Spark学习笔记1:Application,Driver,Job,Task,Stage理解
看了spark的原始论文和相关资料,对spark中的一些经常用到的术语做了一些梳理,记录下。
1,Application
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
2,Driver
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。

3,Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4, Task
Task是Spark中最新的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务是一个Task。
5, Stage
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点。从spark的论文中的两张截图,可以清楚的理解宽窄依赖以及stage的划分。
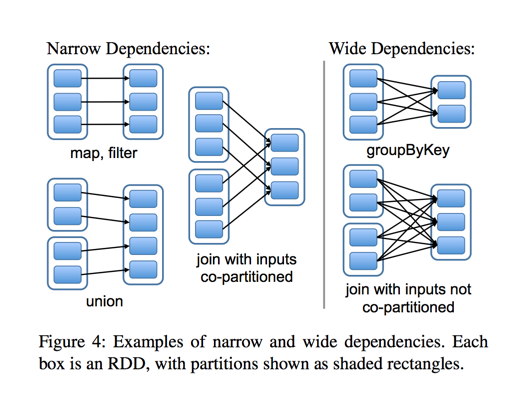
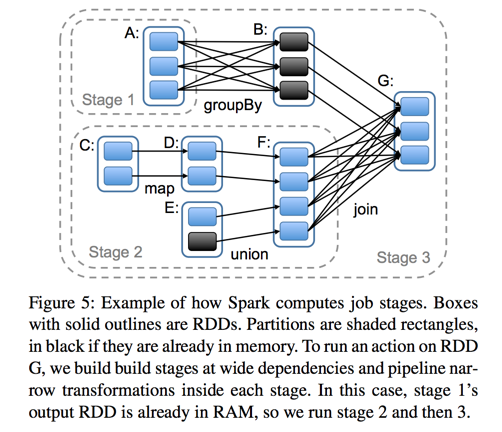
至于为什么这么划分,主要是宽窄依赖在容错恢复以及处理性能上的差异(宽依赖需要进行shuffer)导致的。
关于spark这几个术语的了解暂时就这么多,可能不是很到位,不过暂且就这么多了。
Spark学习笔记1:Application,Driver,Job,Task,Stage理解的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Self-Host c#学习笔记之Application.DoEvents应用 不用IIS也能執行ASP.NET Web API
Self-Host 寄宿Web API 不一定需要IIS 的支持,我们可以采用Self Host 的方式使用任意类型的应用程序(控制台.Windows Forms 应用.WPF 应用甚至是Wind ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- [bzoj2058][Usaco2010 Nov]Cow Photographs_树状数组_动态规划
Cow Photographs bzoj-2058 Usaco-2010 Nov 题目大意:给定一个n的排列.每次操作可以交换相邻两个数.问将序列变成一个:$i,i+1,i+2,...,n,1,2,. ...
- Hive之执行计划分析(explain)
Hive是通过把sql转换成对应mapreduce程序,然后提交到Hadoop上执行,查看具体的执行计划可以通过执行explain sql知晓 一条sql会被转化成由多个阶段组成的步骤,每个步骤有执行 ...
- 【转】golang中的并行与并发
原文:http://blog.csdn.net/taohaoge/article/details/27970421 ------------------------------------------ ...
- GNS3配置SecureCRT
C:\SecureCRT\SecureCRT.exe /script D:\GNS3\DyRouter.vbs /T /telnet 127.0.0.1 %p "D:\Program Fil ...
- 手动加入SSH支持、使用c3p0
之前做的笔记,如今整理一下.大家有耐心的跟着做就能成功: SSH(struts2.spring.hibernate) * struts2 * 充当mvc的角色 * hibernate ...
- C#项目的生成事件及批处理文件
一个C#项目,如果为同一个解决方案的其他项目所引用,则其编译后,会将DLL拷贝到引用项目中:但如果它并不被其他项目引用,但又想编译后能够自动将生成的东西拷贝过去,可以在项目的生成事件中,写上一些批处理 ...
- 2016/2/19 css样式表 Cascading Style Sheet 叠层样式表 美化HTML网页
一.样式表 (一)样式表的分类 1.内联样式表 和HTML联合显示,控制精确,但是可重用性差,冗余较多. 例:<p style="font-size:14px;">内联 ...
- HDU 5000 2014 ACM/ICPC Asia Regional Anshan Online DP
Clone Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/65536K (Java/Other) Total Submiss ...
- SemaphoreSlim
https://msdn.microsoft.com/en-us/library/system.threading.semaphoreslim(v=vs.110).aspx Represents a ...
- flash builder 4.6 下载完成后安装不成功
从网上下载了一下flash builder 4.6 下载完成后安装不成功,说是有一个安装被挂起,不成安装成功结果从注册表中删除了pendingobject,还是不行,没有办法,从网上搜了一下,发现了大 ...