第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
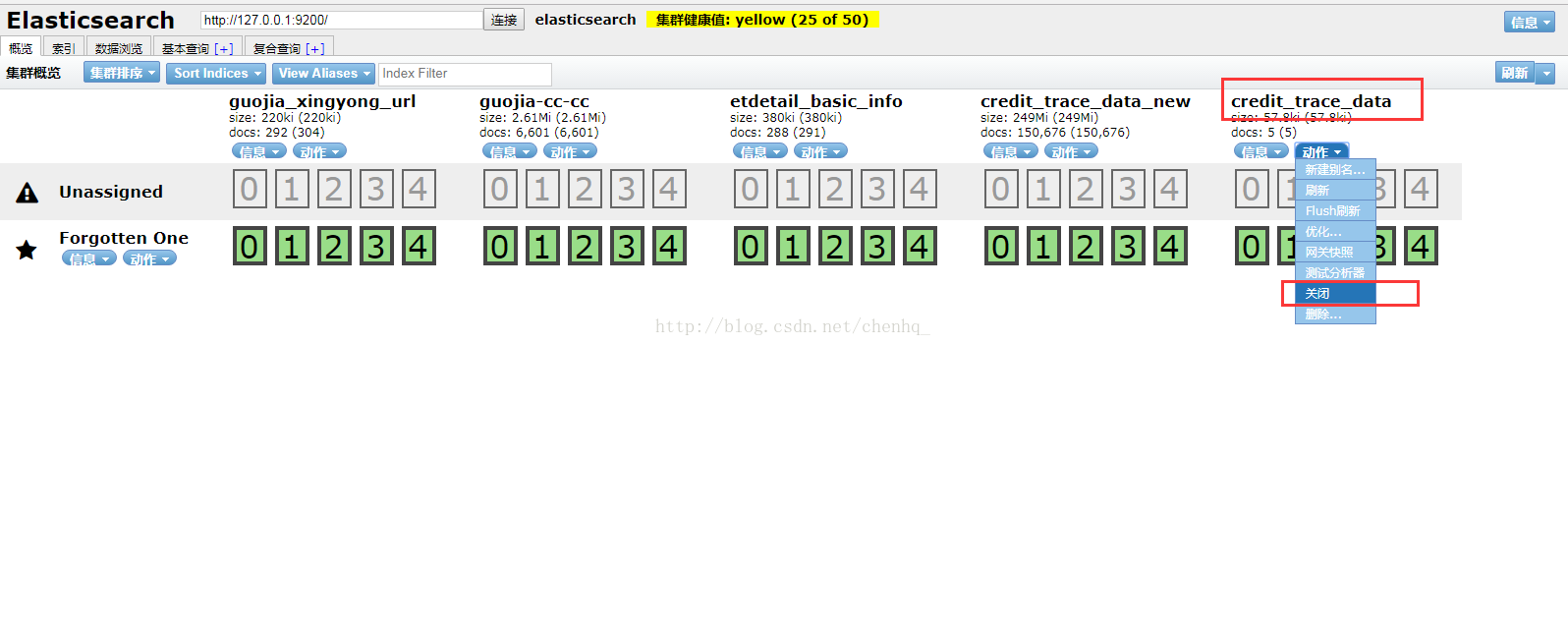
步骤二:
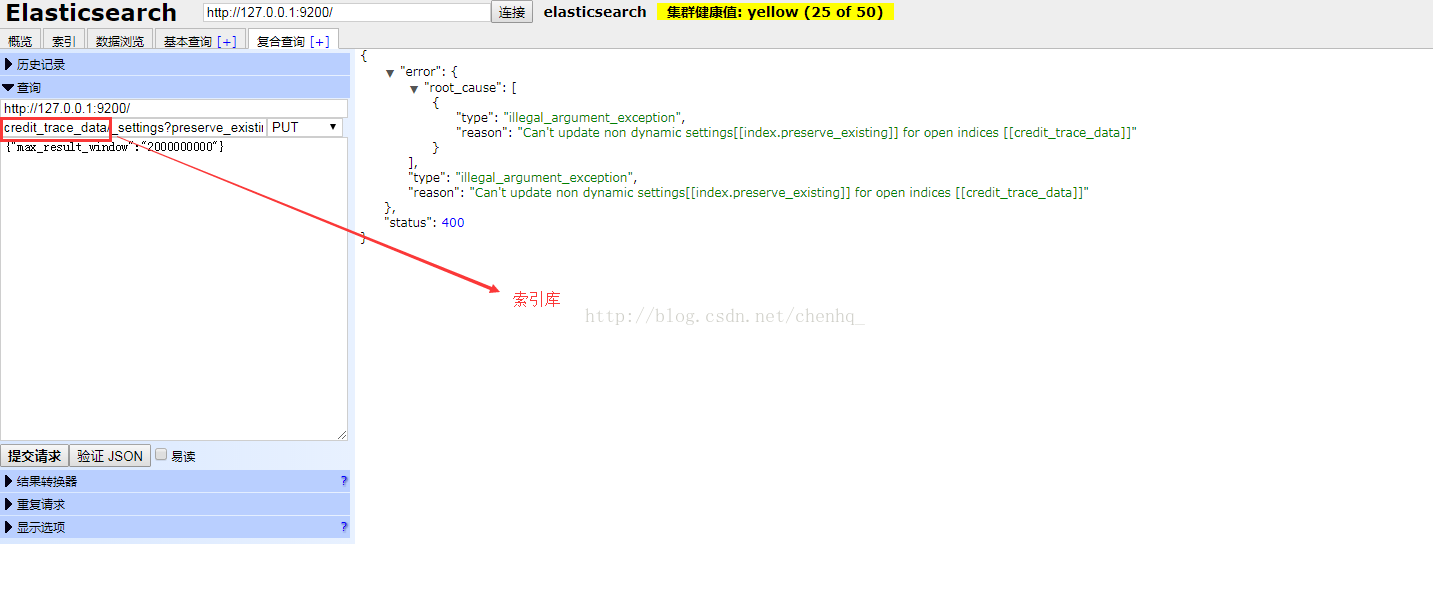
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
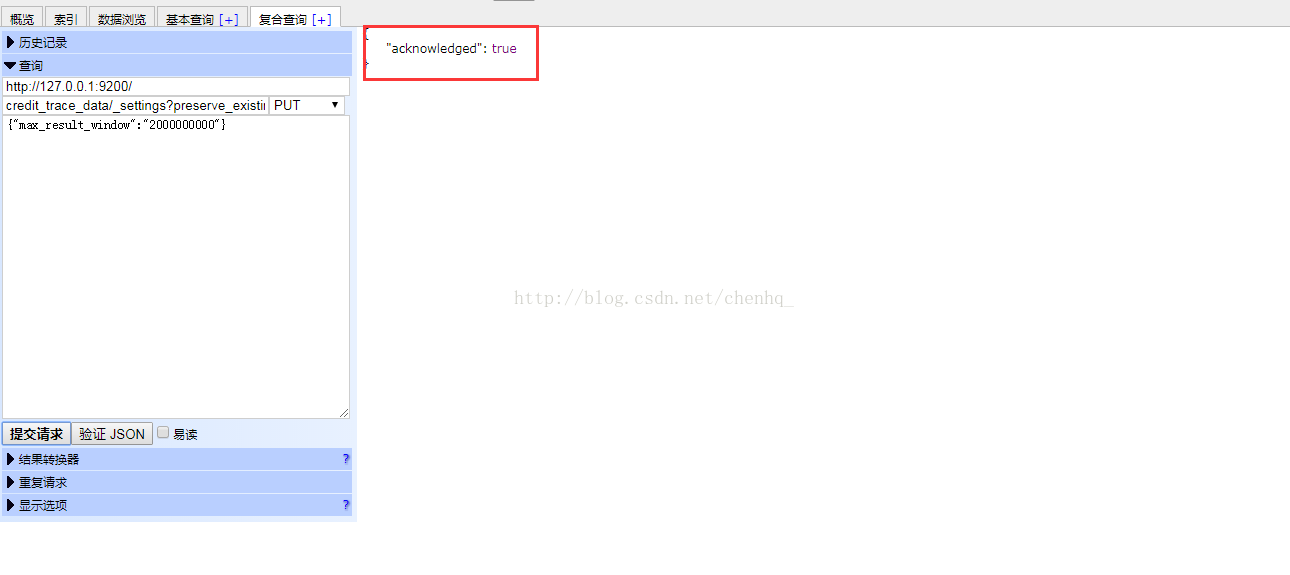
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
如果要查询max_result_window时只需要将PUT改为get即可
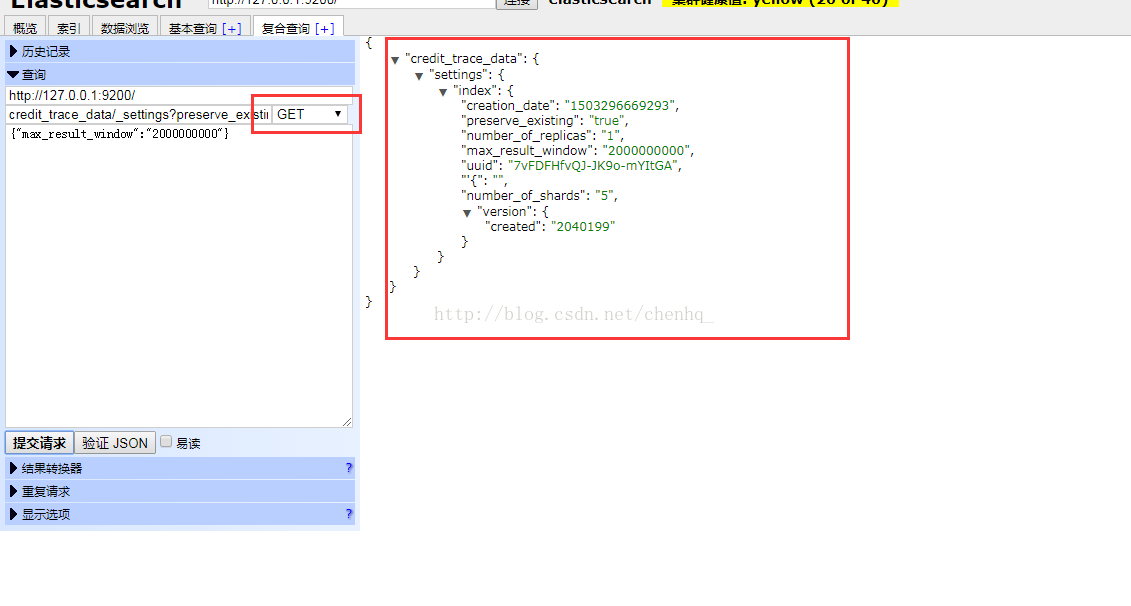
最后记得开启索引!
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索的更多相关文章
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
随机推荐
- HTML5学习笔记(二十三):DOM应用之动态加载脚本
同步加载和执行JS的情况 在HTML页面的</body>表情之前添加的所有<script>标签,无论是直接嵌入JS代码还是引入外部js代码都是同步执行的,这里的同步执行指的是在 ...
