录在这些的基础上基于springboot来构建dubbo的入门demo:众所周知,springb ...
- lua入门demo(HelloWorld+redis读取)
1. lua入门demo 1.1. 入门之Hello World!! 由于我习惯用docker安装各种软件,这次的lua脚本也是运行在docker容器上 openresty是nginx+lua的各种模 ...
- netty入门demo(一)
目录 前言 正文 代码部分 服务端 客服端 测试结果一: 解决粘包,拆包的问题 总结 前言 最近做一个项目: 大概需求: 多个温度传感器不断向java服务发送温度数据,该传感器采用socket发送数据 ...
- canal入门Demo
关于canal具体的原理,以及应用场景,可以参考开发文档:https://github.com/alibaba/canal 下面给出canal的入门Demo (一)部署canal服务器 可以参考官方文 ...
随机推荐
- Bootstrap-datepicker设置开始时间结束时间范围
$('.form_datetime').datepicker({ format: 'yyyy-mm-dd', weekStart: 1, startDate: '+1', endD ...
- Qt+事件的接收和忽略
事件的接收与忽略的示意图如下图: 依据前面的知识,事件是可以依据情况进行接收和忽略的,事件的传播是组件层次上面的,而不是依靠类继承机制.在一个特殊的情形下,我们必须使用accept()和ignore( ...
- js解析器
1>js的预解析 找var function 参数等 所有的变量,在正式运行代码前,都提前赋了一个值:未定义 所有的函数,在正式运行代码前,都是整个函数块. 遇到重名的:只留一个 如果变量与函数 ...
- 【linux】【git】安装/升级Git 1.9.4
因为yum源的最新版本是1.7.x,所以无法通过yum进行更新,下面描述如何通过编译源码进行安装 1.安装需要的依赖 第一步我们需要做的就是确认系统已经安装了编译git时需要的依赖.使用下面的安装 ...
- Java基础知识:集合框架
*本文是最近学习到的知识的记录以及分享,算不上原创. *参考文献见链接. 目录 集合框架 Collection接口 Map接口 集合的工具类 这篇文章只大致回顾一下Java的总体框架. 集合框架 ht ...
- Python中正则表达式讲解
正则表达式是匹配字符串的强大武器,它的核心思想是给字符串定义规则,凡是符合规则的字符串就是匹配了,否则就是不合法的.在介绍Python的用法之前,我们先讲解一下正则表达式的规则,然后再介绍在Pytho ...
- chardet使用方法
简单用法 chardet的使用非常简单,主模块里面只有一个函数detect.detect有一个参数,要求是bytes类型.bytes类型可以通过读取网页内容.open函数的rb模式.带b前缀的字符串. ...
- Django模板语言中的自定义方法filter过滤器实现web网页的瀑布流
模板语言自定义方法介绍 自定义方法注意事项 Django中有simple_tag 和 filter 两种自定义方法,之前也提到过,需要注意的是 扩展目录名称必须是templatetags templa ...
- websphere8.5 与cxf2.x冲突问题
一个客户was部署的小问题,记录一下. 问题现象 在我们的服务中用调用别人的webservice服务报错,框架用的cxf. 报错关键信息有: E com.ibm.ws.webcontainer.web ...
- log4j动态日志级别调整
1. 针对root logger的设置 log4j.rootLogger=INFO, CONSOLELogger.getRootLogger().setLevel(org.apache.log4j.L ...