CUDA C Programming Guide 在线教程学习笔记 Part 10【坑】
▶ 动态并行。
● 动态并行直接从 GPU 上创建工作,可以减少主机和设备间数据传输,在设备线程中调整配置。有数据依赖的并行工作可以在内核运行时生成,并利用 GPU 的硬件调度和负载均衡。动态并行要求算法和程序要提前改进,消除递归、不规则的循环、结构或其他不适合并行的情况。
● 动态并行的经典图
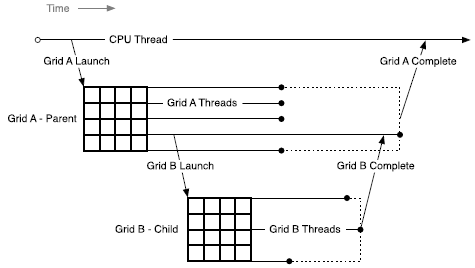
● 主机中 Runtime API 提供了跟踪运行核、流与事件的函数,对主机进程中的所有线程来说 CUDA 对象都是可共享的,但是主机调用的各核函数之间是相互独立的,CUDA 对象不能共享(重叠读写)。同样的情况也存在于设备中创建子内核函数的时候。
● 父线程中的 Runtime API 操作对于该线程所在的线程块是可见的。意思就是在同一个线程块中可以由任意一个线程来调用子内核、调整流和事件,其作用等价。
● 动态并行隐式的完成了父线程和子线程之间的同步,要求所有的子线程都结束后父线程才能结束。若 “父线程所在的线程块中所有的线程” 都在 “子线程结束前” 全部结束了,则子线程隐式的强制结束。
● 父线程格与子线程格共享全局内存和常量内存,但是共享内存和局部内存私有。
● 父线程与子线程在两个时间节点上共享的全局内存具有一致性:父线程格调用子线程格的时候;子线程格计算完成后,在父线程格中调用同步函数的时候。意思就是,父线程格先对全局内存进行操作,然后调用子线程格,则这些操作对子线程格来说都是可见的;子线程格对全局内存进行操作,然后在父线程格中进行同步,则这些操作对父线程格来说都是可见的。
● 动态并行与父 - 子内核之间的全局内存同步的代码举例。
// 子内核
__global__ void child_launch(int *data)
{
data[threadIdx.x] = data[threadIdx.x] + ;
} // 父内核
__global__ void parent_launch(int *data)
{
data[threadIdx.x] = threadIdx.x; __syncthreads(); // 同步所有父线程对全局内存的读写 if (threadIdx.x == )// 使用一个线程来启动子内核
{
child_launch << < , >> >(data);
// 调用子内核时,隐式保证了父线程对全局内存读写(data[0] = 0)对子内核可见,
// 但不能保证父内核中其他线程的全局内存读写可见(因为调用子线程时父内核中其他线程的全局内存读写不一定都完成了)
// 这里多亏调用子内核之前使用了 __syncthreads();,保证父内核中所有线程的全局内存读写在调用子内核之前都已经完成,保证了子内核可见
cudaDeviceSynchronize();// 退出子内核时使用同步,保证父线程对子内核的全局内存读写可见
}
__syncthreads();// 父内核同步,保证父内核中所有线程对子内核的全局内存读写都可见
} void host_launch(int *data)
{
parent_launch << < , >> >(data);
}
● 零拷贝内存与全局内存具有相同的一致性,且不能在设备代码中申请或释放。
● 常量内存不能被设备修改,保证了设备之间高度的一致性。所有的常量内存都应该调用核函数之前由主机读写完成,调用核函数时常量内存就被自动继承。主机与设备之间、设备与设备之间常量内存的指针可以平凡传递。
● 共享内存被线程块私有,局部内存被线程私有,两者均不能在父内核与子内核之间共享。把共享内存指针或局部内存指针传递给子内核的时候编译器会发出警告;可以使用函数 __isGlobal() 来检测一个指针是否指向全局内存,防止将一个共享内存指针或局部内存指针传递给子内核;
// sm_20_intrinsics.h
// "ptr" 指向全局内空间则返回 1;指向共享、局部、常量内存空间则返回 0
__SM_20_INTRINSICS_DECL__ unsigned int __isGlobal(const void *ptr)
{
unsigned int ret;
asm volatile ("{ \n\t"
" .reg .pred p; \n\t"
" isspacep.global p, %1; \n\t"
" selp.u32 %0, 1, 0, p; \n\t"
#if (defined(_MSC_VER) && defined(_WIN64)) || defined(__LP64__) || defined(__CUDACC_RTC__)
"} \n\t" : "=r"(ret) : "l"(ptr));
#else
"} \n\t" : "=r"(ret) : "r"(ptr));
#endif return ret;
}
