python学习笔记——提取网页中的信息正则表达式re
被用来检索\替换那些符合某个模式(规则)的文本,对于文本过滤或规则匹配,最强大的就是正则表达式,是python爬虫里必不可少的神兵利器。
1 正则表达式re基本规则
[0-9] 任意一个数字,等价\d
[a-z] 任意一个小写字母
[A-Z]任意一个大写字母
[^0-9] 匹配非数字,等价\D
\w 等价[a-z0-9_],字母数字下划线
\W 等价对\w取非
. 任意字符
[] 匹配内部任意字符或子表达式
[^] 对字符集合取非
* 匹配前面的字符或者子表达式0次或多次
+ 匹配前一个字符至少1次
? 匹配前一个字符0次或1次
^ 匹配字符串开头
$ 匹配字符串结束
2 python的re模块
几个重要的方法:
match: 匹配一次从开头;
search: 匹配一次,从某位置;
findall: 匹配所有;
split: 分隔;
sub: 替换;
3 正则表达式的两种模式
3.1 贪婪模式:(.*)
import re
str = "hello_python3_world"
re_obj = re.compile(".*_")
data = re_obj.findall(str)
print(data)
# 贪婪模式,一直匹配到最后一个下划线_
3.2 懒惰模式:(.*?)
import re
str = "hello_python3_world"
re_obj1 = re.compile(".?_") #['o_', '3_']
re_obj2 = re.compile(".*?_") #['hello_', 'python3_']
data1 = re_obj1.findall(str)
data2 = re_obj2.findall(str)
print(data1)
print(data2)
# 懒惰模式,匹配到第一个下划线_时即停止继续匹配
4 相关软件
RegexTester.exe
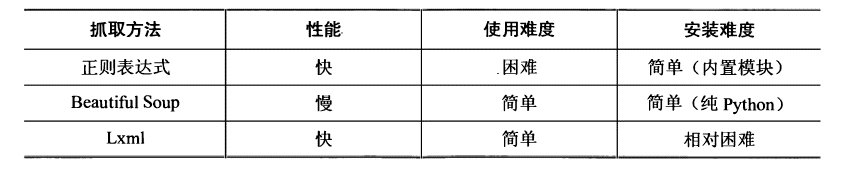
5 正则 BS lxml的比较
6 示例
5.1 示例一
用正则表达式实现下面的效果:
把 i=d%0A&from=AUTO&to=AUTO&smartresult=dict
转换成下面的形式:
i:d%0A
from:AUTO
to:AUTO
smartresult:dict
import re
str = "i=d%0A&from=AUTO&to=AUTO&smartresult=dict"
re_obj = re.compile("&")
data = re_obj.split(str) #data数据存储['i=d%0A', 'from=AUTO', 'to=AUTO', 'smartresult=dict']
m = len(data)
for i in range(m):
print(data[i])
python学习笔记——提取网页中的信息正则表达式re的更多相关文章
- python学习笔记——提取网页信息BeautifulSoup4
1 BeautifulSoup概述 beautifulSoup是勇python语言编写的一个HTML/XML的解析器,它可以很好地处理不规范标记并将其生成剖析树(parse tree): 它提供简单而 ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- 1. svg学习笔记-在网页中使用svg
在网页中使用svg有以下三种方式 1. svg归根结底来说是一种图像格式,虽然有别于jpeg,gif,png等位图图像格式,所以在网页中能嵌入图像的地方都可以嵌入svg,例如将svg文件设置为< ...
- 吴裕雄--天生自然python学习笔记:网页解析
抓取万水书苑网页中所有<a>标签中的超链接井显示. import requests from bs4 import BeautifulSoup url = 'http://www.wsbo ...
- python学习笔记——urllib库中的parse
1 urllib.parse urllib 库中包含有如下内容 Package contents error parse request response robotparser 其中urllib.p ...
- python学习笔记013——模块中的私有属性
1 私有属性的使用方式 在python中,没有类似private之类的关键字来声明私有方法或属性.若要声明其私有属性,语法规则为: 属性前加双下划线,属性后不加(双)下划线,如将属性name私有化,则 ...
- Python学习笔记020——数据库中的数据类型
1 数值类型 数值类型分为有符号signed和无符号unsigned两种. 1.1 整型 int (1)bigint 极大整型(8个字节) 范围 :-2**64 ~ 2**64 - 1 -922337 ...
- python学习笔记(excel中处理日期格式)
涉及到处理excel文件中日期格式数据 这里自己整理下 两种方法 代码如下: @classmethod def get_time(cls, table, nrows): testtime = [] f ...
- python学习笔记 改变字符串中的某一位
a = ' a = list(a) a[2] = ' news = ''.join(a) print news,a 注意不能使用 news = '' news.join(a) 因为news.join只 ...
随机推荐
- windows vs2017环境下编译webkit 2
WebKit在Windows上 内容 安装开发工具 设置Git存储库 设置支持工具 构建WebKit 安装Cygwin(可选) 得到一个崩溃日志 本指南提供了用于构建WebKit的指令在Windows ...
- [Algorithm] Inorder Successor in a binary search tree
For the given tree, in order traverse is: visit left side root visit right side // 6,8,10,11,12,15,1 ...
- 【Python】用geopy查两经纬度间的距离
代码: from geopy.distance import vincenty from geopy.distance import great_circle 天安门 = (39.90733345, ...
- 一些常用&实用的Linux命令
这些指令还是很常用的,最起码有些我每天都要用.当然,很多东西还是写成shell脚本用起来更方便. man 命令(查看一个命令的详细帮助信息) 命令 --help(显示一个命令的简单帮助信息) 命令 | ...
- Array、ArrayList、List、IEnumerable、for、foreach应用
一.Array 类 (System) 声明数组(本身也是一种变量,要先声明再使用) 1.声明数组的语法,数组大小由长度绝定: 数据类型 [] 数组名: 如: string[] student; //字 ...
- Android 之 SharedPreferences应用
Android 平台给我们提供了一个 SharedPreferences 类,它是一个轻量级的存储类,特别适合用于保存共享数据.使用SharedPreferences保存数据,其背后是用xml文件存放 ...
- Ant详解之-path、classpath和fileset
转自:http://www.cnblogs.com/itech/archive/2011/11/01/2231206.html 一 .<path/> 和 <classpath/> ...
- server.xml引入子文件配置(tomcat虚拟主机)[转]
在配置tomcat虚拟主机时候,如何每一个虚拟主机写成单独文件,server.xml包含这些子文件? 如以下<OneinStack>中,添加JAVA环境虚拟主机后tomcat配置文件详情: ...
- 使用 git post-receive 钩子部署服务端代码
在 git 中提交服务器源码的时候,如果能够直接更新到测试服务器,并且重启服务使其生效,会节省懒惰的程序员们大量的时间. git 的 Server-side hook (服务端钩子/挂钩)可以用来做件 ...
- node.js模块化写法入门
子模块的写法: function SVN(){ console.log('svn initialized'); return this; } function getInstance() { cons ...