AdaBoost Classifier和Regressor
AdaBoost在我看理论课程的时候,以分类为例子来讲解的,谁知道sklearn里面基本上都有classifier和regressor两种。这个倒是我没想到的!!!
from sklearn.ensemble import AdaBoostRegressor

参数介绍:
base_estimator : object, optional (default=DecisionTreeRegressor)。基估计器,理论上可以选择任何回归器,但是这个地方需要支持样本加权重,as well as proper classes_ and n_classes_ attributes.(这个地方不过会翻译)。常用的是CART回归树和神经网络,默认CART回归树,即AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。
n_estimators : integer, optional (default=50)。基估计器的个数。
learning_rate : float, optional (default=1.)。即每个弱学习器的权重缩减系数νν,在原理篇的正则化章节我们也讲到了,加上了正则化项,我们的强学习器的迭代公式为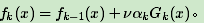
ν的取值范围为0<ν≤1。对于同样的训练集拟合效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的ν开始调参,默认是1。
loss : {‘linear’, ‘square’, ‘exponential’}, optional (default=’linear’)。Adaboost.R2算法需要用到。有线性‘linear’, 平方‘square’和指数 ‘exponential’三种选择, 默认是线性,一般使用线性就足够了,除非你怀疑这个参数导致拟合程度不好。这个值的意义,它对应了我们对第k个弱分类器的中第i个样本的误差的处理,即:
如果是线性误差,则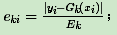
如果是平方误差,则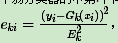
如果是指数误差,则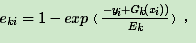
,Ek为训练集上的最大误差Ek=max|yi−Gk(xi)|i=1,2...m
random_state : int, RandomState instance or None, optional (default=None)
属性介绍:
estimators_ : list of classifiers
estimator_weights_ : array of floats
estimator_errors_ : array of floats
feature_importances_ : array of shape = [n_features]
方法介绍:

