利用Spinnaker创建持续交付流水线
在Pivotal Container Service (PKS)上部署软件的方法多种多样,本文重点介绍如何使用Spinnaker在PKS(或任何Kubernetes群集)上进行持续交付。
Pivotal Container Service是一个由Pivotal构建的平台,用于减轻部署和运维Kubernetes群集的负担。PKS基于Cloud Foundry的容器运行环境(以前称为“Kubo”)而构建,利用BOSH为Kubernetes处理初始和后续运维。
PKS却并不仅仅是Kubernetes的另一个分支。它是一种按需服务,能够部署和管理Kubernetes群集。这类似于Google Container Engine (GKE)等公有云提供商提供的服务。因此,Kubernetes运维人员能够根据其业务要求决定如何使用Kubernetes,减少运维开销和管理群集所需的日常冗务,使其比本地Kubernetes部署更贴近业务要求。
PKS可轻松与VMWare集成。通过与VMWare管理整个部署,包括对必要的虚拟机进行编排,它可以在您自己的数据中心内为您提供与GKE类似的体验,不必为构建和安装物理或虚拟服务器劳力费神。
Spinnaker简介
Spinnaker是一款企业级持续交付工具,最初由Netflix构建,是优秀的项目套件Netflix OSS的一部分,用于部署Netflix应用。它是一个开源的多云持续交付平台,能够帮助开发人员快速、自信地发布软件更改。
Spinnaker将云原生部署策略视为一类构造,处理底层编排,比如验证健康检查、禁用旧服务器群组和启用新服务器群组。Spinnaker支持红/黑(又名“蓝/绿”)策略,以及在实时开发中实行红/黑和金丝雀策略。
我的PKS Lab
我在Google Compute Engine上运行Pivotal Container Service,并使用pks cli创建了三个群集:一个运行Spinnaker的群集叫做“cicd”,另一个是只针对开发运行一个K8s Master的small群集,第三个是针对生产的大一些的HA群集。


部署Spinnaker
在使用Spinnaker与Kubernetes之前,我需要进行部署。Spinnaker随附一个叫做Halyard的工具,能够帮助安装。对于不想过多深入的用户,他们提供了一些快速入门选项。我选择使用快速入门指南中的Helm Chart。
在Spinnaker配置(通过Helm变量实现)中,我可以配置对Docker注册表、Git Repo和Kubernetes群集的访问权限/凭证。利用Helm,安装变得非常简单:
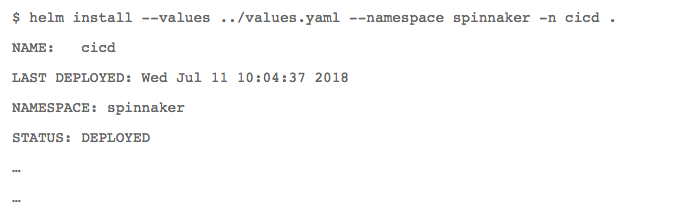
备注:
1.需要创建2个端口转发通道,以便访问Spinnaker UI:
export DECK_POD=$(kubectl get pods --namespace spinnaker -l "component=deck,app=cicd-spinnaker" -o jsonpath="{.items[0].metadata.name}")
