caffe 中base_lr、weight_decay、lr_mult、decay_mult代表什么意思?
在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。
The learning rate is a parameter that determines how much an updating step influences the current value of the weights. While weight decay is an additional term in the weight update rule that causes the weights to exponentially decay to zero, if no other update is scheduled.
So let's say that we have a cost or error function E(w) that we want to minimize. Gradient descent tells us to modify the weights w in the direction of steepest descent in E:
where η is the learning rate, and if it's large you will have a correspondingly large modification of the weights wi(in general it shouldn't be too large, otherwise you'll overshoot the local minimum in your cost function).
In order to effectively limit the number of free parameters in your model so as to avoid over-fitting, it is possible to regularize the cost function. An easy way to do that is by introducing a zero mean Gaussian prior over the weights, which is equivalent to changing the cost function to E˜(w)=E(w)+λ2w2. In practice this penalizes large weights and effectively limits the freedom in your model. The regularization parameter λ determines how you trade off the original cost E with the large weights penalization.
Applying gradient descent to this new cost function we obtain:
The new term −ηλwi coming from the regularization causes the weight to decay in proportion to its size.
In your solver you likely have a learning rate set as well as weight decay. lr_mult indicates what to multiply the learning rate by for a particular layer. This is useful if you want to update some layers with a smaller learning rate (e.g. when finetuning some layers while training others from scratch) or if you do not want to update the weights for one layer (perhaps you keep all the conv layers the same and just retrain fully connected layers). decay_mult is the same, just for weight decay.
参考资料:http://stats.stackexchange.com/questions/29130/difference-between-neural-net-weight-decay-and-learning-rate
http://blog.csdn.net/u010025211/article/details/50055815
https://groups.google.com/forum/#!topic/caffe-users/8J_J8tc1ZHc
视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。

layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
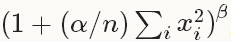 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
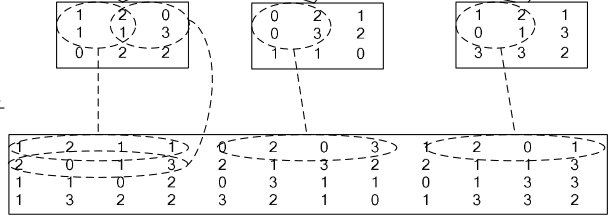
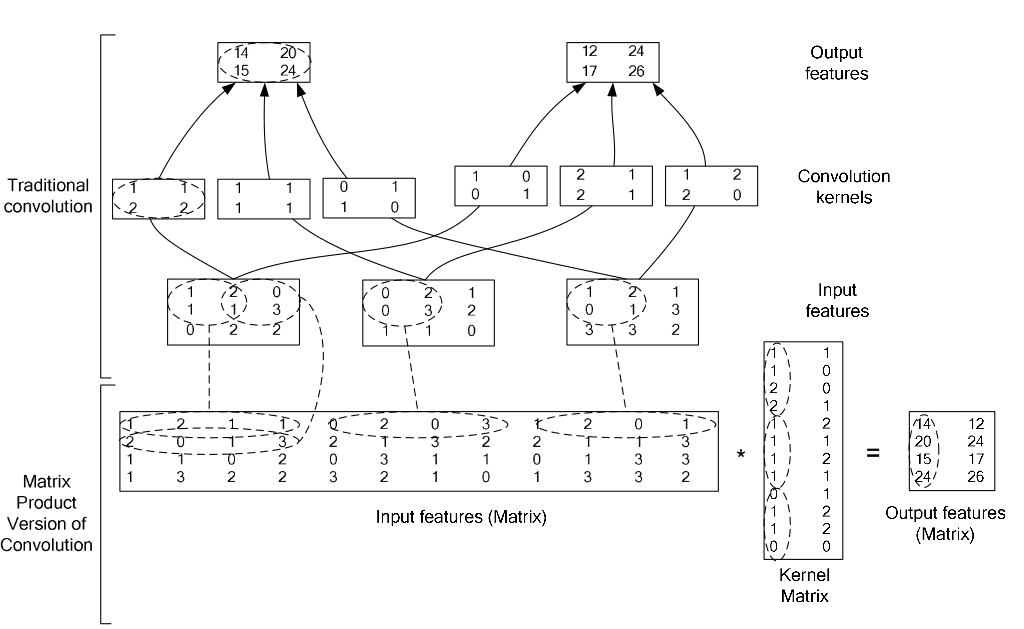
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
caffe 中base_lr、weight_decay、lr_mult、decay_mult代表什么意思?的更多相关文章
- 在Caffe中实现模型融合
模型融合 有的时候我们手头可能有了若干个已经训练好的模型,这些模型可能是同样的结构,也可能是不同的结构,训练模型的数据可能是同一批,也可能不同.无论是出于要通过ensemble提升性能的目的,还是要设 ...
