Hadoop三种模的安装配置过程
JDK+Hadoop安装配置、单机模式配置
以下操作在SecureCRT里面完成
1.关闭防火墙
firewall-cmd --state 显示防火墙状态running/not running
systemctl stop firewalld 临时关闭防火墙,每次开机重新开启防火墙
systemctl disable firewalld 禁止防火墙服务。
2.传输JDK和HADOOP压缩包
SecureCRT 【File】→【Connect SFTP Session】开启sftp操作
put jdk-8u121-linux-x64.tar.gz
put hadoop-2.7.3.tar.gz
传输文件从本地当前路径(Windows)到当前路径(Linux)


3.解压JDK、HADOOP
tar -zxvf jdk-8u121-linux-x64.tar.gz -C /opt/module 解压安装
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/module 解压安装
mkdir module
4.配置JDK并生效
vi /etc/profile文件添加:
export JAVA_HOME=/opt/module/jdk1.8.0_121
export PATH=$JAVA_HOME/bin:$PATH
Esc :wq!保存并退出。不需要配置CLASSPATH。
source /etc/profile配置生效
运行命令javac,检验是否成功。
5.配置HADOOP并生效
vi /etc/profile文件添加:
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
Esc :wq!保存并退出。
source /etc/profile配置生效
运行命令hadoop,检验是否成功。
5.单机模式配置hadoop -env.sh
vi /opt/module/hadoop-2.7.3/etc/hadoop/hadoop-env.sh文件修改
显示行号 Esc :set number 取消行号Esc :set nonumber
修改第25行export JAVA_HOME=/opt/module/jdk1.8.0_121
Esc :wq!保存并退出
本地模式没有HDFS和Yarn,配置JDK后MapReduce能够运行java程序。
6.运行自带程序wordcount
cd /opt/module/hadoop-2.7.3/share/hadoop/mapreduce 转入wordcount所在路径。
创建adir文件夹:
hadoop fs -mkdir /adir
查看所创建的文件:
hadoop fs -ls /
运行touch in.txt,创建In.txt文件,作为输入文件。
(如果in.txt是空文件,运行vi in.txt,输入内容作为被统计词频的输入文件)
传输in.txt文件到adir
hadoop fs -put in.txt /adir
查看in.txt是否传到adir里:
hadoop fs -ls /adir
输出目录/output必须不存在,程序运行后自动创建。
运行wordcount:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /adir/in.txt output/
运行成功之后,进入/output目录,打开文件part-r-00000查看计数结果。
hadoop fs -cat /user/root/output/part-r-00000
Hadoop伪分布式模式配置
只有一台虚拟机bigdata128,既是namenode又是datanode。
一、基础安装配置
完成上述1-5安装配置。
二、修改以下5个配置文件
在<configuration>与</configuration>之间添加如下property:
①core-site.xml
<!--配置HDFS主节点,namenode的地址,9000是RPC通信端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata128:9000</value>
</property>
<!--配置HDFS数据块和元数据保存的目录,一定要修改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.3/tmp</value>
</property>
②hdfs-site.xml
<!--注释配置数据块的冗余度,默认是3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--secondaryNameNode的主机地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata128:50090</value>
</property>
③mapred-site.xml(该配置文件不存在,先复制)
cp mapred-site.xml.template mapred-site.xml
<!--配置MR程序运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
④yarn-site.xml
<!--配置Yarn的节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata128</value>
</property>
<!--NodeManager执行MR任务的方式是Shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
⑤Slaves文件里使用默认localhost,或者添加 bigdata128(既是NameNode又是DataNode)
注:如果Slaves文件为空,就没有DataNode和NodeManager。
⑥修改\etc\hosts配置文件
运行命令 vi \etc hosts
注释掉已有内容,添加虚拟机的ip及对应主机名:
192.168.163.128 bigdata128
⑦修改\etc\hostname配置文件
运行命令 vi \etc hostname
添加虚拟机的主机名:
bigdata128
重启虚拟机,主机名生效。
三、格式化
hdfs namenode -format (如果不是第一次格式化,格式化之前先删除/opt/module/hadoop-2.7.3/下面的tmp、logs两个目录)
四、启动
start-all.sh (如果启动之前已经启动过,启动之前先停止stop-all.sh)(启动记得关闭防火墙)
查看伪分布式配置是否成功:
①执行ll,查看/opt/module/hadoop-2.7.3/tmp/dfs目录,如下图所示,则正确。
②执行jps,如下图所示,NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager如果全部启动,伪分布式配置成功。