kubectl port-forward --namespace spinnaker $DECK_POD 9000
2.打开浏览器,访问Spinnaker UI:
http://127.0.0.1:9000
有关Spinnaker与Kubernetes集成的更多信息,请访问:
http://www.spinnaker.io/docs/kubernetes-source-to-prod
几分钟后,所有单元都可以启动和正常运行,并且可供使用:

Hello World
还需要一个要部署的应用,挑选一个与实际应用没有相似之处的示例应用:比如用Go编写的Hello World应用。只要应用有Dockerfile,而且知道它监听的端口,就可以选择任何应用。如果有数据库后端,则需要考虑更多关于部署流水线的注意事项。
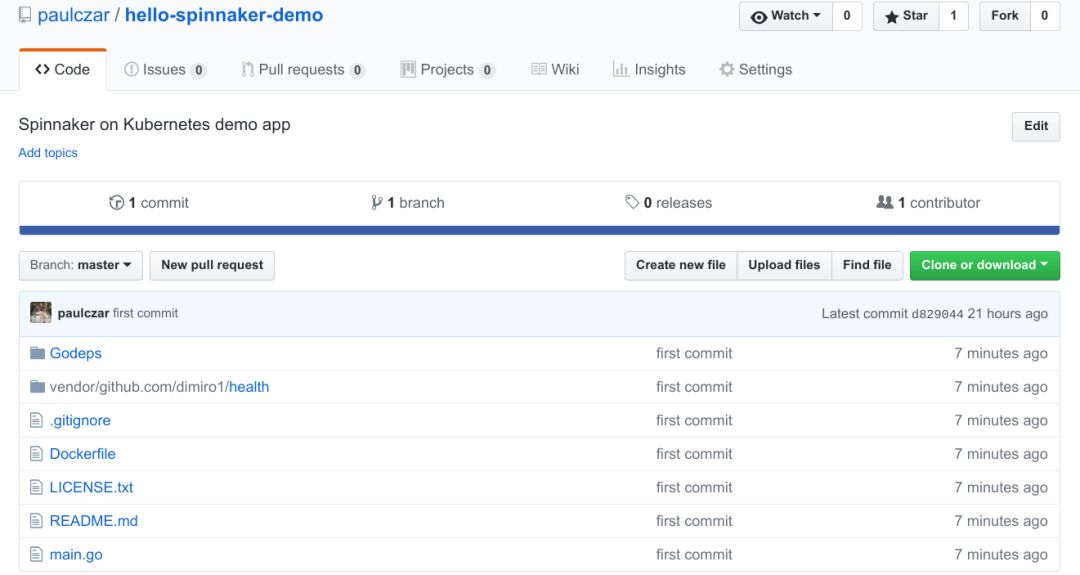
我们还需要为镜像设置自动构建。虽然可以使用Spinnaker构建镜像,但建议使用Docker注册表提供的自动构建工具。所以我在Docker Hub上为此存储库创建了自动构建,将它设置为不仅在Master上构建,还在创建标签时构建。这样一来,可以在Spinnaker中将标签用作一种发布机制。
使用Spinnaker部署Hello World
1.创建Spinnaker应用
使用之前创建的端口转发转到Spinnaker中的一个应用。应用是Spinnaker在您的云提供商(在本例中是Kubernetes)中管理的一组资源。如果有多个应用,可以将它们归纳到项目中,但我们目前暂时将其简化,跳过项目。
在Spinnaker UI顶部的菜单中单击“Applications”。会看到有些应用已在运行。这是因为Spinnaker会将运行中的单元(或其他Kubernetes资源)显示为应用。
在窗口右上角的“Actions”下,单击“Create Application”。
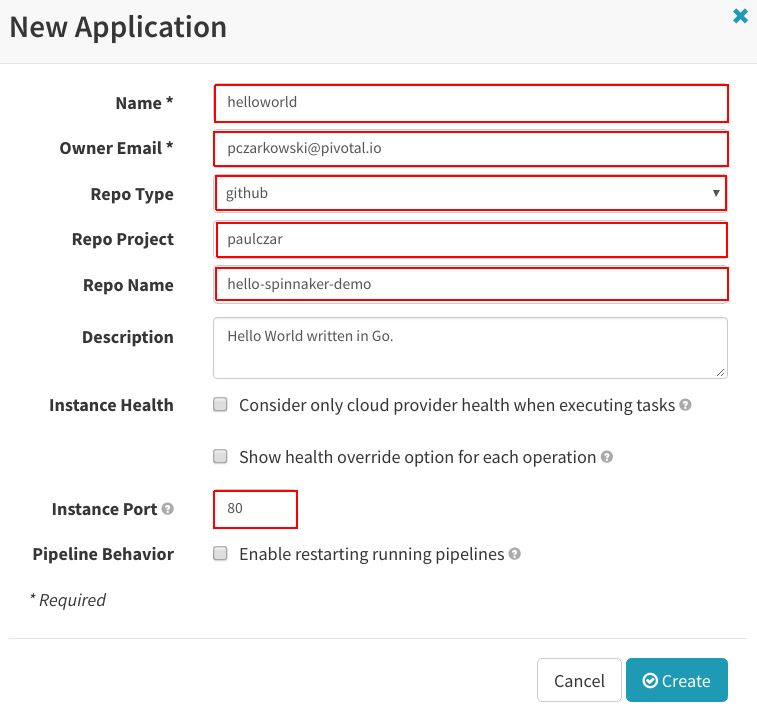
为该应用命名,将“Repo Type”设置为“github”,将“Repo Project”设置为github的用户名,将“Repo Name”设置为Repo的名称。将“Instance Port”设置为“80”并点击“Create”:
创建完成后,您将进入新应用的群集部分,该部分应该显示为空。群集是服务器群组的集合,这些服务器群组运行同一应用的不同版本。服务器群组是Kubernetes中运行的应用,可以是ReplicaSet或Deployment。
2.创建服务器群组
单击右上角的“+”按钮,创建第一个服务器群组:

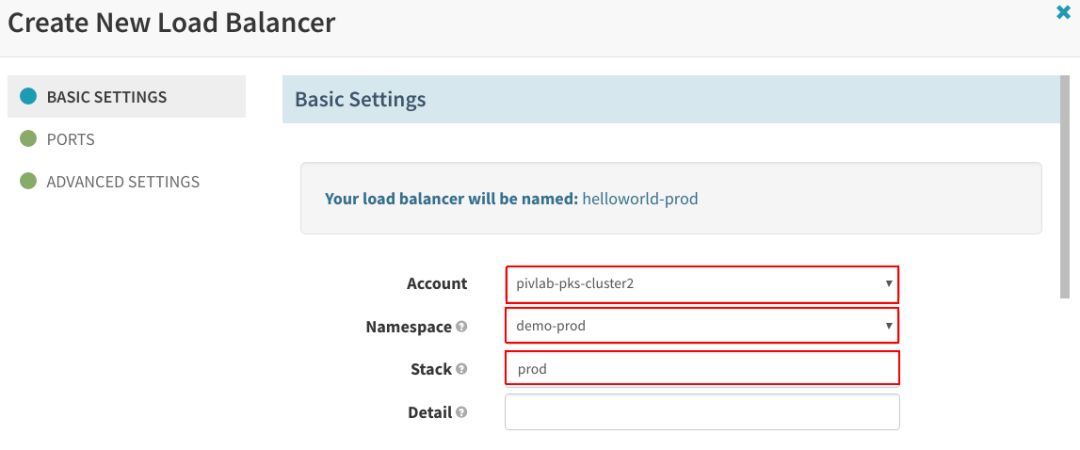
这里提供了大量的配置选项。所幸,对于如此简单的应用,我们不必担心大多数选项。在“Basic Settings”下,我们需要设置应用运行所在的“Account”(Kubernetes群集)和“Namespace”(Kubernetes命名空间)。还可以为“服务器群组”指定“Stack”,帮助为运行中的应用版本命名;指定一个或多个要运行的容器(可从可用的Docker注册表和您使用Spinnaker配置的存储库中选择):
