Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作:
1、驱动程序使将闭包中使用变量封装成对象,驱动程序序列化对象,传给worker节点任务;
2、worker节点任务接收到对象,执行闭包函数;
由于使用外部变量势必会通过网络、序列化、反序列化,如外部变量过大或过多使用外部变量将会影响Spark程序的性能;
Spark提供了两种类型的共享变量(Shared Variables):广播变量(Broadcast Variables)、累加器(Accumulators );
广播变量(Broadcast Variables)
Spark提供的广播变量可以解决闭包函数引用外部大变量引起的性能问题;广播变量将只读变量缓存在每个worker节点中,Spark使用了高效广播算法分发变量从而提高通信性能;如直接在闭包函数中使用外部 变量该变量会缓存在每个任务(jobTask)中如果多个任务同时使用了一个大变量势必会影响到程序性能;
广播变量:每个worker节点中缓存一个副本,通过高效广播算法提高传输效率,广播变量是只读的;
Spark Scala Api与Java Api默认使用了Jdk自带序列化库,通过使用第三方或使用自定义的序列化库还可以进一步提高广播变量的性能;
广播变量使用示例:
val sc = SparkContext("");
val eigenValue = sc.bradcast(loadEigenValue())
val eigen = computer.map{x =>
val temp = eigenValue.value
...
...
}
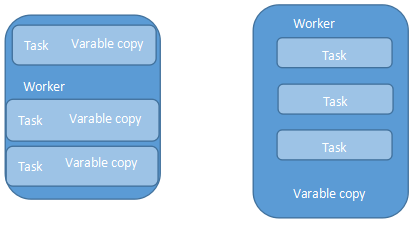
左节点不使用广播变量,右使用广播变量
累加器(Accumulators)
累加器可以使得worker节点中指定的值聚合到驱动程序中,如统计Spark程序执行过程中的事件总数等;
val sc = new SparkContext(...)
val file = sc.textFile("xxx.txt")
val eventCount = sc.accumulator(0,"EventAccumulator") //累加器初始值为0
val formatEvent = file.flatMap(line => {
if(line.contains("error")){
eventCount +=1
}
})
formatEvent.saveAsTextFile("eventData.txt")
println("error event count : " + eventCount);
在使用累加器(Accumulators)时需要注意,只有在行动操作中才会触发累加器,也就是说上述代码中由于flatMap()为转换操作因为Spark惰性特征所以只用当saveAsTextFile() 执行时累加器才会被触发;累加器只有在驱动程序中才可访问,worker节点中的任务不可访问累加器中的值;
Spark原生支持了数字类型的的累加器如:Int、Double、Long、Float等;此外Spark还支持自定义累加器用户可以通过继承AccumulableParam特征来实现自定义的累加器此外Spark还提供了accumulableCollection()累加集合用于;创建累加器时可以使用名字也可以不是用名字,当使用了名字时在Spark UI中可看到当中程序中定义的累加器, 广播变量存储级别为MEMORY_AND_DISK;
文章首发地址:Solinx
http://www.solinx.co/archives/570
Spark——共享变量的更多相关文章
- spark共享变量
boradcast例子代码: scala版本 spark共享变量之Accumulator 例子代码: scala版本
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- 8.Spark SQL
Spark SQL 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- 日期格式 CST
从es 取出来一个date 字段, 结果竟然是 2016-10-10T10:48:58.000Z 这样的字符串, 这个是什么格式啊??? CST ? 只能自己转换了! 通过"yyyy-MM- ...
- xamarin android,UWP 网络类型和IP地址
App开发经常要判断网络连通情况,并判断网络类型,获取网络IP.xamarin中可以使用Dependencies提供各平台下的方法,现把各平台代码记录如下: using System; using S ...
- MVC5 网站开发之八 栏目功能 添加、修改和删除
本次实现栏目的浏览.添加.修改和删除. 栏目一共有三种类型. 常规栏目-可以添加子栏目,也可以添加内容模型.当不选择内容模型时,不能添加内容. 单页栏目-栏目只有一个页面,可以设置视图. 链接栏目-栏 ...
- SQL Server-分页方式、ISNULL与COALESCE性能分析(八)
前言 上一节我们讲解了数据类型以及字符串中几个需要注意的地方,这节我们继续讲讲字符串行数同时也讲其他内容和穿插的内容,简短的内容,深入的讲解,Always to review the basics. ...
- sql重置自增长
SQL的自增列挺好用,只是开发过程中一旦删除数据,标识列就不连续了 写起来 也很郁闷,所以查阅了一下标识列重置的方法 发现可以分为三种: --- 删除原表数据,并重置自增列 truncate tabl ...
- 自己动手之使用反射和泛型,动态读取XML创建类实例并赋值
前言: 最近小匹夫参与的游戏项目到了需要读取数据的阶段了,那么觉得自己业余时间也该实践下数据相关的内容.那么从哪入手呢?因为用的是Unity3d的游戏引擎,思来想去就选择了C#读取XML文件这个小功能 ...
- ASP.NET Core 中文文档 第二章 指南(4.10)检查自动生成的Detail方法和Delete方法
原文 Examining the Details and Delete methods 作者 Rick Anderson 翻译 谢炀(Kiler) 校对 许登洋(Seay).姚阿勇(Mr.Yao) 打 ...
- 利用Python进行数据分析(15) pandas基础: 字符串操作
字符串对象方法 split()方法拆分字符串: strip()方法去掉空白符和换行符: split()结合strip()使用: "+"符号可以将多个字符串连接起来: join( ...
- 简简单单学会C#位运算
一.理解位运算 要学会位运算,首先要清楚什么是位运算?程序中的所有内容在计算机内存中都是以二进制的形式储存的(即:0或1),位运算就是直接对在内存中的二进制数的每位进行运算操作 二.理解数字进制 上面 ...
- WebApi系列~StringContent与FormUrlEncodedContent
回到目录 知识点 本文是一个很另类的文章,在项目中用的比较少,但如果项目中真的出现了这种情况,我们也需要知道如何去解决,对于知识点StringContent和FormUrlEncodedContent ...