- caffe中lenet_solver.prototxt配置文件注解
caffe框架自带的例子mnist里有一个lenet_solver.prototxt文件,这个文件是具体的训练网络的引入文件,定义了CNN网络架构之外的一些基础参数,如总的迭代次数.测试间隔.基础学习 ...
- caffe中权值初始化方法
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代 ...
- caffe中各层的作用:
关于caffe中的solver: cafffe中的sover的方法都有: Stochastic Gradient Descent (type: "SGD"), AdaDelta ( ...
- caffe中的Accuracy+softmaxWithLoss
转:http://blog.csdn.net/tina_ttl/article/details/51556984 今天才偶然发现,caffe在计算Accuravy时,利用的是最后一个全链接层的输出(不 ...
- caffe中LetNet-5卷积神经网络模型文件lenet.prototxt理解
caffe在 .\examples\mnist文件夹下有一个 lenet.prototxt文件,这个文件定义了一个广义的LetNet-5模型,对这个模型文件逐段分解一下. name: "Le ...
- 【神经网络与深度学习】如何在Caffe中配置每一个层的结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
- (原)torch和caffe中的BatchNorm层
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6015990.html BatchNorm具体网上搜索. caffe中batchNorm层是通过Batc ...
- CAFFE中训练与使用阶段网络设计的不同
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正要使 ...
随机推荐
- [VS]VS2010如何使用Visual Studio Online在线服务管理团队资源(在线TFS)
前言 Visual Studio Online,也就是以前的Team Foundation Service,从名字可以看出这是一个团队资源管理服务.在微软的云基础架构中运行,无需安装或配置任何服务器, ...
- Node复制文件
本人开发过程中,经常遇到,要去拷贝模板到当前文件夹,经常要去托文件,为了省事,解决这个问题,写了一个node复制文件. // js/app.js:指定确切的文件名.// js/*.js:某个目录所有后 ...
- 解析xml文件的几种技术与Dom4j与sax之间的对比
一.解析xml文件的几种技术:dom4j.sax.jaxb.jdom.dom 1.dom4j dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的.dom4j是一个非常优秀的 ...
- DLRS(近三年深度学习应用于推荐系统论文汇总)
Recommender Systems with Deep Learning Improving Scalability of Personalized Recommendation Systems ...
- opencv学习笔记霍夫变换——直线检测
参考大佬博文:blog.csdn.net/jia20003/article/details/7724530 lps-683.iteye.com/blog/2254368 openCV里有两个函数(比较 ...
- HDU 3642 - Get The Treasury - [加强版扫描线+线段树]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3642 Time Limit: 10000/5000 MS (Java/Others) Memory L ...
- CNN中的池化层的理解和实例
池化操作是利用一个矩阵窗口在输入张量上进行扫描,并且每个窗口中的值通过取最大.取平均或其它的一些操作来减少元素个数.池化窗口由ksize来指定,根据strides的长度来决定移动步长.如果stride ...
- C++中的类成员指针
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...
- Frame报文
链路层帧常用的帧格式有两种:Ethernet II 与 IEEE802.3 Ethernet II 格式多用于终端设备的通信 IEEE802.3 格式多用于网络设备的通信 如何区分这两种报文 ...
- 为什么使用 Redis及其产品定位(转)
原文:http://www.infoq.com/cn/articles/tq-why-choose-redis 传统MySQL+ Memcached架构遇到的问题 实际MySQL是适合进行海量数据存储 ...