● 需要在父内核与子内核之间传递的内存可以在全局作用域里显式的声明(__device__ int array[256];),防止在父内核中将局部内存地址传入子内核。
● 纹理内存存与全局内存具有相同的一致性,注意使用同步函数来获得父内核与子内核之间的一致。
● 父内核启用子内核的过程是异步的,这与主机启用内核的情况相同。
● 子内核集成父内核的配置参数,即函数 cudaDeviceGetCacheConfig() 和 cudaDeviceGetLimit() 调整的缓存、共享内存及其他参数。从主机中调用内核时使用的设置优先于全局默认设置,且不能在设备中调用子内核的时候更改这些设置。
● 流可以在指定的线程块中的任意线程使用,但流句柄不能在线程块之间、父子内核之间传递。不同的流中启动的内核可以并行运行,但不保证并发,这点在主机和设备之间、设备父子内核之间局成立。
● 主机端 NULL 流的跨流屏障语义对设备穿件的流不适用。设备内的流不能使用函数 cudaStreamCreate() 来创建,而是要使用函数 cudaStreamCreateWithFlags() 来创建,并传入标志 cudaStreamNonBlocking。
● 设备流中的同步不能使用函数 cudaStreamSynchronize() 或 cudaStreamQuery(),而要使用函数cudaDeviceSynchronize()。
● 主机端的 NULL 流隐式地添加了标志 cudaStreamNonBlocking, NULL 流中启动的的内核不会依赖于其他流中挂起的工作(work launched into the NULL stream will not insert an implicit dependency on pending work in any other streams)。
● 自内核仅支持 CUDA 事件的流内同步功能,意思就是函数 cudaStreamWaitEvent()是可用的,但函数 cudaEventSynchronize(),cudaEventElapsedTime(),cudaEventQuery() 不可用。而且在子线程块中创建事件时,还需要向函数 cudaEventCreateWithFlags() 传入标志 cudaEventDisableTiming。
● 事件在创建它的线程块中的所有线程之间共享,不能传递给另一个内核或线程块。事件句柄不能保证在块之间唯一,所以使用事件句柄前要先创建。
● (?) It is up to the program to perform sufficient additional inter-thread synchronization, for example via a call to __syncthreads(), if the calling thread is intended to synchronize with child grids invoked from other threads.
● (?) The cudaDeviceSynchronize() function does not imply intra-block synchronization. In particular, without explicit synchronization via a __syncthreads() directive the calling thread can make no assumptions about what work has been launched by any thread other than itself. For example if multiple threads within a block are each launching work and synchronization is desired for all this work at once (perhaps because of event-based dependencies), it is up to the program to guarantee that this work is submitted by all threads before calling cudaDeviceSynchronize().
● (?) Because the implementation is permitted to synchronize on launches from any thread in the block, it is quite possible that simultaneous calls to cudaDeviceSynchronize() by multiple threads will drain all work in the first call and then have no effect for the later calls.
