感知器、logistic与svm 区别与联系
https://blog.csdn.net/m0_37786651/article/details/61614865
从感知器谈起
对于典型的二分类问题,线性分类器的目的就是找一个超平面把正负两类分开。对于这个超平面,我们可以用下面的式子来表示,
感知器是最简单的一种线性分类器。用f(x)表示分类函数,感知器可以如下来表示。
感知器相当于一个阶跃函数,如下图所示,在0处有一个突变。

损失函数是分类器优化的目标函数,可以用来衡量分类错误的程度,损失函数值越小,代表分类器性能越好。感知器的损失函数为误分类点的函数间隔之和,函数间隔可以理解为样本与分类超平面的距离。误分类点距离分类超平面越远,则损失函数值越大。只有误分类的点会影响损失函数的值。
从感知器到logistic回归
感知器模型简单直观,但问题在于这个模型不够光滑,比如如果对于一个新的样本点我们计算出ω^T x+b=0.001,只比0大了一点点就会被分为正样本。同时这个点在0处有一个阶跃,导致这一点不连续,在数学上处理起来不方便。
那有没有办法让 ωTx+bωTx+b 到y的映射变得更加光滑呢,人们发现logistic函数有着这样的特性,输入范围是−∞→+∞,而值域光滑地分布于0和1之间。于是就有了logistic回归,正样本点分类的超平面距离越远,ωTx+bωTx+b 越大,而logistic函数值则越接近于1。负样本点分类的超平面距离越远,ωTx+bωTx+b 越小,而logistic函数值则越接近于0。
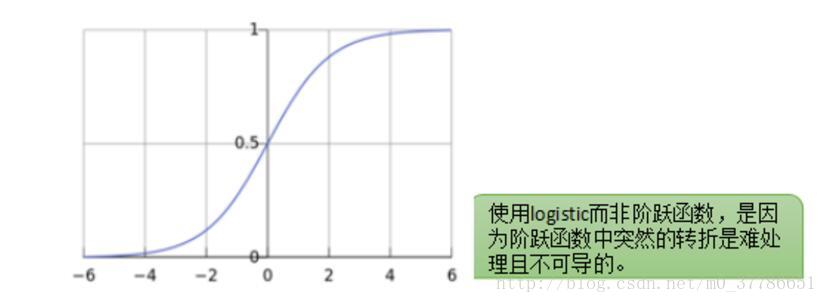
Logistic回归的损失函数为logistic损失函数,当分类错误时,函数间隔越大,则损失函数值越大。当分类正确时,样本点距离超平面越远,则损失函数值越小。所有的样本点分布情况都会影响损失函数最后的值。
从感知器到SVM
在感知器分类选分类超平面时,我们可以选择很多个平面作为超平面,而选择哪个超平面最好呢,我们可以选择距离正样本和负样本最远的超平面作为分类超平面,基于这种想法人们提出了SVM算法。SVM的损失函数为合页函数,当分类错误时,函数间隔越大,则损失函数值越大。当分类正确且样本点距离超平面一定距离以上,则损失函数值为0。误分类的点和与分类超平面距离较近的点会影响损失函数的值。
感知器、logistic与SVM
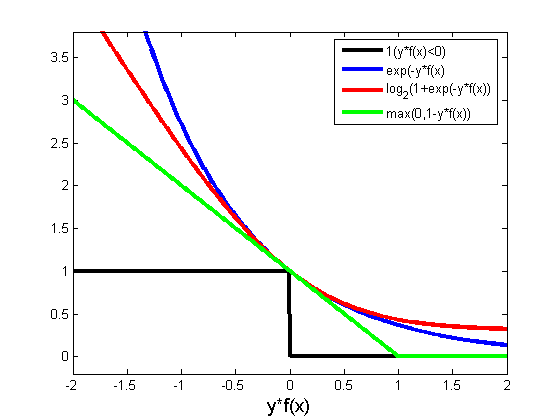
三者都是线性分类器,而logistic和svm是由感知器发展改善而来的。区别在于三者的损失函数不同,后两者的损失函数的目的都是增加对分类影响较大的数据点的权重,SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。下图中红色的曲线代表logistic回归的损失函数,绿色的线代表svm的损失函数。
参考
[1] 统计学习方法,李航
[2] http://blog.csdn.net/hel_wor/article/details/50539967
[3] https://www.zhihu.com/question/21704547
感知器、logistic与svm 区别与联系的更多相关文章
- 机器学习之感知器和线性回归、逻辑回归以及SVM的相互对比
线性回归是回归模型 感知器.逻辑回归以及SVM是分类模型 线性回归:f(x)=wx+b 感知器:f(x)=sign(wx+b)其中sign是个符号函数,若wx+b>=0取+1,若wx+b< ...
