第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二最流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。

全文搜索引擎种类
1、elasticsearch
2、solr
3、sphinx
关系数据搜素缺点,也就是直接通过数据库搜索

elasticsearch(搜索引擎)都能弥补以上缺点
elasticsearch安装
1、elasticsearch是由Java开发的,所以首先要安装Java环境
注意:elasticsearch所需要的Java环境必须大于或者等于1.8版本
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我们下载Windows x64版本,jdk-8u144-windows-x64.exe文件,直接安装
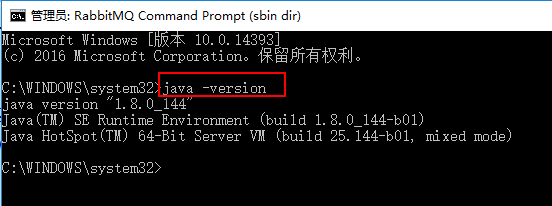
安装好后,我们cmd命令输入:java -version 查看java版本
2、elasticsearch-rtf安装
下载地址:https://github.com/medcl/elasticsearch-rtf 集成了我们很多插件
运行系统可用内存>2G
以下是集成安装的官方插件,个别插件需要配置才能使用,可根据需要删除 plugins 目录无关的插件,重启 elasticsearch 生效。
bin/elasticsearch-plugin install discovery-multicast
bin/elasticsearch-plugin install analysis-icu
bin/elasticsearch-plugin install analysis-kuromoji
bin/elasticsearch-plugin install analysis-phonetic
bin/elasticsearch-plugin install analysis-smartcn
bin/elasticsearch-plugin install analysis-stempel
bin/elasticsearch-plugin install analysis-ukrainian
bin/elasticsearch-plugin install discovery-file
bin/elasticsearch-plugin install ingest-attachment
bin/elasticsearch-plugin install ingest-geoip
bin/elasticsearch-plugin install ingest-user-agent
bin/elasticsearch-plugin install mapper-attachments
bin/elasticsearch-plugin install mapper-size
bin/elasticsearch-plugin install mapper-murmur3
bin/elasticsearch-plugin install lang-javascript
bin/elasticsearch-plugin install lang-python
bin/elasticsearch-plugin install repository-hdfs
bin/elasticsearch-plugin install repository-s3
bin/elasticsearch-plugin install repository-azure
bin/elasticsearch-plugin install repository-gcs
bin/elasticsearch-plugin install store-smb
bin/elasticsearch-plugin install discovery-ec2
bin/elasticsearch-plugin install discovery-azure-classic
bin/elasticsearch-plugin install discovery-gce
elasticsearch-rtf下载好解压后将文件夹复制到一个目录会得到以下文件

双击进入bin文件夹里,按shlft+鼠标右键,在此处打开命令窗口,输入 elasticsearch.bat 回车运行
然后在浏览器输入http://127.0.0.1:9200/ 返回数据说明成功

3、安装elasticsearch-rtf(搜索引擎)的可视化管理工具elasticsearch-head
注意:(搜索引擎)的可视化管理工具elasticsearch-head,的安装要用到node.js的npm 插件管理器
所以要先安装node.js的npm 插件管理器
下载地址:https://nodejs.org/en/download/
我们下载windows版本即可,下载后安装即可
安装后cdm命令:npm 如下显示表示安装成功

npm命令是node.js的npm 插件管理器,也就是下载插件安装插件的管理器,因为下载都是国外服务器很慢会掉线,我们需要使用淘宝的npm镜像cnpm
执行命令:npm install -g cnpm --registry=https://registry.npm.taobao.org 启用淘宝的npm镜像cnpm,注意:启用后当我们要输入npm命令时,就需要输入cnpm
(搜索引擎)的可视化管理工具elasticsearch-head的安装
下载地址:https://github.com/mobz/elasticsearch-head
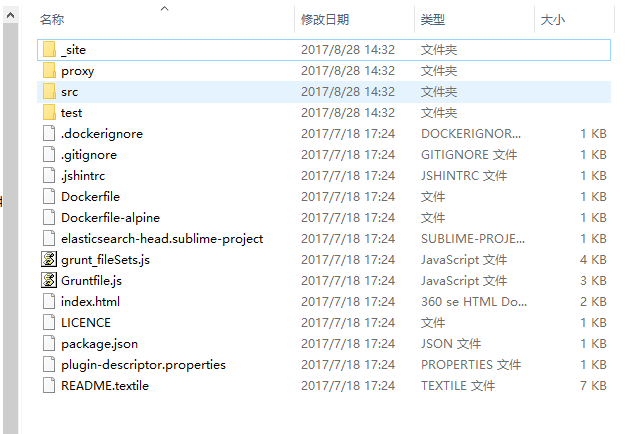
下载后解压到指定目录,会得到以下文件
cd进入到解压的elasticsearch-head目录
执行命令:cnpm install 安装elasticsearch-head的依赖包
在执行命令:cnpm run start 启动elasticsearch-head(搜索引擎)的可视化管理工具
访问后可以看到(搜索引擎)的可视化管理工具