● 一个内核只能在一个设备上启用,父内核中不能使用函数 cudaSetDevice() 或 cudaGetDevicePropertites(),但可以使用函数 cudaDeviceGetAttribute() 来访问其他设备的属性。
● 在文件作用域内声明的 __device__ 和 __constant__ 变量可以被所有内核进行读写或读。
● 只能在主机端创建或销毁纹理或表面对象,设备中不能。只有顶层内核(直接被主机调用的内核)中才能使用纹理和表面(The device runtime does not support legacy module-scope textures and surfaces within a kernel launched from the device)。
● 主机与内核之间、设备中父子内核之间均可使用静态或动态的方法调用共享内存,但是数据传递需要借助全局内存来实现。全局内存地址可以直接用 & 算符来获取。
● 内核中常量内存可以直接引用,且不能更改其内容,所以内核中不支持函数 cudaMemcpyToSymbol() 或 cudaGetSymbolAddress()。
● 内核中也可以使用函数 cudaGetLastError() 来捕获调用内核的错误,注意同时启用多个内核的时候可能会发生多个错误,但是该函数返回值中只保存了最后一个。
● 调用内核的 <<< >>> 算符实际上在 PTX 中被解释为函数 cudaGetParameterBuffer() 和函数 cudaLaunchDevice(),(在 cuda_cevice_runtime_api.h中的定义稍有不同)。
extern __device__ cudaError_t cudaGetParameterBuffer(void **params);
extern __device__ cudaError_t cudaLaunchDevice(void *kernel, void *params, dim3 gridDim, dim3 blockDim, unsigned int sharedMemSize = , cudaStream_t stream = );
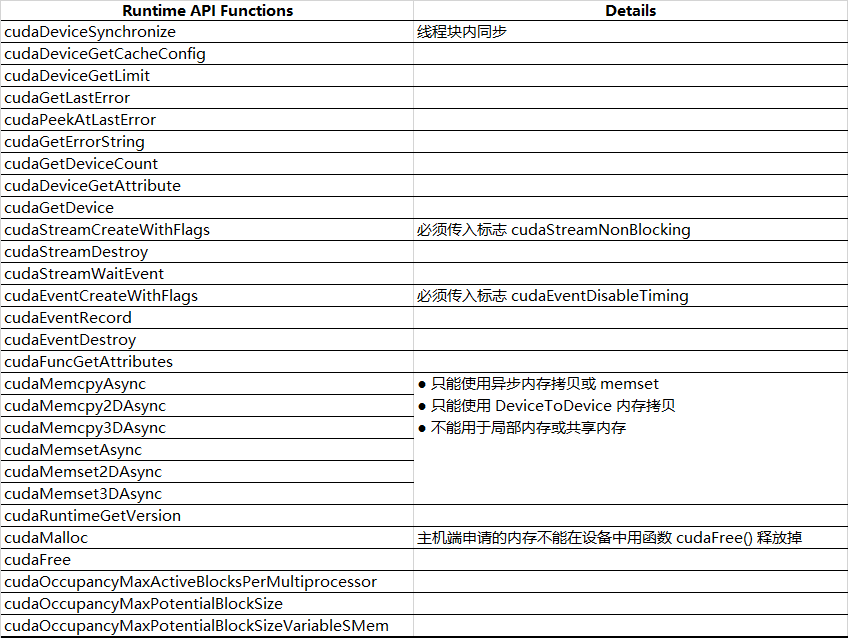
● 给出了所有能在设备代码中使用的 Runtime API 函数。
● PTX 阶段内核调用的低层次实现,详细说明函数 cudaGetParameterBuffer() 和函数 cudaLaunchDevice() 的细节。
■ PTX 阶段 cudaLaunchDevice() 的两种实现。
// .address_size == 64
.extern.func(.param.b32 func_retval0) cudaLaunchDevice
(
.param.b64 func,
.param.b64 parameterBuffer,
.param.align .b8 gridDimension[],
.param.align .b8 blockDimension[],
.param.b32 sharedMemSize,
.param.b64 stream
); // .address_size == 32
.extern.func(.param.b32 func_retval0) cudaLaunchDevice
(
.param.b32 func,
.param.b32 parameterBuffer,
.param.align .b8 gridDimension[],
.param.align .b8 blockDimension[],
.param.b32 sharedMemSize,
.param.b32 stream
);
■ PTX 阶段 cudaGetParameterBuffer() 的两种实现。
// .address_size == 64
.extern.func(.param.b64 func_retval0) cudaGetParameterBuffer
(
.param.b64 alignment,
.param.b64 size
); // .address_size == 32
.extern.func(.param.b32 func_retval0) cudaGetParameterBuffer
(
.param.b32 alignment,
.param.b32 size
);
■ 使用的两个函数的声明。动态并行中必须要有头文件 cuda_device_runtime_api.h,不过其已经在 Runtime 环境中被包含了(cuda_runtime.h)。
extern "C" __device__ cudaError_t cudaLaunchDevice(void *func, void *parameterBuffer, dim3 gridDimension, dim3 blockDimension, unsigned int sharedMemSize, cudaStream_t stream);
