机器学习算法--GBDT
转自 http://blog.csdn.net/u014568921/article/details/49383379
另外一个很容易理解的文章 :http://www.jianshu.com/p/005a4e6ac775
更多参考如下
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple Additive Regression Tree(MART),阿里貌似叫treelink。
首先学习GBDT要有决策树的先验知识。
Gradient Boosting Decision Tree,和随机森林(random forest)算法一样,也是通过组合弱学习器来形成一个强学习器。GBDT的发明者是Friedman,至于随机森林则是Friedman的好基友Breiman发明的。不过,GBDT算法中用到的决策树只能是回归树,这是因为该算法的每颗树学的是之前所有树结论之和的残差,这个残差就是一个累加预测值后能得到真实值。通过将每次预测出的结果与目标值的残差作为下一次学习的目标。
想看英文原文的:
greedy function approximation :a gradient boosting machine.--GBDT发明者Friedman的文章
Stochastic gradient boosting。还是Friedman的
Boosted Regression (Boosting): An introductory tutorial and a Stata plugin。
决策树
以CART决策树为例,简单介绍一下回归树的构建方法。



下面介绍gradient boost。
gradient boost
Boost是”提升”的意思,一般Boosting算法都是一个迭代的过程,每一次新的训练都是为了改进上一次的结果。我们熟悉的adaboost算法是boost算法体系中的一类。gradient boost也属于boost算法体系。
Gradient Boost其实是一个框架,里面可以套入很多不同的算法。每一次的计算都是为了减少上一次的残差,为了消除残差,我们可以在残差减少的梯度方向建立一个新的模型,所以说,每一个新模型的建立都为了使得之前的模型残差向梯度方向上减少。它用来优化loss function有很多种。

下面是通用的gradient boost框架



要学习的回归树的参数就是每个节点的分裂属性、最佳切点和节点的预测值。


GBDT算法流程

Friedman的文章greedy function approximation :a gradient boosting machine.中的least-square regression算法如下:

里面yi-Fm-1求得的即是残差,每次就是在这个基础上学习。
两个版本的GBDT
目前GBDT有两个不同的描述版本,网上写GBDT的大都没有说清楚自己说的是哪个版本,以及不同版本之间的不同是什么,读者看不同的介绍会得到不同的算法描述,实在让人很头痛。
残差版本把GBDT说成一个残差迭代树,认为每一棵回归树都在学习前N-1棵树的残差,前面所说的主要在描述这一版本。
Gradient版本把GBDT说成一个梯度迭代树,使用梯度下降法求解,认为每一棵回归树在学习前N-1棵树的梯度下降值。
要解决问题还是阅读Friedman的文章。
读完greedy function approximation :a gradient boosting machine.后,发现4.1-4.4写的是残差版本的GBDT,这一个版本主要用来回归;4.5-4.6写的是Gradient版本,它在残差版本的GBDT版本上做了Logistic变换,Gradient版本主要是用来分类的。
分类问题与回归问题不同,每棵树的样本的目标就不是一个数值了,而是每个样本在每个分类下面都有一个估值Fk(x)。
同逻辑回归一样,假如有K类,每一个样本的估计值为F1(x)...Fk(x),对其作logistic变化之后得到属于每一类的概率是P1(x)...pk(x),

则损失函数可以定义为负的log似然:

其中,yk为输入的样本数据的估计值,当一个样本x属于类别k时,yk = 1,否则yk = 0。
将Logistic变换的式子带入损失函数,并且对其求导,可以得到损失函数的梯度:

可以看出对多分类问题,新的一棵树拟合的目标仍是残差向量。
用Logistic变换后的算法如下:

对第一棵树,可以初始化每个样本在每个分类上的估计值Fk(x)都为0;计算logistic变换pk(x),计算残差向量,作为当前树的回归的目标,回归树的分裂过程仍可采用【左子树样本目标值(残差)和的平方均值+右子树样本目标值(残差)和的平方均值-父结点所有样本目标值(残差)和的平方均值】最大的那个分裂点与分裂特征值等方法;当回归树的叶子节点数目达到要求示,则该树建立完成;对每个叶子节点,利用落到该叶子节点的所有样本的残差向量,计算增益rjkm;更新每一个样本的估计值Fk(x);因此,又可以对估计进行logistic变化,利用样本的目标值计算残差向量,训练第二棵树了。
正则化regularization
Shrinkage:即学习率
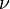 就是学习率。 一般情况下,越小的学习率,可以越好的逼近预测值,不容易产生过拟合,迭代次数会增加,经验上一般选取0.1左右。
就是学习率。 一般情况下,越小的学习率,可以越好的逼近预测值,不容易产生过拟合,迭代次数会增加,经验上一般选取0.1左右。

