SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf
论文翻译请移步:http://www.dengfanxin.cn/?p=403
一、背景:
传统的CNN要求输入图像尺寸是固定的(因为全连接网络要求输入大小是固定的)
- crop处理,可能不包含整个物体,还会丢失上下文信息
- warping处理,会导致图像变形
- 以上都会导致CNN对不同scale/size泛化能力不强


优点
- 不管输入尺寸为多少,SPP都能生成固定尺寸的输出,这使得CNN无需固定输入图片尺寸
- CNN使用多尺度图片输入进行训练,增加了scale-invariance,减少了过拟合
- SPP运用了多尺度的信息,空间信息更加丰富,使得CNN对物体的形变更加robust
- SPP可以广泛运用在任何CNN架构上,提高performance
二、SPP对R-CNN的改进:
1、使用了SPP灵活改变网络输入尺寸
2、将整张图片一次性输入CNN提取特征,将提取出的region proposal的坐标映射到feature map上,共享了计算
改进细节:
1、SPP

- 将feature map(假设有K个channel)划分为固定数量的bin(见上图的网格,假设bin的数目为
),在每个bin里使用Max Pooling(或者AvgPooling)
- 最终每个金字塔得到
-dimension的特征向量,然后拼接起来
- 值得注意的是,最粗粒度的金字塔级别,只是用了一个bin,这等同于Global Average Pooling
2、Mapping a Window to Feature Maps
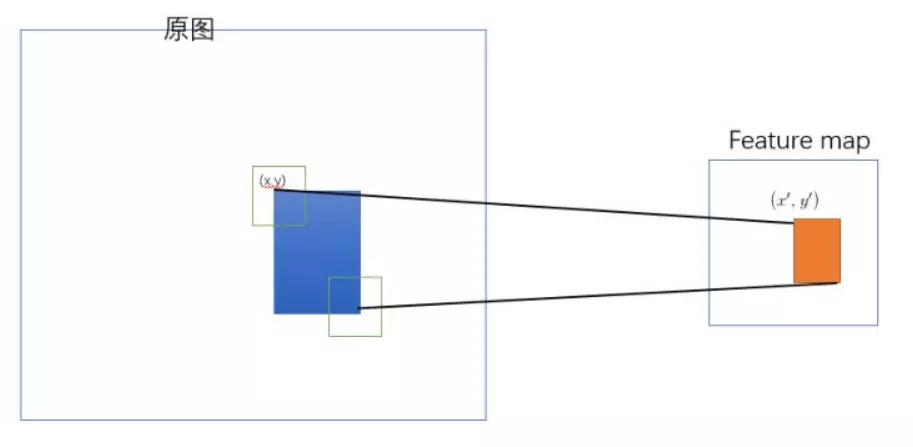


更多映射推理细节详见:https://blog.csdn.net/ibunny/article/details/79397399
3、训练方式
三、SPP-Net网络结构:
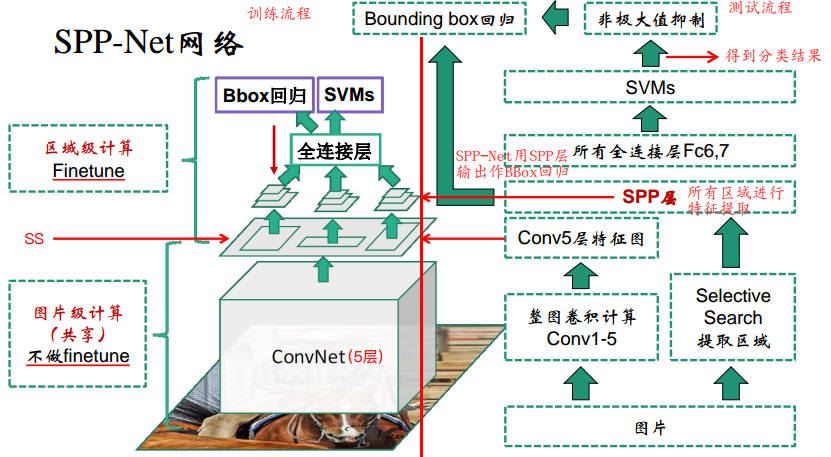
左边是训练流程,右边是测试流程,注意SPP-Net是直接用SPP池化层的输出特征作Bounding Box的回归,不像R-CNN是用Conv5的特征。