from sklearn.ensemble import AdaBoostClassifier

参数介绍:
base_estimator : object, optional (default=DecisionTreeClassifier)。基估计器,理论上可以选择任何分类器,但是这个地方需要支持样本加权重,as well as proper classes_ and n_classes_ attributes.(这个地方不过会翻译)。常用的是CART决策树和神经网络,默认CART决策树,即AdaBoostClassifier默认使用CART决策树DecisionTreeClassifier。
n_estimators : integer, optional (default=50)。基估计器的个数。
learning_rate : float, optional (default=1.)。通过这个参数缩减每个分类器的贡献,learning_rate和n_estimators 两个参数之间存在权衡。
algorithm : {‘SAMME’, ‘SAMME.R’}, optional (default=’SAMME.R’)。如果'SAMME.R'则使用SAMME.R (Real Boosting) 算法。 base_estimator必须支持类概率的计算。 如果'SAMME'则使用SAMME (discrete boosting) 算法。 SAMME.R算法通常收敛速度高于SAMME,通过较少的升压迭代实现较低的测试误差。(老哥们有好的翻译理解记得评论下!)
如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
两者的主要区别是弱学习器权重的度量,SAMME使用了和我们的原理篇里二元分类Adaboost算法的扩展,即用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
random_state : int, RandomState instance or None, optional (default=None)。如果int,random_state是随机数生成器使用的种子; 如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例。
属性介绍:
estimators_ : list of classifiers 子估计器
classes_ : array of shape = [n_classes] 类别的标签信息
n_classes_ : int 类别的数量
estimator_weights_ : array of floats 每个基估计器的权重
estimator_errors_ : array of floats 每个基估计器的错误率
feature_importances_ : array of shape = [n_features] 如果基估计器支持的话
“具体调参”参考博客
调参还是分为两部分:AdaBoost框架调参和弱分类器的调参。
框架参数调节:
框架参数就是值上述介绍的那些需要动态调节观察效果的参数。
弱分类器参数调节:
这里我们仅仅讨论默认的决策树弱学习器的参数。即CART分类树DecisionTreeClassifier和CART回归树DecisionTreeRegressor。
AdaBoost Classifier和Regressor的更多相关文章
- 机器学习经典算法之AdaBoost
一.引言 在数据挖掘中,分类算法可以说是核心算法,其中 AdaBoost 算法与随机森林算法一样都属于分类算法中的集成算法. /*请尊重作者劳动成果,转载请标明原文链接:*/ /* https://w ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- scikit-learn:class and function reference(看看你究竟掌握了多少。。)
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.decomposition Reference This is t ...
- 『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
一.模块概述 上节的最后,我们进行了如下操作获取了有限的proposal, # [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)] # IMAGES_PER_GP ...
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- 转:TensorFlow和Caffe、MXNet、Keras等其他深度学习框架的对比
http://geek.csdn.net/news/detail/138968 Google近日发布了TensorFlow 1.0候选版,这第一个稳定版将是深度学习框架发展中的里程碑的一步.自Tens ...
- sklearn常见分类器(二分类模板)
# -*- coding: utf-8 -*- import pandas as pd import matplotlib matplotlib.rcParams['font.sans-serif'] ...
- [Tensorflow] 使用 Mask_RCNN 完成目标检测与实例分割,同时输出每个区域的 Feature Map
Mask_RCNN-2.0 网页链接:https://github.com/matterport/Mask_RCNN/releases/tag/v2.0 Mask_RCNN-master(matter ...
- MatterTrack Route Of Network Traffic :: Matter
Python 1.1 基础 while语句 字符串边缘填充 列出文件夹中的指定文件类型 All Combinations For A List Of Objects Apply Operations ...
随机推荐
- jQuery的parseHTML方法
// data html字符串 // context 如果指定了context,则碎片将在此范围内被创建,默认是document // keepScripts 如果是true,则将有scr ...
- screen实战
VPS侦探在刚接触Linux时最怕的就是SSH远程登录Linux VPS编译安装程序时(比如安装lnmp)网络突然断开,或者其他情况导致不得不与远程SSH服务器链接断开,远程执行的命令也被迫停止,只能 ...
- Junit单元测试初识
写过单元测试的小童鞋对于Junit一定不陌生,可小白我,刚刚开始接触,这里就把我的测试实验,做一下记录,以便以后方便查看.学习使用JUnit4,既然使用最新版本了,就不要再考虑老版本是如何使用的了,J ...
- Word 2013无法启用Restrict Editing解决方法
当前文档可能是Mail Merge Letter type document,MAILINGS -> Start Mail Merge -> Normal Word Document保存即 ...
- VC++ 学习笔记3 获取编辑框字符串
边界框添加字符串比较简单 可以直接在对话框的空间上面点击右键添加变量,变量类型为CString 在此取名为m_NUM 直接使用m_NUM就是编辑框的CString, 举例: 在messagebox显 ...
- Unity3D 面试ABC
最先执行的方法是: 1.(激活时的初始化代码)Awake,2.Start.3.Update[FixUpdate.LateUpdate].4.(渲染模块)OnGUI.5.再向后,就是卸载模块(TearD ...
- Centos6.5 (或Linux) 安装Elasticsearch
一.可以在网上下载对饮的版本:https://github.com/elastic/elasticsearch,本次安装的是5.5.3. 首先保证虚拟机上安装了jdk,jdk的版本只是是1.7或以上 ...
- Web前端编码规范[转]
先插入一条广告,博主新开了一家淘宝店,经营自己纯手工做的发饰,新店开业,只为信誉!需要的亲们可以光顾一下!谢谢大家的支持!店名: 小鱼尼莫手工饰品店经营: 发饰.头花.发夹.耳环等(手工制作)网店: ...
- POJ-2184 Cow Exhibition(01背包变形)
Cow Exhibition Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10949 Accepted: 4344 Descr ...
- HDU 2089 - 不要62 - [数位DP][入门题]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2089 Time Limit: 1000/1000 MS (Java/Others) Memory Li ...