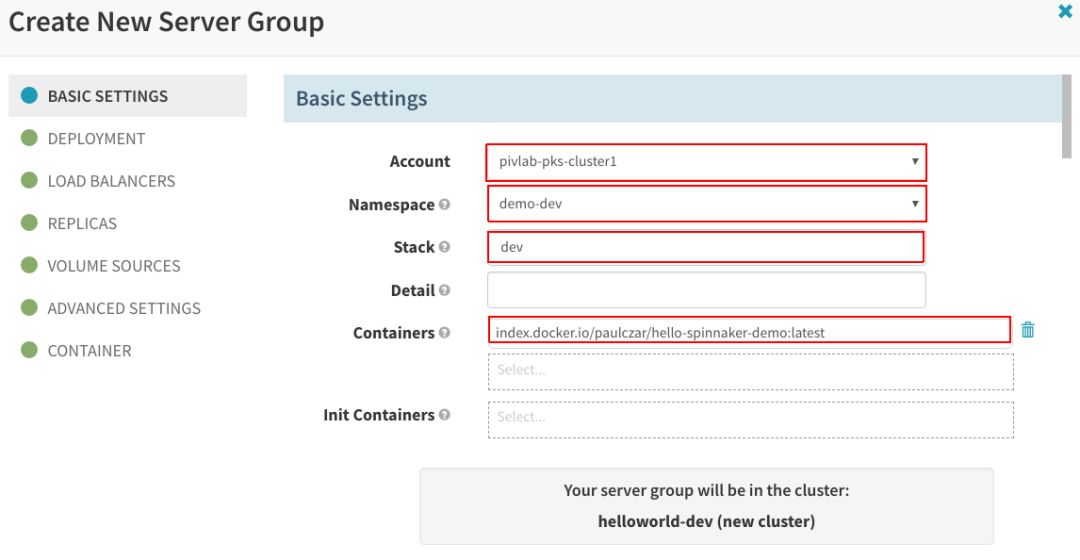
在“CONTAINER”部分,需要指定应用在容器中监听的“Container Port”:
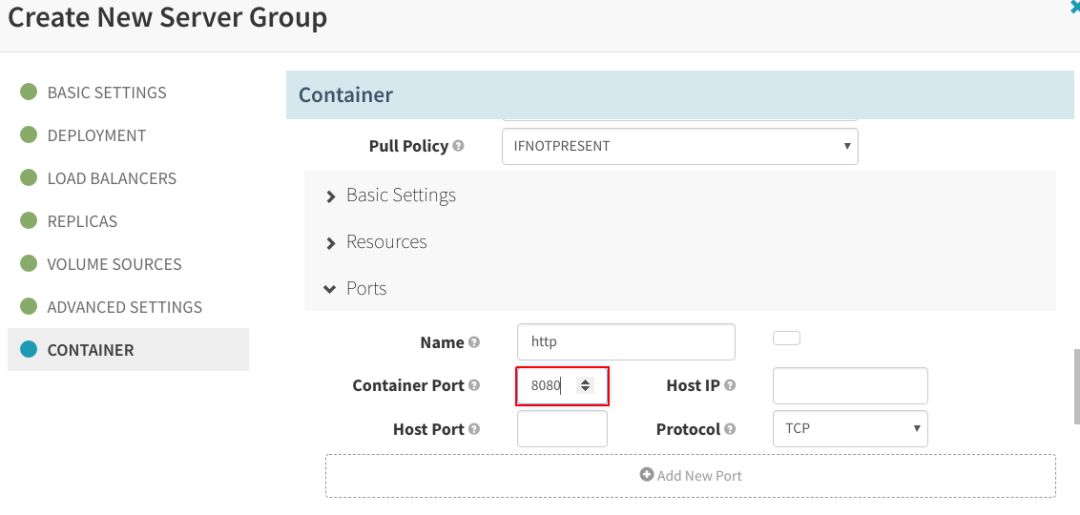
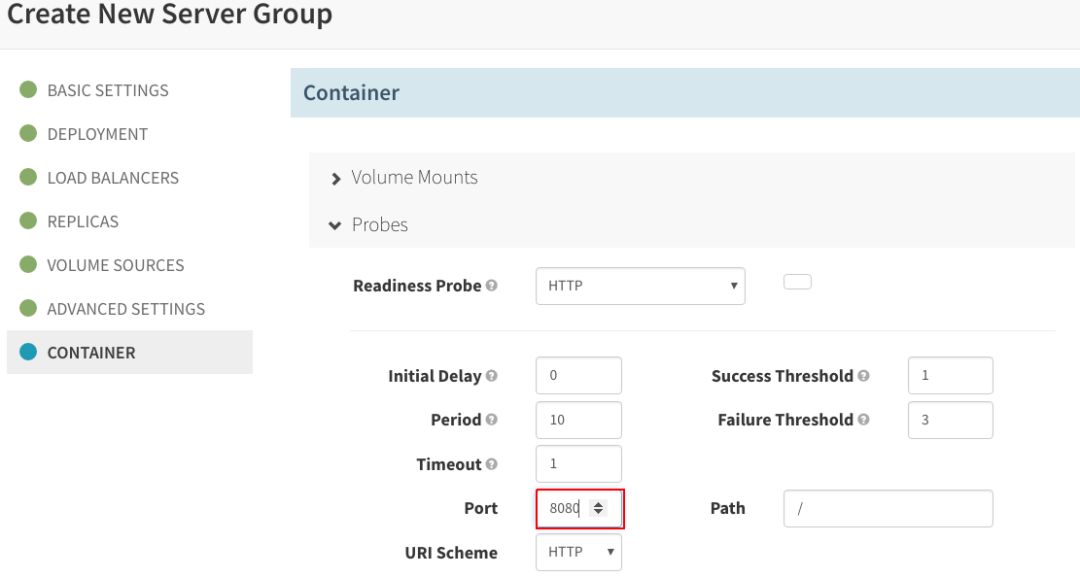
此外,在“CONTAINER”部分,单击“Enable Readiness Probe”,将它配置为同一个端口:
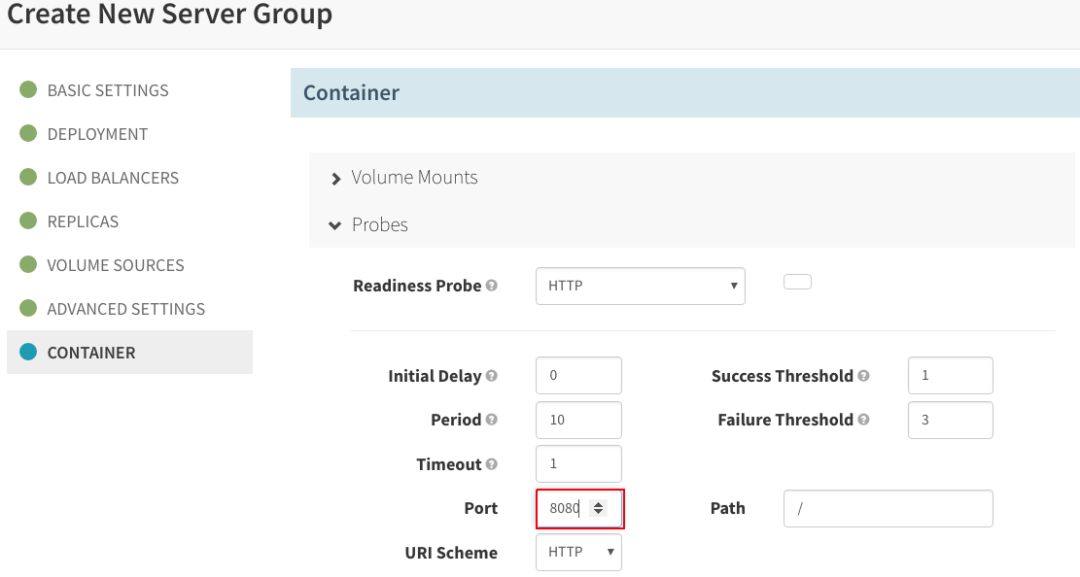
单击“Create”,等待几分钟,以便Spinnaker部署您的应用:

部署服务器群组后,将返回群集界面:
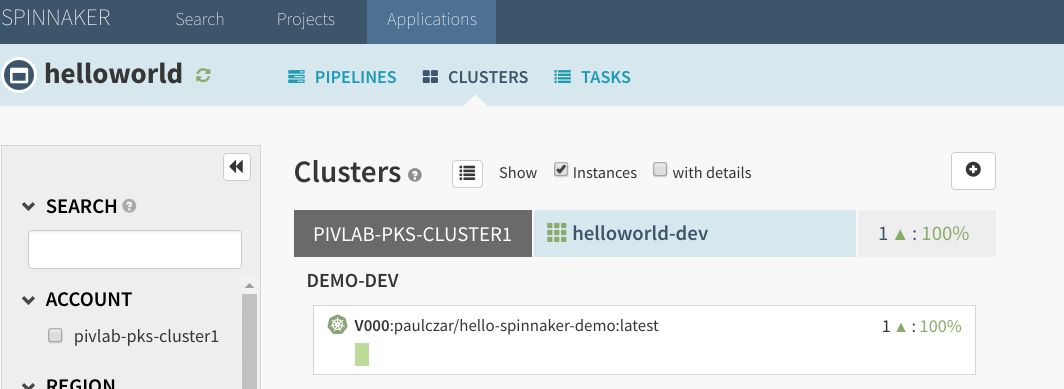
在此阶段,Spinnaker已经为应用创建了一些Kubernetes资源。使用kubectl了解一下(确保您为Kubernetes客户端配置了正确的群集和命名空间):
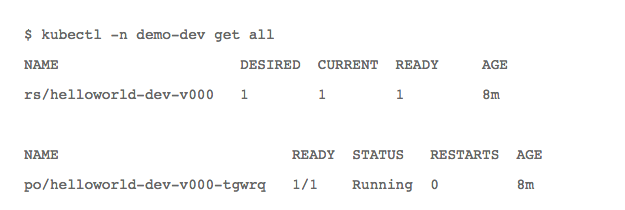
可以看到Spinnaker已经为应用创建了ReplicaSet,这又创建了单元。但没有已配置的服务,所以无法通过NodePort或LoadBalancer访问它。这是预料之中的。我们需要在Spinnaker中为此创建负载均衡器资源。但目前暂时只使用kubectl端口转发,以确保应用得到正确部署。通过在后台运行kubectl流程,可以在同一终端运行curl,以验证应用是否正在运行:
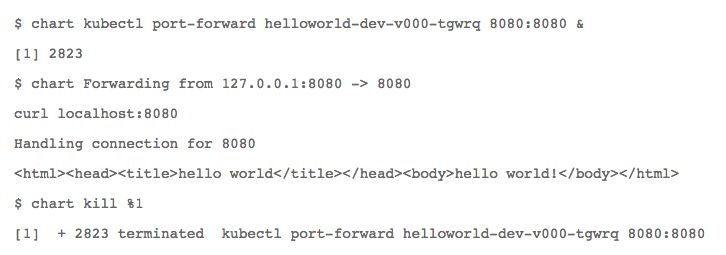
3.创建负载均衡器
如果无法访问应用,它就只是无用的摆设。可以在管理Kubernetes服务资源的Spinnaker中创建负载均衡器资源。返回Spinnaker UI,单击右上角的“Load Balancers”菜单项。

在这里创建两个负载均衡器,一个用于开发,一个用于生产。
单击“创建负载均衡器”(即“+”按钮):
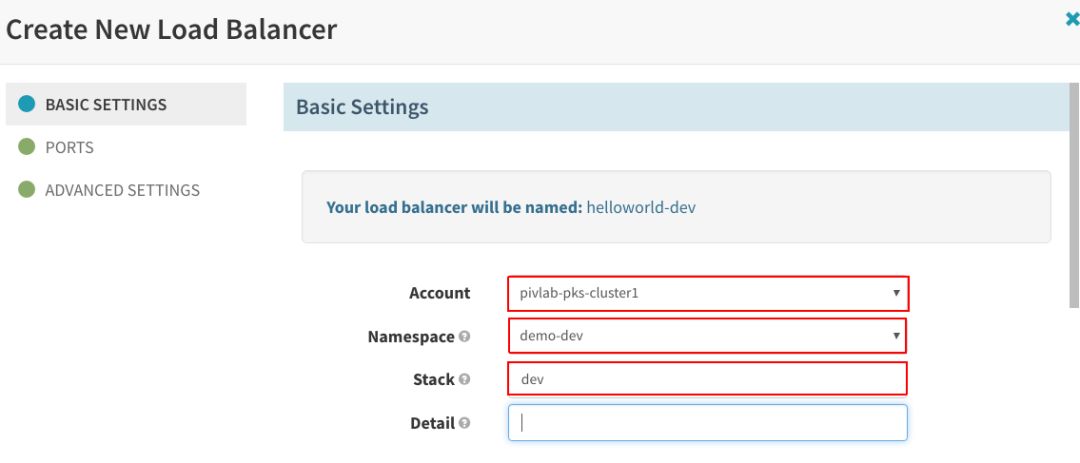
在“Basic Settings”下填写“Account”、“Namespace”和“Stack”项:
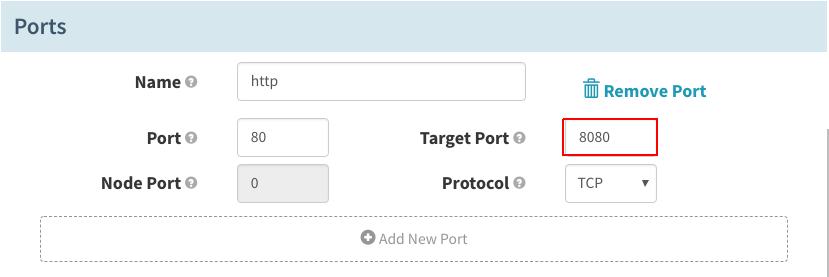
在“Ports”下,设置“Target Port”,以匹配容器内的应用端口:
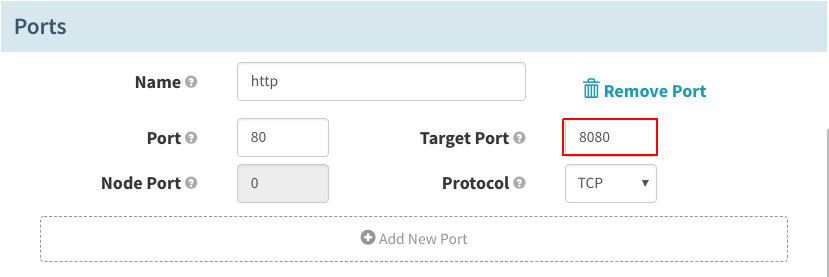
在“Advanced Settings”下,将“Type”设置成“LoadBalancer”。
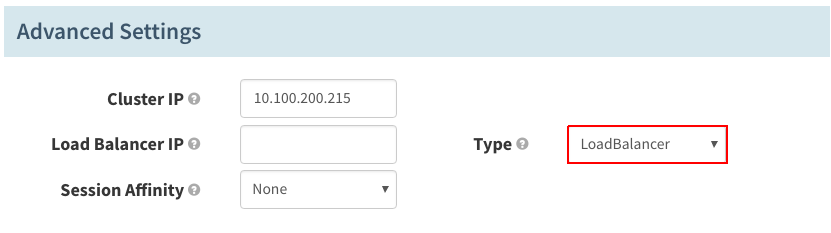
点击“Create”按钮,等待系统创建负载均衡器(实际上不需要等待;如果等不及,可以关闭进度窗口,转到后续步骤)。
以同样的方式为单元创建第二个负载均衡器:
创建完成后,应该看到Spinnaker中列出了两个负载均衡器。如果单击一个负载均衡器,可以查看详细信息,比如与该负载均衡器相关的外部IP:
