常用模块:re ,shelve与xml模块
一 shelve模块:
shelve模块比pickle模块简单,只有一个open函数,所以使用完之后要使用f.close关闭文件。返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
import shelve f=shelve.open(r'sheve.txt')
# f['stu1_info']={'name':'egon','age':,'hobby':['piao','smoking','drinking']}
# f['stu2_info']={'name':'gangdan','age':}
# f['school_info']={'website':'http://www.pypy.org','city':'beijing'} print(f['stu1_info']['hobby'])
f.close()
二 xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。
xml使用〈〉来区别分数据结构:
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
# print(root.iter('year')) #搜索全部内容
# print(root.find('country')) #在root的子节点找,只找一个,也就是说找到一个country就停止。
# print(root.findall('country')) #在root的子节点找,找所有,将所有的country都找到。
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = ''
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = ''
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
同样的xml可以对文件内容进行增,删,改,查.
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print('========>',child.tag,child.attrib,child.attrib['name'])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')
node.set('version','1.0')
tree.write('test.xml')
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')
xml相关操作
三 re模块
re模块就是我们说的正则:
那么正则就是用使用一些具有特殊意义的符号组合起来的,用来描述字符或则字符串的方法。
其中组合起来的特殊字符就叫做正则表达式。
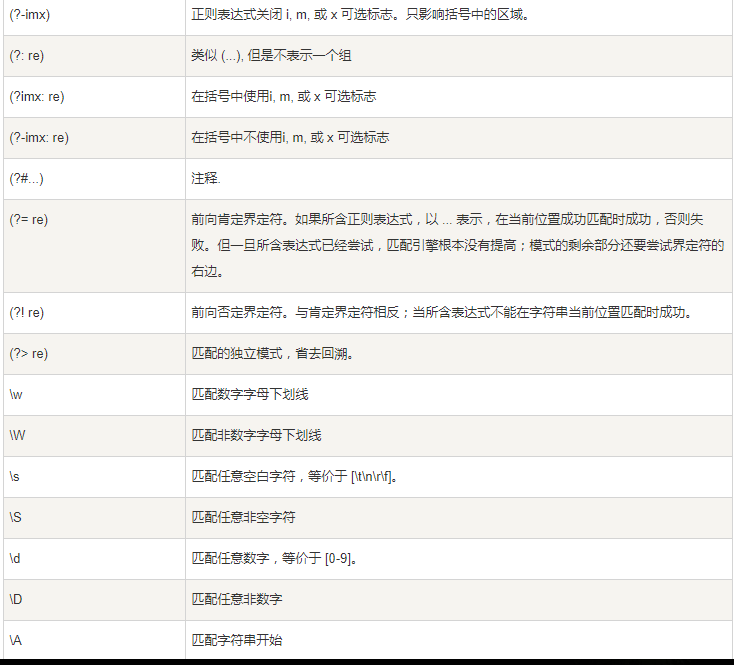
‘\W’:大写的W与小w是相反的,匹配非字母数字下划线。
‘\s’:匹配任意空白字符,[\t\n\r]或则一个空字符‘’
'\S':匹配任意非空字符,除了空字符
'\d':匹配任意数字,相当于匹配任意[0-9]的数字
'\D':匹配任意非数字。
'\n':匹配一个换行符
'\t':匹配一个制表符
'^':匹配字符串的开始字符
'$':匹配字符串的结尾字符
‘.’:匹配任意字符,除了换行符,当我们在后面加上(re.Dotall时可以匹配任意字符包括换行符)
'[...]':匹配一个指定范围的字符(这个字符来自于括号内),[]内只能代表一个。
‘[^...]’:对括号内的内容取反,当我们使用‘-’时,应将‘-’放左边或右边,不能放中间,放中间有其特殊意义。
‘*’:表示匹配0个或则无数个。
‘+’:表示匹配1个或者无数个
‘?’:匹配0个或者1个。
‘{m,n}’:匹配m到n个。

=================================匹配模式=================================
#一对一的匹配
# 'hello'.replace(old,new)
# 'hello'.find('pattern') #正则匹配
import re
#\w与\W
print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3']
print(re.findall('\W','hello egon 123')) #[' ', ' '] #\s与\S
print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' ']
print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] #\n \t都是空,都可以被\s匹配
print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' '] #\n与\t
print(re.findall(r'\n','hello egon \n123')) #['\n']
print(re.findall(r'\t','hello egon\t123')) #['\n'] #\d与\D
print(re.findall('\d','hello egon 123')) #['1', '2', '3']
print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' '] #\A与\Z
print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^
print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$ #^与$
print(re.findall('^h','hello egon 123')) #['h']
print(re.findall('3$','hello egon 123')) #['3'] # 重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
#.