- 4-4-串的KMP匹配算法-串-第4章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第4章 串 - KMP匹配算法 ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚敏,吴伟民版)课本源码 ...
- linux安全配置检查脚本_v0.5
看到网上有人分享了一些linux系统的基线检查脚本,但有些检查项未必适合自己或者说检查的不够完善, 计划按着自己的需求重新写一份出来,其中脚本的检查范围在不断更新中. 脚本内容: [root@loca ...
- excel 添加换行符,去除换行符:
excel 中添加换行符: :alt+enter 去掉excel中的换行符有三种方法: 注:解决过程中翻阅其他博客,看到如下方式: 1.看到有的说全选后“取消自动换行”,保存后,再打开,依然存在换行符 ...
- linux命令(40):基础常用命令:cd,rm,mk
常用命令介绍 pwd,显示当前在哪个路径下 linux的用户管理 : useradd 用户名,添加用户 [案例]useradd xiaoming pas ...
- Android 编程下string-array 的使用
在实际开发中,当数据为固定数据.数据量不是很大.希望很方便的获取到这些数据的时候,可以考虑使用这种低成本的方式来获取预装数据.将想要保存的数据存储到 values 文件夹下的 arrays.xml 文 ...
- 【Linux】Linux根目录下各文件夹的意义
[root@localhost /]# ll / total 102 dr-xr-xr-x. 2 root root 4096 Dec 1 07:37 bin # binary file,二进制执行文 ...
- 使用flume将kafka数据sink到HBase【转】
1. hbase sink介绍 1.1 HbaseSink 1.2 AsyncHbaseSink 2. 配置flume 3. 运行测试flume 4. 使用RegexHbaseEventSeriali ...
- JAVA-JSP内置对象之application对象获得服务器版本
相关资料:<21天学通Java Web开发> application对象获得服务器版本1.通过application对象的getMajorVersion()方法和getMinorVersi ...
- java二维码的生成与解析代码
二维码,是一种采用黑白相间的平面几何图形通过相应的编码算法来记录文字.图片.网址等信息的条码图片.如下图 二维码的特点: 1. 高密度编码,信息容量大 可容纳多达1850个大写字母或2710个数字或 ...