ThreadLocal实现原理
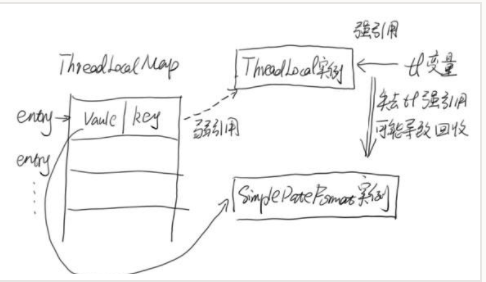
ThreadLocal实现原理的更多相关文章
- 线程局部变量ThreadLocal的原理及使用范围_1
线程局部变量ThreadLocal的原理及使用范围 使用原理 每个Thread中都有一个ThreadLocalMap成员, 该成员是ThreadLocal的内部类ThreadLocalMap类型.每使 ...
- ThreadLocal的原理和在框架中的应用
ThreadLocal的原理和在框架中的应用 博客分类: java基础 框架多线程SpringthreadDAO 概述 我们知道Spring通过各种DAO模板类降低了开发者使用各种数据持久 ...
- ThreadLocal的原理及产生的问题
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. ThreadLocal的原理 特点 ThreadLocal和Sychro ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
- ThreadLocal工作原理
原文出处: imzoer 在这篇文章中,总结了一下面试过程中遇到的关于ThreadLocal的内容.总体上说,这样回答,面试算是过得去了.但是,这样的回答,明显仅仅是背会了答案,而没有去研究Threa ...
- ThreadLocal的原理,源码深度分析及使用
文章简介 ThreadLocal应该都比较熟悉,这篇文章会基于ThreadLocal的应用以及实现原理做一个全面的分析 内容导航 什么是ThreadLocal ThreadLocal的使用 分析Thr ...
- 对ThreadLocal实现原理的一点思考
前言 在<透彻理解Spring事务设计思想之手写实现>中,已经向大家揭示了Spring就是利用ThreadLocal来实现一个线程中的Connection是同一个,从而保证了事务.本篇博客 ...
- 【原理】Java的ThreadLocal实现原理浅读
当前线程的值传递,ThreadLocal 通过ThreadLocal设值,在线程内可获取,即时获取值时在其它Class或其它Method. public class BasicUsage { priv ...
- ThreadLocal使用原理、注意问题、使用场景
想必很多朋友对ThreadLocal并不陌生,今天我们就来一起探讨下ThreadLocal的使用方法和实现原理.首先,本文先谈一下对ThreadLocal的理解,然后根据ThreadLocal类的源码 ...
随机推荐
- jq ajax传参的两种方式
第一种 在url ? 后通过拼接传参 第二种 通过data传参 (1)第一种方法:(通过url传参) function GetQuery(id) { if (id ==1||id==7) { ...
- python recv()是什么
socket有个recv方法,recv有一个参数,指定数据缓冲区的大小 但是现在的问题就是不知道将要接受的数据的大小到底是多少,可能只有几个字节,可能会有几M,google了一下socket的入门文章 ...
- Hive 常用优化参数
常用调优测试语句 : ①显示当前hive环境的参数值: set 参数名; 如: hive> set mapred.map.tasks;mapred.map.tasks; ②设置hi ...
- angularjs 路由参数
.state('classrooms',{ url: '/classrooms/:id' }) .state('classrooms',{ url: '/classrooms/{id}' }) .st ...
- Unix/Linux系统编程
一,开发工具 编译器 GCC 调试工具 GDB 代码编辑 Vim 1. 编译命令 gcc hello.c -o hello # 第二个hello为新生成的可执行文件名 -o 为生成的可执行文件指定名称 ...
- SCP报错:WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
经过google,出现这个问题的原因是,这是ssh的问题, GkFool大神说(第一次使用SSH连接时,会生成一个认证,储存在客户端的known_hosts中) 我的解决办法是: ssh-keygen ...
- C++ Compress Floder
第三方函数.头文件.测试工程下载地址:http://download.csdn.net/detail/u012958937/8361733
- 【前端】javascript+jquery实现手风琴式的滚动banner或产品展示图
实现效果 实现步骤 // 鼠标放入到li中该盒子变宽,其他盒子变窄,鼠标移开大盒子,恢复原样 // 实现步骤 // 1. 给li添加背景 // 2. 绑定onmouseover事件,鼠标放入到li中, ...
- P2472 [SCOI2007]蜥蜴(网络最大流)
P2472 [SCOI2007]蜥蜴 题目描述 在一个r行c列的网格地图中有一些高度不同的石柱,一些石柱上站着一些蜥蜴,你的任务是让尽量多的蜥蜴逃到边界外. 每行每列中相邻石柱的距离为1,蜥蜴的跳跃距 ...
- Python 开发环境搭建
Python分别有两个大的版本,分别是2和3 下载地址:Python-3.6.2 Python-2.7.13 现在安装路径:D:\Program Files\Python 安装完成以后要安装 pi ...