使用缩减训练集
Friedman提出在每次迭代时对base learner从原始训练集中随机抽取一部分(a subsample of the training set drawn at random without replacement)作为本次base learner去拟合的样本集可以提高算法最后的准确率。
限制叶节点中样本的数目
这个在决策树中已经提到过。
剪枝
这个在决策树中已经提到过。
限制每颗树的深度
树的深度一般取的比较小,需要根据实际情况来定。
迭代的次数d
也即最多有多少棵树,树太多可能造成过拟合,即在训练集上表现很好,测试集上表现糟糕;太少则会欠拟合。树的棵树和shrink有关,shrink越小,树会越多。
几个细节提一下
对初始分类器(函数)的选择就可以直接用0,通过平方差LOSS函数求得的残差当然就是样本本身了;也可以选择样本的均值;
一棵树的分裂过程只需要找到找到每个结点的分裂的特征id与特征值,而寻找的方法可以是平均最小均方差,也可以是使得(左子树样本目标值和的平方均值+右子树样本目标值和的平方均值-父结点所有样本目标值和的平方均值)最大的那个分裂点与分裂特征值等等方法;从而将样本分到左右子树中,继续上面过程;
注意样本的估计值Fk(x)是前面所有树的估值之和,因此,计算残差时,用样本的目标值减去Fk(x)就可以得到残差了
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html这篇文章关于分类讲得比较好,借鉴了他写的一些,例子也很好,大家可以看看。
https://github.com/MLWave/Kaggle-Ensemble-Guide
机器学习算法--GBDT的更多相关文章
- 机器学习算法GBDT的面试要点总结-上篇
1.简介 gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩.原因大概有几个,一是效果确实挺不错.二是 ...
- 机器学习算法GBDT
http://www-personal.umich.edu/~jizhu/jizhu/wuke/Friedman-AoS01.pdf https://www.cnblogs.com/bentuwuyi ...
- 机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法.在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示.以决策树为基学习器的提升方法称为提升树(Boosting Tree).对 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- paper 17 : 机器学习算法思想简单梳理
前言: 本文总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想. 朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- LightGBM详细用法--机器学习算法--周振洋
LightGBM算法总结 2018年08月21日 18:39:47 Ghost_Hzp 阅读数:2360 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
随机推荐
- e615. Finding the Next Focusable Component
public Component findNextFocus() { // Find focus owner Component c = KeyboardFocusManager.getCurrent ...
- mothur reverse.seqs 将序列反向互补
reverse.seqs 命令可以得到输入序列的反向互补序列 用法: mothur "#reverse.seqs(fasta = "input.fasta")" ...
- MATLAB错误:下标索引必须是正整数类型或者逻辑类型
背景: Matlab R2015b 问题: 在运行BP算法时出现错误: 下标索引必须是正整数类型或者逻辑类型 output( i , class( i ) ) = 1 ; 解决办法: 根目录下运行, ...
- java多线程入门学习(一)
java多线程入门学习(一) 一.java多线程之前 进程:每一个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销.一个进程包括1--n个线程. 线程:同一类线程共享代码 ...
- 在PC上运行安卓(Android)应用程序的4个方法
我有一部荣耀3C,一般放在宿舍(我随身携带的是一部诺基亚E63,小巧.稳定.待机时间长),在宿舍我就会用它在微信上看公众号里的文章,最近要考驾照也在上面用驾考宝典.最近想在实验室用这两个软件,但又懒得 ...
- asp.net c# repeater或gridview导出EXCEL的详细代码。
Response.Clear(); Response.Charset = "GB2312"; Response.ContentEncoding = System.Text.Enco ...
- Thinkphp5笔记二:创建模块
系统:window 7 64位 Thinkphp版本:5.0.5 环境:wampserver集成 我的项目是部署在本地www/thinkphp 目录下.在做之前,先要考虑清楚,你需要几个模块来完成你 ...
- JS判断设备类型跳转至PC端或移动端相应页面
if((navigator.userAgent.match(/(phone|pad|pod|iPhone|iPod|ios|iPad|Android|Mobile|BlackBerry|IEMobil ...
- PGsql 基本用户权限操作
Ⅰ. 安装与初始账户密码修改 1. 安装 sudo apt-get install postgresql-9.4 2. 管理员身份打开pg sudo -u postgres psql sudo -u ...
- 使用java启动mybatis generator
1.java工程目录结构: |src/main/java |com.leslie.mybatis.generator |MybatisGeneratorUtil.java |src/main/reso ...