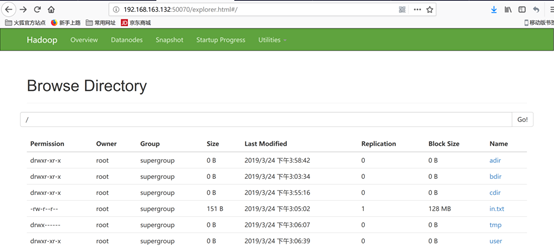
③web控制台访问:http://192.168.163.132:50070 、http://192.168.163.132:8088
页面正常显示,则成功。
五、运行wordcount
hdfs dfs -put in.txt /adir 上传本地当前路径下的in.txt文件 到hdfs的/adir目录下。
运行hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /adir/in.txt output/。
在http://192.168.163.132:50070 查看/user/root/output/part-r-00000文件里的词频统计结果。
六、SSH免密码登陆(解决每次启动hadoop输入用户密码问题)
生成公、私密钥对:ssh-keygen -t rsa 按3次回车键
查看:cd ~/.ssh路径下面的id_rsa和id_rsa.pub
复制:ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata128
查看生成authorized_keys。
Hadoop完全分布式模式配置
一、新建另外两台Linux虚拟机
完全分布式模式共三台虚拟机,前述伪分布式的虚拟机(bigdata128)作为master主节点,克隆另外两个虚拟机(bigdata129、bigdata131)作为slaves子节点,克隆机自带安装JDK、Hadoop及配置文件。
注:此配置是为学习所用,且电脑资源有限,因此照搬伪分布式配置,将NameNode、SecondaryNameNode、ResourceManager全部配置在主节点bigdata128上面,实际情况则相反,应该分别配置在不同的节点上面。
二、修改以下配置文件
①slaves配置文件
三台虚拟机分别都运行命令 vi /opt/module/hadoop-2.7.3/etc/hadoop slaves
修改slaves为:
bigdata129
bigdata131
②修改\etc\hosts配置文件
三台虚拟机分别都运行命令 vi \etc hosts
注释已有内容,添加集群三台虚拟机的ip及对应主机名:
192.168.163.128 bigdata128
192.168.163.129 bigdata129
192.168.163.131 bigdata131
③修改\etc\hostname配置文件
三台虚拟机分别都运行命令 vi \etc hostname
添加各自的主机名bigdata128或者bigdata129或者bigdata131。
重启全部虚拟机,主机名生效。
三、格式化
在主节点bigdata128上面输入格式化命令(hdfs namenode -format),格式化集群。
注:如果不是第一次格式化,三台虚拟机都删除\opt\module\hadoop-2.7.3\下面的tmp、logs目录:rm –rf \opt\module\hadoop-2.7.3\tmp rm –rf \opt\module\hadoop-2.7.3\logs
注:如果格式化之前启动过集群,先在主节点bigdata128上面停止集群(stop-all.sh),再格式化。
四、启动集群
在主节点bigdata128上面输入启动命令(start-all.sh),启动集群。
注:如果启动之前启动过集群,先在主节点bigdata128上面停止集群(stop-all.sh),再启动。
启动正常,输入jps命令,显示如下:

