AdaBoost学习笔记
学习了李航《统计学习方法》第八章的提升方法,现在对常用的一种提升方法AdaBoost作一个小小的笔记,并用python实现书本上的例子,加深印象。提升方法(boosting)是一种常用的统计学习方法,在分类中通过改变样本的权值分布,学习多个分类器,然后组合这些分类器,提高分类性能。
一、 提升方法的问题
1、训练弱分类器时如何更改样本权重或概率分布
2、如何组合弱分类器
AdaBoost的解决方案
1、在训练过程中,提高前一轮被分类器错误分类的样本权值,降低被正确分类的样本权值
2、采用加权多数表决的方法,即分类时误差小的分类器权重提高,分类误差大的分类器权重减小
二、AdaBoost算法步骤
1、初始化训练数据的权值分布(初始化时一般赋予相同的权值:1/N);
2、训练弱分类器。根据具有权值分布的训练数据,得到弱分类器,根据当前分类器,如果样本点被正确分类,则降低该样本的权值,反之提高权值,对样本权值分布进行更新,然后在根据更新后的样本数据训练下一个弱分类器;
3、组合弱分类器。根据分类器训练误差,计算分类器的权重,误差越大,权重越小,然后把加权后的分类器进行相加得到强分类器。
下面是一个二分类算法
算法: (输入:训练数据集T={(x1,y1),(x2,y2),..,(xN,yN))},输出:最终分类器)
(1)初始化训练数据的权值分布
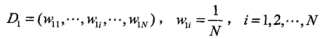
(2)训练弱分类器。对于m=1,2,...,M (M为弱分类器个数)
(a) 使用具有权值分布Dm的训练数据集学习,得到基本分类器
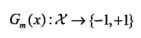
(b) 计算Gm(x)在训练数据集Dm上的分类误差率:
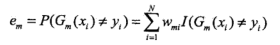
这里相当于把没有正确分类的样本对应的权值求和。
(c) 计算Gm(x)的权重系数:
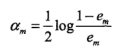
这里log表示自然对数,将am对em求导后可以得到对应的导函数为1/(em-1)em,误差0<em<1,所以对应的导函数小于0,即系数am随着误差em的增大而减少。
(d) 更新训练数据集权值分布:

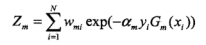
这里Zm是对权值进行归一化,保证权值和为1,另外样本如果正确分类,则yi*Gm(xi)为一个正数,前面添加负号和乘以am,这可以看出正确分类的样本其权值降低,错误分类的样本权值提高。
(3)构建基本分类器的线性组合,得到最终分类器


三、例题(python实现)
1、初始化权值分布
## 导入数据
import numpy as np
x = np.arange(10) # x共10个,利用numpy生成
y = np.array([1,1,1,-1,-1,-1,1,1,1,-1], dtype=int) #例题中对应的标签值 ## 权值初始化,一共10个数,初始权值赋为1/10
N = x.shape[0]
w_0 = np.array([1/N]*N) #先计算1/N,然后乘以个数
w_0

2、x1和x2之间的阀值取x1+(x2-x1)*b,x之间间隔为1,因此0<b<1都行,这里参照书本取b=0.5
# 得到所有阀值,存入列表
v = np.array([(x1+x2)/2 for x1, x2 in zip(x[:-1], x[1:])])
v

3、训练一个弱分类器
# 定义一个分类函数 输入:样本数据x,y,阀值v,权重w 输出:最佳阀值min_v,该分类器分类结果res,和权重alpha,以及误差min_error def get_res(x,y,v,w):
error_1 = [] # 用于存放所有阀值分类得到的误差
error_2 = []
res_1 = np.ones(x.shape[0], dtype=int) # 先初始化结果全为1 小于阀值取1,大于取-1
res_2 = np.ones(x.shape[0], dtype=int) # 先初始化结果全为1 小于阀值取-1,大于取1
for v_i in v: # 对每一个阀值计算分类误差
for x_i in x:
if x_i < v_i:
res_1[x_i] = 1
res_2[x_i] = -1
else:
res_1[x_i] = -1
res_2[x_i] = 1
error_1.append(np.sum(w[y!=res_1]))
error_2.append(np.sum(w[y!=res_2]))
min_error_1 = min(error_1) # 最小误差
min_error_2 = min(error_2)
if min_error_1 > min_error_2:
min_error = min_error_2
min_error_index = error_2.index(min_error_2) # 求出最小误差对应的索引值,用于找出最佳阀值
label = '小于取-1,大于取1'
state = 0 # 用于判断分类器怎么分类 求res
else:
min_error = min_error_1
min_error_index = error_1.index(min_error_1)
label = '小于取1,大于取-1'
state = 1
min_v = v[min_error_index] # 得到最佳阀值
alpha = 1/2 * np.log((1-min_error)/min_error) # 计算该分类器的权值
if state == 1:
res = [1 if x_i < min_v else -1 for x_i in x] # 计算该分类器分类结果
else:
res = [-1 if x_i < min_v else 1 for x_i in x]
return alpha, min_v, label, res, min_error
## 输入初始权值,进行测试
alpha1, v1, label, res1, min_error = get_res(x,y,v,w_0)
v1,label,alpha1,res1,min_error