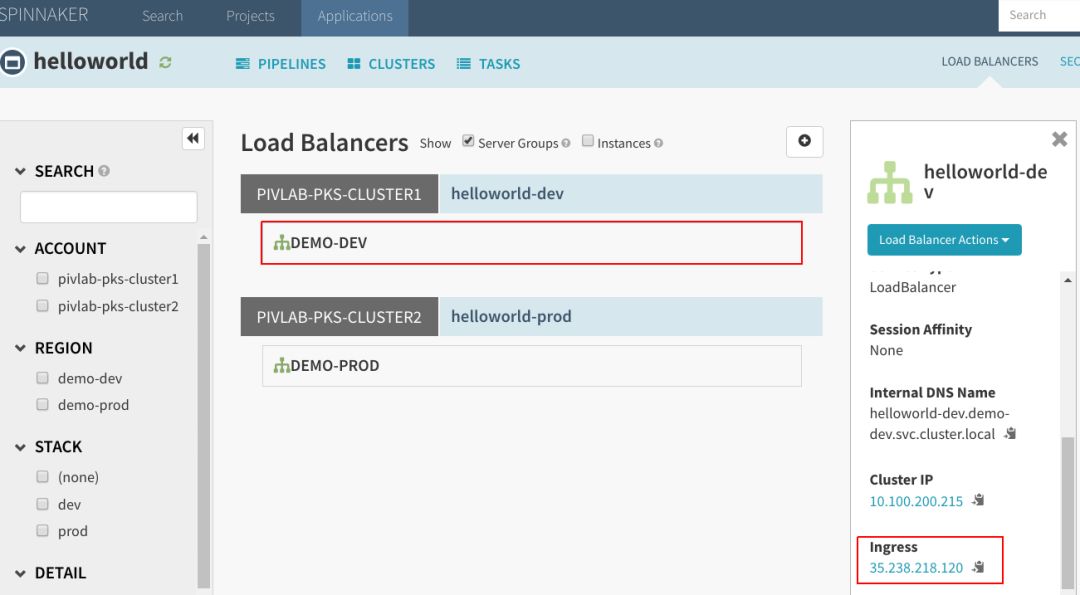
4.创建流水线
现在,应用和负载均衡器均由Spinnaker管理,我们可以创建流水线,将应用部署到开发中,当我们在Github中创建新版本时,该流水线让我们能够随时将它推入到生产中。
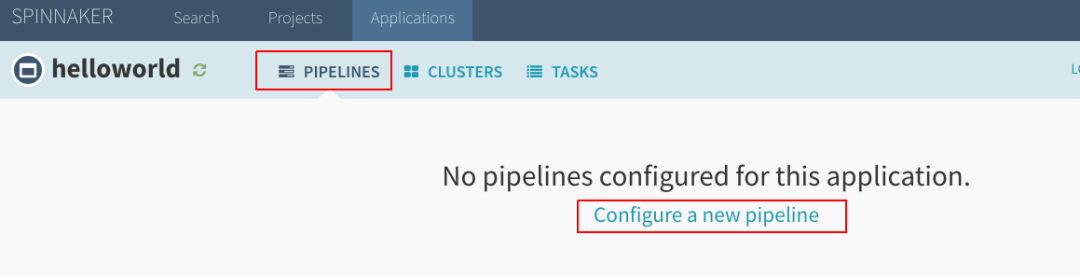
单击菜单中的“Pipelines”,然后单击“Configure a new pipeline”:
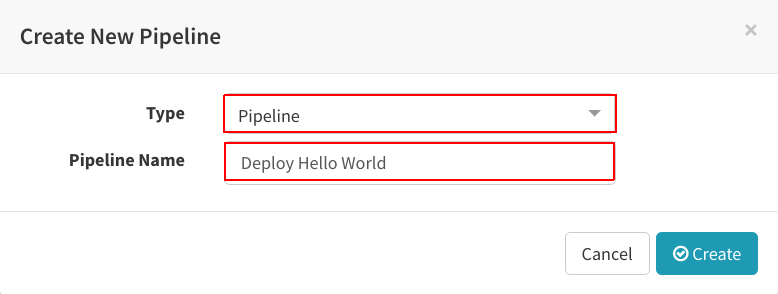
确保“Type”设置为“Pipeline”,“Pipeline Name”设置为有意义的内容(比如“Deploy Hello World”),点击“Create”:
此操作将导向该流水线的配置屏幕。单击“Add Trigger”按钮:
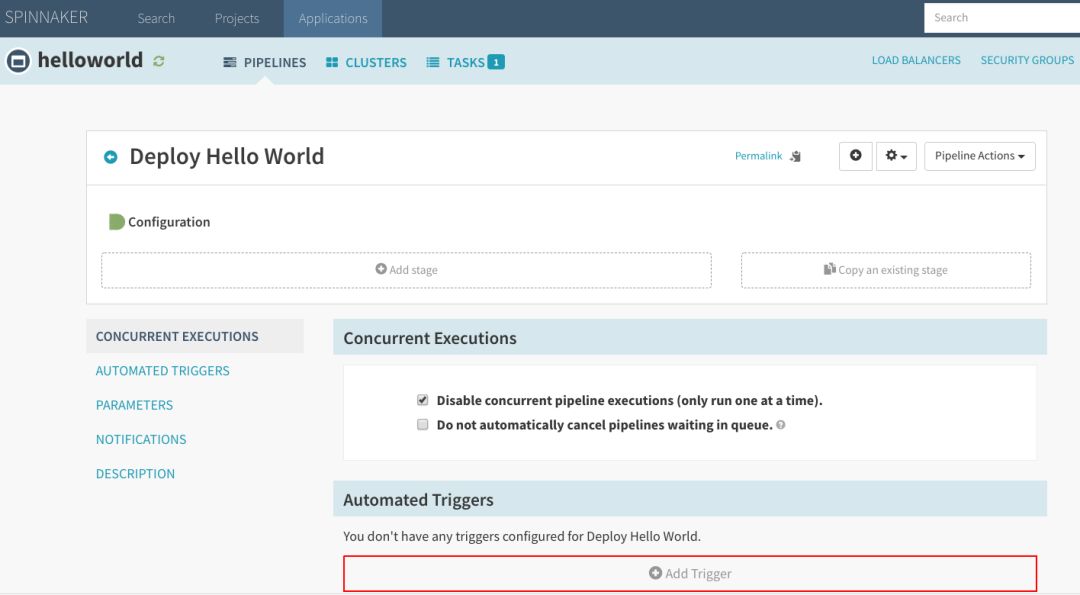
将“Type”设置为“Docker Registry”,然后填写“Registry Name”、“Organization”和“Image”部分,点击“Save Changes”。
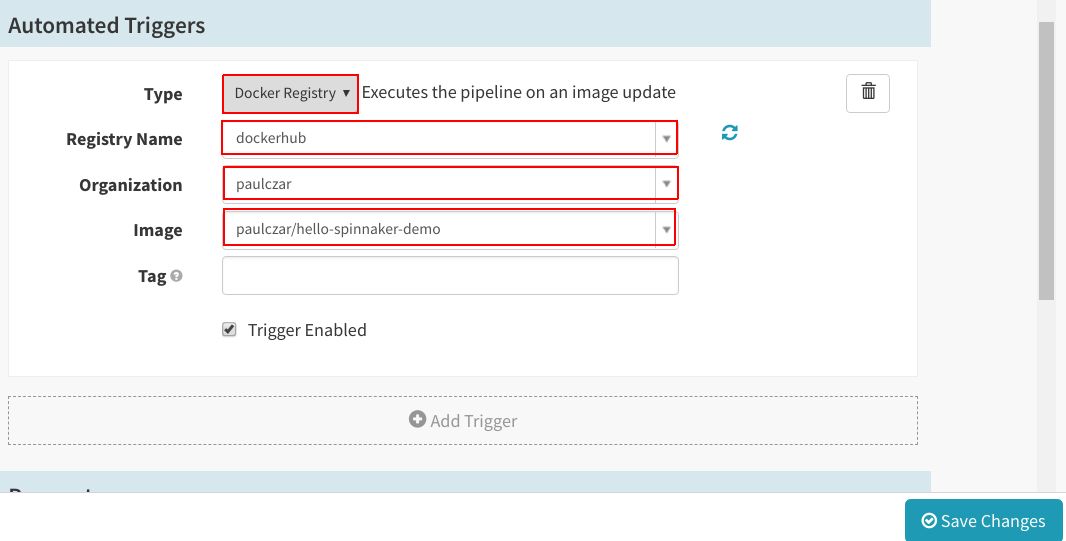

将“Type”设置为“Deploy”,将“Stage Name”指定为“Deploy to Dev”。然后点击“Add server group”:
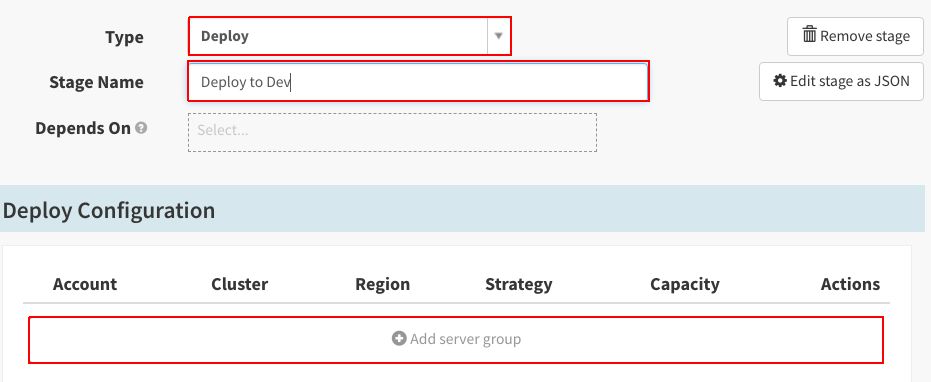
从之前创建的开发服务器群组创建新的服务器群组,点击“Use this template”:
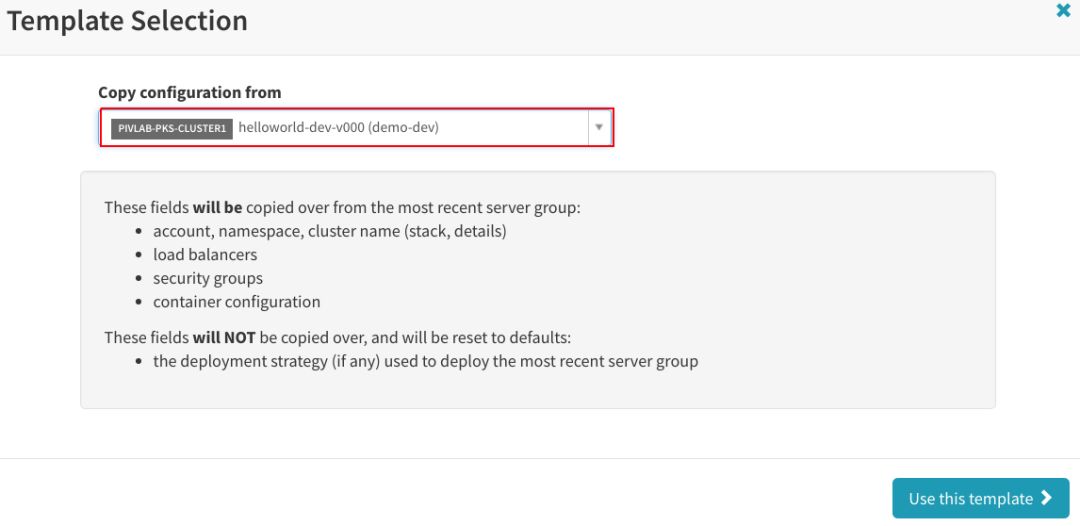
在“Basic Settings”下,只需更改“Containers”,选择“Images from Trigger(s)”选项,以便Spinnaker知道根据创建的版本选择正确的镜像。将“Strategy”设置成“Highlander”,以便它删除应用的旧版本。
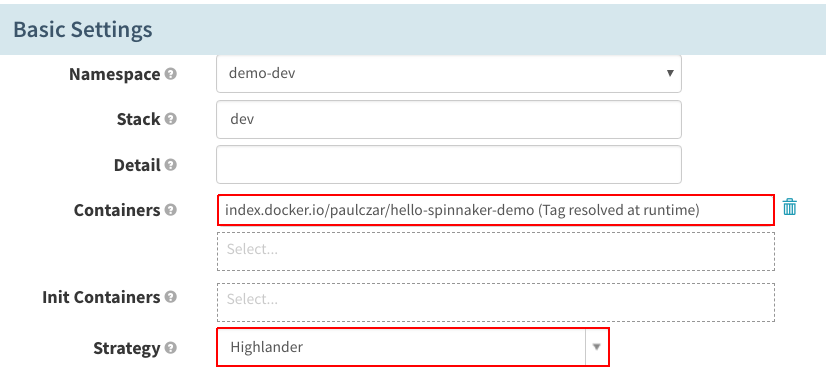
在“Load Balancers”下,选择之前创建的“helloworld-dev”负载均衡器:
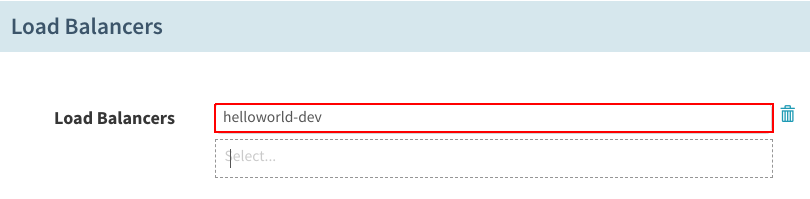
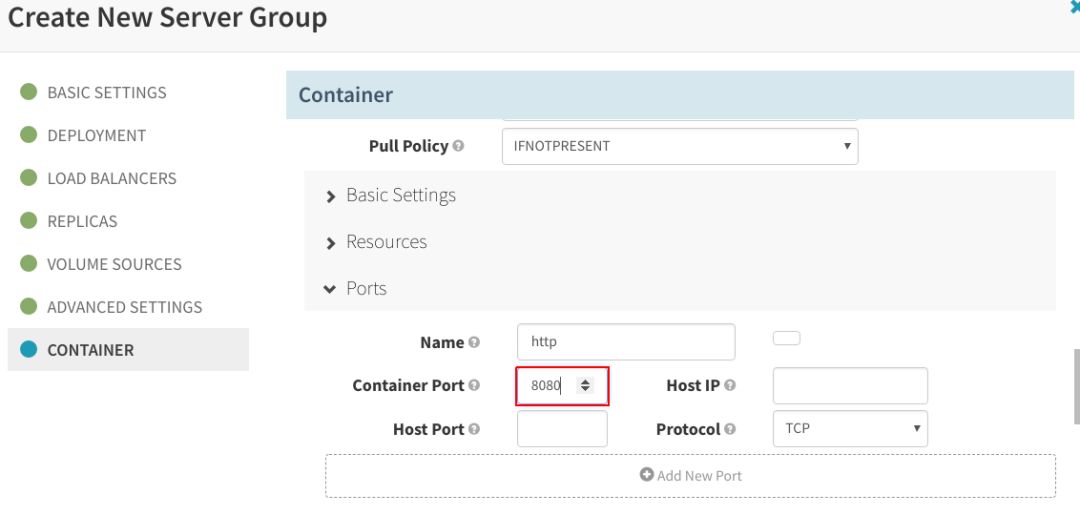
设置“Container Port”,并按照之前的操作创建Readiness Probe:
保存此阶段,然后立即创建新的阶段:

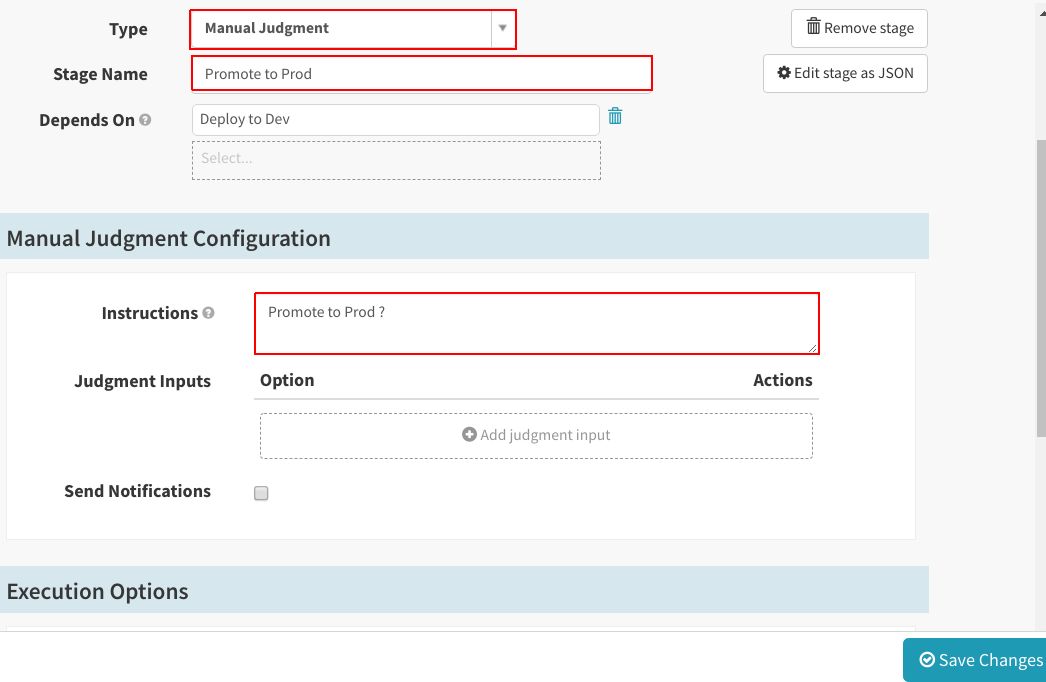
将“Type”、“Stage Name”分别设置成“Manual Judgement”和“Promote to Prod”。将“Promote to Prod?”添加到“Instructions”中。点击“Save Changes”。
创建新阶段:

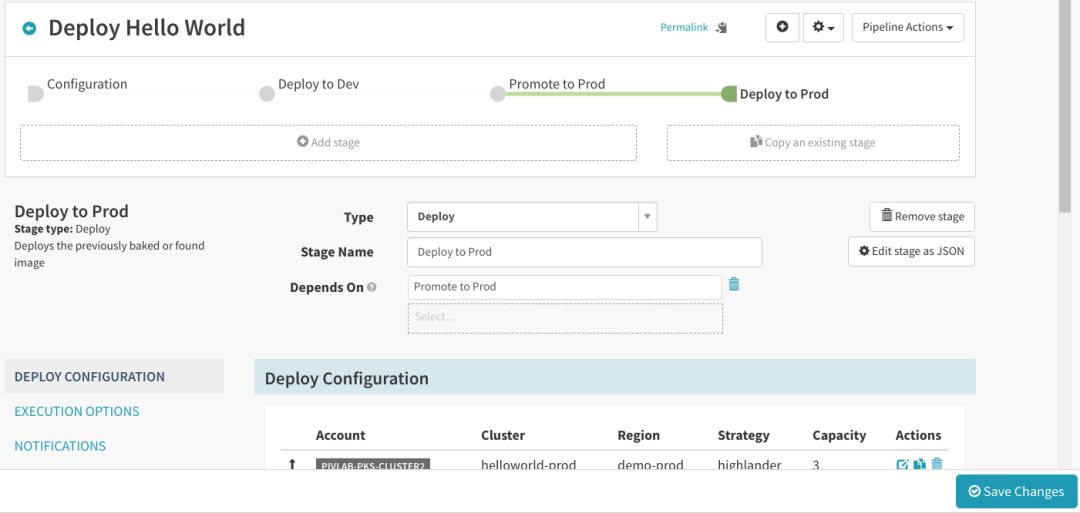