启动正常jps显示3台主机如上如下

启动正常目录显示如下:

web控制台访问:http://192.168.163.132:50070 、http://192.168.163.132:8088
页面正常显示,则成功。
五、运行wordcount
hdfs dfs -put in.txt /adir 上传本地当前路径下的in.txt文件 到hdfs的/adir目录下。
运行hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /adir/in.txt output/。
在http://192.168.163.132:50070 查看/user/root/output/part-r-00000文件里的词频统计结果。
如下图所示:

Hadoop三种模的安装配置过程的更多相关文章
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- Hadoop三种架构介绍及搭建
apache hadoop三种架构介绍(standAlone,伪分布,分布式环境介绍以及安装) hadoop 文档 http://hadoop.apache.org/docs/ 1.StandAlo ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- httpd2.4.6三种工作模式(如何配置),防止占用内存暴增的策略
之前偷懒默认用yum安装了httpd.后来发现服务器内存暴增,一度达到75% 打开一看,好嘛后台休眠进程全是httpd. 重启之后再度访问发现内存还是稳步增长. [root@iz2ze3ayxs2yp ...
- Hadoop集群搭建-05安装配置YARN
Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hadoop集群搭建-01前期准备 先保证集群5台虚 ...
- WAMP(Windows、Apache、MySQL、php)安装配置过程常见问题
WAMP(Windows.Apache.MySQL.php)安装配置过程 可以参考该网友的总结(总结的不错,鼓掌!!): http://www.cnblogs.com/pharen/archive/2 ...
- LAMP安装配置过程
Mysql ./configure --prefix=/usr/local/mysql (注意/configure前有“.”,是用来检测你的安装平台的目标特征的,prefix是安装路径) #make ...
- Hadoop 系列(二)安装配置
Hadoop 系列(二)安装配置 Hadoop 官网:http://hadoop.apache.or 一.Hadoop 安装 1.1 Hadoop 依赖的组件 JDK :从 Oracle 官网下载,设 ...
随机推荐
- (转发)IOS高级开发~Runtime(一)
IOS高级开发-Runtime(一) IOS高级开发-Runtime(二) IOS高级开发-Runtime(三) IOS高级开发-Runtime(四) 一些公用类: @interface Custom ...
- ios之UISlider
初始化一个Slider UISlider *slider = [[UISlider alloc]initWithFrame:CGRectMake(0, 400,320 , 20)]; 滑块是一个标 ...
- (39)zabbix snmp自定义OID nginx监控实例
为什么要自定义OID? 前面的文章已经讲过zabbix如何使用snmp监控服务器,但是他有一个很明显的局限性:只能监控定义好的OID项目 假如我们想知道nginx进程是否在运行?在没有zabbix a ...
- CSS3的border-image
border-image:none|image-url|number|percentage|stretch,repeat,round 参数: none:默认,无背景图片 url:地址,可以为绝对,也可 ...
- logging日志模块,四种方式
1.最简单的用法 import logging logging.error("hah") logging.info("hah") logging.debug(& ...
- jQuery和Vue
jQuery 概述 是js的一种函数库有美国人 John Resig编写 特点 写的少,做的多,国内用的jq1.0版本,可以兼容低版本的浏览器,支持链式编程或链式调用和隐式迭代 链式编程 $(this ...
- Solr通过配DIH对数据库数据做索引
1 加入相关jar包 将2个相关jar包复制到/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib文件夹下 jar包名称 solr-dataimp ...
- Android开发——Android的消息机制详解
)子线程默认是没有Looper的,Handler创建前,必须手动创建,否则会报错.通过Looper.prepare()即可为当前线程创建一个Looper,并通过Looper.loop()来开启消息循环 ...
- xhtml css 漏 整理
1)文档类型 代码最上部有如下这句话: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" &quo ...
- js--如何判别 null undefined
收集资料如下判断: 1.判断undefined: ? 1 2 3 4 var tmp = undefined; if (typeof(tmp) == "undefined"){ a ...