print(re.findall('a.b','a1b')) #['a1b']
print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab']
print(re.findall('a.b','a\nb')) #[]
print(re.findall('a.b','a\nb',re.S)) #['a\nb']
print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一条意思一样 #*
print(re.findall('ab*','bbbbbbb')) #[]
print(re.findall('ab*','a')) #['a']
print(re.findall('ab*','abbbb')) #['abbbb'] #?
print(re.findall('ab?','a')) #['a']
print(re.findall('ab?','abbb')) #['ab']
#匹配所有包含小数在内的数字
print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3'] #.*默认为贪婪匹配
print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b'] #.*?为非贪婪匹配:推荐使用
print(re.findall('a.*?b','a1b22222222b')) #['a1b'] #+
print(re.findall('ab+','a')) #[]
print(re.findall('ab+','abbb')) #['abbb'] #{n,m}
print(re.findall('ab{2}','abbb')) #['abb']
print(re.findall('ab{2,4}','abbb')) #['abb']
print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+'
print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*' #[]
print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾
print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #[]内的^代表的意思是取反,所以结果为['a=b']
print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #[]内的^代表的意思是取反,所以结果为['a=b'] #\# print(re.findall('a\\c','a\c')) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常
print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义
print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c'] #():分组
print(re.findall('ab+','ababab123')) #['ab', 'ab', 'ab']
print(re.findall('(ab)+123','ababab123')) #['ab'],匹配到末尾的ab123中的ab
print(re.findall('(?:ab)+123','ababab123')) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">点击</a>'))#['http://www.baidu.com']
print(re.findall('href="(?:.*?)"','<a href="http://www.baidu.com">点击</a>'))#['href="http://www.baidu.com"'] #|
print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
1#^上结符
# print(re.findall('^a','bc a12a sd 3a4 f'))
# print(re.findall('^1','1llo egon 123'))
#如果存在以^后面的字母或数字,那么就输出这个字符或数字,否者输出为空。
2#.点
# print(re.findall('a.b','a2b a\nb acb ccb'))
# 如果存在一个字符a与b中间有一个任意的字符,除了换行符则输出该字符,a与b中间只能有一个字符。
# print(re.findall('a.b','a2b a\nb acb ccb',re.DOTALL))#加上一个re.DOTALL就可以实现所有的字符
3#*星号
# print(re.findall('a*b','a2b b acb ccb b'))
# print(re.findall('ab*','a2b a、b acb ccb aaaabbbbb'))
#将星号前面的表达式字符与后面的字符进行匹配,将匹配到的字符输出,可以是0个到多个
4#?问号
# print(re.findall('ab?','ab abc accc abccc abbbb')) #['a']
# print(re.findall('ab?','abbb')) #['ab']
# ?将问号前面的字符与后面的字符进行匹配,只匹配0个或1个。即使有多余的也不会匹配
5#
# print(re.findall('\d+\.?\d*',"asdfasdf12453as1.13dfa12adsf1asdf3"))
# 匹配所有包括小数在内的数字
6#(.*)为贪婪匹配
# print(re.findall('a.*b','a1b22222222b'))
# 那么他会从a开始匹配,一直匹配到最后一个b
7#(.*?)为非贪婪匹配
# print(re.findall('a.*?b','a1b22222222b'))
# 那么他从a开始碰到第一个b就会结束
8#(+)加号
# print(re.findall('ab+','a'))
# print(re.findall('ab+','abbb'))
#也就是至少有一个匹配上。
9#{n,m}从n到m
# print(re.findall('ab{2}','ab')) #['abb']
# print(re.findall('ab{2,4}','abbb')) #['abb']
# print(re.findall('ab{1,}','abbbbbbbbbbbb')) #'ab{1,}' ===> 'ab+'
# print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*'
# 从a开始,在大括号内定义开始个数和结束个数。
10#[]中括号
# print(re.findall('a[1*-]b','a1b a*b a-b ab'))
# []内的都为普通字符,也就是说只能表示[]的意思,其他的都是匹配不到,按照[]中德单独字符的格式。
11#[^]中括号内加^
# print(re.findall('a[^1*-]b','a1b a*b a-b'))
# 对括号里的内容取反。也就是说凡是跟[]中一样的格式都匹配不到。
12#分组()
# print(re.findall('ab+123','ababab123')) #['ab', 'ab', 'ab']
# print(re.findall('(ab)+123','ababab123')) #['ab'],
#['ab123']
# ['ab']
# 上述为两个输出的结果,所以()只输出括号内的匹配到的值。
13#竖杠|
print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, '
'and the next one is my company'))
#一个或的作用,

常用模块:re ,shelve与xml模块的更多相关文章
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- Python3基础(5)常用模块:time、datetime、random、os、sys、shutil、shelve、xml处理、ConfigParser、hashlib、re
---------------个人学习笔记--------------- ----------------本文作者吴疆-------------- ------点击此处链接至博客园原文------ 1 ...