将“Type”、“Stage Name”分别设置成“Deploy”和“Deploy to Prod”,点击“Add Server Group”:
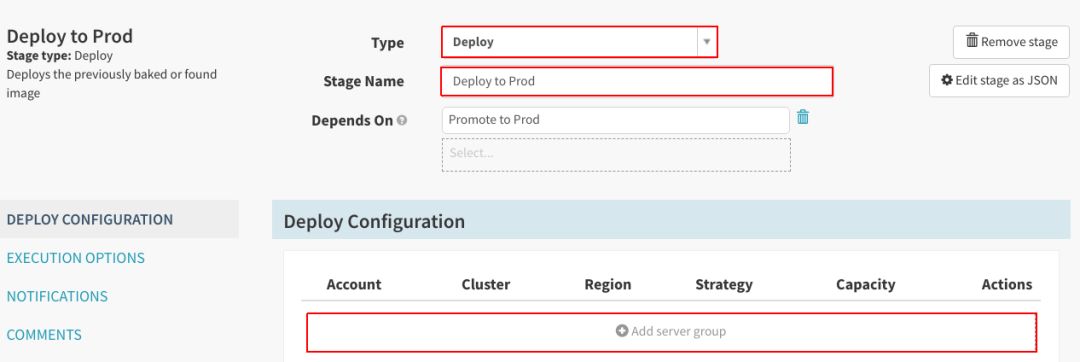
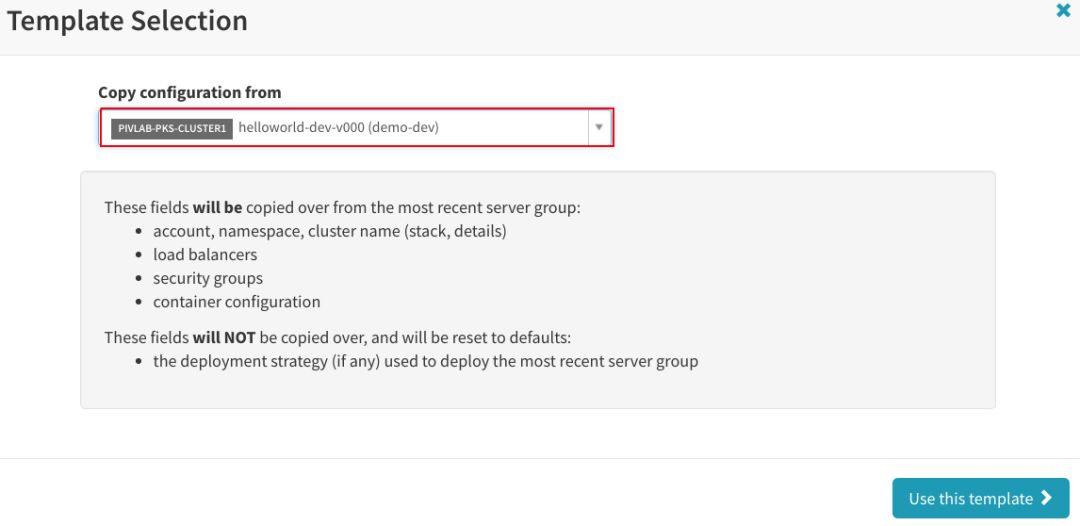
将现有开发服务器群组用作模板:
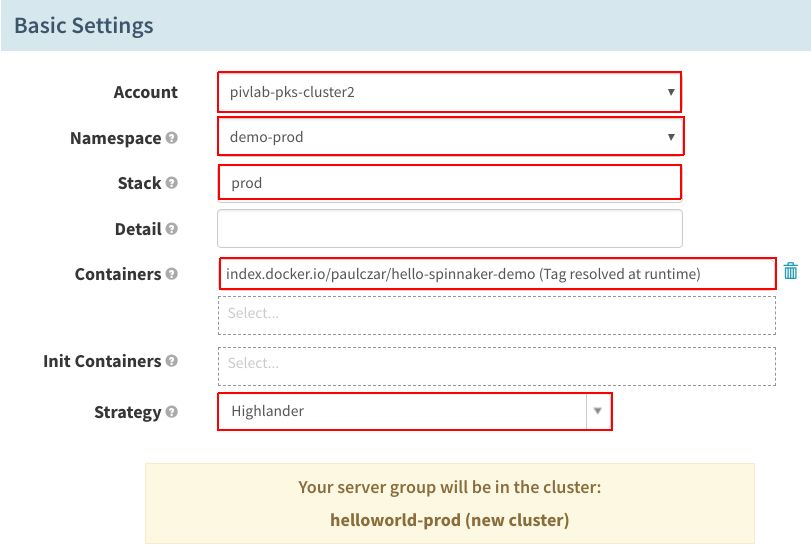
将“Account”和“Namespace”设置为要部署到的Kubernetes群集和命名空间,然后将“Stack”名称指定为“prod”,并将“Containers”更改成“Tag resolved at runtime”容器。将“Strategy”设置成“Highlander”:
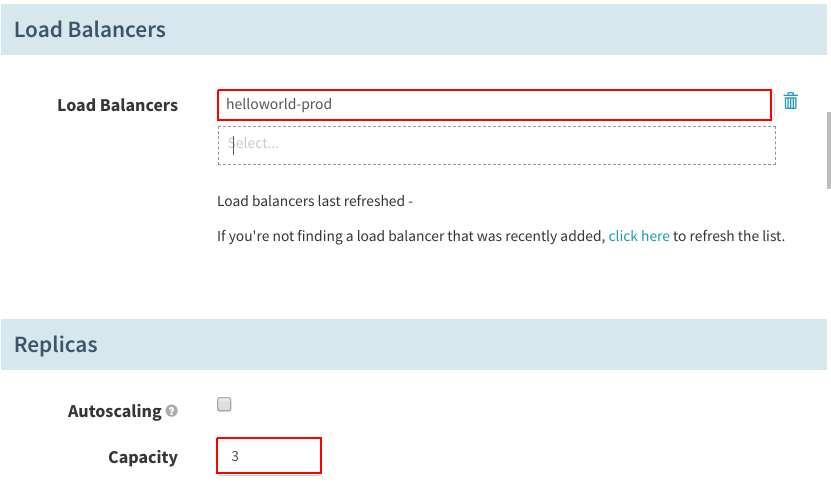
在“Load Balancers”下,选择生产负载均衡器,在“Replicas”下,将“Capacity”设置成“3”:
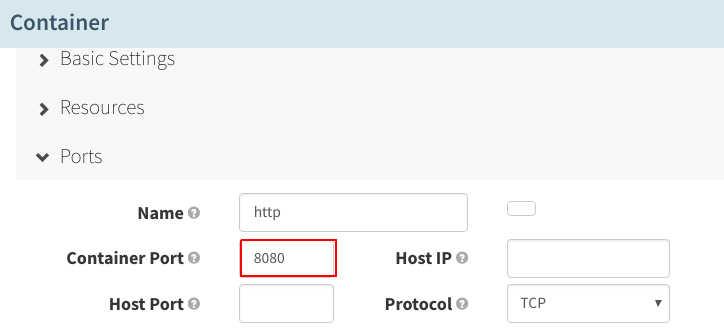
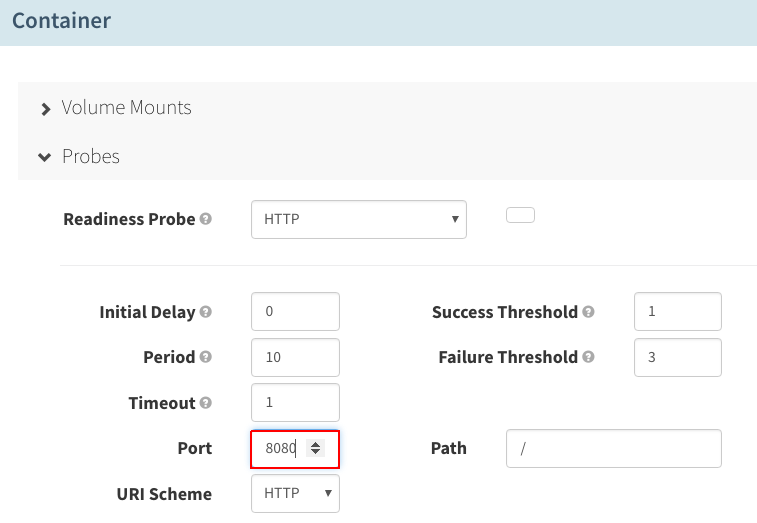
像以前一样,将“Container port”更改成“8080”,并为端口8080创建就绪性检查:
再次点击“Pipelines”菜单项,返回“Pipelines”摘要界面:
5.创建release
现在,用于测试流水线的一切工作应该已经设置完毕。首先,为当前的应用版本创建release,观看它如何通过此流水线。可以先单击发布文本,在Github中执行此操作:
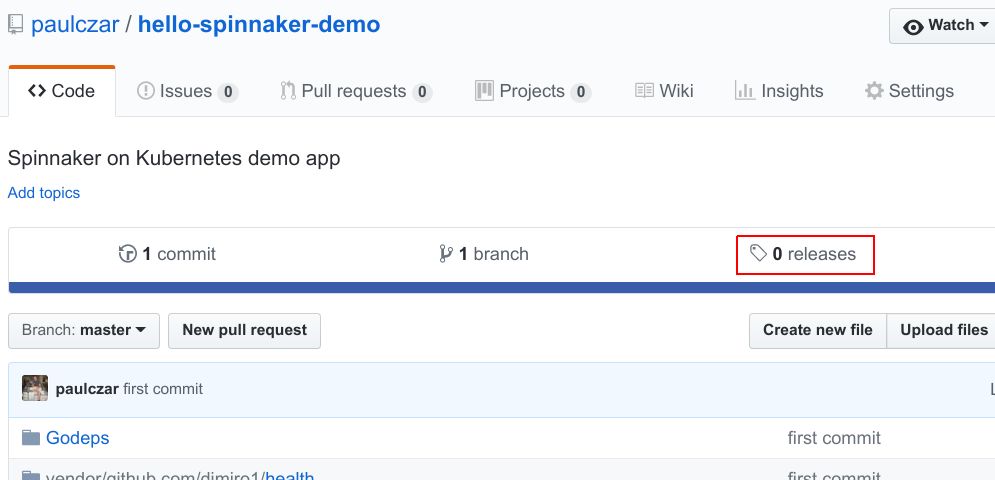
单击“Create a new release”按钮:
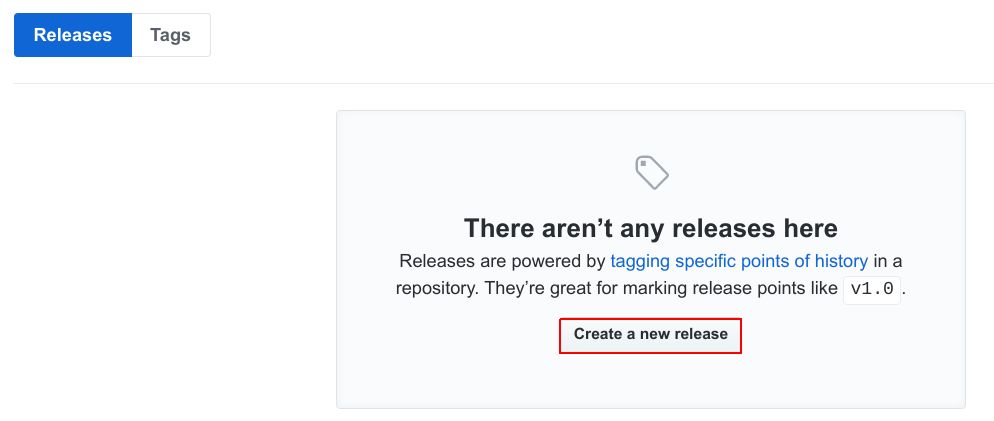
将发布版本指定为1.0.0,指定发布名称,然后点击“Publish Release”。
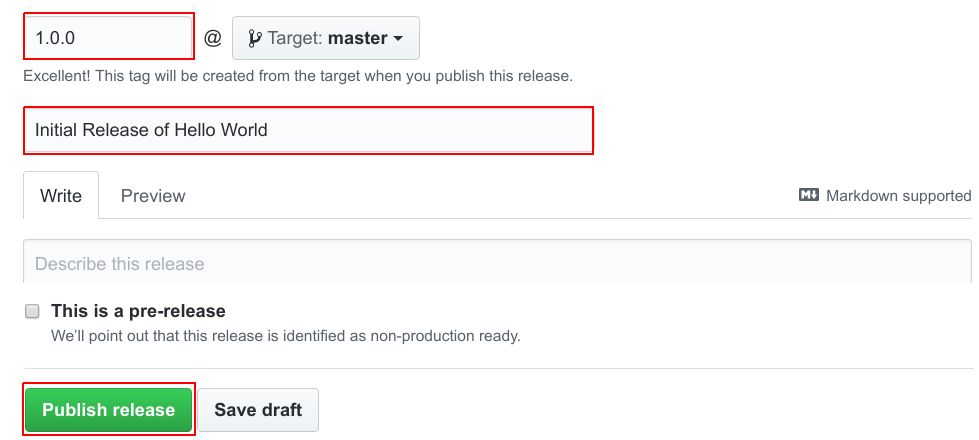
发布中断后,将看到Docker Hub排队等候新的构建:
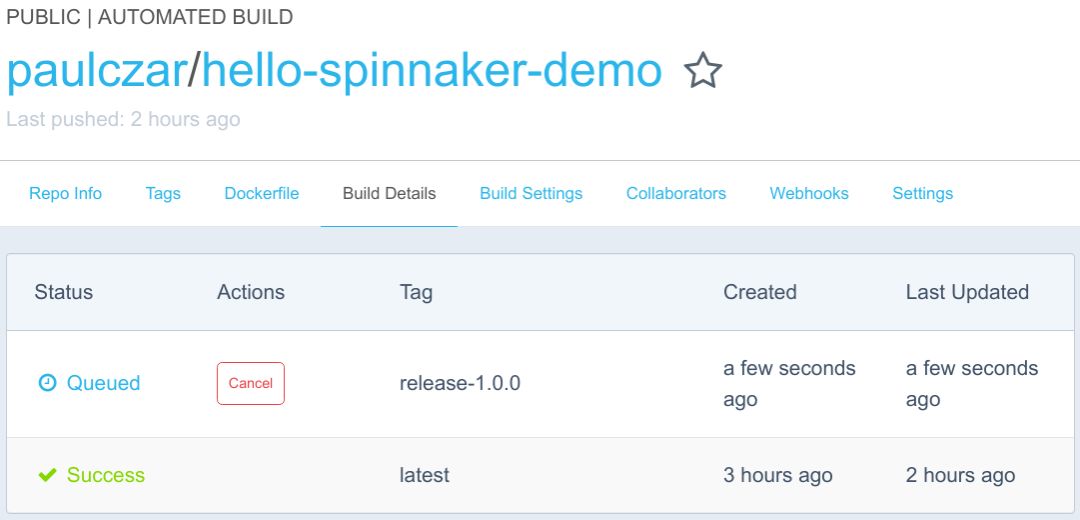
一两分钟后,切换到“Building”:
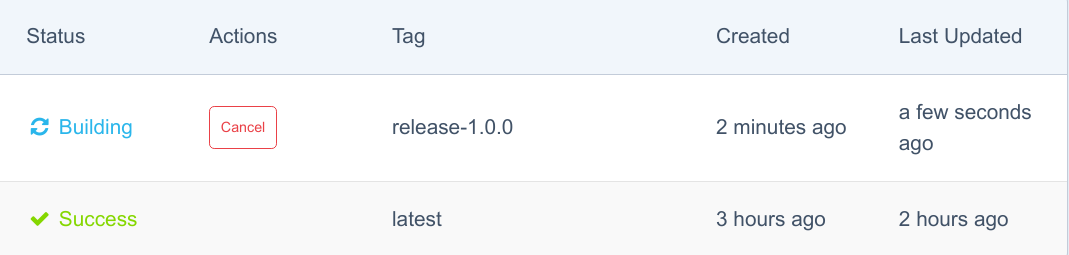
在最终达到“Success”状态之前:
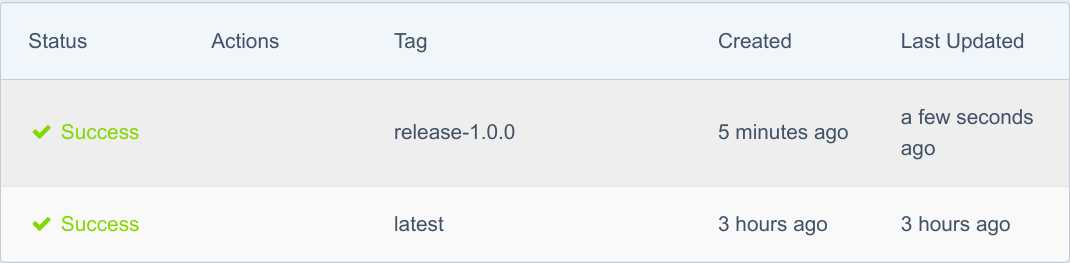
出现这一情况后,Spinnaker将进来执行新流水线的第1个阶段:
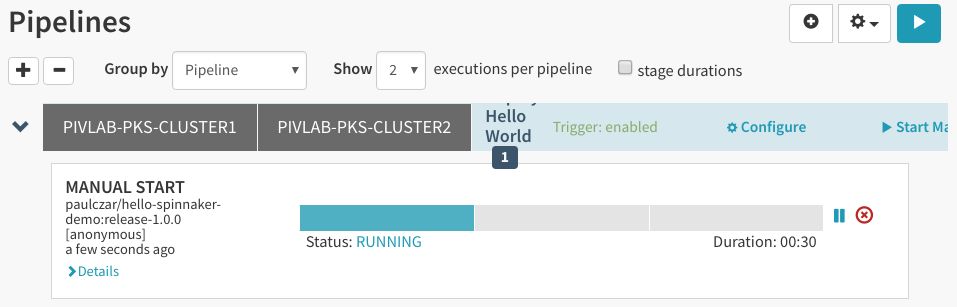
由于我们将第二个阶段设置成需要手动干预,它会停下来,等待用户提供输入内容:
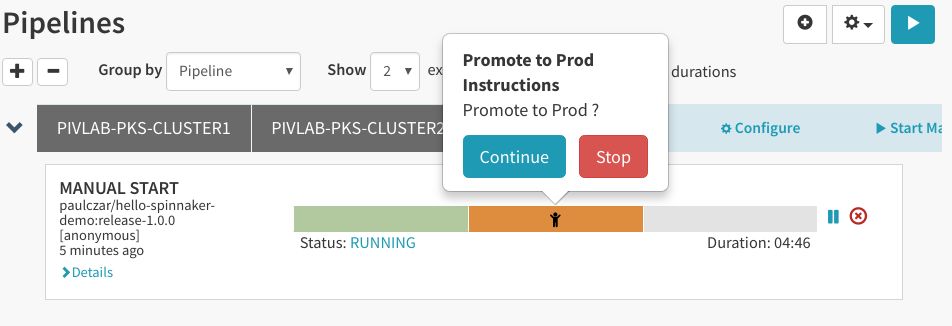
在做出决定之前,可以单击开发负载均衡器入口IP来测试开发部署:
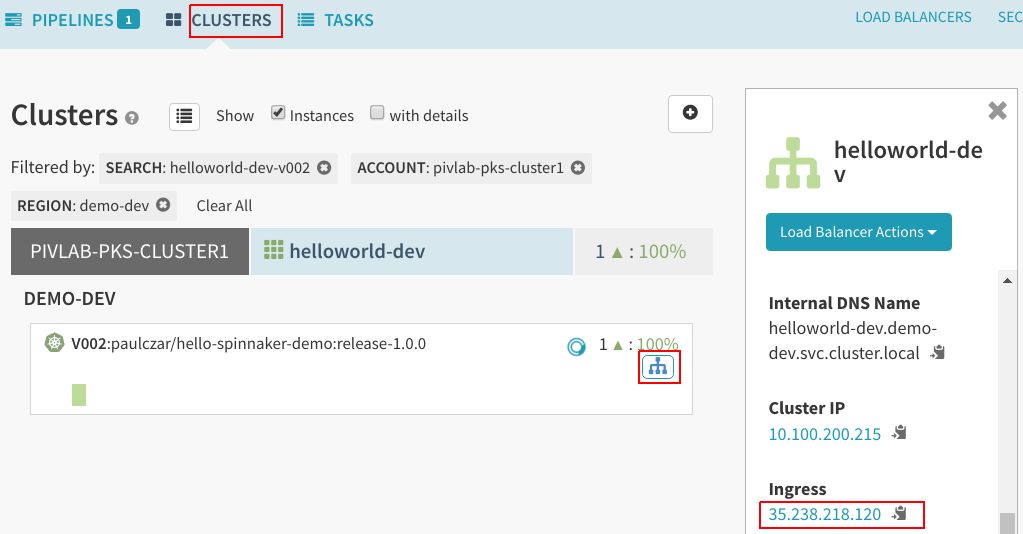