- 感知器、逻辑回归和SVM的求解
这篇文章将介绍感知器.逻辑回归的求解和SVM的部分求解,包含部分的证明.本文章涉及的一些基础知识,已经在<梯度下降.牛顿法和拉格朗日对偶性>中指出,而这里要解决的问题,来自<从感知器 ...
- 从感知器到SVM
这篇文章主要是分析感知器和SVM处理分类问题的原理,不涉及求解 感知器: 感知器要解决的是这样的一个二分类问题:给定了一个线性可分的数据集,我们需要找到一个超平面,将该数据集分开.这个超平面的描述如下 ...
- 第三集 欠拟合与过拟合的概念、局部加权回归、logistic回归、感知器算法
课程大纲 欠拟合的概念(非正式):数据中某些非常明显的模式没有成功的被拟合出来.如图所示,更适合这组数据的应该是而不是一条直线. 过拟合的概念(非正式):算法拟合出的结果仅仅反映了所给的特定数据的特质 ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- 机器学习 —— 基础整理(六)线性判别函数:感知器、松弛算法、Ho-Kashyap算法
这篇总结继续复习分类问题.本文简单整理了以下内容: (一)线性判别函数与广义线性判别函数 (二)感知器 (三)松弛算法 (四)Ho-Kashyap算法 闲话:本篇是本系列[机器学习基础整理]在time ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- 深度学习炼丹术 —— Taoye不讲码德,又水文了,居然写感知器这么简单的内容
手撕机器学习系列文章就暂时更新到此吧,目前已经完成了支持向量机SVM.决策树.KNN.贝叶斯.线性回归.Logistic回归,其他算法还请允许Taoye在这里先赊个账,后期有机会有时间再给大家补上. ...
- Stanford大学机器学习公开课(三):局部加权回归、最小二乘的概率解释、逻辑回归、感知器算法
(一)局部加权回归 通常情况下的线性拟合不能很好地预测所有的值,因为它容易导致欠拟合(under fitting).如下图的左图.而多项式拟合能拟合所有数据,但是在预测新样本的时候又会变得很糟糕,因为 ...
随机推荐
- jQuery 概述
jQuery 概述 版权声明:未经博主授权,内容严禁分享转载! 什么是 JavaScript 类库 JavaScript 类库是指已经被封装好的一系列 JavaScript 函数,能够实现一些特定的功 ...
- 编译安装vsftpd-3.0.2
编译安装vsftpd 首先下载源码包(我一般喜欢放在/home/test) 解压:tar -zxvf vsftpd-3.0.2.tar.gz 进入目录进行编译 cd vsftpd-3.0.2 编译之前 ...
- 20145317彭垚《网络对抗》Exp2 后门原理与实践
20145317彭垚<网络对抗>Exp2 后门原理与实践 基础问题回答 例举你能想到的一个后门进入到你系统中的可能方式? 在网上下载软件的时候,后门很有可能被捆绑在下载的软件当中: 例举你 ...
- 20145322 Exp5 Adobe阅读器漏洞攻击
20145322 Exp5 Adobe阅读器漏洞攻击 实验过程 IP:kali:192.168.1.102 windowsxp :192.168.1.119 msfconsole进入控制台 使用命令为 ...
- 20145330 《网络对抗》 Eternalblue(MS17-010)漏洞复现与S2-045漏洞的利用及修复
20145330 <网络对抗> Eternalblue(MS17-010)漏洞利用工具实现Win 7系统入侵与S2-045漏洞的利用及修复 加分项目: PC平台逆向破解:注入shellco ...
- NSwag enum
https://github.com/RSuter/NJsonSchema/wiki/JsonSchemaGenerator#integer-vs-string-enumerations Intege ...
- 【第二十章】 springboot + consul(1)
consul的具体安装与操作查看博客的consul系列. 一.启动consul (1个server+1个client,方便起见,client使用本机):查看:http://www.cnblogs.co ...
- navicat Window . MAC版常用快捷键
navicat 结合快捷键 1.ctrl+q 打开查询窗口 2.ctrl+/ 注释sql语句 3.ctrl+shift +/ 解除注释 4.ctrl+r 运行查询窗口的sql语句 5.ctrl+shi ...
- LINK : fatal error LNK1104: 无法打开文件“libboost_serialization-vc90-mt-gd-1_62.lib”
boost安装:https://www.cnblogs.com/sea-stream/p/10205425.html 在vs中添加
- sublime text3 (Mac) 快捷键
符号说明 符号 说明 ⌘ command ⌃ control ⌥ option ⇧ shift ↩ enter ⌫ delete 打开/关闭/前往 快捷键 功能 ⌘⇧N 打开一个新的sublime窗口 ...