4、更新样本数据权值分布
### 定义一个更新函数 输入:前一个分类器的权重alpha和分类结果res 样本标签y, 前一次样本权值分布w 输出:样本数据新的权值分布w
def update_data_weight(alpha, res, y, w):
numerator = w*np.exp(-alpha*y*res) # 8.4式分子
denominator = w.dot(np.exp(-alpha*y*res)) # 8.4式分母Zm
return numerator/denominator
## 测试
w_1 = update_data_weight(alpha1, res1, y, w_0)
w_1
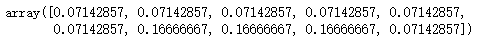
5、构建最终分类器
## alpha 各弱分类器权重列表
## res 各弱分类器分类结果列表 def final_model(alpha, res):
f = np.sum(alpha*res, axis=0)
return [1 if i > 0 else -1 for i in f]
这里在对其进行综合,代码如下。
n = 3 # 弱分类器个数1
sigmma = 0.001 # 终止误差 x = np.arange(10) # 样本中x值
y = np.array([1,1,1,-1,-1,-1,1,1,1, -1], dtype=int) # 样本中x对应的标签值 N = x.shape[0] # 样本个数 alpha = np.zeros((n, 1)) # 初始化分类器权重矩阵
W = np.zeros((n, N)) # 初始化权值分布
res = np.zeros((n, N)) # 初始化各分类器结果
res_save = [] # 保存每一次的阀值和误差 w = np.array([1/N]*N) # 样本初始权值分布 v = np.array([(x1+x2)/2 for x1, x2 in zip(x[:-1], x[1:])]) # 所有阀值 for i in range(n):
alpha_i, v_i, label, res_i, min_error_i = get_res(x,y,v,w) if min_error_i < sigmma: # 如果满足误差要求 停止迭代
break
w = update_data_weight(alpha_i, res_i, y, w)
alpha[i] = alpha_i
res[i:] = res_i
res_save.append([v_i, label, min_error_i])
W[i:] = w result = final_model(alpha, res)
print('最终分类结果:', result)
print('各分类器分类结果:', res)
print('各分类器系数:', alpha)
print('各分类器阀值及误差:',res_save)
print('样本权值分布:',W)

AdaBoost学习笔记的更多相关文章
- 机器学习7—AdaBoost学习笔记
Adaboost算法原理分析和实例+代码(简明易懂)(转载) [尊重原创,转载请注明出处] http://blog.csdn.net/guyuealian/article/details/709953 ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- 概率图模型学习笔记:HMM、MEMM、CRF
作者:Scofield链接:https://www.zhihu.com/question/35866596/answer/236886066来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- 2014年暑假c#学习笔记目录
2014年暑假c#学习笔记 一.C#编程基础 1. c#编程基础之枚举 2. c#编程基础之函数可变参数 3. c#编程基础之字符串基础 4. c#编程基础之字符串函数 5.c#编程基础之ref.ou ...
- JAVA GUI编程学习笔记目录
2014年暑假JAVA GUI编程学习笔记目录 1.JAVA之GUI编程概述 2.JAVA之GUI编程布局 3.JAVA之GUI编程Frame窗口 4.JAVA之GUI编程事件监听机制 5.JAVA之 ...
- seaJs学习笔记2 – seaJs组建库的使用
原文地址:seaJs学习笔记2 – seaJs组建库的使用 我觉得学习新东西并不是会使用它就够了的,会使用仅仅代表你看懂了,理解了,二不代表你深入了,彻悟了它的精髓. 所以不断的学习将是源源不断. 最 ...
随机推荐
- yii的安装
1.安装composer windows系统直接下载Composer-Setup.exe 运行安装. 2.安装Composer asset plugin composer安装完成后,在一个可通过web ...
- Shell sleep指定延迟时间
可以给时间,让上一条命令执行完毕后,并且退出 sleep 1 睡眠1秒sleep 1s 睡眠1秒sleep 1m 睡眠1分sleep 1h 睡眠1小时
- 一个sfm开源项目
Structure from Motion 资料总结 https://blog.csdn.net/u014636245/article/details/77527627 github上用opencv实 ...
- python中的字符串切片
python中的字符串切片,似乎有点乱,例如: >>>pystr='Python' >>>pystr[2:5] 就会输出 'tho' 这该怎样理解呢?中括号[2:5 ...
- UVA - 11624 Fire! bfs 地图与人一步一步先后搜/搜一次打表好了再搜一次
UVA - 11624 题意:joe在一个迷宫里,迷宫的一些部分着火了,火势会向周围四个方向蔓延,joe可以向四个方向移动.火与人的速度都是1格/1秒,问j能否逃出迷宫,若能输出最小时间. 题解:先考 ...
- ubuntu 添加用户到已存在的组
sudo adduser 用户名 组名 sudo minicom –s 配置 minicom访问ttyUSB0没权限,发现属于dialout 组 james@james-OptiPlex-380: ...
- ios-Objective-C中的各种遍历(迭代)方式(转载)
iOS开发实用技巧—Objective-C中的各种遍历(迭代)方式 说明: 1)该文简短介绍在iOS开发中遍历字典.数组和集合的几种常见方式. 2)该文对应的代码可以在下面的地址获得:https:// ...
- 图论——最小生成树prim+邻接表+堆优化
今天学长对比了最小生成树最快速的求法不管是稠密图还是稀疏图,prim+邻接表+堆优化都能得到一个很不错的速度,所以参考学长的代码打出了下列代码,make_pair还不是很会,大体理解的意思是可以同时绑 ...
- 【Git 使用笔记】第四部分:git在公司中的开发流程
先声明几个变量 仓管A:主分支,只有master分支仓管B:开发分支,只有各个业务开发分支 仓管B fork 于 A 如下图 为了保证 代码的稳定性,只有 仓管B中的某个分支测试完毕并进行了代码r ...
- 如何去除WIN7任务栏项目上右键菜单中的最近访问一栏
运行gpedit.msc-->用户配置-->管理模板-->任务栏和开始菜单-->将"不保留最近打开文档的记录"和"退出系统时清空最近打开文档的记录 ...