单击该IP应该能够在浏览器中打开新的选项卡,并显示应用:
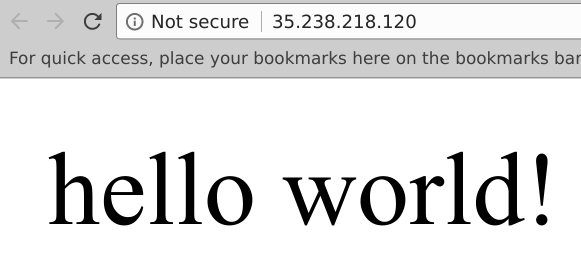
看来一切正常,所以返回流水线,回复“是”,流水线将进入第3个阶段。会注意到进度栏分成了几个阶段,您可以单击第3阶段,查看这一阶段的进度:
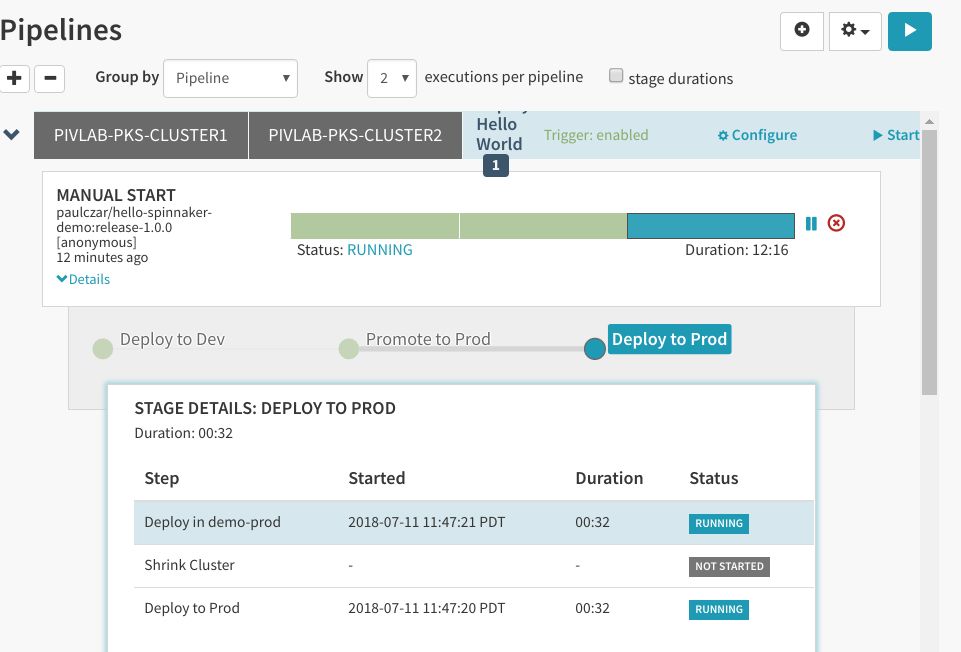
几分钟后,状态应该变成“Completed”:
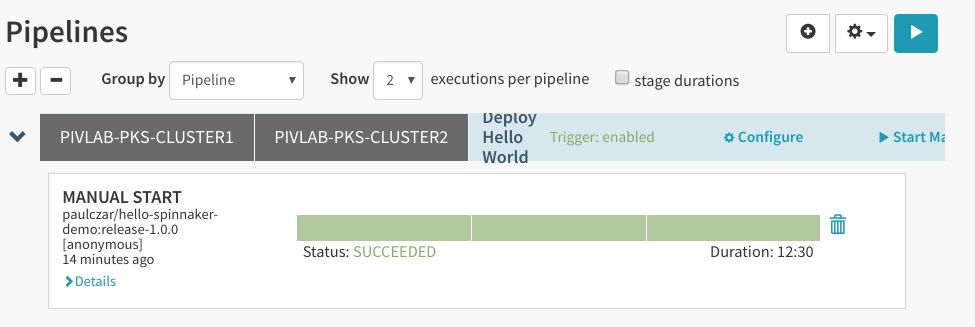
在Spinnaker中返回“Clusters”页面,将看到一个叫做“helloworld-prod”的新服务器群组。注意到它显示为有三个正常运行的单元,而开发只拥有一个正常运行的单元。
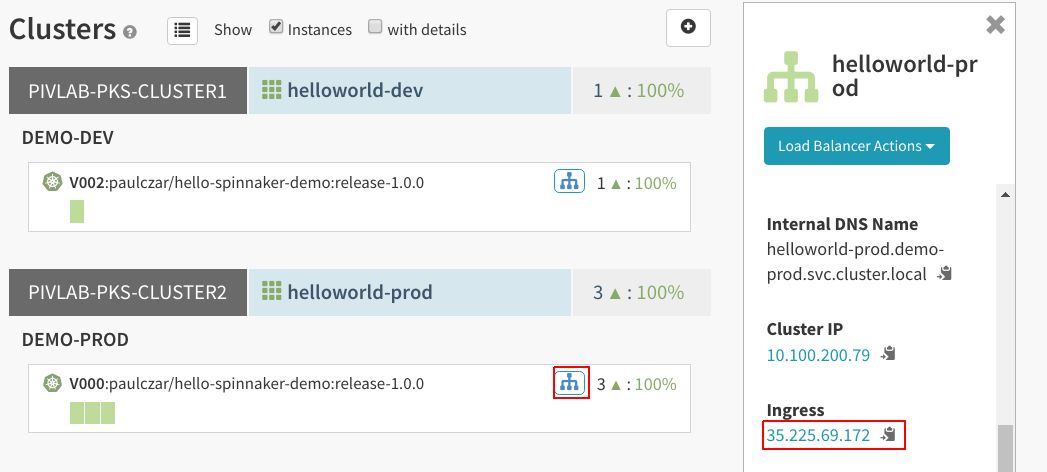
可以单击负载均衡器入口IP对它进行测试,所得到的内容应该与开发相同。
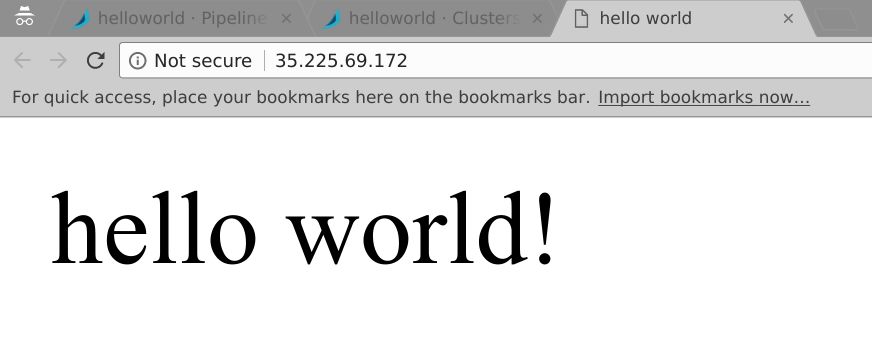
6.更新应用并中断新的发布
要更新应用,我在Github中创建了新的拉取请求,并对hello world文本做出了改动:
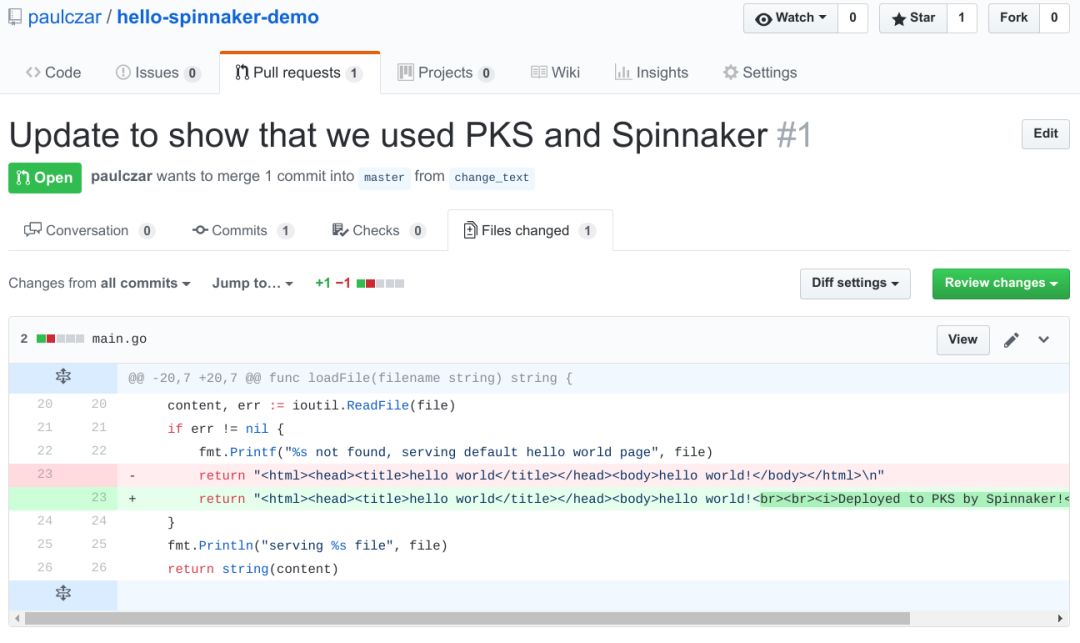
我合并了PR,创建了新的发布版本1.1.0。
同样,Docker将看到新标签并创建新构建,这又会触发执行Spinnaker流水线:
请注意,此时执行会显示它已被Docker触发。
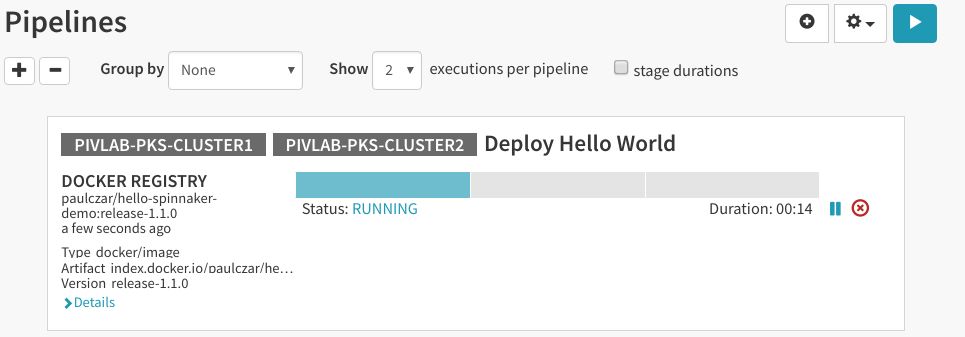
Spinnaker将提示我们选择“Promote to Production”:

但在此之前,我们可以检查开发环境。可以在“Clusters”页面看到,开发服务器群组已经更新了新版本,但生产服务器群组还没有更新:
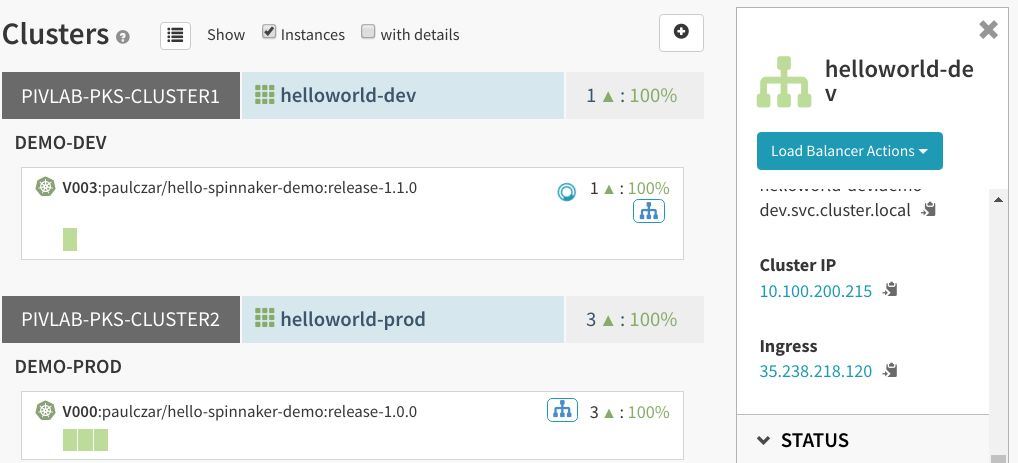
正如所预料的,开发负载均衡器后的内容已经更新:
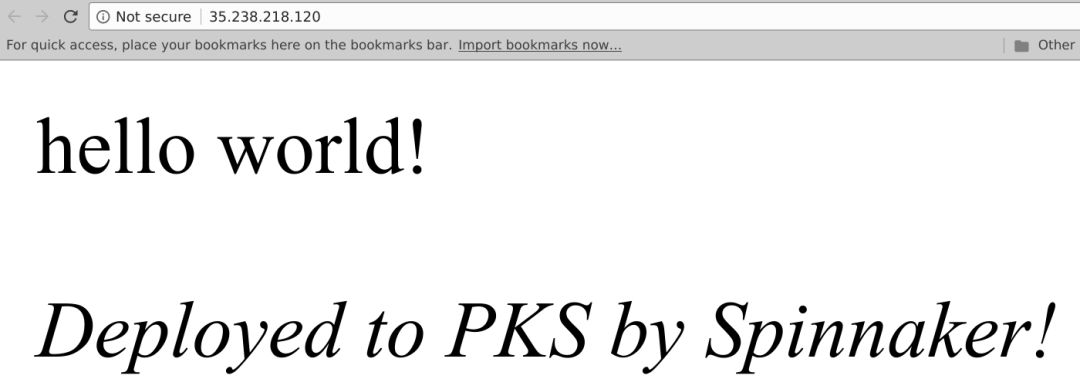
看来一切正常,通过对“Promote to Prod gate”单击“Yes”,Spinnaker执行“Promote to Production”。这将完成流水线的执行,将应用部署到生产:
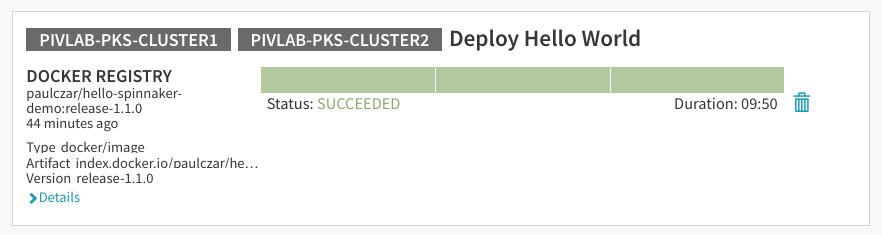
同样,可以看一下“Clusters”页面,看到服务器群组已经更新:
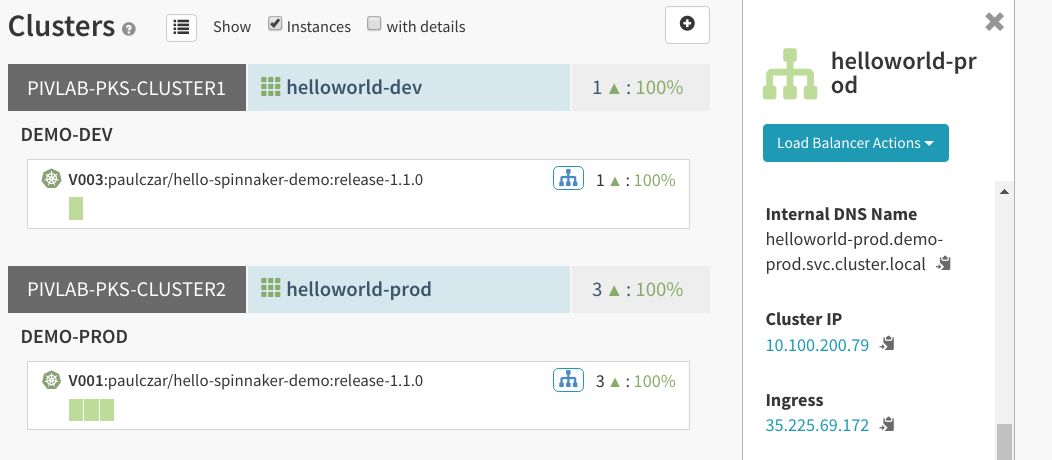
最后,查看针对生产服务器群组的负载均衡器,可以看到应用已自动更新:
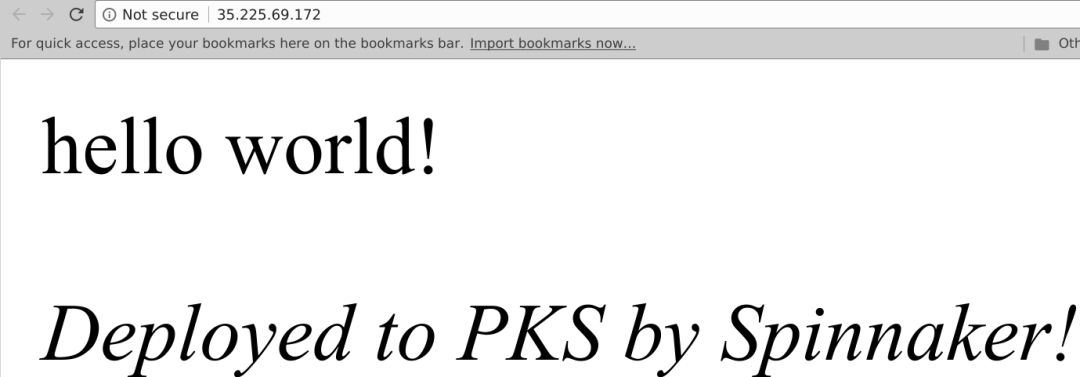
总结
总之,Spinnaker将应用部署到Kubernetes所采用的方式让人印象深刻。它可以处理创建Kubernetes manifest所需的所有烦琐事项,且功能足够丰富,可以部署大多数类型的应用。
这只是一个非常简单的示例应用,但使用Spinnaker部署基于微服务的复杂应用(比如Netflix!)的示例有很多,毫无疑问,它可以用于实际环境。