extern "C" __device__ void *cudaGetParameterBuffer(size_t alignment, size_t size); // cuda_device_runtime_api.h
static __inline__ __device__ __cudart_builtin__ cudaError_t CUDARTAPI cudaLaunchDevice(void *func, void *parameterBuffer, dim3 gridDimension, dim3 blockDimension, unsigned int sharedMemSize, cudaStream_t stream)
{
return cudaLaunchDevice_ptsz(func, parameterBuffer, gridDimension, blockDimension, sharedMemSize, stream);
}
static __inline__ __device__ __cudart_builtin__ cudaError_t CUDARTAPI cudaLaunchDeviceV2(void *parameterBuffer, cudaStream_t stream)
{
return cudaLaunchDeviceV2_ptsz(parameterBuffer, stream);
}
extern __device__ __cudart_builtin__ cudaError_t CUDARTAPI cudaLaunchDevice(void *func, void *parameterBuffer, dim3 gridDimension, dim3 blockDimension, unsigned int sharedMemSize, cudaStream_t stream);
extern __device__ __cudart_builtin__ cudaError_t CUDARTAPI cudaLaunchDeviceV2(void *parameterBuffer, cudaStream_t stream); extern __device__ __cudart_builtin__ void * CUDARTAPI cudaGetParameterBuffer(size_t alignment, size_t size);
■ 函数 cudaGetParameterBuffer() 的第一个参数是数据缓冲区的对齐值,默认为 64 Byte,以保证各种类型的数据都能容纳。(?) Parameter reordering in the parameter buffer is prohibited, and each individual parameter placed in the parameter buffer is required to be aligned. That is, each parameter must be placed at the nth byte in the parameter buffer, where n is the smallest multiple of the parameter size that is greater than the offset of the last byte taken by the preceding parameter. The maximum size of the parameter buffer is 4KB.
● 编译使用动态并行的程序需要显式链接库文件(Windows:cudadevrt.lib,Linux MacOS:libcudadevrt.a)。
# 直接编译和连接
$ nvcc hello_world.cu -o hello.exe -arch=sm_35 -rdc=true -lcudadevrt # 先编译后连接
$ nvcc hello_world.cu -o hello_world.o -arch=sm_35 -dc
$ nvcc hello_world.o -o hello.exe -arch=sm_35 -rdc=true -lcudadevrt
CUDA C Programming Guide 在线教程学习笔记 Part 10【坑】的更多相关文章
- CUDA C Programming Guide 在线教程学习笔记 Part 5
附录 A,CUDA计算设备 附录 B,C语言扩展 ▶ 函数的标识符 ● __device__,__global__ 和 __host__ ● 宏 __CUDA_ARCH__ 可用于区分代码的运行位置. ...