我们看到显示未连接,我们需要配置elasticsearch-rtf(搜索引擎)连接,在elasticsearch-rtf/config/elasticsearch.yml 这个文件里配置
在文件的最后面写入
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
重启elasticsearch-rtf(搜索引擎)后就可以连接了

安装Kibana 5.1.2版本
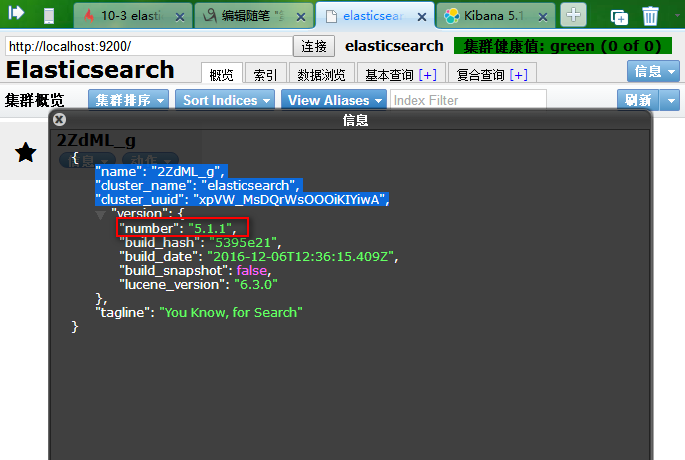
注意:Kibana的版本要对应elasticsearch-head里信息里的版本
下载地址:https://www.elastic.co/downloads/past-releases/kibana-5-1-2
我们下载windows版即可
将下载文件解压到指定目录,进入kibana-5.1.2/bin文件夹
cd 进入kibana-5.1.2/bin文件夹
执行命令:kibana.bat 运行kibana-5.1.2

浏览器访问:http://localhost:5601 如下显示说明成功

第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装的更多相关文章
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装
第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装 xadmin介绍 xadmin是基于Django的admin开发的更完善的后台管理系统,页面基于Bootstr ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页
第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页 根据用户的筛选条件来结合分页 实现原理就是,当用户点击一个筛选条件时,通过get请求方式传参将筛选的id或者值, ...
随机推荐
- 菜鸟学SSH(九)——Hibernate——Session之save()方法
Session的save()方法用来将一个临时对象转变为持久化对象,也就是将一个新的实体保存到数据库中.通过save()将持久化对象保存到数据库需要经过以下步骤: 1,系统根据指定的ID生成策略,为临 ...
- 如何让 zend studio 10 识别 Phalcon语法并且进行语法提示
让 zend studio 10 识别 Phalcon语法并且进行语法提示 https://github.com/rogerthomas84/PhalconPHPDoc 下载解压后,把里面 phalc ...
- (原) ubuntu下用pycharm2016.1专业版配docker编译环境(docker Interpreter)
一:先创建docker-machine 先创建docker machine.我主机上的虚拟机是virtualbox.$ docker-machine create --driver virtualbo ...
- 【嵌入式】S3C2410平台移植linux 2.6.14内核
小续 第一次接触内核的东西,有点小激动啊 激动归激动,这实验还是要继续做下去,书上三两句话就带过去的,剩下的就留给我们了,着实考验动手能力啊 当编译过内核之后,发现这个过程也不复杂嘛(复杂的是内核的配 ...
- vue实现点击区域外部的区域,关闭该区域
var _this = this; document.addEventListener('click',function(e){ console.log(_this.$refs.configforms ...
- csv和excel互转
Python csv转换为excel学习笔记: openpyxl模块需要安装pip install openpyxl import openpyxl import csv '''读取csv文件写入ex ...
- 通过Python的JIRA库操作JIRA
[本文出自天外归云的博客园] 前提 需要安装jira库: pip install jira 编写脚本 例如,我想统计一下某一jira的备注里是否有如下信息,没有则给予提示: [产品需求文档地址]:ht ...
- Commons.net FTPClient 上传文件
使用 Commons.net FTPClient 上传 文件打不开. 原因,FTPClient 默认使用 ASCII 传输文件,FTP.ASCII_FILE_TYPE; 需要在登录代码后重新指定传输方 ...
- 前端弹窗展示后台html文件
1,首先使用window.open函数,弹出返回jsp页面的窗口,对应viewZhengXinReport()方法,进行jsp页面的请求跳转forward 2,然后在jsp页面中使用ajax同步请求后 ...
- 1:(0or1)
public class User { public int ID { get; set; } public string UserName { get; set; } ...