通过依靠Docker注册表构建镜像,还需要依靠上游工具执行单元测试,能够向流水线添加内容,从而执行集成测试。Spinnaker可以创建亚马逊AMI镜像,所以也希望看到让Spinnaker为Kubernetes执行构建和单元测试的选项。
Spinnaker本身有许多单元和服务可以运行,所以不会随意将它用于非常简单的应用。但是,我知道对于处理有意义的应用的大型团队来说,它会带来巨大价值并帮助简化部署流程。
利用Spinnaker创建持续交付流水线的更多相关文章
- DevOps-如何构建持续交付流水线
引言 DevOps 是一套实践方法,在保证高质量的前提下缩短系统变更从提交到部署至生产环境的时间,其中持续集成和持续交付是 DevOps 里面非常重要的一环.本文讲述了达到自动化持续交付需要做的准备工 ...
- Docker学习总结(8)——利用Docker开启持续交付之路
持续交付即Continuous Delivery,简称CD,随着DevOps的流行正越来越被传统企业所重视.持续交付讲求以短周期.小细粒度,自动化的方式频繁的交付软件,在这个过 程中要求开发.测试.用 ...
- 人多力量大vs.两个披萨原则,聊聊持续交付中的流水线模式
人多力量大vs.两个披萨原则,聊聊持续交付中的流水线模式 在前面5期文章中,我们分别详细介绍了持续交付体系基础层面的建设,主要是多环境和配置管理,这些是持续交付自动化体系的基础,是跟我们实际的业务场景 ...
- [持续交付实践] Jenkins 中国用户大会参会见闻
前言 上周日在上海召开了Jenkins中国用户大会(Jenkins User Confluence China),这应该是Jenkins在中国第一次举办吧.Jenkins的创始人Kohsuke Kaw ...
- 玩转spring boot——结合阿里云持续交付
前言 在互联网项目中,项目测试.部署往往需要花费大量时间.传统方式是在本地打包.测试完毕程序,然后通过ftp上传至服务器,再把测试的配置文件修改为生产环境的配置文件,最后重新运行服务.这一过程如果交给 ...
- [持续交付实践] 开篇:持续集成&持续交付综述
前言 随着微服务架构与容器虚拟化技术的发展,持续集成与持续交付的概念又重新回到了大家的视野,越来越多的公司开始使用持续集成的系统来解决频繁发布带来的质量问题:使用持续交付的工具来实现代码在不同环境上的 ...
- TOP100summit 2017:【案例分享】魅族持续交付平台建设实践
本篇文章内容来自第10期魅族开放日魅族运维架构师林钟洪的现场分享.编辑:Cynthia 一.自动化建设历程1.1 魅族互联网发展的时间线 2003-2008年被称之为“互联网1.0时代”.2003年, ...
- 利用jenkins和docker实现持续交付
利用jenkins和docker实现持续交付 一.什么是持续交付 让软件产品的产出过程在一个短周期内完成,以保证软件可以稳定.持续的保持在随时可以发布的状况.它的目标在于让软件的构建.测试与发布变得更 ...
- 【云计算】Netflix 开源持续交付平台 Spinnaker