- CUDA C Programming Guide 在线教程学习笔记 Part 4
▶ 图形互操作性,OpenGL 与 Direct3D 相关.(没学过,等待填坑) ▶ 版本号与计算能力 ● 计算能力(Compute Capability)表征了硬件规格,CUDA版本号表征了驱动接口 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 2
▶ 纹理内存使用 ● 纹理内存使用有两套 API,称为 Object API 和 Reference API .纹理对象(texture object)在运行时被 Object API 创建,同时指定 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 13
▶ 纹理内存访问补充(见纹理内存博客 http://www.cnblogs.com/cuancuancuanhao/p/7809713.html) ▶ 计算能力 ● 不同计算能力的硬件对计算特性的支持 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 9
▶ 协作组,要求 cuda ≥ 9.0,一个简单的例子见 http://www.cnblogs.com/cuancuancuanhao/p/7881093.html ● 灵活调节需要进行通讯的线程组合 ...
- CUDA C Programming Guide 在线教程学习笔记 Part 8
▶ 线程束表决函数(Warp Vote Functions) ● 用于同一线程束内各线程通信和计算规约指标. // device_functions.h,cc < 9.0 __DEVICE_FU ...
- CUDA C Programming Guide 在线教程学习笔记 Part 7
▶ 可缓存只读操作(Read-Only Data Cache Load Function),定义在 sm_32_intrinsics.hpp 中.从地址 adress 读取类型为 T 的函数返回,T ...
- CUDA C Programming Guide 在线教程学习笔记 Part 3
▶ 表面内存使用 ● 创建 cuda 数组时使用标志 cudaArraySurfaceLoadStore 来创建表面内存,可以用表面对象(surface object)或表面引用(surface re ...
- CUDA C Programming Guide 在线教程学习笔记 Part 1
1. 简介 2. 编程模型 ▶ SM version 指的是硬件构架和特性,CUDA version 指的是软件平台版本. 3. 编程接口.参考 http://chenrudan.github.io/ ...
随机推荐
- day32 多进程
一 multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程. ...
- PHP安装sqlsrv和memcache扩展步骤
做了两天的实验才终于摸清楚如何将PHP连接上sqlserver数据库,以及怎样通过修改virtualhost文件来重定向,因为走得弯路比较多所以很想分享一下这次的心路历程. 第一步:安装wamp等类似 ...
- BMP、GIF、JPEG、PNG以及其它图片格式简单介绍
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/songjinshi/article/details/37516649 BMP格式 BMP是英文Bit ...
- ActiveMQ集群方案
集群方案主要为了解决系统架构中的两个关键问题:高可用和高性能.ActiveMQ服务的高可用性是指,在ActiveMQ服务性能不变.数据不丢失的前提下,确保当系统灾难出现时ActiveMQ能够持续提供消 ...
- Upgrade to or Install Cinnamon 2.4 in Ubuntu
http://www.omgubuntu.co.uk/2014/11/install-cinnamon-2-4-ubuntu-14-04-lts sudo add-apt-repository ppa ...
- ace 在线编辑器 知识点
ace 常用方法: 功能 语句 设置值 editor.setValue("the new text here"); // or session.setValue 获取值 edito ...
- ASP.NET Core 2.0 使用支付宝PC网站支付实现代码(转)
最近在使用ASP.NET Core来进行开发,刚好有个接入支付宝支付的需求,百度了一下没找到相关的资料,看了官方的SDK以及Demo都还是.NET Framework的,所以就先根据官方SDK的源码, ...
- C#中如何把byte[]数组转换成其他类型
http://bbs.csdn.net/topics/20447859 byte[] bytes = new byte[256]; //receive some stream from network ...
- 深入理解ASP.NET MVC(目录)
学ASP.NET MVC2有一段时间了,也针对性的做了个练习.感觉这个框架还是不错的,所以决定要深入系统的学习一下.看到这样一本书: 作者博客:http://blog.stevensanderson. ...
- iotBaidu问题小结
1.后台程序不能正常运行: d:\>java -jar MqttService.jar Exception in thread "main" java.lang.Securi ...