- 常用模块之 os,json,shelve,xml模块
os 即操作系统 在 os 中提供了很多关于文件,文件夹,路径处理的函数 这是我们学习的重点 os.path 是os模块下专门用于处理路径相关的 python是一门跨平台语言,由于每个平台路径规则不同 ...
- 常用文件操作模块json,pickle、shelve和XML
一.json 和 pickle模块 用于序列化的两个模块 json,用于字符串 和 python数据类型间进行转换 pickle,用于python特有的类型 和 python的数据类型间进行转换 Js ...
- shelve,xml,re模块
一.shelve模块 shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型 import shelve ...
- 保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python
一.各模块的主要功能区别 json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文. (与其他大多语言交互的类型) pickle模块:将数据对象从内存中完成序列 ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- python(32)——【shelve模块】【xml模块】
一. shelve模块 json和pickle模块的序列化和反序列化处理,他们有一个不足是在python 3中不能多次dump和load,shelve模块则可以规避这个问题. shelve模块是一个简 ...
- Python常用内置模块之xml模块
xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言.从结构上,很像HTML超文本标记语言.但他们被设计的目的是不同的,超文本标记语言被设计用来显示 ...
随机推荐
- 《TensorFlow实战》读书笔记(完结)
1 TensorFlow基础 ---1.1TensorFlow概要 TensorFlow使用数据流图进行计算,一次编写,各处运行. ---1.2 TensorFlow编程模型简介 TensorFlow ...
- 步步入佳境---UI入门(1)--项目建立与实现
一,本文讲解建立一个空项目,怎么一步一步的创建程序,总体的感觉一下程序流程 1,首先建立一个项目,如下:single view project,我们首先删除CHAppDelegate文件和Main. ...
- chapter02“良/恶性乳腺癌肿瘤预测”的问题
最近比较闲,是时候把自己以前看的资料整理一下了. LogisticRegression:由于在训练过程中考虑了所有的样本对参数的影响,因此不一定获得最佳的分类器,对比下一篇 svm只用支持向量来帮助决 ...
- 文件的存储GridFS
1.存储路径--->可以理解就是存储路径,然后在通过路径来获取文件 将文件放在本地路径(网络路径)下,然后数据库中存储该文件的查找路径 db.log.insert({filename:" ...
- Http常见状态码说明
一些常见的状态码为: 200 - 服务器成功返回网页404 - 请求的网页不存在503 - 服务不可用 详细分解: 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码.代码 说明100 ...
- PHP处理大数据导出Excel方法
在日常的工作中,很多时候都需要导出各种各样的报表,但是如果导出的数据一旦比较大,很容易就导致超时,对于这种问题,有很多的解决方法,例如网上说的分批导出.采用CSV.还有就采用JAVA.甚至是C++和C ...
- Thrift 个人实战--Thrift 网络服务模型(转)
前言: Thrift作为Facebook开源的RPC框架, 通过IDL中间语言, 并借助代码生成引擎生成各种主流语言的rpc框架服务端/客户端代码. 不过Thrift的实现, 简单使用离实际生产环境还 ...
- zz 【见闻八卦】《金融时报》年度商业书单:互联网题材占一半
[见闻八卦]<金融时报>年度商业书单:互联网题材占一半 文 / 见闻学堂 2014年12月18日 09:47:38 0 中国最好的金融求职培训:见闻学堂(微信号:top-elites) ...
- MyBatis 知识点
2010年,随着开发团队转投Google Code旗下,ibatis 3.x 正式更名为 Mybatis. orm工具的基本思想 无论是 hibernate.Mybatis,orm工具有一个共同点: ...
- Mac 下安装python3.7 + pip 利用 chrome + chromedriver + selenium 自动打开网页并自动点击访问指定页面
1.安装python3.7https://www.python.org/downloads/release/python-370/选择了这个版本,直接默认下一步 2.安装pipcurl https:/ ...