oschina 发布于: 2015年11月19日 (0评) 分享到: 收藏 +1 CDS首都在线全球云主机.全球私有网络,开工送礼,免费试用! » 日前,Ne ...
随机推荐
- 巩固JavaSE基础--IDEA完成实战项目
PS:学习完JavaSE基础后,需要有一个项目来测试自己的学习成果,并加以巩固.所以在这里,就让我们来学习下“一本糊涂账”项目吧.(此项目来源于Java自学网站) 项目完成效果图一览
- TWaver3D特效之高光反射
前篇我们介绍了TWaver 3D的环境映射特效,下面我们接着给大家分享高光反射特效.高光反射定义了物体上的某一区域比其他地方更反光.在高光反射的贴图中,黑色区域的反射率为0(完全不反光),白色区域的反 ...
- 用 Systemtap 统计 TCP 连接
转自: https://mp.weixin.qq.com/s?__biz=MzIxMjAzMDA1MQ==&mid=2648946009&idx=1&sn=3a0be2fe4f ...
- MySql报Packet for query is too large错误
mysql中执行sql的时候报以下错误:Packet for query is too large (1354 > 1024) 原因是mysql一次接收的报文太长,需要调整服务器参数max_al ...
- airfoil polar data during post stall stages (high AOA)
airfoil polar data during post stall stages (high AOA) Table of Contents 1. airfoil polar during pos ...
- pandas处理各类表格数据
经常遇到Python读取excel和csv还有其他各种文件的内容.json还有web端的读取还是比较简单,但是excel和csv的读写是很麻烦.这里记录了pandas库提供的方法来实现文本内容和Dat ...
- Cmake的介绍和使用 Cmake实践
Cmake的介绍和使用 Cmake实践http://www.cppblog.com/Roger/archive/2011/11/17/160368.html
- codechef 营养题 第一弹
第一弾が始まる! 定期更新しない! 来源:http://wenku.baidu.com/link?url=XOJLwfgMsZp_9nhAK15591XFRgZl7f7_x7wtZ5_3T2peHh5 ...
- springcloud(十三):Ribbon客户端负载均衡实例
一.采用默认的负载均衡策略:RoundRobinRule 轮询策略 1.修改提供者原的控制类 在之前的eureka-client-provider项目的CenterController.java中加入 ...
- 管理Bean的生命周期
[IOC容器中Bean的生命周期方法] 1.SpringIOC容器可以管理Bean的生命周期,Spring允许在Bean生命周期的特定点执行定制的任务. 2.Spring IOC容器对Bean的生命周 ...