测试过程:
输入任意尺寸大小的图像,类似R-CNN,利用SS得到近2K推荐区域
通过卷积网络进行一次特征提取,得到特征图
通过ROI映射计算得到推荐区域映射到特征图的特征
输入SPP得到固定尺寸的特征
然后类似R-CNN,通过全连接层,再输入SVM得到分类概率
NMS处理
对处理后的结果,结合SPP输出特征进行边框回归
训练过程:
1、依旧是预训练好的网络,以及2K推荐区域,得到每个区域的SPP pooling层的一维特征
2、fine-tune(最大不同)
- 只fine-tune全连接网络
- FC6,FC7,FC8
- FC8被换成了21-way(20个类+背景)
- 初始化为Guassian(0, 0.01)
- learning rate从1e-4到1e-5
- 250K个batch使用1e-4
- 50k个batch使用1e-5
- 正负例平衡
- 每个batch中25%是正例,75%为负例
- IOU threshold
- 正例为0.5-1
- 负例为0.1-0.5
3、SVM
- IOU threshold为0.3
- 负例互相之间IOU超过70%则去除一个
- 使用了hard negtive mining的策略来训练SVM
4、Bbox Regression
- 使用了和R-CNN里一样的边框回归来refine坐标
- IOU阈值为0.5
四、SPP-Net缺点
SPP-Net只解决了R-CNN卷积层计算共享的问题,但是依然存在着其他问题:
(1) 训练分为多个阶段,步骤繁琐: fine-tune+训练SVM+训练Bounding Box
(2) SPP-Net在fine-tune网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行fine-tune。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)
参考资料:
https://blog.csdn.net/bryant_meng/article/details/78615353
https://www.jianshu.com/p/b2fa1df5e982
https://blog.csdn.net/ibunny/article/details/79397399
SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解的更多相关文章
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景 用ConvNet方法解决图像分类.检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息.论文作者发明了SPP pooling ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- Paper Reading - Long-term Recurrent Convolutional Networks for Visual Recognition and Description ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4389 Main Points: A novel Recurrent Convolutional Arch ...
随机推荐
- loadrunner 接口性能脚本编写(Get请求和Post请求)
前段时间接触了一下loadrunner的接口性能测试,然后尝试了一下手动编写脚本,毕竟录制这种东西,不是每次都能通的,而且录制下来的脚本,通常是有很多其他杂七杂八的请求夹杂在中间,没有达到真正的压测接 ...
- python的三种字符串格式化方法
1.最方便的 print 'hello %s and %s' % ('df', 'another df') 但是,有时候,我们有很多的参数要进行格式化,这个时候,一个一个一一对应就有点麻烦了,于是就有 ...
- !! A股历史平均市盈率走势图
http://value500.com/PE.asp 一. A股历史平均市盈率走势图 *数据来源:上海证券交易所 分享到: 354 - 上海A股 深圳A股更新时间 2017年6月7日 2017年6月7 ...
- 函数指针(pointer to function)——qsort函数应用实例
一,举例应用 在ACM比赛中常使用 stdlib.h 中自带的 qsort 函数,是教科书式的函数指针应用示范. #include <stdio.h> #include <stdli ...
- 20145322 Exp5 利用nmap扫描
20145322 Exp5 利用nmap扫描 实验过程 使用命令创建一个msf所需的数据库 service postgresql start msfdb start 使用命令msfconsole开启m ...
- JAVA I/O(一)基本字节和字符IO流
最近再看I/O这一块,故作为总结记录于此.JDK1.4引入NIO后,原来的I/O方法都基于NIO进行了优化,提高了性能.I/O操作类都在java.io下,大概将近80个,大致可以分为4类: 基于字节操 ...
- 重写(override)与重载(overload)的区别
一.重写(override) override是重写(覆盖)了一个方法,以实现不同的功能.一般是用于子类在继承父类时,重写(重新实现)父类中的方法. 重写(覆盖)的规则: 1.重写方法的参数列表必须完 ...
- linux下如何源码安装expect
1.作用 自动交互.比如如果用ssh登陆服务器,每次都输入密码,然而你觉得麻烦,那你就可以使用expect来做自动交互,这样的话就不用每次都输入密码 2.依赖 依赖tcl 3.获取源码 wget ht ...
- Wireshark 显示域名列
一般使用Wireshark只能看到ip地址,但是看域名更方便更简明 只要修改一个配置就可以 编辑-->首选项 勾选Resolve network(IP) addresses 重新捕捉:
- 【附10】kibana创建新的index patterns
elk整体架构图: 一.logstash indexer 配置文件: input { stdin{} } filter { } output { elasticsearch { hosts => ...